一种基于改进视觉词袋模型的图像分类方法与流程
本发明涉及一种图像分类方法,尤其涉及一种基于改进视觉词袋模型的图像分类方法,属于图像分类处理领域。
背景技术:
近年来,随着多媒体技术和互联网技术的快速发展,图像的产生与传播变得更加的方便与快捷,图像资源呈现快速的增长。其中,场景图像分类是图像研究领域的重要分支,是当前计算机视觉的热点问题。针对在交通场景下,监控摄像机和电子眼的大量使用,产生大量的交通场景图像,使得有效地管理这些图像变得愈加困难。为了更为有效地管理和检索交通场景图像,对场景图像分类技术的需求变得更加的迫切。如何结合现有的数据挖掘知识,对图像进行有效的特征提取和分类,是实现智慧交通要解决的关键技术之一,它的研究具有很大的理论价值和应用价值。
在众多的图像分类方法中,由“词袋法”发展而来的视觉词袋模型(BOW,Bag of Words)是目前图像分类中较主流的方法之一。通常首先提取图像的局部特征,其次将这些特征矢量量化并构造视觉码本,特征矢量编码为视觉单词,从而每幅图像可以由不同频率的视觉单词表示。最后生成每幅图像的视觉单词直方图,通过训练分类器,检测出待判别的图像类型。
例如,发明专利“基于视觉词典的图像分类方法”(专利申请号:201110175101.9,公开号:CN102208038A)即通过BOW模型构建视觉词典,并将图像用基于该视觉词典的直方图表示,建立模型对图像进行分类,该方法没有考虑图像特征点的空间布局信息;发明专利“基于空间局部聚合描述向量的图像分类方法”(专利申请号:201310180925.4,公开号:CN103295026A)中的方法考虑了特征点空间布局信息,用基于带有特征点空间分布的局部描述聚合向量训练分类器,实现图像分类。针对场景图像,其具有复杂的背景,上述方法无法避免的提取了相同的背景单词,在不同类图像间造成了相似性干扰,且场景图像易受遮挡,以及多标记的影响,同类视觉单词不突出。另外,上述方法复杂度高,实际应用中运行效率低,实时性较差。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种基于改进视觉词袋模型的图像分类方法。
本发明的技术方案如下:
一种基于改进视觉词袋模型的图像分类方法,具体包括以下步骤:
步骤1,将图像集划分为训练图像集和测试图像集;
步骤2,获取训练图像集的SIFT描述子:
步骤2.1,利用尺度可变的二维高斯核函数与原始图像做卷积,将相邻尺度的两个高斯图像相减建立DOG尺度空间金字塔模型,具体计算为:
L(x,y,σ)=G(x,y,σ)*I(x,y);
D(x,y,σ)=(G(x,y,kσ)-G(x,y,σ))*I(x,y);
其中G(x,y,σ)为可变尺度的二维高斯函数,L(x,y,σ)为图像函数的尺度空间,D(x,y,σ)为原始图像;σ为尺度空间因子,是高斯函数的标准差;I(x,y)为图像的二维函数表示,其中x和y是空间坐标,k为常数。
步骤2.2,通过逐个比较每个像素点(x,y)的方法,找到相邻位置和相邻尺度内的特征点,并确定特征点的位置和尺度;
步骤2.3,计算特征点邻域内每个像素点的梯度幅值和方向,计算公式为:
其中,m(x,y)代表特征点梯度的大小,θ(x,y)代表特征点的梯度方向;
步骤2.4,以特征点为中心,对其邻域分块并计算块内梯度直方图,生成SIFT描述子;
步骤3,利用均值聚类方法聚类步骤2.2生成的所有特征点,进而生成视觉词典;
步骤4,根据步骤3生成的视觉词典,生成每一幅图像的视觉词袋,进而提取同类图像视觉单词的最大频繁项集;
步骤5,对视觉单词的最大频繁项集进行加权处理后生成其视觉单词直方图;
步骤6,测试图像集处理过程和训练图像集步骤2到步骤5的处理过程相同,最后根据生成的视觉单词直方图训练SVM分类器实现场景图像的图像分类。
作为本发明一种基于改进视觉词袋模型的图像分类方法的进一步优选方案,在步骤2中,特征点的提取和生成视觉词典的方法采用迭代Topology模型进行分布式并行改进。
作为本发明一种基于改进视觉词袋模型的图像分类方法的进一步优选方案,在步骤4中,提取同类图像视觉单词的最大频繁项集的具体步骤如下:
步骤4.1,扫描事务数据集一次,给定最小支持度产生频繁项目集及其支持度,按支持度降序排列F,生成频繁项目列表LF,记LF={1,2,3,...,j},j=|LF|;
步骤4.2,设最大频繁项集集合MFS=φ,最大频繁候选项集集合MFCS=LF,计算MFCS的支持度,若支持度大于min_s,MFS=MFCS,执行步骤4.6,否则执行4.3;
步骤4.3,设MFCS={c|c∈LF且|c|=j-1},对于所有项集m∈MFCS,若支持度大于min_s,则MFS=MFS∪m,若项目则令MFS为所求,执行步骤4.6,否则执行步骤4.4;
步骤4.4,若MFS≠φ,MFCS={c|e∈c且|c|=j-2},若MFS=φ,MFCS={c|c∈LF且|c|=j-2},对于所有项集m∈MFCS,若支持度大于min_s,则MFS=MFS∪m,若项目MFS为所求,执行步骤4.6,否则执行步骤4.5;
步骤4.5,重复步骤4.4,变量j=j-1,直至项目MFS为所求;
步骤4.6,重复步骤4.1~步骤4.5,求得每类的最大频繁视觉单词项集。
作为本发明一种基于改进视觉词袋模型的图像分类方法的进一步优选方案,在步骤5中,加权处理具体包含如下步骤:
步骤5.1,计算每幅图像的归一化视觉单词直方图时,对其中最大频繁视觉单词进行加权;
步骤5.2,每幅图像的视觉词袋中,各个视觉单词的数量为ki(i=1,2,...,n),n为视觉单词的种数,整个词袋的视觉单词数量为k,则权值为ωi=(1+ki/k);
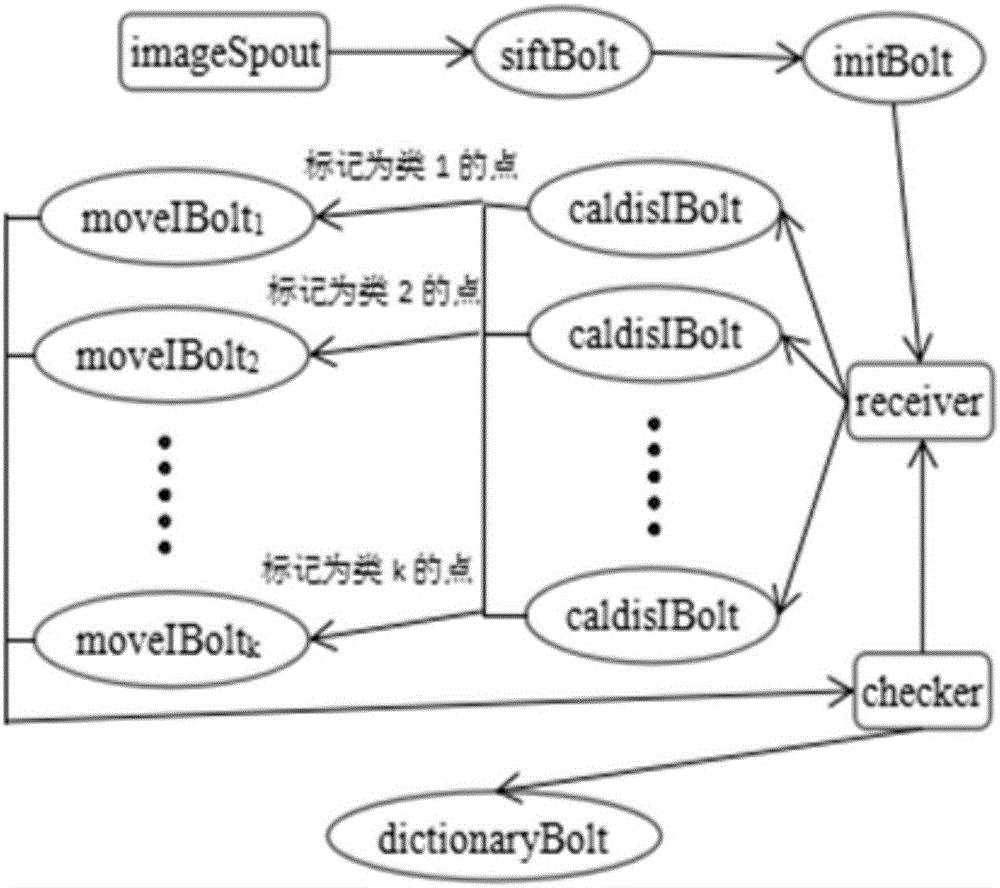
5.根据权利要求2所述的一种基于改进视觉词袋模型的图像分类方法,其特征在于:依据Topology模型的设计规范,所述Topology模型包括imageSpout模块、siftBolt模块、initBolt模块、receiver模块、caldisIBolt模块、moveIBolt模块、checker模块以及dictionaryBolt模块。
本发明与现有的技术相比,具有以下优点:
1,通过引入关联规则的最大频繁项集,分别统计和加权各类的最大频繁视觉单词项集,突出同类图像的视觉单词,增强同类图像的共有特征,提高分类的准确度;
2,通过引入Topology模型对视觉词典生成过程进行并行化改进,提高方法的实际应用效率;
3,针对现有方法并没有充分考虑同类别图像视觉单词的相似性,不能充分表达图像所属类别的共有特征,本文运用关联规则中的最大频繁项集的知识,突出同类别图像频繁出现的视觉单词,以提高分类的准确度;
4,传统方法生成视觉词典是一个特征聚类的过程,通常,图像提取的特征点数量很大,且运用聚类算法对特征点进行聚类需要反复迭代,实时性不高,针对这个问题,提出基于Topology模型的生成视觉词典方法来提高生成视觉词典的效率。
附图说明
图1是本发明的实现流程图;
图2是基于Topology的生成视觉词典模型图;
图3是本发明仿真采用的COREL和Caltech-256图像库中的样例图像;
其中:(a)是本发明图像库中一幅自然场景下的自行车样例图像;
(b)是本发明图像库中一幅自然场景下的公交车样例图像;
(c)是本发明图像库中一幅自然场景下的轿车样例图像;
(d)是本发明图像库中一幅自然场景下的跑车样例图像;
(e)是本发明图像库中一幅自然场景下的摩托车样例图像;
(f)是本发明图像库中一幅自然场景下的卡车样例图像;
图4是本发明与传统方法的仿真分类性能图;
图5是本发明与传统方法的仿真生成视觉词典的执行时间图。
具体实施方式
参照图1,本发明的具体技术实施步骤如下:
一种基于改进视觉词袋模型的图像分类方法,具体包括以下步骤:
步骤1,将图像集划分为训练图像集和测试图像集;
步骤2,获取训练图像集的SIFT描述子:
步骤3,利用均值聚类方法聚类步骤2.2生成的所有特征点,进而生成视觉词典;
步骤4,根据步骤3生成的视觉词典,生成每一幅图像的视觉词袋,进而提取同类图像视觉单词的最大频繁项集;
步骤5,对视觉单词的最大频繁项集进行加权处理后生成其视觉单词直方图;
步骤6,测试图像集处理过程和训练图像集步骤2到步骤5的处理过程相同,最后根据生成的视觉单词直方图训练SVM分类器实现场景图像的图像分类。
步骤2的具体步骤如下:
步骤2.1,利用尺度可变的二维高斯核函数与原始图像做卷积,将相邻尺度的两个高斯图像相减建立DOG尺度空间金字塔模型:
L(x,y,σ)=G(x,y,σ)*I(x,y);
D(x,y,σ)=(G(x,y,kσ)-G(x,y,σ))*I(x,y);
其中G(x,y,σ)为可变尺度的二维高斯函数,L(x,y,σ)为图像函数的尺度空间,D(x,y,σ)为原始图像;σ为尺度空间因子,是高斯函数的标准差;I(x,y)为图像的二维函数表示,其中x和y是空间坐标,k为常数。
步骤2.2,通过逐个比较每个像素点(x,y)的方法,找到相邻位置和相邻尺度内的局部极值点(极大值或极小值),即为特征点,并确定特征点的位置和尺度;
步骤2.3,计算特征点邻域内每个像素点的梯度幅值和方向,公式为:
其中,m(x,y)代表特征点梯度的大小,θ(x,y)代表特征点的梯度方向;
步骤2.4,以特征点为中心,将其邻域分成4*4=16个子区域,对每个子区域求8个方向的梯度,并生成梯度直方图,最终获得8*4*4=128维的SIFT描述子。
步骤3,利用均值聚类方法聚类优化后的特征点集得到视觉词典。
步骤4的具体步骤如下:
根据步骤3生成的视觉词典,生成每一幅图像的视觉词袋,进而提取同类图像视觉单词的最大频繁项集;得到视觉词典后,计算训练图像的每个SIFT特征向量与词典中视觉单词的欧式距离,将特征向量映射到距离最近的视觉单词,统计每一幅图像的视觉单词出现的次数,再将每一个视觉单词出现的次数除以总的视觉单词数,归一化形成最终的图像特征表述,提取同类图像的视觉单词最大频繁项集,具体如下:
对于一类图像的N幅图像,生成的视觉词典组成项目集合,即I={i1,i2,i3,...,im}是m个视觉单词组成的集合。对于第一幅图像,其视觉词袋构成项目集这就是第一条事务记录,依次从第一幅图像到第N幅图像,生成了X1,…,XN的N条事务记录。然后挖掘这个事务集的最大频繁项集:
步骤4.1,扫描事务数据集一次,给定最小支持度产生频繁项目集及其支持度,按支持度降序排列F,生成频繁项目列表LF,记LF={1,2,3,...,j},j=|LF|;
步骤4.2,设最大频繁项集集合MFS=φ,最大频繁候选项集集合MFCS=LF,计算MFCS的支持度,若支持度大于min_s,MFS=MFCS,执行(步骤4.5),否则执行(步骤4.4);
步骤4.3,设MFCS={c|c∈LF且|c|=j-1},对于所有m∈MFCS,若支持度大于min_s,则MFS=MFS∪m。若项目MFS为所求,执行(步骤4.5),否则执行(步骤4.4);
步骤4.4,若MFS≠φ,MFCS={c|e∈c且|c|=j-2},若MFS=φ,MFCS={c|c∈LF且|c|=j-2},对于所有m∈MFCS,若支持度大于min_s,则MFS=MFS∪m。若项目MFS为所求,执行(步骤4.5),否则执行(步骤4.6);
步骤4.5,重复(步骤4.4),变量j=j-1,直至项目MFS为所求;
步骤4.6,重复(步骤4.1)~(步骤4.6),求得每类的最大频繁视觉单词项集。
步骤5的具体步骤如下:
以第一幅图像为例,加权如下:
步骤5.1,最大频繁项中出现的就是同类图像频繁出现的视觉单词,将第一幅图像的视觉词袋对比最大频繁项中的频繁视觉单词,若其词袋中存在频繁的视觉单词,计算图像的视觉单词直方图时,对频繁视觉单词加权;
步骤5.2,加权权值与视觉单词在图像中的数量有关,第一幅图像的视觉词袋中,各个视觉单词的数量为ki(i=1,2,...,n),整个词袋的视觉单词数量为k,则权值为ωi=(1+ki/k);
步骤5.3,对加权后的视觉词袋生成第一幅图像的归一化视觉单词直方图。按照这样方式,依次生成所有训练图像的归一化视觉单词直方图;
步骤6,训练支持向量机实现自然场景图像的分类,并得到分类结果。
其中上诉步骤2和步骤3用Topology模型进行改进的模型图如图2所示,每个模块的具体描述如下:
(1)imageSpout为Spout组件的实现,主要工作是从预处理好的图像数据中读数据,并传递给下一级模块;
(2)siftBolt为Bolt组件的实现,该部分在接收到数据后,借助JavaCV库,执行提取图像的SIFT描述子的工作,生成特征点并传递给下一级模块,由于提取SIFT描述子是一项比较耗时的工作,siftBolt可以设置较高的并行度来提高效率;
(3)在得到训练集图像特征点后,输入initBolt模块,它是Bolt组件的实现,该模块进行初始化的操作。包括点群、聚类基点(C1,C2,...,Ck)及阈值的初始化,并传递到迭代模块的入口;
(4)receiver模块是Receiver组件的实现,是迭代的入口,接收到外部的输入后对输入数据排队处理,并发往下一级模块开始迭代;
(5)核心计算模块caldisIBolt是IBolt组件的实现,它接收receiver模块发来的数据,包括待聚类的特征点以及初始基点,计算读取的特征点与每个基点(C1,C2,...,Ck)之间的欧式距离,并将特征点标记到距离最近的基点,最后将确定了标记类别ID的特征点发往相应类别ID的下一级模块;
(6)核心计算模块moveIBolt是IBolt组件的实现,不同类别ID的moveIBolt模块接收相应标记类别ID的特征点形成点群簇,累加点个数及各分量的和,计算出分量的均值,求出新的簇中心,并更新基点到簇中心,最后输出新的基点与点群作为数据发往下一级模块;
(7)checker模块是Checker组件的实现,首先,它接收moveIBolt模块发来的数据,保留接收到的基点,作为下一次比较的对象,与下一次从moveIBolt模块接收的基点做比较,以确定是否把点群和基点发回receiver,进行下一次(4)~(6)的处理过程;然后,当checker模块中接收到的基点与上一次的基点相比,若变化小于阈值时,迭代结束,将基点发往dictionaryBolt模块,它是Bolt组件的实现,用于保存生成的聚类点。到此,就生成了图像的视觉词典。
本发明的分类效果可通过如下仿真进一步说明:
1.仿真内容:
本发明从公用数据集COREL和Caltech-256中选取了6个类别的自然交通场景图像进行图像分类,如图3中的(a)自行车、图3中的(b)公交车、图3中的(c)轿车、图3中的(d)跑车、图3中的(e)摩托车、图3中的(f)卡车所示,每类100张图像,每类选取其中50幅组成训练图像集,剩下的图像组成测试集。仿真1分析了不同的视觉单词数下本发明与传统方法的分类性能,分类结果如图4所示;仿真2为了测试Topology编程模型下,生成视觉词典的效率,分别选用COREL中50、100、150、200张图片,分别测试传统方法和改进方法在同样数量的图片数据下的执行时间。测试用的主机CPU为Inter(R)Core(TM)i5CPU M350@2.67GHz,内存为4GB,改进方法在Ubuntu10.04LTS上进行测试,所需的平台为Twitter公司提供的开源Storm框架,再增加相同配置的机器搭建Storm集群,板载Intel千兆网络,分别在伪分布式单机模式下、3台集群及5台集群下运行;传统方法在同样的单机条件下按步执行。在稳定状态下,取10次执行时间的平均值作为比较,结果如图5所示。
2.仿真结果:
图4显示在视觉词典的形成过程中,选取多大的词典数量才能使分类效果最佳,词典数值较大时,视觉单词直方图维数较高,运行复杂度高,词典数值较低时,并不相近的特征点聚类到一个中心,影响分类精度;随着k值增大时,不同方法的分类性能趋于稳定;通过突出同类图像的共有特征,本发明有更好的分类性能。
图5可以看出,基于Topology编程模型改进的生成视觉词典的方法的执行时间在图片数量不大时效率提升不明显,随着图片数量增大时,执行时间有了大幅度降低,且在集群下运行时,进一步降低了执行时间,实时效率有所提高。
- 还没有人留言评论。精彩留言会获得点赞!