一种基于变异回溯算法的数据识别方法与流程
本发明涉及一种数据识别方法,尤其涉及一种基于变异回溯算法的数据识别方法。
背景技术:
现有的日志数据识别主要有如下两种方案:
1、正则表达式数据识别,这个技术方案根据不同的数据日志,从该数据日志第一个字符进行正则表达式编写,基于这个基础,根据需求编写出不同的格式正则表达式,即候选匹配正则表达式。数据日志匹配不同候选正则表达式,判断该正则表达式是否匹配,如果匹配成功,识别相应的字段,否则继续匹配下一个正则表达式,直到匹配到所有的候选的正则表达式。
2、切割符识别,这个技术方案根据所选字符(切割符)进行切割,在所在的数据日志寻找是否存在切割符,如果找到,那么就在该处将数据日志切开,前面的数据作为一个字段信息,之后继续寻找下一个切割符;如果找到,进行相同的操作,直到数据日志的结束。当数据日志寻找结束位置,数据识别就完成。
现有技术的缺点在于,正则表达式匹配数据识别,根据不同的数据日志,不同的需求编写不同的正则表达式,而且在编写正则表达式,往往编写的正则表达式比较长,复杂,阅读起来困难,如果在已存在的正则表达式进行修改,将是一件耗时耗力的工作,而且在进行匹配过程,如果正则表达式无法匹配,匹配速度非常慢,导致整个识别过程非常耗时。切割符识别,对于按照某个分隔符形成有规则的数据日志,而且每次切割出来的字段信息都是完整,如果不存在这个规则,那么使用切割符进行切割将会得到无用字段信息。
技术实现要素:
本发明所要解决的技术问题是提供一种基于变异回溯算法的数据识别方法,识别速度快,易于添加新的规则,且不需要编写不同的格式正则表达式,就能识别各种无规则的数据。
本发明为解决上述技术问题而采用的技术方案是提供一种基于变异回溯算法的数据识别方法,包括如下步骤:a)预选分词符对数据样例进行切割,并将切割后的分词作为最小的匹配单元;b)对切割后的分词选择不同的编码方式进行编码;c)根据每一个分词在数据样例中的出现顺序形成匹配路径,并构建匹配树;d)输入日志数据进行分词,获取每一分词存在的编码方式,通过回溯匹配树进行数据识别。
上述的基于变异回溯算法的数据识别方法,其中,所述步骤a)预选空格作为分词符对数据样例进行切割。
上述的基于变异回溯算法的数据识别方法,其中,所述步骤b)对切割后的分词根据分词属性值中的编码方式得到该分词的编码值,所述分词属性值中的编码方式包括全匹配编码、ASIIC码顺序匹配编码、特征符号编码、任意词匹配编码、目标字符匹配编码以及词跳跃匹配编码。
上述的基于变异回溯算法的数据识别方法,其中,所述步骤c)遍历每一个分词的编码方式,计算编码值,每一个分词的编码值及其编码方式对应一个节点编码,不同节点编码之间根据对应的分词关系确定父子节点,所有节点编码存储在节点编码库中并形成一棵树或者树中的一条分支,或者树中的一条路径。
上述的基于变异回溯算法的数据识别方法,其中,所述步骤d)将待识别的日志数据进行分词后,对每一分词按所有可选的编码方式分别进行编码,并在节点编码库查询每一次的编码结果,如果存在,那么该编码作为候选的编码,如果该编码不存在,那么使用下一种编码进行编码,直至获得每一个分词的所有候选的编码方式。
上述的基于变异回溯算法的数据识别方法,其中,所述步骤d)通过如下步骤回溯匹配树进行数据识别:d1)获取根节点编码值;d2)判断节点是否存在子节点,如果不存在子节点,则跳到步骤d4);d3)如果存在子节点,获取下一个编码值,查看该属性值是否可作为父子节点,如果存在,那么返回步骤d2),如果不是父子关系,则跳到步骤d5);d4)判断该节点是否可作为叶子节点,如果可以作为叶子节点,则该回溯匹配结束,返回匹配到的一条完整的路径,如果不可以,回溯到上一个节点;d5)如果节点编码方式是目标寻找,那么跳到步骤d6),如果节点编码方式是跳跃寻找则跳到步骤d7),如果节点编码方式为任意词,返回步骤d2);d6)遍历后面的所有词的字符串值,查看是否存在该目标,如果存在返回步骤d2),不存在则回溯到上一个节点;d7)遍历后面的所有编码,查看是否存在该编码,如果存在返回步骤d2),不存在则回溯到上一个节点。
本发明对比现有技术有如下的有益效果:本发明提供的基于变异回溯算法的数据识别方法,通过分词,编码,获取候选编码,再进行回溯的匹配,在回溯的匹配过程,同时根据编码的不同编码方式可以匹配多种规则;利用分词作为最小的匹配单元,识别速度快,易于添加新的规则,且不需要编写不同的格式正则表达式,就能识别各种无规则的数据。
附图说明
图1为本发明基于变异回溯算法的数据识别流程示意图;
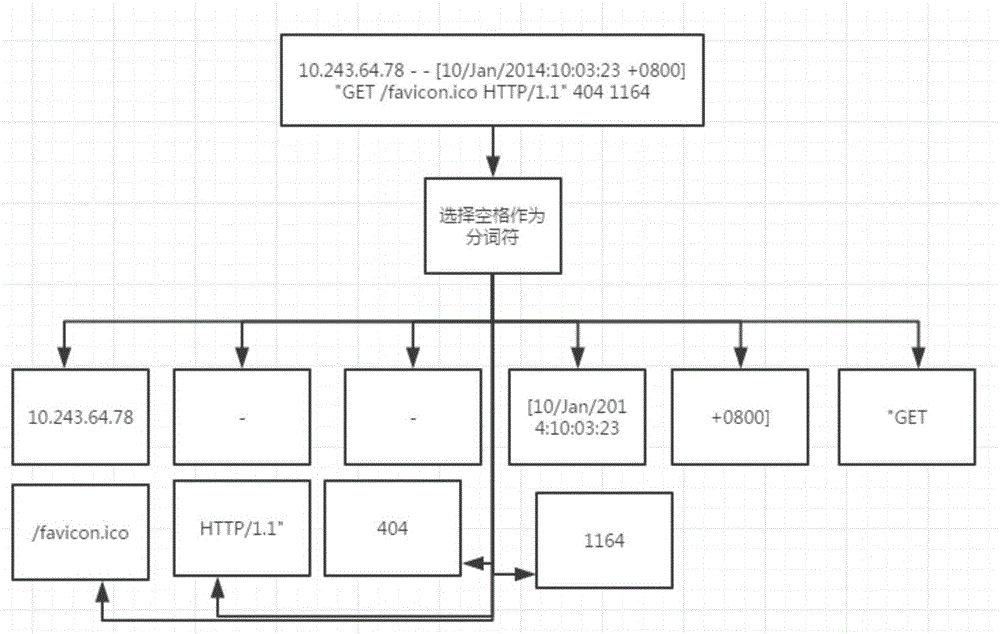
图2为本发明选定分词符后按规则分词示意图;
图3为本发明对分词按不同编码方式进行编码示意图;
图4为本发明获取每一分词的编码值及其编码方式形成编码节点示意图;
图5为本发明确定不同分词对应的编码节点之间父子关系示意图;
图6为本发明根据每一分词对应的编码节点构建匹配树示意图;
图7为本发明基于变异回溯算法的数据识别匹配示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图1为本发明基于变异回溯算法的数据识别流程示意图。
请参见图1,本发明提供的基于变异回溯算法的数据识别方法,包括如下步骤:
步骤S1:预选分词符对数据样例进行切割,并将切割后的分词作为最小的匹配单元;如预选空格或者其他符号为分词符;
步骤S2:对切割后的分词选择不同的编码方式进行编码;
步骤S3:根据每一个分词在数据样例中的出现顺序形成匹配路径,并构建匹配树;
步骤S4:输入日志数据进行分词,获取每一分词存在的编码方式,通过回溯匹配树进行数据识别。
本发明提供的基于变异回溯算法的数据识别方法,不同于传统回溯算法,通过规则的输入,而这些规则是可自定义,根据定义的规则,对规则的数据样例进行分词,而通过自定义分词符号分词,每一个词是最小的匹配单元,而每一个词有可以使用不同的编码方式,从而同一个词可以使用不同的编码方式,表示不同的意思。编码方式是,从精确匹配到模糊匹配,模糊度表示可以匹配的程度。对一个词进行不同的编码后,相当是一个唯一的整数表示,根据每一个词在数据样例的出现的顺序形成的匹配路径,而这个路径就是一个树的结构。根据数据样例的每一个词存在父子的关系,前面的词是后面的词的父节点或者祖先节点,自然后面的词就是前面词的子节点。这样就形成一个可以遍历的树中的一条路径。如果在这个规则不断添加,那么这棵树分支会越来越多,匹配的规则会越来越多,即树可达的路径越多。
匹配过程,日志数据输入后,根据分词符进行分词,分为最小的匹配单元,根据多种编码方式,对每一个词查询匹配树节点的值,如果存在编码的值,那么该词作候选匹配节点。如此类推,将每一个词可以存在的候选节点保存。依次遍历每一次词的每一个可以候选的节点,当遍历所有词之后,如果存在这样的路径,相应就匹配树中的其中的一路径,而该树的一路径保存相应的信息,从而识别出该日志数据。
本发明提供的基于变异回溯算法的数据识别方法,具有如下特点:1)定义规则简单,在定义规则过程,不需要编写不同的格式,只需要将数据日志配置到相应的规则下,根据数据日志生成一棵树中的一条可达的路径。2)识别速度快,可以根据日志快速定位到该数据日志是属于那一个条规则,寻找到规则,进行快速的识别。3)识别各种无规则的数据,可以将无规则数据中的某一个部分或者某段数据段作为规则,而且该部分或者段数据是存在一定的规则。4)自学能力,添加新的规则,该规则单独形成一个颗树,或者是某一颗树的一条可达的路径,规则添加越多,形成树的越来越多,构造的森林越大,识别能力越来。下面对本发明基于变异回溯算法的数据识别的主要步骤作出进一步展开描述。
1、规则分词
将规则日志输入,选定分词符,形成最小的匹配单元,具体形成过程如图2所示。
2、词编码
请继续参见图3,本发明遍历所有的词,根据的每一词的属性值中的编码方式,选择不同的编码方式,从而得到词的编码值。其中,c1编码是使用编码m2,c2使用编码m1,c3使用编码m2,c4使用m2,c5使用编码m2,c6使用编码m6,c7使用编码m2,c8使用编码m1,c8使用编码m1,如图4所示。
3、构建匹配树
请继续参见图5,本发明通过遍历每一个编码方式,计算编码与编码之间的关系,形成一棵树或者树中的一条分支,或者树中的一条路径。如图6所示,其中的编码c10和c11是为了形成多个分支而添加,为了在后面寻路时使用。
4、获取所有候选节点
将待识别的日志数据(例如10.243.64.78--[10/Jan/2014:10:03:23+0800]"GET/favicon.ico HTTP/1.1"404 1164)进行分词后,每一次进行对应的m1,m2,m3,m4,m5,m6的编码,将每一次的编码的结果在节点编码库查询,如果存在,那么该编码作为候选的编码,如果该编码不存在,那么使用下一种编码进行编码,如此类推,最后获得每一个词的所有候选的编码方式,以便回溯匹配时使用。如例子所有的候选编码是c1,c2,c2,c3,c4,c5,c6,c7,c8,c8。
5、回溯匹配
本发明提供的变异回溯匹配过程如下:
d1)获取根节点编码值,例如图7中的n1;
d2)判断节点是否存在子节点,如果不存在子节点,进行d4)。
d3)存在子节点,获取下一个编码值,查看该属性值是否可以作为父子节点,如果存在,那么继续进行d2),例如图7中的n2,n3如果不是父子关系,进行d5);
d4)判断该节点是否可以作为叶子节点,如果可以作为,那么该回溯匹配结束。匹配到一条完整的路径,例如图7中的n4,n5,n6,n7,如果不可以,回溯到上一个节点
d5)如果关系是目标寻找,那么进行d6),如果关系是跳跃寻找进行d7),如果关系任意,返回d2);
d6)遍历后面的所有词的字符串值,查看是否存在该目标,如果存在返回d2),不存在,再回溯到上一个节点;
d7)遍历后面的所有编码,查看是否存在该编码,如果存在返回d2),不存在,再回溯到上一个节点。
具体以图6中的样例为例,变异回溯匹配过程:
(1)获取根节点c1(10.243.64.78),根据节点有子节点(c2),进行(2);
(2)获取下一个节点c2(-),存在子节点(c2),进行(3);
(3)获取下一个节点c2(-),存在子节点(c3),进行(4);
(4)获取下一个节点c3([10/Jan/2014:10:03:23),存在子节点(c4),进行(5);
(5)获取下一个节点c4(+0800]),存在子节点(c5),进行(6);
(6)获取下一个节点c5("GET),存在子节点(c10,c6),进行(7);
(7)获取下一个节点c10,不是父子关系,该路径不是完整的路径。回溯到(6),进行(8);
(8)获取下一个节点c6(/favicon.ico),存在子节点(c6),该节点跳跃编码,获取下一个节点c7(HTTP/1.1"),进行(9);
(9)获取下一个节点c8(404),存在子节点(c8),进行(10);
(10)获取下一个节点c8(41164),不存在子节点,该节点也是叶子节点,回溯匹配结束。
本发明提供的基于变异回溯算法的数据识别方法,日志数据规则按照分隔符进行分词,转换成最小的匹配单元;每一个词都对应六种编码的一种或者多种,形成不同的编码进行匹配,根据多条规则可以构建一棵匹配树或者多棵匹配树,最后通过变异回溯匹配算法,即通过分词,编码,获取候选编码,再进行回溯的匹配,在回溯的匹配过程,同时根据编码的不同编码方式,可以使用传统的回溯算法,也可以使用目标性寻找,或者跳跃性寻找,或者任意匹配,从而遍历出一条匹配的路径。经过该过程后,可以匹配多种规则,从而达到数据识别的作用。具体优点如下:1)配置规则简单,相对正则表达式,不需要根据不同的规则编写不同的复杂的正则表达式,修改规则相对简单,只要找到对应每一个词的属性值,进行修改即可。2)匹配速度快,寻找到对应的树时间复杂是O(1),之后对树的中每一个分支进行匹配,匹配其实就是整数匹配,所以匹配每一个节点时间复杂是O(1)。如果寻找到,那么立即结束该词寻找。在寻找过程中可以根据节点的属性信息进行特殊的操作,也会匹配更快。3)自学规则,随着规则不断的添加,形成的树也会随之增多,或者树会越来越大,导致分支越多,匹配的路径也随之增多,从而形成自学规则的效果。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!