基于新统计的词汇语义相似度求解算法的制作方法
本发明涉及语义网络技术领域,具体涉及基于新统计的词汇语义相似度求解算法。
背景技术:
21世纪以来,全球互联网进入了一个高速发展的新时期,各种新技术不断涌现。作为联系计算机与人之间重要的自然语言处理技术也快速发展中。传统的语义相关度计算方法大致分为两类:基于语义词典的语义相关度计算方法以及基于语料库的语义相关度计算方法;语义相关度计算是自然语言处理领域非常重要的一项技术,它的用途很广泛,是自然语言处理领域一项基础性的研究工作。例如要识别“这个苹果很好吃”,通过语料库检索得到相似的翻译有“这个梨子很好吃”、“这个人很好吃”。这里涉及一个歧义问题,前一个“好”的意思是很好,读音为三声,后一个“好”为四声,所以第一个翻译更合适。为了处理未登录词的语义相似度问题,同时鉴于词汇语义相似度计算在自然语言处理中的重要作用,本发明提出了一种基于新统计的词汇语义相似度求解算法。
技术实现要素:
针对于词语中的相似度问题,本发明提出了基于新统计的词汇语义相似度求解算法。
为了解决上述问题,本发明是通过以下技术方案实现的:
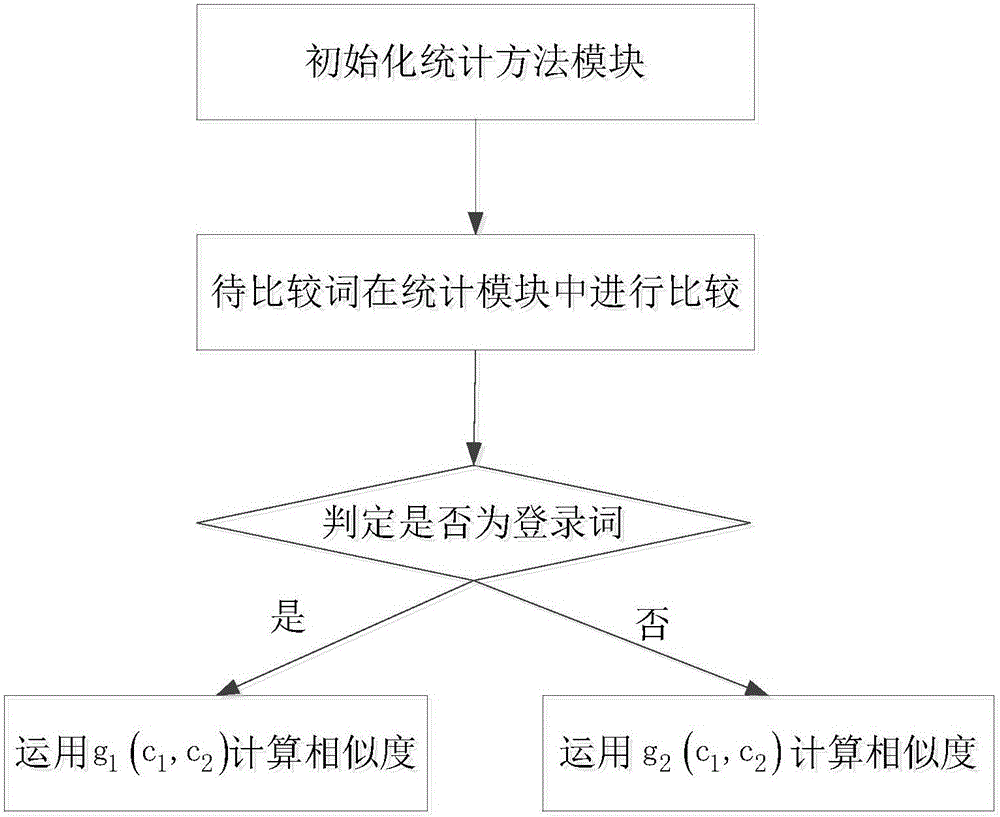
步骤1:初始化统计方法模块,这里可以是《词语字典》、《词林》、知网、《百度百科》等等语料库。
步骤2:将待比较词(c1,c2)输入初始化统计方法模块中。
步骤3:在统计模块中判断其(c1,c2)是否为登录词。
步骤4:如果为登录词,运用特定算法g1(c1,c2)实现词汇之间相似度的求解。
步骤5:如果为未登录词,运用相关特定算法g2(c1,c2)实现词汇之间相似度的求解。
本发明的有益效果是:
1、比较传统的语义分析方法,此计算得出的精确度更高。
2、在消除歧义方面有更好的效果。
3、更符合用户需求。
4、对未登录词具有更好的识别和判定效果。
附图说明
图1为基于新统计的词汇语义相似度求解算法的结构流程图。
具体实施方式
为解决词语(c1,c2)之间语义相似度问题,将结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:初始化统计方法模块,这里可以是《词语字典》、《词林》、《知网》、《百度百科》等等语料库。
步骤2:将待比较词(c1,c2)输入初始化统计方法模块中。
步骤3:在统计模块中判断其是否为登录词。其具体判定过程如下:
步骤3.1)先计算出(c1,c2)在选定的语料库中的权重值w(c1)、w(c2),这里我们根据其上下文词分别与目标词c1、c2共现的频数nf(c1)、nf(c2),上下文词的根据约束条件查找,例如,在汉语中,具有比较强的上下文约束关系的词性对有:形容词-名词、动词-名词、名词-动词、形容词-动词等等。当满足下列条件即为登录词:
(1)nf(c1)>α
(2)nf(c2)>α
α为领域专家给定的一个权重阈值,当频数nf(c1)、nf(c2)都满足用户给定的条件,即两词语(c1,c2)都为登录词,当条件1成立条件2不成立时,则词语c1为登录词,依此,同理可知其他情况。
步骤4:如果(c1,c2)为登录词,运用特定算法g1(c1,c2)实现词汇之间相似度的求解,需先求解(c1,c2)与上下文词的共现向量、上下文词分别与目标词(c1,c2)共现的概率f(c1)、f(c2)以及分别找到(c1,c2)与上下文词的最大共现向量,步骤4的具体求解过程如下:
步骤4.1)先计算(c1,c2)与上下文词的共现向量如下:
上式(x1,x2,…,xn)分别为与目标词c1共现的上下文词,(y1,y2,…,yn)分别为与目标词c2共现的上下文词,fi(c1)为xi与c1在上下文中共现的概率,同理fi(c2)为yi与c2在上下文中共现的概率。
步骤4.2)其上下文词分别与目标词(c1,c2)共现的概率f(c1)、f(c2)。
根据上述步骤4.1,可推出如下:
f(c1)=max[(f1(c1)),(f2(c1)),…,(fn(c1))]
f(c2)=max[(f1(c2)),(f2(c2)),…,(fn(c2))]
步骤4.3)最后分别找到目标词(c1,c2)最匹配的上下文词最大向量如下:
上式最大向量是分别根据概率f(c1)、f(c2)的值得来的。
步骤4.4)两词语g1(c1,c2)相似度计算,根据上述步骤4.3可推出下列表达式:
步骤5:如果为未登录词,运用相关特定算法g2(c1,c2)实现词汇之间相似度的求解。
这里可以应用上下文词的停用词表来确定两词汇间的相似度,由于停用词的分布与语义无关,根据上下文停用词找到两相似度最大的两个向量。
分别查找上下文中与目标词(c1,c2)搭配的停用词,找到共有停用词数最多的两个向量根据这两个向量在语料库中的权重值可分别知道两个向量的值,再根据下式求目标词(c1,c2)的相似度g2(c1,c2):
基于新统计的词汇语义相似度求解算法,其伪代码计算过程:
输入:待比较词(c1,c2),语料库,领域专家给定阈值α以及停用词表。
输出:待比较词(c1,c2)之间的语义相似度。
- 还没有人留言评论。精彩留言会获得点赞!