一种结合用户评论内容和评分的项目推荐方法与流程
本发明涉及项目推荐方法,具体是一种结合用户评论内容和评分的项目推荐方法。
背景技术:
随着Web2.0以来,互联网上的信息以指数级的数量增长,面对海量的数据,用户明显感觉到很难从中发现自己真正感兴趣的内容,于是推荐系统变得越来越不可或缺。我们可以依靠推荐系统从音乐流媒体服务平台(例如网易云音乐)中收藏的上百万首歌曲中发现自己喜欢的歌曲;我们也可以依靠推荐系统从新闻网站(例如腾讯新闻)中发现自己感兴趣的新闻。淘宝等购物网站使用推荐系统向用户推荐他们可能喜欢的商品。
虽然推荐系统在互联网的很多领域表现良好,但是现有的方法仍然存在不足之处。其中一个不足之处在于大多数推荐系统都不能很好的处理冷启动问题,冷启动问题指的是当推荐系统中存在新用户时,由于系统中缺少新用户足够的历史行为信息,这样就导致推荐系统不能很好的给新用户做出满意的推荐结果;同样,对于新项目推荐系统也不能及时的推荐给用户。冷启动问题在导致推荐系统对新用户和新项目的体验不好。另外一个问题是现有的推荐系统的可解释性差,它们不能更加深入地学习用户的偏好以及项目的属性。例如在矩阵分解方法中,我们学习对应用户潜在特征和项目潜在特征的两个特征向量。两个潜在特征向量的点积大小表示用户是否喜欢这个项目。但是这些潜在的特征值很难同用户真实的评价联系起来。例如一个用户可能喜欢某个项目由于两个特征向量的某个特征值同时对应的值比较大,当推荐系统给用户推荐这个项目时,很难用真实的物理意义解释说明给用户,做出相应推荐的原因。如果项目是一 部科幻题材的电影,是否意味着用户喜欢科幻电影或者用户仅仅因为喜欢电影的男主角而喜欢呢?我们无从得之。事实上把潜在向量的每一个特征值都对应于一个真实的物理意义是很困难的。
推荐系统中预测用户的偏好是通过学习用户对项目的历史评分得到的,它的思想是假设过去有相似偏好的用户在未来也有相似的偏好,推荐系统对用户进行建模仅仅用到用户的评分信息而没有考虑评论的内容。在实际的推荐系统中,用户不仅有对项目的评分值,而且有对项目的评论。评论中包含了丰富的信息解释了用户对这个项目的评分值是某个确定值的原因。这些评论提供了项目的内容,可以用来缓解当用户评分很稀疏时的冷启动问题。这是因为评论内容中包含的信息比一个评分值丰富很多,当系统中的评分数据很稀疏时,推荐系统几乎不可能学习到用户或者项目的特点。然而文本的评论内容却可以更好的估计用户偏好或者项目的内容。在早期的研究中,研究者们也意识到在推荐系统中使用文本内容的优点,于是在基于内容过滤和基于协同过滤的组合中做了大量的工作,研究者们发现有很多特征影响用户对项目的评分,他们利用文本的评论内容学习用户在这些特征上的权重分布,然而他们的方法需要有经验的专家预先定义这些特征。而且这样选择的特征也有很大的随机性,如果特征选择的不好,导致系统不能正确的学习用户的偏好。
技术实现要素:
本发明的目的在于克服上述项目推荐现有方法中存在的问题和不足,提供一种结合用户评论内容和评分的项目推荐方法,通过基于用户评论内容的过滤和基于评分的协同过滤自动学习这些特征,从而解决上述问题。同时为了解决可解释性问题,把评分的潜在主题空间维度和评论内容的主题空间维度进行了一致排列,这样每一个评分的潜在主题的维度都可以用评价的关键词的标签来 解释,标签解释了评分对应维度的真实物理意义。
为实现本发明目的,本发明一种结合用户评论内容和评分的项目推荐方法,其中评分用基于矩阵的方法进行潜在特征分解,用户评论的内容用LDA方法进行建模,项目推荐方法包括以下步骤:
步骤1:从互联网中采集用户数据并对其进行预处理,生成用户行为数据存放到用户行为信息数据库;
步骤2:通过分析用户的历史行为数据,构建用户对项目偏好评分以及评论的标签,并将数据划分为训练集和测试集;
步骤3:基于训练集构建用户-项目的偏好评分矩阵;
步骤4:利用训练集中用户对项目的评论内容构建LDA模型;
步骤5:构建映射函数,使基于评分的矩阵分解方法和基于评论的LDA模型方法有效地联系起来;
步骤6:通过设置一个超参数μ来平衡评分数据和评论数据对推荐的影响程度,得到推荐的模型表达式;
步骤7:训练步骤6中得到的模型,利用测试集得到的不同的超参数μ中的推荐误差,绘制不同超参数μ得到的误差曲线;
步骤8:从误差曲线中选择出最优的误差曲线对应的超参数μ,得到最优的预测推荐模型;
步骤9:基于最优超参数μ,对推荐系统中出现的用户项目集,按照步骤8的模型对目标用户计算他对某个待推荐项目的评分,当评分大于设定的阈值时,系统就把该项目推荐给用户。
所述步骤1采集的数据至少包括用户唯一ID、项目唯一ID、用户对项目的评论内容、偏好评分以及用户对项目的行为时间的相关信息,存放于用户行为 信息数据库中。
所述步骤3中,用户-项目的偏好评分矩阵是利用矩阵分解方法的SVD算法得到的:
rec(u,i)=α+βu+βi+γu.γi (1)
其中,rec(u,i)表示用户u对项目i的预测评分,α表示预测基准,βu和βi表示用户u和项目i的评分偏移值,γu和γi表示用户和项目的潜在特征向量。
所述步骤4基于评论内容集构建的LDA模型为:
其中τ表示整个评论集,Nd表示一条评论中出现的词的数量,表示出现某个主题的可能性,ωd,j表示某个词描述某个主题的可能性。
所述步骤5构建的映射函数为:
其中θi表示项目i的主题分布,k控制转换函数的平滑,θi,k表示评论中讨论项目i的第k维特征,γi表示项目i的潜在特征向量,γi,k表示项目i的第k个潜在特征。
所述矩阵分解的潜在主题数量和评论内容的主题数量相等,事实上项目的潜 在特征向量γi和评论的主题分布θi不是相互独立的,从直观上我们可以认为γi描述了产品i的潜在特征,如果用户u喜欢这个产品,则用户相应的潜在特征向量γu上值就会大。另一方面,主题θi定义了项目i特定主题的词。通过连接二者,我们希望如果一个项目展示了某一个项目的潜在特征(对应于γi,k的值较大,θi,k表示评论中讨论项目i的第k维特征),则在评论中讨论了相应的主题(对应于θi,k的值较大,θi,k表示评论中讨论项目i的第k维特征)。
所述步骤6得到推荐的模型表达式为:
其中参数Θ={α,βu,βi,γu,γi},Φ={θ,φ},μ表示两种算法在整个模型中权重,α表示预测基准,βu和βi表示用户u和项目i的评分偏移值,γu和γi表示用户和项目的潜在特征向量,θ表示评论集的主题分布,φ表示主题中的词分布。
所述步骤7训练步骤6中得到的模型,开始训练利用构建的映射函数使项目的潜在特征向量γ和评论的主题分布θ相对应,因此Θ和Φ都依赖于潜在特征向量γ,训练(4)式的模型时两个部分不能独立。通常情况下单独训练(1)式中的各个参数可以利用梯度下降的方法,训练(2)式中的参数可以通过Gibbs Sampling的方法。因此我们可以通过交替这两个过程训练模型。
所述步骤7训练步骤6中得到的模型,(4)式的第一部分的训练首先通过平方误差最小化得到
其中T表示整个训练的评分数据集,Ω(Θ)表示模型复杂度的正则化;
然后,对(5)式运用梯度下降进行参数的训练,α一般是评分矩阵的平均值,其余各个参数的表达式为:
βu=βu+η(eu,i-λβu) (6)
βi=βi+η(eu,i-λβi) (7)
γu=γu+η(eu,i-λγu) (8)
γi=γi+η(eu,i-λγi) (9)
其中βu和βi的初值为0,γu和γi的初值为0向量,eu,i=(rec(u,i)-ru,i),η为梯度下降的步长,即学习率;
(4)式的第二部分LDA模型是采用Gibbs Sampling方法初始时随机给用户行为记录中的每个项目分配一个所隶属的潜在兴趣T(0),然后统计每个潜在兴趣T中项目的出现次数,以及每个用户中出现潜在兴趣T中项目的次数;每一次迭代依据Gibbs updating rule计算条件分布公式如下:
其中,分别是N×K、M×K维的矩阵,分别代表项目Ii被赋予潜在兴趣Tj的次数、用户Ui的所有项目中被赋予兴趣Tj的次数;N 为项目的个数,M为用户的个数,K为潜在兴趣的个数;T-i表示除当前项目外的其他所有项目的潜在兴趣赋值,Ui表示用户索引,Ii表示项目索引,·代表其他所有已知或可见的信息,α和β是超参数,需提前进行指定;排除当前项目的潜在兴趣分配,根据其他所有项目的潜在兴趣分配估计当前项目分配到各个潜在兴趣上的概率值,当得到当前项目属于所有潜在兴趣T的概率分布后,根据这个概率分布重新为该项目采样一个新的潜在兴趣T(1),以此类推,用相同的方式不断更新下一项目的待定状态,最终近似的计算公式如下:
θij即可认为是用户Ui在潜在兴趣Tj上的偏好概率值,φij可认为是潜在兴趣Tj在项目Ii上的概率权重值。
所述评估推荐模型的好坏用RMSE表示,其公式如下:
其中,P(rui)代表示用户u对项目i的预测得分,rui表示用户u对项目i的实际得分,N表示测试集的大小,RMSE值越小表示预测越精确。
本发明针对推荐系统中存在的冷启动问题和可解释性差问题,提出了基于结合用户评论和用户评分的模型,通过利用蕴含在评论中丰富的信息,我们可以极大的提高预测的精确度,尤其当数据很稀疏时,可以很好的解决冷启动和可解释性差的问题。本发明方法主要考虑到用户评论信息中包含了项目特征的描述,通过映射函数使数值评分中的潜在特征和评论信息的项目特征相对应。可以很好的对用户的喜好进行建模,因此即使数据很稀疏时,也能很好的进行预测和推荐。
附图说明
图1为本发明项目推荐方法流程图;
图2为基于用户评论内容构建LDA模型图;
图3为实施例亚马逊商品的评分和评论单词数的百分比图;
图4为实施例在亚马逊数据集上本发明方法和其它算法预测评分的均平方误差图。
具体实施方式
下面结合附图和实施例对本发明内容作进一步详细说明,但不是对本发明的限定。
参照图1,一种基于用户评论内容和评分的项目推荐方法,包括如下步骤:
ST1:从互联网中采集用户数据并对其进行预处理,生成用户行为数据存放 到用户行为信息数据库;
ST2:通过分析用户的历史行为数据,构建用户对项目偏好评分以及评论的标签,并将数据划分为训练集和测试集;
ST3:基于训练集构建用户-项目的偏好评分矩阵;
ST4:利用训练集中用户对项目的评论内容构建LDA模型;
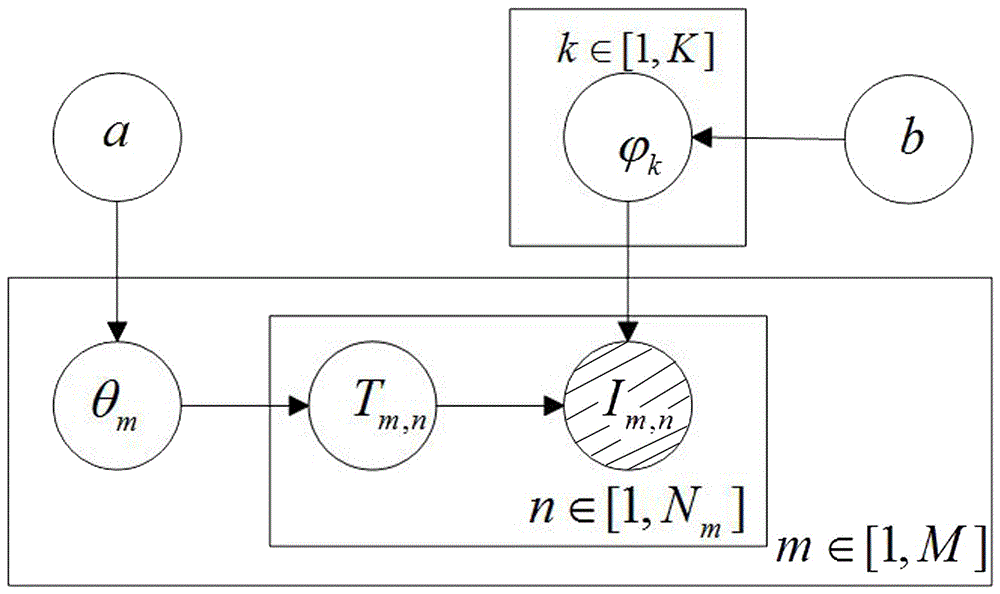
LDA模型参考图2,其中所有空白圆表示不可预知的隐藏变量,而阴影圆则代表可观察变量,每个矩形代表着步骤的重复。θm表示第m个用户的兴趣概率分布,φ表示兴趣中的项目概率分布;k代表预先设置的兴趣数目,M代表系统的中用户数目,Nm表示第m个用户产生行为的项目个数。Im,n和Tm,n分别表示第m个用户行为记录中的第n个项以及该项目所属兴趣。α和β是整个模型的两个超参数,α反映了用户行为项目集合中兴趣的相对强弱,β则反映了兴趣中项目的概率密度;
ST5:构建映射函数,使基于评分的矩阵分解方法和基于评论的LDA模型方法有效地联系起来;
ST6:通过设置一个超参数μ来平衡评分数据和评论数据对推荐的影响程度,得到推荐的模型表达式;
ST7:训练步骤6中得到的模型,利用测试集得到的不同的超参数μ中的推荐误差,绘制不同超参数μ得到的误差曲线;
ST8:从误差曲线中选择出最优的误差曲线对应的超参数μ,得到最优的 预测推荐模型;
ST9:基于最优超参数μ,对推荐系统中出现的用户项目集,按照步骤8的模型对目标用户计算他对某个待推荐项目的评分,当评分大于设定的阈值时,系统就把该项目推荐给用户。
采用本发明方法,当我们观察到一个用户对一部电影的评价内容是“恐怖片、科幻、诺兰”,而且该用户对电影评分进行矩阵分解可以发现在这三个维度上的值都比较大。由此我们知道该用户喜欢克里斯托弗·诺兰执导的科幻类的惊悚电影。
可解释性和冷启动的问题不是两个孤立的问题,我们可以通过学习一个可解释性的模型来缓解冷启动的问题,我们可以充分利用用户对项目的历史评论中已知的信息,给用户推荐新的项目。例如一个用户给电影《月光宝盒》很高的评分,并且该用户给电影评价的标签是“爱情、喜剧、周星驰”。则可解释模型的推荐系统可以确信的给用户推荐《美人鱼》即使这部电影还没有公映,而传统的推荐系统在《美人鱼》刚公映时存在冷启动的问题。
实施例
参照结合用户评论内容和评分的项目推荐方法,用亚马逊的商品评论数据集进行验证,从亚马逊的商品中随机选取了5个类别,分别是珠宝、艺术品、手表、软件和汽车。这些数据的特点每种商品的用户评分很稀疏,但是都有用户对其的评论。如图3所示。
参数预估:
本实施例中,α为每类商品的评分的均值,βu和βi表示用户u和项目i的评分偏移值,这里初始都为0;γu和γi表示用户和项目的5维潜在的 特征的随机向量,并且5维向量相加为1,学习率η为0.05;控制映射函数平滑程度k为0.02,其中迭代次数默认为150。如图4所示描述了将数据集分成4:1的训练集和测试集的情况下,本发明提出的方法和其它算法在亚马逊数据集上预测评分的均平方误差(13)如图4。其中RMSE数值越小,代表性能越好。由图中我们可以清楚地发现,本发明方法中提出的算法确实在数据稀疏的情况下提高系统推荐性能上有很大的意义。
- 还没有人留言评论。精彩留言会获得点赞!