一种基于全卷积网络的非限制场景中运动目标快速分割方法与流程
本发明涉及一种基于全卷积网络的非限制场景中运动目标快速分割方法,属于视频对象分割技术领域。
背景技术:
随着多媒体技术的发展,视频内容为我们提供了丰富而全面的信息,然而,原始视频往往含有的信息量非常巨大,其中大部分信息对于具体的行业应用是没有意义可言,因此,如何从视频中提取到有意义的信息来服务于人们的生活和工作就成为一个与实际应用紧密相关的重要问题,例如:在交通监控视频中使用视频对象分割技术将运动目标信息提取出来。
目前利用图像处理来实现视频对象分割方法和产品在国内已经拥有比较成熟的产品和专利。如北京航空航天大学研究人员于2009年发明了一种基于时域定区间记忆补偿的视频对象分割方法,该发明公开了一种基于时域定区间记忆补偿的视频对象分割方法,这是一种新的并行时空融合自动分割方法,它的提出有效地解决了时空融合时经常出现的视频对象内部缺失严重以及采用帧差检测运动区域时不可避免的遮挡(覆盖/显露)问题,同时,在精确性、通用性和速度方面也有了较大的改善。北京航空航天大学研究人员于2012年发明了一套基于变化检测和帧差累积的视频对象分割方法专利,该发明公开了一种基于变化检测和帧差累积的视频对象分割方法,它的提出有效地解决了视频对象分割方法经常出现的对象不规则运动造成的视频对象内部缺失和背景显露。分割速度、分割效果、适用范围及可移植性均有了很大的改善。温州大学研究人员于2014年提出了一种基于遗传算法的视频对象分割方法,该发明公开了一种基于遗传算法的视频对象分割方法。通过VFW对视频进行捕捉并处理,获取视频中的图像帧;采用中值滤波对图像帧内在的噪声进行处理;通过遗传算法寻找参量空间的全局最优分割阈值,将视频对象与视频背景进行分离。用户可以做到在导入一个本地视频之后,在用户的控制下,自动将该视频分成若干帧,并检测该视频中的前景物体,然后对每一帧中的前景物体较为完美地提取出来,再将提取出来的物体自动粘贴至用户所指定的目标背景中去,并将合成的结果在本地输出。但上述方法对于目标本体局部不运动部分分割效果都不能达到最佳,且自动化程度不够。
本发明由国家自然科学基金项目(No.61461022和No.61302173)资助研究,主要在于探索运动背景下对目标的分割算法,解决了对准确移动的背景、任意物体的运动和表观以及非刚体变形和关节运动分割难题,为动态场景下高效、准确、准确的前景目标信息检测与分割提供理论依据。
技术实现要素:
本发明提供了一种基于全卷积网络的非限制场景中运动目标快速分割方法,以用于解决对准确移动的背景、任意物体的运动和表观以及非刚体变形和关节运动的视频中的运动目标对象实现分割的难题,为动态场景下高效、准确的前景目标信息检测与分割提供理论依据,从而高效、准确地获取视频中运动目标的信息,提高对视频内容的解读和信息的获取。
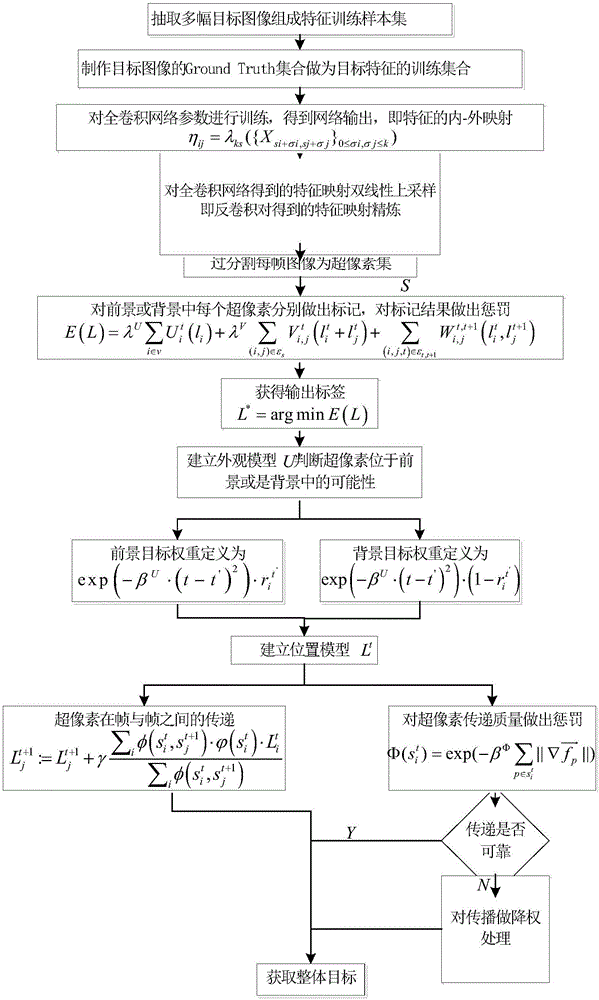
本发明的技术方案是:一种基于全卷积网络的非限制场景中运动目标快速分割方法,首先,对视频进行分帧,利用分帧后的结果制作样本图像的Ground Truth集合S;采用通过PASCAL VOC标准库训练的全卷积神经网络对视频各帧中的目标进行预测,获取图像前景目标的深层特征估计子,据此得到所有帧中目标最大类间似然映射信息,实现对视频帧中的前景和背景的初步预测;然后,通过马尔科夫随机场对前景和背景的深层特征估计子进行精细化,从而实现对非限制场景视频中视频前景运动目标的分割。
所述方法的具体步骤如下:
Step1、对视频进行分帧,利用分帧后的结果制作样本图像的Ground Truth集合S,采用通过PASCAL VOC标准库训练的全卷积神经网络对视频各帧中的目标进行预测,获取图像前景目标的深层特征估计子,据此得到所有帧中目标最大类间似然映射信息,将视频前景和背景分别标记为0、1,实现对视频帧中的前景和背景的初步预测;
Step2、通过马尔科夫随机场对前景和背景的深层特征估计子进行精细化,建立外观模型和位置模型,融合所有帧中目标最大类间似然映射信息在所有帧中分割目标;
Step3、循环步骤Step1至Step2,直至完成视频中的运动目标分割。
所述步骤Step1中,建立全卷积网络,获得各自图像帧的最大类间似然映射信息(即各自图像帧的内-外映射信息)步骤如下:
Step1.1、对目标视频进行分帧处理,获取具有运动目标的视频帧,挑选目标的若干幅图像组成特征训练样本集,制作目标图像的Ground Truth集合,共同构成运动目标特征的训练集合S;
Step1.2、将VGG-16模型的最后三层,即全连接层用卷积层替换,构成全卷积网络,利用PASCAL VOC标准库训练全卷积网络;
Step1.3、将分好的视频帧作为网络输入,利用训练好的全卷积网络对视频帧中的目标进行预测,获取图像前景目标的深层特征估计子;其中,网络层的数据为h×w×d大小的数组,h、w为空间维度,d为图像的色彩通道,对于网络结构第一层,其输入为原始图像,h×w为图像大小,d为图像的色彩通道,对于网络的其它层,其输出为ηij=ξks({Xsi+i,sj+j}0≤i,j≤k),Xij是在指定层(i,j)处的数据向量,k为卷积核大小,s为降采样因子,ξks决定网络层的类型;
Step1.4、对全卷积网络得到的特征映射双线性上采样即反卷积对得到的特征映射精炼,在网络结构浅层处减小上采样的步长,得到精炼层的特征映射,将其同网络高层得到的粗略层的特征映射融合得到新的一个特征映射层,再次做上采样得到新的精炼特征映射输出。
所述步骤Step2中,将视频帧每一帧过分割为超像素,并为超像素建立表观模型和位置模型,结合所有内-外映射在所有帧中分割目标步骤如下:
Step2.1、将视频帧过分割为超像素集合S,对超像素集合S中每个超像素赋予一个属于{0,1}的标签,分别为前景和背景,建立马尔科夫随机场能量函数对标签做出惩罚,优化标记结果:
利用图割法,得到将能量函数最小化的标签其中,Ut为一个一元项,它可以根据第t帧的外观模型估计一个超像素是前景或是背景的可能性,V,W为二元项,它们能够平滑空间和时间邻域,变量i∈V,V={1,2,...,n},λ为一权衡参数;
Step2.2、结合内-外映射利用交互分割法建立外观模型Ut自动估计前景和背景,外观模型包含两个在RGB空间内的混合高斯模型,其中一个为前景,另一个为背景,超像素位于前景和背景中的可能性,为所有超像素建立前景模型和背景模型,前景模型超像素的权重定义为背景模型超像素的权重定义为其中βU为时间上的权重,为超像素属于目标的百分比,反之为超像素不属于目标的百分比;
Step2.3、建立位置模型Lt降低背景颜色和前景颜色相似情况下对分割效果的影响,利用公式argmaxcηtp(i,j,c)建立最大类间位置似然,由ηtp(i,j,c)全连接网络预测层在上一个时刻t的输出,判断像素(i,j)处第c类目标的分类似然,结合最大类间位置似然内-外映射传播法建立位置先验,超像素通过光流传递从第一帧正向传播到最后一帧,超像素帧间传播t+1帧中的位置通过如下公式得到更新:由Φ判断传播质量是否可靠,对不可靠的传递作出惩罚进行降权处理;类似于上述过程,再将超像素通过光流从最后一帧反向传播至第一帧,最后将正向传播和反向传播两步归一化和,建立位置模型,其中,为连接权重,δ为更新速率,δ∈[0,1],为像素p的光流向量。
所述步骤Step1.2中全卷积网络层数为13层。
本发明的有益效果是:
(1)本发明克服了在复杂运动背景下,相比于其他算法对目标分割不完全的弊端,对获取的视频帧序列输入网络的每帧图像大小没有限制,不要求每帧图像都是同样尺寸;
(2)本发明所述方法提出利用全卷积网络对视频帧的语义区域进行预测,对所述类评分,取最高评分并排名确定目标类,从而获得种子点作为最大类间目标内-外映射信息,能够明显将目标从复杂背景当中分离出来;利用光流法建立外观模型和位置模型能够准确、高效、准确获取运动目标信息,实现对运动目标本体中局部不运动部分的分割。
(3)本发明用全卷积网络和视频分割方法能够有效地获取运动目标的信息,以实现对运动目标的高效、准确分割,提高视频前景-背景信息的分析精度。
附图说明
图1为本发明的方法流程图;
图2为本发明的算法流程图;
图3为本发明方法和其他方法分割结果对比图;
图4为本发明方法与其他方法的P/R曲线对比图。
具体实施方式
实施例1:如图1-4所示,一种基于全卷积网络的非限制场景中运动目标快速分割方法,首先,对视频进行分帧,利用分帧后的结果制作样本图像的Ground Truth集合S;采用通过PASCAL VOC标准库训练的全卷积神经网络对视频各帧中的目标进行预测,获取图像前景目标的深层特征估计子,据此得到所有帧中目标内-外映射信息,实现对视频帧中的前景和背景的初步预测;然后,通过马尔科夫随机场对前景和背景的深层特征估计子进行精细化,从而实现对非限制场景视频中视频前景运动目标的分割并通过Ground Truth集合S验证本方法的性能。
所述方法的具体步骤如下:
Step1、对视频进行分帧,利用分帧后的结果制作样本图像的Ground Truth集合S,采用通过PASCAL VOC标准库训练的全卷积神经网络对视频各帧中的目标进行预测,获取图像前景目标的深层特征估计子,据此得到所有帧中目标内-外映射信息,将视频前景和背景分别标记为0、1,实现对视频帧中的前景和背景的初步预测;
Step2、通过马尔科夫随机场对前景和背景的深层特征估计子进行精细化,建立外观模型和位置模型,融合所有帧中目标内-外映射信息在所有帧中分割目标;
Step3、循环步骤Step1至Step2,直至完成视频中的运动目标分割。
所述步骤Step1中,建立全卷积网络,获得各自图像帧的内-外映射信息步骤如下:
Step1.1、对目标视频进行分帧处理,获取具有运动目标的视频帧,挑选目标的若干幅图像组成特征训练样本集,制作目标图像的Ground Truth集合,共同构成运动目标特征的训练集合S;
Step1.2、将VGG-16模型的最后三层,即全连接层用卷积层替换,构成全卷积网络,利用PASCAL VOC标准库训练全卷积网络;
Step1.3、将分好的视频帧作为网络输入,利用训练好的全卷积网络对视频帧中的目标进行预测,获取图像前景目标的深层特征估计子;其中,网络层的数据为h×w×d大小的数组,h、w为空间维度,d为图像的色彩通道,对于网络结构第一层,其输入为原始图像,h×w为图像大小,d为图像的色彩通道,对于网络的其它层,其输出为ηij=ξks({Xsi+i,sj+j}0≤i,j≤k),Xij是在指定层(i,j)处的数据向量,k为卷积核大小,s为降采样因子,ξks决定网络层的类型;
Step1.4、对全卷积网络得到的特征映射双线性上采样即反卷积对得到的特征映射精炼,在网络结构浅层处减小上采样的步长,得到精炼层的特征映射,将其同网络高层得到的粗略层的特征映射融合得到新的一个特征映射层,再次做上采样得到新的精炼特征映射输出。
所述步骤Step2中,将视频帧每一帧过分割为超像素,并为超像素建立表观模型和位置模型,结合所有内-外映射在所有帧中分割目标步骤如下:
Step2.1、将视频帧过分割为超像素集合S,对超像素集合S中每个超像素赋予一个属于{0,1}的标签,分别为前景和背景,建立马尔科夫随机场能量函数对标签做出惩罚,优化标记结果:
利用图割法,得到将能量函数最小化的标签其中,Ut为一个一元项,它可以根据第t帧的外观模型估计一个超像素是前景或是背景的可能性,V,W为二元项,它们能够平滑空间和时间邻域,变量i∈V,V={1,2,...,n},λ为一权衡参数;
Step2.2、结合内-外映射利用交互分割法建立外观模型Ut自动估计前景和背景,外观模型包含两个在RGB空间内的混合高斯模型,其中一个为前景,另一个为背景,超像素位于前景和背景中的可能性,为所有超像素建立前景模型和背景模型,前景模型超像素的权重定义为背景模型超像素的权重定义为其中βU为时间上的权重,为超像素属于目标的百分比,反之为超像素不属于目标的百分比;
Step2.3、建立位置模型Lt降低背景颜色和前景颜色相似情况下对分割效果的影响,利用公式argmaxcηtp(i,j,c)建立最大类间位置似然,由ηtp(i,j,c)全连接网络预测层在上一个时刻t的输出,判断像素(i,j)处第c类目标的分类似然,结合最大类间位置似然内-外映射传播法建立位置先验,超像素通过光流传递从第一帧正向传播到最后一帧,超像素帧间传播t+1帧中的位置通过如下公式得到更新:由Φ判断传播质量是否可靠,对不可靠的传递作出惩罚进行降权处理;类似于上述过程,再将超像素通过光流从最后一帧反向传播至第一帧,最后将正向传播和反向传播两步归一化和,建立位置模型,其中,为连接权重,δ为更新速率,δ∈[0,1],为像素p的光流向量。
所述步骤Step1.2中全卷积网络层数为13层。
图3为本发明在自然非限制场景中运动目标分割应用的一个实例,前景目标分割结果用掩膜区域表示。前3列为当前先进的FOS、KS和DAGVOS三种方法的分割结果,最后一列是本专利方法分割结果。从定性分割结果来看,FOS算法没有检测到前景,KS算法检测到的前景位置不准确,DAGVOS算法检测精度较高,但第一帧中目标的腿部和第二帧图像中目标的尾巴部分没有检测到。最后一列本专利方法分割结果空间上能比较完整的分割目标,在时间跨度上前景目标也具有一致性。
图4为本发明在自然非限制场景中运动目标分割结果图3的定量评价,并与当前先进的FOS、KS和DAGVOS三种方法的分割结果进行定量对比。其中横轴为召回率,纵轴为精度,底纹线条为等高线。从定量分割结果来看,FOS算法和KS算法检测到的精度不高,曲线下面积(AUC)分别为44.12%和48.46%,DAGVOS算法检测精度较高,AUC精度为83.61%。本专利方法分割结果精度最高,AUC精度达到了88.74%。在定性和定量分析两个方面验证了本专利方法在非限制场景中运动目标准确分割的有益效果。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!