一种用于人脸识别的自适应冗余字典构造方法与流程
本发明属于人脸识别领域,尤其是当采用基于分类的稀疏表示算法时,涉及到的一种用于人脸识别的自适应冗余字典构造方法。
背景技术:
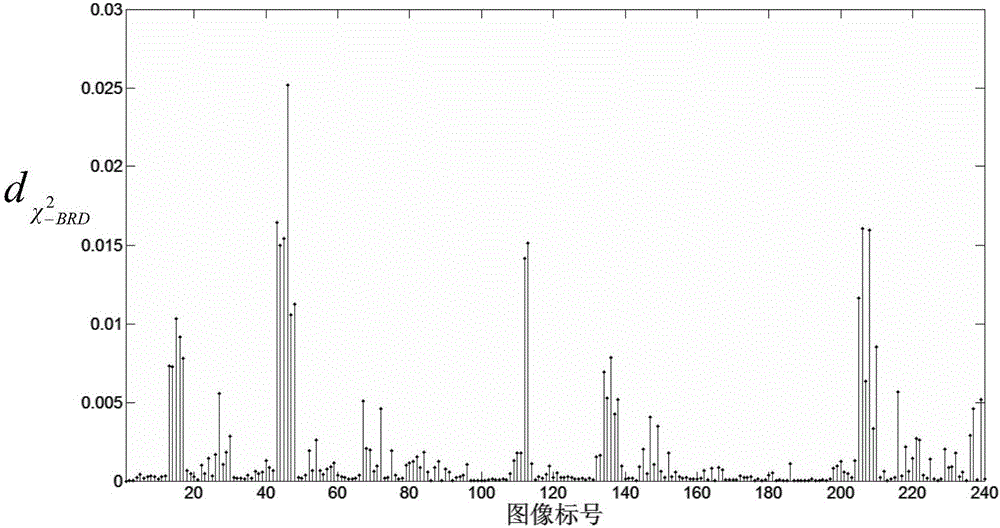
:人脸识别是利用人的面部图像进行身份识别的技术,在经济、民用、军用、公安等领域具有广阔的应用前景。稀疏表示利用过完备的冗余字典对输入测试数据进行最优线性表示,表示系数为稀疏矢量。基于分类的稀疏表示算法是利用稀疏表示矢量及各类训练样本分别对测试数据进行逐类重构并分类的一类算法。大量文献表明,基于分类的稀疏表示算法具有较高的正确识别率。人脸识别在本质上可看作是图像分类问题,因此基于分类的稀疏表示算法在人脸识别中得到了广泛研究。稀疏表示算法的核心问题包括冗余字典的构造和稀疏表示矢量的快速求解。后者可采用线性规划优化算法和贪婪算法两种较成熟算法,而冗余字典的构造依然是研究的重点内容。目前,在基于稀疏表示的人脸识别算法中,字典原子以全部训练样本为基础进行选择,冗余字典是固定不变的。假设有N幅m维的训练人脸样本,Yang等用全部训练人脸图像作为原子构造超完备冗余字典,字典原子数量为N。为了提高算法对遮挡的鲁棒性,Wright等引入m维的单位矩阵作为遮挡字典,对图像中的异常像素点进行单独编码,冗余字典的原子数量为(N+m),其中,N和m均为正整数。Huang等提出将图像在水平方向和垂直方向上的梯度也作为字典原子,可以解决了图像的对齐问题,字典原子数量为3N。为了满足冗余字典对原子的特征数量必须小于原子数量的要求,通常采用图像降维的方法将高维人脸图像投影到低维的特征空间,然后进行稀疏表示并分类。Yang等直接提取图像的低维Gabor特征,利用Gabor特征代替原始人脸图像作为字典原子。上述这些常用的冗余字典存在明显的不足。首先,通过增加原子数量提高表示矢量的稀疏度从而提高识别率,但是任何一种稀疏求解算法的计算速度都会随着原子数量的增大而下降。其次,对任何输入测试图像来说,冗余字典均为固定不变的,不具有自适应性。技术实现要素:为了解决现有技术的缺点,本发明提供一种用于人脸识别的自适应冗余字典构造方法。本发明在局部构造模式(LCP)特征空间选择图像的近邻,用近邻人脸图像作为原子构造字典,原子结构与测试图像具有更高的相似性,同时能够减少字典原子的数量;利用这种自适应的冗余字典对测试图像进行稀疏表示分类时,能够同时提高识别速度和正确识别率。本发明首先判断测试图像的合法性,分别在LBP和MiC层判断测试数据的合法性,当LBP特征和MiC特性均属于合法特征时,才判断测试图像为合法数据;否则,判断测试图像为非法数据,拒绝接收识别。为实现上述目的,本发明采用以下技术方案:本发明提供的用于人脸识别的自适应冗余字典构造方法,包括:步骤(1):获取待测试人脸图像和若干人脸图像样本,将若干人脸图像样本存储至训练样本集中,分别提取待测试人脸图像和训练样本集中每个样本的LCP特征;其中,LCP特征由LBP特征和MiC特征融合构成;步骤(2):计算待测试人脸图像与训练样本集中任一样本之间的LBP特征相似性和MiC特征相似性,进而得到待测试人脸图像与训练样本集中全部样本的平均LBP特征相似性和平均MiC特征相似性;步骤(3):将平均LBP特征相似性和平均MiC特征相似性分别与相应合法阈值比较,判断LBP特征和MiC特性是否均属于合法特征,若是,则进入下一步;否则,拒绝识别待测试人脸图像;步骤(4):在合法特征中,当LBP特征相似性不小于LBP特征近邻阈值且MiC特征相似性不大于MiC特征近邻阈值时,训练样本集中相应的样本才被标注为待测试人脸图像的近邻样本;步骤(5):将被标注的待测试人脸图像的近邻样本作为原子,进而构造出用于人脸识别的自适应冗余字典。所述步骤(1)中的LBP特征是通过二值化邻域内近邻像素与中心像素的灰度差得到的。所述步骤(1)中,提取MiC特征的具体过程为:分别构建测试人脸图像或训练样本集中每个样本的LBP特征的m模式下的像素的灰度值矩阵Gm以及所有模式下的像素的中心邻域内的近邻像素的灰度值矩阵Vm,其中m为正整数;根据Gm=VmAm,求解Am,进而求解Am的傅里叶变换,最终得到测试人脸图像或训练样本集中每个样本的MiC特征。所述步骤(2)中LBP特征相似性采用χ2-BRD相似性来度量。χ2-BRD相似性等于χ2-BRD距离对数的相反数,其中,χ2-BRD距离为BRD距离与χ2距离的结合。所述步骤(2)中的MiC特征相似性采用欧氏距离来度量。其中,步骤(5)中的冗余字典构造如下:第i类训练样本中任意一幅测试样本的近邻人脸图像张成的列矢量为第i类训练样本中全部的近邻样本构成矩阵ni表示第i类训练样本训练图像的数量,i为正整数),则最终构成的自适应冗余字典为R=[R1,…,Ri,…,RC](C表示训练样本的类别数,C为正整数)。本发明的有益效果为:(1)本发明提出了一种利用LCP特征自适应构造冗余字典的方法。其创新性如下:第一,提出了基于比例直方图距离的“χ2-BRD相似性”,用于度量图像在LBP特征上的近邻程度;用简单的欧氏距离度量图像在MiC层上的相似性。第二,将两层特征融合,给出了测试样本合法性的判决方案和近邻样本的选择方案,并通过大量详细的实验,给出了χ2-BRD特征和MiC特征的合法阈值与近邻阈值的经验值取值范围。(2)利用近邻样本作为原子构造超完备的冗余字典,完成对测试图像的稀疏表示分类。字典依据测试图像自适应生成,字典原子和测试样本在结构上具有更高的相似性,更符合稀疏表示理论中字典构造的原则,因此正确识别率得以显著提高,同时字典的“厚度”缩减了一半以上,提高了稀疏表示矢量的求解速度,从而提高了识别速度。附图说明图1是本发明的自适应冗余字典的构造方法的流程示意图;图2是以ORL人脸库中的一幅图像与其它239幅图像之间的图3是ORL人脸库中图像的各直方图间的图4(a)是ORL数据库的近邻样本的数量分布;图4(b)是AR数据库的近邻样本的数量分布。具体实施方式下面结合附图与实施例对本发明做进一步说明:一、局部构造模式(LCP)特征本发明的LBP特征是通过二值化邻域内近邻像素与中心像素的灰度差得到的,增强了光照变化的鲁棒性,但削弱了像素间的相互关系,从而丢失了局部构造信息。为了克服这一问题,本发明采用局部构造模式(Localconfigurationpattern,LCP)编码,把图像特征分为两层。第一层采用LBP提取局部结构信息,称为LBP特征,第二层称为微观构造(MiCroscopicConfiguration,MiC)特征,用于描述近邻像素之间的线性关系,其提取方法描述如下。局部二值模式(LocalBinaryPattern,LBP),通过简单计算即可捕捉到图像的细节特征,提取出更利于分类的局部邻域关系模式,成为图像分类的主流方法之一。设(xc,yc)为图像中任意一个像素点,其灰度值为gc,用gp(p=0,…,P-1)表示以(xc,yc)为圆心。LBP算法以gc为阈值对近邻像素的灰度值进行二值化,并从某个指定点开始按照指定顺序把P个二进制数串接起来,该二进制数对应的十进制数即为像素点(xc,yc)的LBP模式值,记为LBPP,R(xc,yc)。其中,R为圆周的半径,R可以取任意正数,P可以取任意正整数。LBPP,R(xc,yc)=Σp=0P-1s(gp-gc)2p---(1)]]>其中为阶跃函数。把描述LBP模式值的二进制数串视为首尾链接的环形,定义为0、1之间的转换次数,当U(LBPP,R)≤2时,该模式被定义为“均匀模式”(UniformPattern,也称为“统一模式”)。为了保证LBP算子具有旋转不变性,令被称为具有旋转不变性的均匀模式。对一幅w×h的图像I,计算每个像素点(i,j)处的得到一幅局部二值模式图像,其中,w和h均可以取任意正整数;i和j均可以取任意正整数。此局部二值模式图像的直方图即是原始图像I的LBP特征矢量H:H(m)=Σi=1wΣj=1hδ(LBPP,Rriu2(i,j)-m),m∈[0,M-1]---(3)]]>其中M=2P表示的最大取值。给定一个P维的参数矢量A=(a0,a1,…,aP-1)T,完成对邻域中心像素的重构,用表示中心像素的重构,最优参数矢量应满足令hm表示LBP特征图像中第m种模式出现的次数,H=[h0h1…hM-1]表示图像的LBP特征,gm,i(i=0,1,…,hm-1)表示具有m模式的第i个像素的灰度值,其中,m为正整数;vi;0,vi;1,…,vi;P-1(i=0,…,hm-1)表示以第i个具有m模式的像素为中心的邻域内的近邻像素的灰度值,构造矩阵Gm=gm,0gm,1...gm,Om-1T---(4)]]>Vm=v0;0v0;1...v0;P-1v1;0v1;1...v1;P-1...vNL-1;0vNL-1;1...vNL-1;P-1---(5)]]>令最优参数矢量应该满足:Gm=VmAm(6)一般情况下,hm>>P,采用最小二乘法很容易求得方程(6)的唯一解为:Am=(VmTVm)-1VmTGm---(7)]]>若hm≤P,则说明m模式出现的概率很低,是一小概率事件,该模式被定义为不可靠模式,此时参数矢量中的所有值均置为0,即Am=0。令Fm表示Am的P点傅里叶变换,则Fm的第k个元素为Fm(k)=Σi=0P-1Am(i)*e-j2πki/P---(8)]]>Fm具有旋转不变特性,其中,k为大于或等于0的整数。令|Fm|=[|Fm(0)||Fm(1)|…|Fm(P-1)|]T(9)图像的局部微观构造(MiC)特征被定义为F=[|F0||F1|…|FM-1|]。融合第一层的LBP特征和第二层的MiC特征,构成图像的LCP特征,即LCP=[[|F0|;O0];[|F1|;O1];…;[|FM-1|;OM-1]](10)二、LCP特征相似性度量本算法分别从LBP和MiC两层特征计算两幅图像在LCP特征空间上的相似性。2.1、LBP特征相似性基于bin-比例直方图距离(BinRatio-basedDistance,BRD)可以很好地度量直方图之间的相似性,尤其是在有遮挡时,该直方图距离具有更好的分类性能。bin-比例直方图距离定义如下。令表示具有Q个bin值的单位长度直方图矢量,即其中,Q为正整数。分别表示两幅图像A和B的单位长度直方图矢量,A、B之间基于bin比例直方图距离(BRD)为:dBRD(Z~A,Z~B)=Σi=1QdBRD,i(Z~A,Z~B)=Σi=1QΣj=1Q(z~iBz~jA-z~jBz~iAz~iA+z~iB)2---(11)]]>将BRD距离与χ2距离结合定义为χ2-BRD距离:dχ-BRD2(Z~A,Z~B)=dχ2(Z~A,Z~B)-2||Z~A+Z~B||22Σi=1Q(z~iA-z~iB)2z~iAz~iB(z~iA+z~iB)3---(12)]]>其中表示之间的卡方距离。χ2-BRD距离的分类效果优于单独使用χ2距离或者BRD距离。图2以ORL人脸库中的一幅图像为例,画出了该图像与其它239幅图像之间的为单位长度矢量,因此的值域很小,从图2也可以看出之间的差异过小,不利于区分它们之间的差异性。为此我们定义图像间的“χ2-BRD相似性”为Sχ-BRD2=-log[dχ-BRD2(Z~A,Z~B)]---(13)]]>上述对数运算非线性地扩展了的值域。图3给出了图1中各直方图间的显然,各数据之间的差异得到明显提高,更利于度量图像之间相似性的大小。越大,表明两幅图像之间的相似性越大,同一幅图像与它自身的为无穷大。2.2、MiC特征相似性采用欧氏距离度量两个图像在MiC特征层上的相似性。令F(x1)和F(x2)表示两幅图像的归一化MiC特征,则ρ(x1,x2)=||F(x1)-F(x2)||2(14)表示了F(x1)和F(x2)之间的结构距离即为MiC相似性。两者之间的距离越小相似性越大。三、近邻样本的选择3.1、近邻样本的选择准则对测试图像y,根据公式(13)和(14)分别计算出其与任意一幅像素点为(i,j)训练图像xi,j的和结构距离ρ(y,xi,j)。令和分别表示y与全部N幅训练图像的平均和平均MiC相似性,给出以下判据:判据1:若则认为测试图像在LBP特征层不合法,标注为非法数据。对于合法数据,若则xi,j在LBP特征层被标定为近邻样本,其中,为LBP特征合法阈值,为LBP特征近邻阈值,和的值均为常数。判据2:若则认为测试图像的MiC特性符合合法数据特征。若ρ(y,xi,j)≤ρC,则xi,j在局部微观构造特征空间被标定为近邻样本,其中,ρT为MiC特性合法阈值,ρC为MiC特性近邻阈值,ρT和ρC的值均为常数。判据1和判据2分别在LCP的两层特征空间对测试样本进行了标注。合法阈值用于判断测试图像是否为冒充人员,其值可根据具体应用进行选择。本发明按照“两层特征均符合合法数据特征时才接受识别”的原则进行判决。对于合法数据,仅当且ρ(y,xi,j)≤ρC时,xi,j才被标注为测试图像的近邻样本。近邻样本的选择流程如图1中实线方框部分所示。3.2阈值训练采用ORL、YaleB和AR三个标准人脸库,分别计算同类样本间的相似性、同一数据库中异类样本间的相似性和不同数据库中样本间的相似性。通过大量实验发现,样本间的不依赖于具体的实验样本,可以给出LBP特征合法阈值和LBP特征近邻阈值的经验值,其中可在2.4下方附近选择,可在2.5上方附近选择。MiC层上的MiC特性合法阈值ρT根据错误接收率和错误拒绝率两类错误率进行选择,实验发现,ρT也不依赖于具体的实验数据,可以在[0.5,0.6]之间设定经验值。在MiC层上,近邻阈值与具体的实验数据有关,需要首先利用数据库中的训练样本训练出平均类内结构距离和平均类间结构距离,然后再选择MiC特性近邻阈值ρC。例如ORL库选择ρC=0.48比较合适,而YaleB数据库选择ρC=0.35比较合适。四、结果4.1、近邻样本的数量分布表1给出了利用ORL和AR数据库,合法性判决分别采用两种特征融合方案时,全部测试样本的近邻样本的数量范围。取近邻阈值ρc=0.55。其中ORL数据库共有240幅训练图像,AR数据库中共有700幅训练图像,分别表示合法性采用“两层特征均符合”和“只要一层特征符合即可”的判决方案。表1ORL库中各种特征融合方案中的近邻样本的数量虽然不同测试图像的近邻样本数量的分布范围较大,但实验证明大多数测试图像的近邻样本数量分布集中于一个小范围内。如图4(a)表示ORL库中绝大多数测试样本的近邻样本数量均集中在100到170之间,与训练样本总数240相比,原子数目减少到一半左右,与样本类别数40相比,原子数量相对较多。图4(b)表明AR数据库中,近邻样本的数量集中在200到500之间,与训练样本数量700相比,减少了三分之一以上,与样本类别数100相比,原子数量较充足。因此这种方法构造的字典既包含了足够多的字典原子,又极大地减少了原子数量。4.2、识别速度基于分类的稀疏表示算法的识别速度取决于稀疏表示矢量的求解速度。理论和实验均表明,当原子数量增多时,识别速度急速下降。此处列出用一台i5处理器、内存为4G的联想PC机,用MATLAB2010作为编程软件,在不同原子数量下,求解一次稀疏表示矢量所用的时间,单位为秒(s)。从ORL数据库中选取240幅训练样本数,原子特征数量取95,字典原子数量分别取240、150和120,表2列出了分别采用线性规划优化算法(l1~ls)和正则化最小二乘(RLS)算法求解一次稀疏解所需的时间。表2利用ORL人脸库求解稀疏矢量的时长(s)表3列出了利用AR数据库中700幅人脸图像作为训练样本,在字典原子数量和原子特征数量取不同数值时,分别采用线性规划优化(l1~ls)算法和正则化最小二乘(RLS)算法求解一次稀疏表示矢量所用的时间。为了保证冗余字典满足原子特征数量小于原子数量的要求,在稀疏求解前,利用PCA对人脸数据进行降维,以保证保留的原子特征数量小于训练样本的数量。表中第一列括号中的数字表示保留的特征数量。表3AR人脸库上求解稀疏矢量的时长(s)利用PCA对人脸图像进行特征提取时,识别结果受到保留特征的影响,为了克服特征提取和特征选择对识别的影响,可采用压缩感知算法对人脸图像进行感知降维,稀疏求解算法同样可以采用线性优化算法,也可采用正交匹配跟踪(OMP)算法。表4和表5分别给出了利用ORL和AR人脸库和OMP算法,在不同原子数量以及不同维数的感知矩阵下,求解一个稀疏解所用的时间,单位为秒。表4ORL人脸库上利用OMP求解稀疏矢量的时长(s)表5AR人脸库上利用OMP求解稀疏矢量的时长(s)从表2到表5可以看出,所有稀疏求解算法所需的计算时间均随着原子数量的降低迅速提高,尤其是在原子特征维数较多的情况下,速度的提升更加明显。4.3、利用近邻样本自适应构造冗余字典稀疏表示分类的正确识别率稀疏表示理论指出,原子结构与测试图像之间的相似性越高,其正确识别率也越高。本算法利用测试图像的近邻样本作为原子,原子结构与测试样本具有更高的相似性。因此,与用全部训练样本构成的字典相比,稀疏分类的正确识别率得以提高,在AR、ORL、YALEB数据库上,无遮挡时的正确识别率提高了2%左右,在FERET数据库上提高了3%左右,在AR数据库上,测试图像采用墨镜和围巾遮挡时,正确识别率可以分别达到84%和86.5%,提高了将近15%左右。本发明提出了一种利用LCP特征自适应构造冗余字典的方法。其创新性如下:第一,提出了基于比例直方图距离的“χ2-BRD相似性”用于度量图像在LBP特征上的近邻程度;用简单的欧氏距离度量图像在MiC层上的相似性。第二,将两层特征融合,给出了测试样本合法性的判决方案和近邻样本的选择方案,并通过大量详细的实验,给出了χ2-BRD特征和MiC特征的合法阈值与近邻阈值的经验值取值范围。利用近邻样本作为原子构造超完备的冗余字典,完成对测试图像的稀疏表示分类。字典依据测试图像自适应生成,字典原子和测试样本在结构上具有更高的相似性,更符合稀疏表示理论中字典构造的原则,因此正确识别率得以显著提高。同时字典的“厚度”缩减了一半以上,提高了稀疏表示矢量的求解速度,从而提高了识别速度。上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1