一种考虑任务相关性的Hive优化方法及系统与流程
本发明涉及大数据质量高效评估领域,具体涉及一种考虑任务相关性的Hive优化方法及系统。
背景技术:
随着大数据时代的到来,数据呈爆炸式增长,种类也越来越多。数据库也随之发展,经历了一个从各种模式百花齐放,然后关系型数据库一支独秀,再到后关系型数据库出现,新型非关系型数据再度兴起的过程,为应对海量数据低成本、可扩展、高可靠存储及快速处理的挑战,产业界、学术界也掀起大数据处理的浪潮,现在可以方便得搭建大规模集群来处理这些问题,典型代表是Hadoop生态系统,Hadoop生态系统借鉴了Google实现。Hadoop实现了分布式文件系统HDFS,以及MapReduce编程模型,为大数据处理提供了存储与计算平台。进而在其上演化出了挖掘工具Hive,提供类SQL的查询功能,即HQL(HiveQL)的查询。MapReduce编程模型需要用户手动编写map函数和reduce函数,这个低层次的应用程序接口提高了程序的灵活性,但是增加了排错的难度,高层次的描述性语言例如Hive,简化了MapReduce编程。
Hive数据仓库适合处理大量的离线数据,但仍存在速度过慢的缺点。
技术实现要素:
本发明提供一种考虑任务相关性的Hive优化方法及系统,其目的是考虑任务之间的相关性,最小化MapReduce Job数量。
本发明的目的是采用下述技术方案实现的:
一种考虑任务相关性的Hive优化方法,其改进之处在于,包括:
将HQL语句转化为MapReduce物理计划,并获取所述MapReduce物理计划中各MapReduce Job在shuffle阶段用于排序的键shuffle key;
根据相关性规则,合并所述各MapReduce Job中相关MapReduce Job。
优选的,所述相关性规则包括:
规则a.若n个MapReduce Job间不包含父子关系且shuffle key相同,则所述n个MapReduce Job互为相关MapReduce Job,并对所述规则a确定的相关MapReduce Job进行合并,其中,n为正整数且n小于所述MapReduce物理计划中MapReduce Job的总个数;
规则b.若父MapReduce Job与其所有子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job互为相关MapReduce Job,并对所述规则b确定的相关MapReduce Job进行合并;
规则c.若父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job互为相关MapReduce Job,并对所述规则c确定的相关MapReduce Job进行合并。
进一步的,所述对所述规则a确定的相关MapReduce Job进行合并包括:
所述n个MapReduce Job读磁盘时读取所述n个MapReduce Job对应的map函数的处理数据并将所述n个MapReduce Job对应的map函数输出数据的n个shuffle key分别与n个标记{tag1,tag2...tagi...tagn}进行合并,获取合并结果其中,为第i个MapReduce Job对应的map函数的处理数据,为第i个MapReduce Job对应的map函数的处理数据的排序键,为第i个MapReduce Job对应的map函数的处理数据的排序键的属性值,为第i个MapReduce Job对应的map函数输出数据,为第i个MapReduce Job对应的shuffle key且列相同,第i个MapReduce Job对应的shuffle key的属性值,tagi与为唯一对应关系,用于标记shuffle key与MapReduce Job的对应关系;
将所述合并结果放入shuffle过程,通过shuffle key对应的标记确定数据来源,将第i个标记tagi对应的发送至所述第i个MapReduce Job的reduce函数。
进一步的,所述对所述规则b确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job的所有子MapReduce Job互为所述规则a定义的相关MapReduce Job,则将所述父MapReduce Job的所有子MapReduce Job按所述对所述规则a确定的相关MapReduce Job进行合并的合并方式进行合并;
将所述父MapReduce Job的所有子MapReduce Job对应的reduce函数处理结果直接发送至所述父MapReduce Job的map函数,且所述父MapReduce Job的map函数直接将所述父MapReduce Job的map函数的输出结果发送至所述父MapReduce Job的reduce函数。
进一步的,所述对所述规则c确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job读磁盘时读取与其不相关的子MapReduce Job的存盘结果和与其相关的子MapReduce Job对应的map函数的处理数据;
将所述与其相关的子MapReduce Job对应的map函数的处理数据发送至所述与其相关的子MapReduce Job对应的map函数并获取所述与其相关的子MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述与其相关的子MapReduce Job对应的reduce函数,将所述与其相关的子MapReduce Job对应的reduce函数的输出结果直接发送至所述父MapReduce Job对应的map函数,并直接将所述父MapReduce Job对应的map函数的输出结果发送至所述父MapReduce Job对应的reduce函数;
将所述与其不相关的子MapReduce Job的存盘结果发送至所述父MapReduce Job对应的map函数并获取所述父MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述父MapReduce Job对应的reduce函数。
一种考虑任务相关性的Hive优化系统,其改进之处在于,所述系统包括:相互连接的HQL解释器和查询优化器,其中,所述HQL解释器,用于将HQL语句转化为MapReduce物理计划,并获取所述MapReduce物理计划中各MapReduce Job在shuffle阶段用于排序的键shuffle key,所述查询优化器,用于接收所述MapReduce物理计划并根据相关性规则,合并所述MapReduce物理计划中各MapReduce Job中相关MapReduce Job。
优选的,所述相关性规则包括:
规则a.若n个MapReduce Job间不包含父子关系且shuffle key相同,则所述n个MapReduce Job互为相关MapReduce Job,并对所述规则a确定的相关MapReduce Job进行合并,其中,n为正整数且n小于所述MapReduce物理计划中MapReduce Job的总个数;
规则b.若父MapReduce Job与其所有子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job互为相关MapReduce Job,并对所述规则b确定的相关MapReduce Job进行合并;
规则c.若父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job互为相关MapReduce Job,并对所述规则c确定的相关MapReduce Job进行合并。
进一步的,所述对所述规则a确定的相关MapReduce Job进行合并包括:
所述n个MapReduce Job读磁盘时读取所述n个MapReduce Job对应的map函数的处理数据并将所述n个MapReduce Job对应的map函数输出数据的n个shuffle key分别与n个标记{tag1,tag2...tagi...tagn}进行合并,获取合并结果其中,为第i个MapReduce Job对应的map函数的处理数据,为第i个MapReduce Job对应的map函数的处理数据的排序键,为第i个MapReduce Job对应的map函数的处理数据的排序键的属性值,为第i个MapReduce Job对应的map函数输出数据,为第i个MapReduce Job对应的shuffle key且列相同,第i个MapReduce Job对应的shuffle key的属性值,tagi与为唯一对应关系,用于标记shuffle key与MapReduce Job的对应关系;
将所述合并结果放入shuffle过程,通过shuffle key对应的标记确定数据来源,将第i个标记tagi对应的发送至所述第i个MapReduce Job的reduce函数。
进一步的,所述对所述规则b确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job的所有子MapReduce Job互为所述规则a定义的相关MapReduce Job,则将所述父MapReduce Job的所有子MapReduce Job按所述对所述规则a确定的相关MapReduce Job进行合并的合并方式进行合并;
将所述父MapReduce Job的所有子MapReduce Job对应的reduce函数处理结果直接发送至所述父MapReduce Job的map函数,且所述父MapReduce Job的map函数直接将所述父MapReduce Job的map函数的输出结果发送至所述父MapReduce Job的reduce函数。
进一步的,所述对所述规则c确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job读磁盘时读取与其不相关的子MapReduce Job的存盘结果和与其相关的子MapReduce Job对应的map函数的处理数据;
将所述与其相关的子MapReduce Job对应的map函数的处理数据发送至所述与其相关的子MapReduce Job对应的map函数并获取所述与其相关的子MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述与其相关的子MapReduce Job对应的reduce函数,将所述与其相关的子MapReduce Job对应的reduce函数的输出结果直接发送至所述父MapReduce Job对应的map函数,并直接将所述父MapReduce Job对应的map函数的输出结果发送至所述父MapReduce Job对应的reduce函数;
将所述与其不相关的子MapReduce Job的存盘结果发送至所述父MapReduce Job对应的map函数并获取所述父MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述父MapReduce Job对应的reduce函数。与最接近的现有技术比,本发明具有的优异效果如下:
本发明提供的技术方案,定义了MapReduce Job的相关性规则,根据MapReduce Job的相关性规则,在Hive执行过程中,能够对相关MapReduce Job进行合并,减少MapReduce Job数目,避免了Hive执行过程中过多的重复操作,提高了Hive的运行效率,极大的方便了大数据质量评估。
附图说明
图1是本发明一种考虑任务相关性的Hive优化方法的流程图;
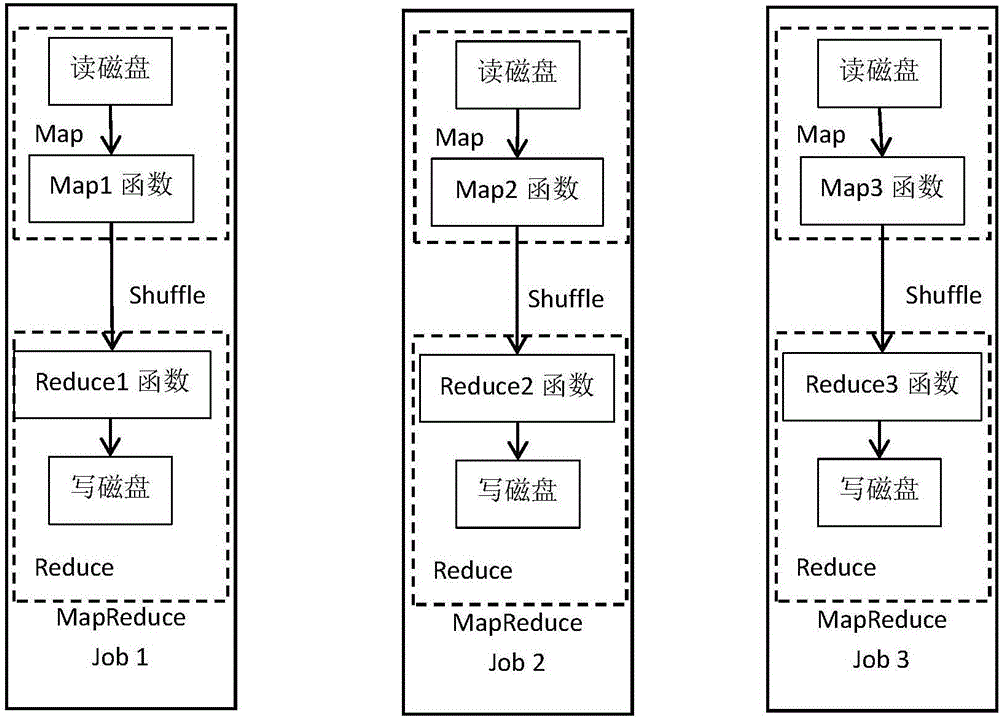
图2是本发明实施例提供的3个MapReduce Job的应用示意图;
图3是本发明实施例提供的3个MapReduce Job合并的应用示意图;
图4是本发明实施例提供的将TPCH的Q17翻译为4个MapReduce Job的应用示意图;
图5是本发明实施例提供的4个MapReduce Job合并的应用示意图;
图6是本发明一种考虑任务相关性的Hive优化系统的结构示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作详细说明。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明提供的一种考虑任务相关性的Hive优化方法,如图1所示,包括:
101.将HQL语句转化为MapReduce物理计划,并获取所述MapReduce物理计划中各MapReduce Job在shuffle阶段用于排序的键shuffle key;
其中,在运行一个MapReduce Job计算任务时候,任务过程被分为map阶段和reduce阶段,该任务过程中还包括一个阶段比较少提,就是shuffle阶段,shuffle阶段用于在MapReduce计算框架中衔接map阶段和reduce阶段,因为是MapReduce计算框架自动实现,所以一般不提及,但是仍然存在,map阶段和reduce阶段都是用键值对(key/value)作为输入(input)和输出(output)。需通过人工定义两个阶段的函数,即map函数和reduce函数。
102.根据相关性规则,合并所述各MapReduce Job中相关MapReduce Job。
其中,所述相关性规则包括:
规则a.若n个MapReduce Job间不包含父子关系且shuffle key相同,则所述n个MapReduce Job互为相关MapReduce Job,并对所述规则a确定的相关MapReduce Job进行合并,其中,n为正整数且n小于所述MapReduce物理计划中MapReduce Job的总个数;
其中,所述父子关系包含孙子关系,指不能有上下层关系的MapReduce Job;
规则b.若父MapReduce Job与其所有子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job互为相关MapReduce Job,并对所述规则b确定的相关MapReduce Job进行合并;
规则c.若父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job互为相关MapReduce Job,并对所述规则c确定的相关MapReduce Job进行合并。
其中,所述子MapReduce Job指所述父MapReduce Job的直接儿子;
进一步的,所述对所述规则a确定的相关MapReduce Job进行合并包括:
所述n个MapReduce Job读磁盘时读取所述n个MapReduce Job对应的map函数的处理数据并将所述n个MapReduce Job对应的map函数输出数据的n个shuffle key分别与n个标记{tag1,tag2...tagi...tagn}进行合并,获取合并结果其中,为第i个MapReduce Job对应的map函数的处理数据,为第i个MapReduce Job对应的map函数的处理数据的排序键,为第i个MapReduce Job对应的map函数的处理数据的排序键的属性值,为第i个MapReduce Job对应的map函数输出数据,为第i个MapReduce Job对应的shuffle key且列相同,第i个MapReduce Job对应的shuffle key的属性值,tagi与为唯一对应关系,用于标记shuffle key与MapReduce Job的对应关系;
将所述合并结果放入shuffle过程,通过shuffle key对应的标记确定数据来源,将第i个标记tagi对应的发送至所述第i个MapReduce Job的reduce函数。
所述对所述规则b确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job的所有子MapReduce Job互为所述规则a定义的相关MapReduce Job,则将所述父MapReduce Job的所有子MapReduce Job按所述对所述规则a确定的相关MapReduce Job进行合并的合并方式进行合并;
将所述父MapReduce Job的所有子MapReduce Job对应的reduce函数处理结果直接发送至所述父MapReduce Job的map函数,且所述父MapReduce Job的map函数直接将所述父MapReduce Job的map函数的输出结果发送至所述父MapReduce Job的reduce函数。
其中,若所述父MapReduce Job还有数据来自表文件,则表文件相当于下述规则c中与父MapReduce Job不相关的子MapReduce Job文件,处理方式同包括:所述父MapReduce Job读取所述父MapReduce Job对应map函数的处理数据,及表数据,并获取所述并获取所述父MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述父MapReduce Job对应的reduce函数。
所述对所述规则c确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job读磁盘时读取与其不相关的子MapReduce Job的存盘结果和与其相关的子MapReduce Job对应的map函数的处理数据;
将所述与其相关的子MapReduce Job对应的map函数的处理数据发送至所述与其相关的子MapReduce Job对应的map函数并获取所述与其相关的子MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述与其相关的子MapReduce Job对应的reduce函数,将所述与其相关的子MapReduce Job对应的reduce函数的输出结果直接发送至所述父MapReduce Job对应的map函数,并直接将所述父MapReduce Job对应的map函数的输出结果发送至所述父MapReduce Job对应的reduce函数;
将所述与其不相关的子MapReduce Job的存盘结果发送至所述父MapReduce Job对应的map函数并获取所述父MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述父MapReduce Job对应的reduce函数。
例如:如图2所示,3个MapReduce Job,Job1和Job2无子任务,可以直接执行,Job3是Job1和Job2的父任务,且Job3与Job1的shuffle key相同,能够根据所述规则c进行合并,则重写MapReduce物理计划,如图3所示,将Job1对应的map函数map1的处理数据,即表数据,发送至Job1对应的map函数map1并获取Job1对应的map函数map1的输出结果,将该输出结果放入shuffle过程,再发送至Job1对应的reduce函数reduce1,将Job1对应的reduce函数reduce1的输出结果直接发送至Job3对应的map函数map3,并直接将Job3对应的map函数map3的输出结果发送至Job3对应的reduce函数reduce3;
将Job2的存盘结果发送至Job3对应的map函数map3并获取Job3对应的map函数map3的输出结果,将该输出结果放入shuffle过程,再发送至Job3对应的reduce函数reduce3。
实施例
本发明提供的实施例,如图4所示,利用事务处理性能委员会(TPC)组织的一个通用的测试集TPCH的Q17为例,Hive将TPCH Q17翻译成了4个MapReduce Job,其中MapReduce Job1和MapReduce Job2没有子任务,读磁盘取的是表数据,可以直接执行,MapReduce Job3的子任务是MapReduce Job1和MapReduce Job2,读磁盘取的是MapReduce Job1和MapReduce Job2的结果,需要MapReduce Job1和MapReduce Job2执行完毕才能执行,MapReduce Job4的子任务是MapReduce Job3,读磁盘取的是MapReduce Job3的结果,需要MapReduce Job3执行完毕才能执行,具体地,Hive自动地生成了4个map函数:Map1函数、Map2函数、Map3函数、Map4函数和4个reduce函数:Reduce1函数、Reduce2函数、Reduce3函数、Reduce4函数。每个map函数处理完后就调用相应接口函数,将数据交给shuffle,shuffle在将数据交给reduce函数,reduce通过调用相应接口函数获得数据,本发明的优化过程并不会改写map函数和reduce函数对数据的处理部分,也不会修改MapReduce框架,仅修改map函数和reduce函数中关于结果传递的代码,也就是说只修改调用接口读取或发送数据的部分,再例如map函数的结果原本是调用接口,传给shuffle,现在可能将调用接口的内容删去,增加直接传给reduce函数的语句,也可能将map函数的结果的键值对中的键加一个tag字段,值不变,仍然将这个键值对交给shuffle。图2中,任务1、2、3的shuffle key是一个字段,具有相关性,满足合并的情况,则将其合并到一个任务中执行,如图5所示,合并后不修改原来4个map函数和reduce函数内部关于数据的处理过程,只是读磁盘时,同时读取Map1函数和Map2函数需要的数据,Hive会根据读取文件的路径自动判断是传给Map1函数还是Map2函数,假设Map1函数处理完输入发出的数据是(k21,v21),Map2函数处理完输入发出的数据是(k22,v22),因为任务1和任务2的shuffle key相同,所以k21和k22实际上是一个字段(后面合称为k2),可以一起放入shuffle过程,与Hive生成的原生态的Map1函数和Map2函数略有不同,在Map1函数和Map2函数原来的输出(不改变原函数执行内容)基础上,获得原函数的输出结果,MapReduce重写模块将修改k2的内容,将k2和一个tag(标记)合并为一个字段记为k2',标记作用是标记它是来自Map1函数还是Map2函数,最后传给shuffle的内容是(k2',v21或v22),当k2'中tag为0表示内容是(k2',v21),tag为1表示内容是(k2',v22)。Shuffle过后得到结果(k2',k21或k22),在原Hive生成的Reduce1函数和Reduce2函数执行之前,获得shuffle的结果然后根据tag确定数据来源,并从k2'中提取k21和k22,然后分别发送给Reduce1和Reduce2,这样Reduce1和Reduce2获得的内容就是(k21,v21)和(k22,v22),它们所处理的数据与任务合并之前完全一样,所以对Reduce1和Reduce2不需做任何更改,假设map3函数获取的数据为(k13,v13),在未优化的情况下,Map3函数读取的是Reduce1和Reduce2的输出(k21,v21)和(k22,v22)的存磁盘的结果,这里可以将(k21,v21)和(k22,v22)直接传给Map3函数,也就是说将Reduce1和Reduce2的结果不存磁盘,而是传给Map3函数,和前面一样,Map3会根据路径自动识别输入时来自Reduce1还是Reduce2,因为附图3中传给map3函数的数据是经过shuffle排序的,且排序键不变,所以次序不需要重排(重排仍会得到相同结果,不会改变次序),将Map3函数的结果直接传给Reduce3函数,最后Reduce3的结果存磁盘,交给MapReduce Job2。
本发明提供的一种考虑任务相关性的Hive优化系统,如图6所示,所述系统包括:相互连接的HQL解释器和查询优化器,其中,所述HQL解释器,用于将HQL语句转化为MapReduce物理计划,并获取所述MapReduce物理计划中各MapReduce Job在shuffle阶段用于排序的键shuffle key,所述查询优化器,用于接收所述MapReduce物理计划并根据相关性规则,合并所述MapReduce物理计划中各MapReduce Job中相关MapReduce Job。
其中,所述相关性规则包括:
规则a.若n个MapReduce Job间不包含父子关系且shuffle key相同,则所述n个MapReduce Job互为相关MapReduce Job,并对所述规则a确定的相关MapReduce Job进行合并,其中,n为正整数且n小于所述MapReduce物理计划中MapReduce Job的总个数;
规则b.若父MapReduce Job与其所有子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job互为相关MapReduce Job,并对所述规则b确定的相关MapReduce Job进行合并;
规则c.若父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job的shuffle key相同,则所述父MapReduce Job与其所有子MapReduce Job中的一个子MapReduce Job互为相关MapReduce Job,并对所述规则c确定的相关MapReduce Job进行合并。
进一步的,所述对所述规则a确定的相关MapReduce Job进行合并包括:
所述n个MapReduce Job读磁盘时读取所述n个MapReduce Job对应的map函数的处理数据并将所述n个MapReduce Job对应的map函数输出数据的n个shuffle key分别与n个标记{tag1,tag2...tagi...tagn}进行合并,获取合并结果其中,为第i个MapReduce Job对应的map函数的处理数据,为第i个MapReduce Job对应的map函数的处理数据的排序键,为第i个MapReduce Job对应的map函数的处理数据的排序键的属性值,为第i个MapReduce Job对应的map函数输出数据,为第i个MapReduce Job对应的shuffle key且列相同,第i个MapReduce Job对应的shuffle key的属性值,tagi与为唯一对应关系,用于标记shuffle key与MapReduce Job的对应关系;
将所述合并结果放入shuffle过程,通过shuffle key对应的标记确定数据来源,将第i个标记tagi对应的发送至所述第i个MapReduce Job的reduce函数。
所述对所述规则b确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job的所有子MapReduce Job互为所述规则a定义的相关MapReduce Job,则将所述父MapReduce Job的所有子MapReduce Job按所述对所述规则a确定的相关MapReduce Job进行合并的合并方式进行合并;
将所述父MapReduce Job的所有子MapReduce Job对应的reduce函数处理结果直接发送至所述父MapReduce Job的map函数,且所述父MapReduce Job的map函数直接将所述父MapReduce Job的map函数的输出结果发送至所述父MapReduce Job的reduce函数。
若所述父MapReduce Job还有数据来自表文件,则表文件相当于规则c中无法合并的MapReduce Job的执行结果文件,处理方式同规则c。
所述对所述规则c确定的相关MapReduce Job进行合并包括:
所述父MapReduce Job读磁盘时读取与其不相关的子MapReduce Job的存盘结果和与其相关的子MapReduce Job对应的map函数的处理数据;
将所述与其相关的子MapReduce Job对应的map函数的处理数据发送至所述与其相关的子MapReduce Job对应的map函数并获取所述与其相关的子MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述与其相关的子MapReduce Job对应的reduce函数,将所述与其相关的子MapReduce Job对应的reduce函数的输出结果直接发送至所述父MapReduce Job对应的map函数,并直接将所述父MapReduce Job对应的map函数的输出结果发送至所述父MapReduce Job对应的reduce函数;
将所述与其不相关的子MapReduce Job的存盘结果发送至所述父MapReduce Job对应的map函数并获取所述父MapReduce Job对应的map函数的输出结果,将该输出结果放入shuffle过程,再发送至所述父MapReduce Job对应的reduce函数。最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!