一种心率数据质量评估方法与流程
本发明涉及数据处理领域,涉及一种心率数据质量评估方法。应用本发明可以对不同人群的心率数据进行数据质量评估,有效提高识别异常心率数据的准确度。
背景技术:
异常数据是指数据集有部分数据与整体中其他数据相比存在明显不一致,也称为异常值、离群值。数据异常的产生原因较多,常见的原因有监护系统不稳定或者监护对象人为因素、环境条件突变或数据采集传感器突然故障等。异常数据识别一般采用的方法有基于模型的方法、基于邻近度的方法、基于密度的方法等等。
本发明提供了一种心率数据质量评估方法。首先以年龄段为基准对用户的心率数据进行分类,然后提出数据异常假设,提出了改进的t检验法对心率数据进行数据质量评估。
技术实现要素:
本发明公开了一种心率数据质量评估方法。本发明以年龄段为基准对用户的心率数据进行分类,提出数据异常假设,提出了一种改进的t检验法对心率数据进行数据质量评估。其具体实现的步骤如下:
S1:建立心率数据模型。心率数据基本符合高斯分布:
X~(μ,σ2)
其中,X为数据集,μ表示数据均值,σ2表示数据方差。
S2:提出假设检验。假设H0:xi=xc,H1:xi≠xc。H0:正常值。检测数据属于正常误差范围内;H1:异常值。检测数据不属于正常范围内,需要予以处理。
其中xc为参考值,xi为检测数据,i为检测数据的序号(i为正整数)。
S3:分类取样。随机获得参考样本Xn={x1,x2,…,xn},n为样本数(n为正整数)。
根据用户的年龄段把用户分为婴儿、少年、青年、壮年、老年等不同的层次,根据不同的层次对心率数据进行分类,采取分类采样的方式确定检测样本。心率数据取样分类具体描述为:
a)婴儿。年龄段:0~6岁。
b)少年。年龄段:7~14岁。
c)青年。年龄段:15~25岁。
d)壮年。年龄段:26~65岁。
e)老年。年龄段:66岁或以上。
S4:定义t检验法的参考值xc。具体描述为:
满足:
α+β+γ=3
其中,α为样本平均值的权值;为样本平均值;β为样本中位数的权值;xmedian为样本中位数;γ为样本众数的权值;xmode为样本众数。
S5:选定t检验法为检验统计方法,计算xi的统计量ti。
S6:给出显著性水平α及临界值tα/2,根据|ti|的大小判断xi是否异常值。
附图说明
图1本发明所述算法流程图;
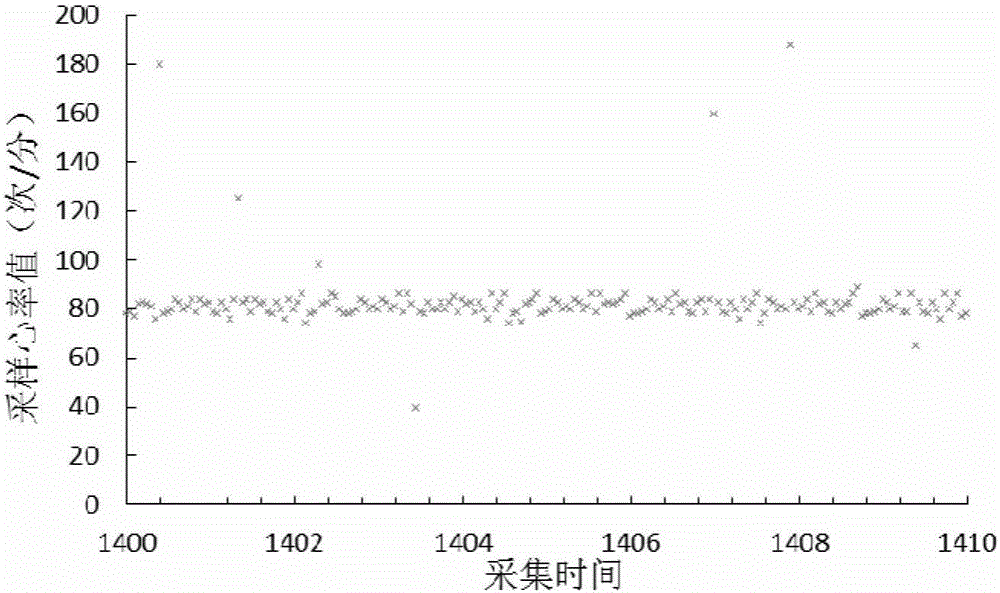
图2心率数值统计图;
图3心率数据质量评估对比图;(a)标准t检验法的统计量;(b)改进的t检验法的统计量。
具体实施方式
下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明的具体实施步骤如下:
Step1:建立心率数据模型。心率数据基本符合高斯分布:
X~(μ,σ2)
其中,X为数据集,μ表示数据均值,σ2表示数据方差。
Step2:提出假设检验。假设H0:xi=xc,H1:xi≠xc。H0:正常值。检测数据属于正常误差范围内;H1:异常值。检测数据不属于正常范围内,需要予以处理。
其中xc为参考值,xi为检测数据,i为检测数据的序号(i为正整数)。
Step3:分类取样。随机获得参考样本Xn={x1,x2,…,xn},n为样本数(n=10000)。
根据用户的年龄段把用户分为婴儿、少年、青年、壮年、老年等不同的层次,根据不同的层次对心率数据进行分类,采取分类采样的方式确定检测样本。心率数据取样分类具体描述为:
a)婴儿。年龄段:0~6岁。
b)少年。年龄段:7~14岁。
c)青年。年龄段:15~25岁。
d)壮年。年龄段:26~65岁。
e)老年。年龄段:66岁或以上。
Step4:定义t检验法的参考值xc。具体描述为:
满足:
α+β+γ=3
其中,α为样本平均值的权值;为样本平均值;β为样本中位数的权值;xmedian为样本中位数;γ为样本众数的权值;xmode为样本众数。取α=0.9,β=1.2,γ=0.9。
Step5:选定t检验法为检验统计方法,计算xi的统计量ti。具体描述为:
其中,xi为当前检测值;xc为参考值;n为样本数;xj为参考样本Xn={x1,x2,…,xn}。
Step6:给出显著性水平α及临界值tα/2,根据|ti|的大小判断xi是否异常值。
Step6-1:设定α=0.01,则tα/2(n-1)≈2.807。
Step6-2:当满足条件时,可判断检测值xi为异常值。判断条件具体描述为:
|ti|≥tα/2(n-1)
完成以上实施步骤后,采集心率数据可得到图2所示的心率数值统计图。经计算,得采样心率数据的统计量,标准t检验法和改进的t检验法的统计量如图3所示。从结果可看出,本发明提供了一种有效的心率数据质量评估方法。
- 还没有人留言评论。精彩留言会获得点赞!