一种基于数据库数据的搜索排名算法的制作方法
本发明属于计算机软件应用
技术领域:
,特别是一种针对数据库数据搜索而设计的,依据用户的兴趣和数据间的关系而定制的搜索排名算法。
背景技术:
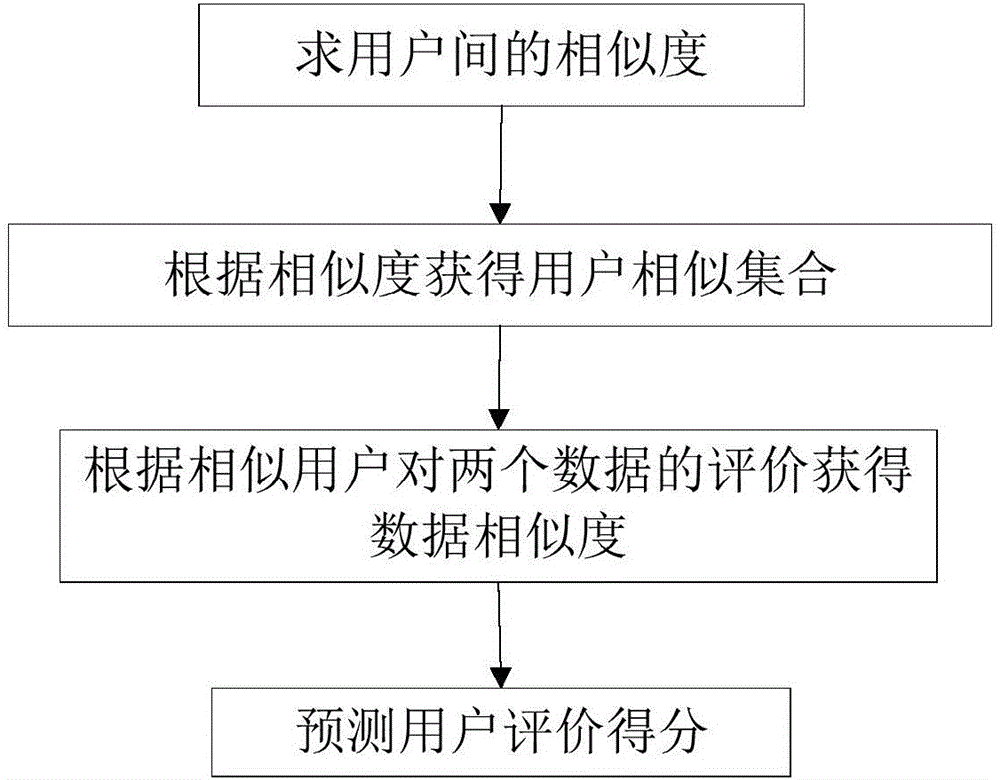
:在数据量巨大的互联网时代,为了更好的为在线用户提供服务,个性化搜索结果展现系统成为网络信息检索领域的一项重要研究。通过用户兴趣、信息之间的关系为用户选择最合适的信息展示形式,且协同过滤技术来解决用户搜索信息过量和迷失问题,是数据库搜索排名算法需要解决的问题之一。技术实现要素:发明目的:为了解决用户信息过载和数据迷失的问题,本发明提供一种基于数据库数据的搜索排名算法,能够根据用户兴趣和数据关系的个性化搜索展示结果,为用户提供更好的搜索上网体验。技术方案:为实现上述目的,本发明中基于数据库数据的搜索排名算法,包括以下步骤:(1)根据待预测用户输入的搜索词进行分词搜索;(2)对搜索结果集按照Lucenetf-idf算法进行评分排序,获取所述待预测用户对搜索结果集中某一待预测评分的数据的第一预测评分;(3)根据用户相似度获取数据推导相似度,并利用数据推导相似度计算所述待预测用户对该待预测评分的数据的第二预测评分;根据数据相似度获取用户推导相似度,并利用用户推导相似度计算所述待预测用户对该待预测评分的数据的第三预测评分;(4)根据所述待预测用户对所述待预测评分的数据的第一预测评分、第二预测评分和第三预测评分计算所述待预测用户对所述待预测评分的数据的最终预测评分;(5)结果展现。其中,步骤(3)中所述第二预测评分的计算包括以下步骤:1)根据不同用户对同一数据的评价统计计算出用户之间的相似度,利用预先设定的用户相似度阈值确定所述待预测用户的相似用户集合,所述相似用户集合中的用户与所述待预测用户之间的相似度大于所述用户相似度阈值;2)根据所述相似用户集合中的用户评价过的两个不同数据计算出这两个数据间的推导相似度,运用数据间的推导相似度计算所述待预测用户对所述待预测评分的数据的第二预测评分。其中,步骤(3)中所述第三预测评分的计算包括以下步骤:1)根据所有用户对两个不同数据的评价统计计算出这两数据间的相似度,得到待预测评分的数据的相似数据集合,所述相似数据集合中的数据与所述待预测评分的数据之间的相似度大于预先设定的数据相似度阈值;2)根据两个不同用户对所述待预测评分的数据的相似数据集合中的数据评价计算出这两个用户的推导相似度,运用用户间的相似度预测所述待预测用户对所述待预测评分的数据的第三预测评分。有益效果:本发明中基于数据库数据的搜索排名算法,首先根据特定用户对各业务模块的关注程度得出各模块对不同用户的重要程度,再通过用户与用户之间的相似程度预测用户对未评价的搜索数据的评价得分,通过数据与数据之间的相似关系预测用户对未评价数据的评价得分,最后综合上述评分得到最后展示排序结果。本发明方法利用用户与用户之间的相似程度使用户的差异性得到体现,利用数据与数据之间的相似关系使数据的关联性得到体现,能够根据用户兴趣和数据关系的个性化搜索展示结果,为用户提供更好的搜索上网体验,提高用户搜索结果的满意度。附图说明图1是本发明中基于数据库数据的搜索排名算法的流程图;图2是根据数据推导相似度获取用户对数据预测评分的流程图;图3是根据用户评价过的数据集合确定相似用户集合的软件实现流程图;图4是根据相似用户集合中用户对数据的评价计算数据间的推导相似度的软件实现流程图;图5是根据数据间的推导相似度计算用户对数据预测评分的软件实现流程图;图6是根据用户推导相似度获取用户对数据预测评分的流程图。具体实施方式下面结合实施例对本发明作更进一步的说明。图1中,本发明中基于数据库数据的搜索排名算法,包括以下步骤:(1)根据用户输入的搜索词进行分词搜索;(2)对搜索结果集按照Lucenetf-idf算法进行评分排序,获取用户对搜索结果集中某一待预测评分的数据的第一预测评分;(3)根据用户相似度获取数据推导相似度,并利用数据推导相似度计算用户对该待预测评分的数据的第二预测评分;根据数据相似度获取用户推导相似度,并利用用户推导相似度计算用户对该待预测评分的数据的第三预测评分;(4)根据用户对该待预测评分的数据的第一预测评分、第二预测评分和第三预测评分计算用户对该数据的最终预测评分;(5)结果展现:根据计算出的用户对需要排名的特定数据的预测评分,按照预测评分的高低对数据进行先后排序以网页形式展示在用户面前。下面以获取用户y对某一待预测评分的数据si的最终评分为例,针对本发明中基于数据库数据的搜索排名算法的几个关键步骤进行详细说明。对于上述步骤(2),设通过Lucenetf-idf算法获取到用户y对搜索结果数据si的第一预测评分为设数据si属于第k个业务模块,k∈{1,2,3,4,5,6},各业务模块与用户关注数据如下表1所示:表1各业务模块与用户关注度模块名称总数据量用户关注数据量模块1n1N1模块2n2N2模块3n3N3模块4n4N4模块5n5N5模块6n6N6通过对不同业务模块的用户关注数据统计得出用户对业务系统各模块的关注重要程度,第i个模块的重要程度的计算公式为:Rim=niNi.]]>如图2所示,上述步骤(3)中根据用户相似度获取数据推导相似度,并利用数据推导相似度计算用户对该待预测评分的数据的第二预测评分,包括以下步骤:1)根据不同用户对同一数据的评价统计计算出用户之间的相似度,得到用户y的相似用户集合。结合图3中所示的软件实现过程,设用户yi和用户yj评价过的数据集合分别为Si和Sj,用户yi和用户yj均评价过的数据集合为Sij,Ri,c为用户yi对数据c的评价值,Rj,c为用户yj对数据c的评价值,表示用户yi评价过的所有数据的评价平均值,表示用户yj评价过的所有数据的评价平均值,则用户yi和用户yj的相似度simy(i,j)的计算公式(分子对应图3中的变量fij,分母对应图3中的变量fi、fj)为:simy(i,j)=Σc∈Sij(Ri,c-R‾yi)(Rj,c-R‾yj)Σc∈Si(Ri,c-R‾yi)2Σc∈Sj(Rj,c-R‾yj)2]]>得到了用户与用户的相似度后,设与用户y的相似用户集合为Yg,本发明中对于任意用户y,若某一用户与其之间的相似度高于预设设定的用户相似度阈值,则该用户为与用户y相似度较高的用户,该用户属于相似用户集合Yg,用户相似度阈值根据实际情况进行设定。2)根据用户y的相似用户集合Yg中的用户评价过的两个数据计算出这两个数据间的推导相似度,运用数据间的推导相似度预测用户y对数据si的第二预测评分。结合图4中所示的软件实现过程,设对数据si和数据sj评价过的用户集合分别为Yi和Yj,则对数据si评价过且与用户y相似度较高的用户集合Yi'=Yi∩Yg,对数据sj评价过且与用户y相似度较高的用户集合Yj'=Yj∩Yg,对数据si和数据sj均评价过的用户集合Yij=Yi∩Yj,对数据si和数据sj均评价过且与用户y相似度较高的用户集合Y’ij=Yij∩Yg。设Ry,i为用户y对数据si的评价值,Ry,j为用户y对数据sj的评价值,表示Yi所有用户对数据si评价的平均值,表示Yj所有用户对数据sj评价的平均值,数据si和数据sj的推导相似度sims(i,j)的计算公式(分子对应图4中的变量fij,分母对应图4中的变量fi、fj)为:sims(i,j)=Σy∈Yij′(Ry,i-R‾st)(Ry,j-R‾sj)Σy∈Yi′(Ry,i-R‾st)2Σy∈Yj′(Ry,j-R‾sj)2,]]>结合图5中所示的软件实现过程,设用户y没有对其搜索结果集中待预测评分的si进行评价过,则可以预测用户y对数据si的第二预测评分为(式中分子对应图5中的R,分母对应图5中的|R|):Ry,is=Σk∈Sisims(i,k)Ry,kΣk∈Si|sims(i,k)|]]>式中,Si为用户y评价过的数据集合其中sims(i,k)为数据si和数据sk的推导相似度。如图6所示,上述步骤(3)中根据数据相似度获取用户推导相似度,并利用用户推导相似度计算用户对该待预测评分的数据的第三预测评分,包括以下步骤:1)根据所有用户对两个不同数据的评价分数计算出这两数据间的相似度,得到待预测评分的数据si的相似数据集合。设对数据si和数据sj评价过的用户集合分别为Yi和Yj,则对数据si和数据sj均评价过的用户集合Yij=Yi∩Yj,设Ry,i为用户y对数据si的评价值,Ry,j为用户y对数据sj的评价值,表示集合Yi中所有用户对数据si评价的平均值,表示集合Yj中所有用户对数据sj评价的平均值,数据si和数据sj的相似度sim's(i,j)的计算公式为:sims′(i,j)=Σy∈Yij(Ry,i-R‾si)(Ry,j-R‾sj)Σy∈Yi(Ry,i-R‾si)2Σy∈Yj(Ry,j-R‾sj)2;]]>根据不同数据之间相似度的计算公式,设与数据si的相似数据集合为Sg,本发明中对于任意数据si,若某一数据与其之间的相似度高于预设设定的数据相似度阈值,则该数据为与数据si相似度较高的数据,该数据属于相似数据集合为Sg,数据相似度阈值根据实际情况进行设定。2)根据两个不同用户对数据si的相似数据集合Sg中的数据评价计算出这两个用户的推导相似度,运用用户间的相似度预测用户y对数据si的第三预测评分。设用户yi和用户yj评价过的数据集合分别为Si和Sj,则被用户yi评价过且为数据si的相似数据集合Sg中的数据的集合S'i=Si∩Sg,被用户yj评价过且为数据si的相似数据集合Sg中的数据的集合S'j=Sj∩Sg,用户yi和用户yj均评价过的数据集合为Sij=Si∩Sj,则被用户yi和用户yj均评价过且为数据si的相似数据集合Sg中的数据的的集合S'ij=Sij∩Sg,Ri,c为用户yi对数据c的评价值,Rj,c为用户yj对数据c的评价值,表示用户yi评价的所有数据的评价平均值,表示用户yj评价的所有数据的评价平均值,用户yi和用户yj的推导相似度sim'y(i,j)的计算公式为:simy′(i,j)=Σc∈Sij′(Ri,c-R‾yi)(Rj,c-R‾yj)Σc∈Si′(Ri,c-R‾yi)2Σc∈Sj′(Rj,c-R‾yj)2]]>设用户y没有对其搜索结果集中待预测评分的数据si进行评价过,则可以预测用户y对数据si的第三预测评分为:Ry,iy=Σk∈Yisimy,(k,i)Rk,iΣk∈Yi|simy,(k,i)|]]>式中,Yi为对数据si评价过的用户集合,则用户sim'y(i,j)为用户yi和用yj的推导相似度。结合步骤(2)和(3)的内容,上述步骤(4)中得出用户y对搜索结果中待预测评分的数据si的最终预测评分fyi为:fyi=(fyil+Ry,iy+Ry,is/3).(nkNk+1).]]>当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1