一种基于非监督特征学习的高分辨率图像场景分类方法与流程
本发明属于遥感图像处理领域,尤其涉及一种基于非监督特征学习的高分辨率遥感图像场景分类方法。
背景技术:
高分辨率遥感图像(一般指大于1米空间分辨率的遥感图像)由于其具有很高的空间分辨率,丰富的空间信息可以为地物识别提供精细的信息,已被广泛应用于各个领域。然而,由于图像空间分辨率比较高,进行识别的场景通常包含多种不同类别的地物混合得到的像元,这些地物往往有着不同的结构信息,但是由于光谱分辨率较低,往往难以区分。随着高分辨率成像技术的成熟和成本的降低,高分辨率图像被越来越多的使用,但是高分辨率图像的场景识别仍然存在一些限制条件:
1)高分辨率的存在使得场景往往有多种复杂地物组成,造成异物同谱现象,使精确解译成为一个难点,因为无法确定这个像元到底属于哪种物质。
2)进行场景识别,需要利用获取的图像的空间、结构、纹理和语义信息,从语义的层面上解译图像,但是自适应的特征学习是个难点。
3)一些算法只利用了高分辨率图像中的浅层信息,如结构,纹理信息等人为设计的特征,往往忽略了数据本身的结构特点。这些方法不能有效地提取图像的特征表达。
因此,需要一种能利用数据本身高层次特征,又有优异的语义信息表达的方法来进行自适应的特征学习。
技术实现要素:
本发明主要是提供了一种非监督特征学习方法解决现有方法所存在的问题,提供了一种既能利用数据本身高层次特征,又有优异的语义信息表达的方法。
本发明提供的技术方案是,一种基于非监督特征学习的高分辨率图像场景分类方法,包含以下步骤:
步骤1,显著度检测,利用图像中不同位置的图像块局部和全局相似度来计算图像的显著度,实现方式如下,
对于不同的图像块,首先定义一个图像块相似函数(1),
其中dcolor为图像块在CIELab颜色空间的欧氏距离,dposition为图像块在图像位置空间的欧氏距离,xi,xj是任意位置的图像块,c是常数,选取与对应图像块xi最相似的K个图像块xk,其中k=1,2,…K,利用公式(2)来最终计算图像块所在位置的显著度,
其中,Si指图像块xi的显著度;
步骤2,显著图像块采样,根据步骤1所述的显著度检测获取图像中图像块的显著度信息,随机的从图像中选取预设固定大小的图像块;
步骤3,利用特征稀疏性目标函数和最小重构残差目标函数学习图像块特征表达,根据目标优化公式(5)同时优化目标特征的稀疏性和最小重构残差,
其中J(X,Z)是原始图像与经过解码后图像的残差和权值大小,其中X表示原始图像块,Z表示重构的图像块,i表示图像块编号,m表示图像块的数目,zi为图像块xi的重构结果,W表示目标函数的权值,是要学习到的特征提取算子,λ是约束项权值;是神经元的稀疏度,ρ是目标特征稀疏度,是当前特征稀疏度,β是稀疏度的权值;Y为总体误差函数;
步骤4,通过数据增强和随机丢弃进一步增强步骤3学习到的图像块特征表达;
步骤5,求解和更新特征算子,根据步骤3所述的目标优化公式(5),利用随机梯度下降法求解和更新特征算子;
步骤6,判断迭代是否达到最大训练次数,若达到最大训练次数则转至步骤7;否则转至步骤5;
步骤7,利用特征算子对图像进行卷积神经网络操作提取图像特征;
步骤8,利用支持向量机进行场景识别。
而且,步骤4所述的数据增强通过对图像进行随机旋转平移实现,所述随机丢弃通过在网络训练过程中,随机的屏蔽部分神经元实现。
与现有技术相比,本发明的有益效果是:
本发明使用稀疏自编码对特征进行自适应学习,并引入数据增强和随机丢弃对特征算子的最优解进行更新,避免数据“过拟合”问题。在目标函数的设计方面,巧妙结合稀疏目标函数和最小重构残差目标函数来进行特征学习,可以在合理的时间代价下实现对特征的学习,学习到的特征在场景识别中更具有鲁棒性。
附图说明
图1为本发明实施例中的非监督特征学习原理图。
图2为本发明实施例中的卷积神经网络提取图像特征原理图。
具体实施方式
以下结合附图和具体实施例来对本发明做进一步的说明。
本发明提供一种用于高分辨率遥感图像场景分类的方法,将场景分类中的特征学习看作一个非监督的学习问题,利用显著度检测提取图像的显著度信息,利用稀疏自编码从图像中学习特征表达,结合特征稀疏性目标函数和最小重构残差目标函数使得特征学习结果具有鲁棒性。
引入显著度检测算法,显著度检测算法是一种将人眼视觉机制引入特征学习的算法。具有显著度特征的图像块一般包含图像最具代表的特征,因此可以保证学习到最优的特征表达。实施例利用包含显著信息的图像空间位置的图像块进行特征编码学习。这样学习编码的原因在于,包含显著度信息的图像块往往具有最具代表的图像结构特征和充分的语义信息。由图像的统计信息,可以知道图像中的纹理和结构信息是静态的,不同的局部信息往往是高度相似的,利用显著度信息寻找代表性的图像块,即能以较高的概率学习到全局最优的特征表达。
引入稀疏自编码对特征进行编码学习。不同图像的特征表达往往包含着不同的纹理,结构和语义信息。利用稀疏自编码方法,自适应的学习图像的内在结构和特征表达,这样可以使学习到的特征具有最好的场景可分性。同时利用稀疏约束,对学习到的特征进行优化,使得特征更加鲁棒。实施例为了避免特征学习的过程中出现数据“过拟合”问题,引入数据增强和随机丢弃进行最优解位置的更新。对特征表达的每一维进行适应的丢弃操作,这样可以使学习算法更加鲁棒,同时提高特征的有效性。
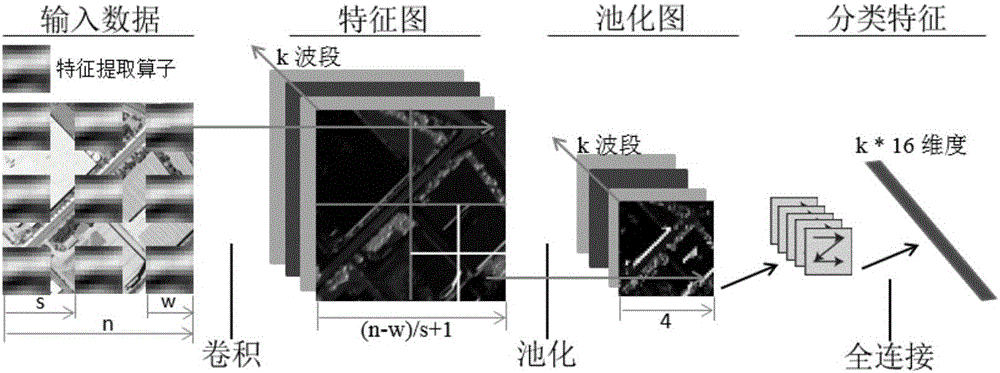
图1为非监督特征学习原理图,非监督特征学习分为两个阶段进行,第一阶段是基于显著度的图像块采样,首先利用显著度检测提取图像的显著度信息,根据图像不同位置的显著度信息,从图像中根据显著度的大小随机采样选取图像块(如10×10大小)。第二阶段是利用稀疏自编码进行特征学习,基于选取出来的图像块,利用稀疏自编码自适应的学习特征提取算子。稀疏自编码利用随机梯度下降法进行求解。随机梯度下降法是一种传统的神经网络优化算法。最后,利用学习出来的特征算子,对待识别的遥感影像的图像数据进行卷积操作,提取图像特征,然后把提取出来的特征输入支持向量机进行分类,例如分为居民区、跑道、草地、机场、工业区。
实施例提供的流程具体包括以下步骤:
步骤1,显著度检测:利用图像中不同位置的图像块的局部和全局的相似度来计算图像的显著度。对于不同的图像块(实施例为10×10大小),首先定义一个图像块相似函数(1),
其中dcolor为图像块在CIELab颜色空间的欧氏距离,dposition为图像块在图像位置空间的欧氏距离,xi,xj是任意位置的图像块,c是常数,本实施例取c=3。根据相似函数,其值越大表示两个图像块越相似,选取与对应图像块xi最相似的K个图像块xk(k=1,2,…K,具体实施时,K可由本领域技术人员自行预设取值,建议取值9-15),利用公式(2)来最终计算这个图像块所在位置的显著度,
其中,Si指图像块xi的显著度。
步骤2,显著图像块采样:根据图像的显著度信息,随机的从图像中选取预设固定大小的图像块(如10×10)。本实施例设定显著度大于显著阈值0.75为包含显著信息的图像块,小于非显著阈值0.25的为非显著度块;从待识别的遥感数据中随机选取20万个图像块,其中75%为显著度块,25%为非显著度块。具体实施时,显著阈值、非显著阈值、图像块数目可由本领域技术人员自行预设。
步骤3,利用特征稀疏性目标函数和最小重构残差目标函数学习图像块特征表达。
利用稀疏自编码从图像块中自适应的学习特征算子。稀疏自编码是一种包含一个隐含层的神经网络,主要根据输入图像进行编码和解码,来得到图像的最佳编码方法,同时使得解码误差最小。根据目标优化公式(5)来同时优化目标特征的稀疏性和最小重构残差:
其中J(X,Z)是原始图像与经过解码后图像的残差和权值大小,其中X表示原始图像块,Z表示重构的图像块,i表示图像块编号,m表示图像块的数目(实施例中为20万),zi为图像块xi的重构结果,W表示目标函数的权值,也就是要学习到的特征提取算子,λ是约束项权值,用来约束W的数值大小,一般取值0.005。是神经元的稀疏度,KL表示Kullback-Leibler divergence[1],ρ是目标特征稀疏度,用来保持特征稀疏性,具体实施时可由本领域技术人员预先设置,一般取0-1,是当前特征稀疏度。β是稀疏度的权值,一般取值0-1。Y为总体误差函数。
实施例中,巧妙结合特征稀疏性目标函数和最小重构残差目标函数来进行最优特征的选取。特征稀疏性目标函数要求特征具有差异性,可以有效地学习特征的稀疏表达;最小重构残差目标函数计算特征的重构误差,学习特征的最优组合表达。所以在特征学习的过程中,同时使用特征稀疏性目标函数和最小重构残差为目标函数,学习特征的最优组合表达模型,同时确保特征的稀疏性。
[1]S.Kullback and R.A.Leibler,“On information and sufficiency,”Ann.Math.Stat.,vol.22,pp.79–86,1951.
步骤4,通过数据增强和随机丢弃来进一步增强学习到的图像块特征表达。由于神经网络训练需要大量的数据,而目前难以获取。实施例通过对图像进行随机旋转平移,来达到数据增强的效果,并模拟不同数据之间的变化。同时为了进一步提高步骤3学习的数据特征表达,通过加入随机丢弃机制,即在网络训练过程中,随机的屏蔽部分神经元,加入随机性,使特征更加稳健[2]。
[2]G.E.Hinton,N.Srivastava,A.Krizhevsky,I.Sutskever,and R.R.Salakhutdinov,“Improving neural networks by preventing co-adaptation of feature detectors,”Arxiv preprint arXiv:1207.0580,2012.
步骤5,求解和更新特征算子。根据步骤3的目标优化公式(5),利用随机梯度下降法[3]进行求解和更新特征算子。
[3]D.E.Rumelhart,G.E.Hinton,and R.J.Williams,“Learning representations by back-propagating errors,”Nature,vol.323,pp.533–536,1986.
步骤6,判断迭代是否达到最大训练次数,若达到最大训练次数则转至步骤7;否则转至步骤5。
步骤7,利用特征算子对图像进行卷积神经网络操作提取图像特征。
图2为卷积神经网络提取图像特征的原理图,输入一幅高分辨率图像的数据,有k=3个波段。首先利用学习到的特征算子对图像进行卷积操作,其中n是输入图像的大小(如n×n),w是特征算子的大小(如w×w),s是卷积操作的步长,表示间隔几个像素进行一次卷积操作,最后得到大小为(n-w)/s+1的特征图。k代表的是特征算子的个数,经过k个特征算子的卷积操作,可以得到k幅特征影像,即k个波段,得到对应的特征图,特征图是由每一个特征算子得到的。利用特征图,继续进行池化操作,缩小特征图的维度,得到更有效的特征。池化是一种特征统计方式,特征图按照网格平均划分,然后求取每一个网格的均值或者最大值。如图2所示,特征图划分成4×4的网格,每个网格求取其中的最大值,得到池化后的特征图。最后对特征图进行向量化,每个特征图对应16维的特征,全连接后得到k×16(图中记为k*16)维度的最终分类特征,以此输入支持向量机进行分类。
步骤8,利用支持向量机[4]进行场景识别。
[4]Cortes C,Vapnik V.Support-vector networks[J].Machine learning,1995,20(3):273-297.
以上是本发明实施例涉及的基于显著度的非监督特征学习方法的实现步骤。通过显著度检测算法、稀疏自编码学习、数据增强和随机丢弃的引入,可以在较合理的时间代价下,提取数据的非监督特征学习算子。
在具体实现的时候还有以下注意事项:
在寻优阶段的最大迭代次数设置方面,由于初始值是随机设置的,所以可能需要较多的迭代来寻找到特征算子的最优解;随机丢弃又引入了更多的随机性,算法收敛速度较慢,本领域技术人员可自行根据经验值预设最大迭代次数。
具体实施时,本发明所提供方法可基于软件技术实现自动运行流程。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的。因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!