大数据量预测的三层联合动态选择最优模型方法与流程
本发明涉及一种大数据量预测的三层联合动态选择最优模型方法。
背景技术:
现在每天生成的数据高达250兆亿个字节,超过过去两年里生成的数据总量的90%。大量的数据,以结构化的形式存储于计算机。这些数据被结构化后,在方便储存的同时,也失去了逻辑上的关联,比如,通讯上相邻的两个小区之间,彼此影响,相互因果,并以某种模式延续到未来,而存储在计算机里的,只是两列数据,并无关联和模式,实际情况下,可能是无数列这样的数据,这让关联和模式隐藏的更深,形式更复杂。在如此大量而复杂的数据中,要发现关联、捕捉模式,以预测未来,需要一个稳定而准确的模型,这对现有算法提出了更高的要求。
为了获得这样一个理想模型,分析常规建模过程是有必要的。基于大量数据预测时,首先是借助统计和可视化的方法,分析数据的特征,比如,是线性的还是非线性的,周期多少,滞后期多少,呈何种分布等等,如果到这步还没有清晰的特征,就需要对数据进行数学转换,转换后的数据继续上述步骤,直到得到清晰的数学特征,然后是基于数学特征建模。这种建模流程固然很好,且绝大多数情况下能很好的实现目标。然而,有时候这么做会有问题。
第一个问题是,模型可能会选择错误,假设模拟产生某列数据,符合周期逐渐变小的震荡的数学特性(假定是周期渐小的正弦),并且让它的周期特别大,大到在一定范围内看,局部分布是呈线性的,但从足够的远期看,才能看到它的庐山真面目。在一段时间内,它的模式很可能被错误捕捉,实际运用中,如果数据不够多,或者数据没有累计到一定程度,那么,在选用模型时,很可能会有问题。而且,一旦选用了某个模型,很可能没有机会再去选用别的,甚至也不能修正模型本身,因为在一开始模型就被评估的很好,然后就进入正式开发,放入工程中,当数据增加或情况改变时,也不会再考虑重新选择模型。随着数据的积累或者在预测长期的数据时,问题就会凸现,预测效果会变得很差。
第二个问题是,当要预测大量不同数据时,需要针对每列数据选择一个模型,这样,需要花大量时间在模型甄选上,即使这样做了,仍然不能避免上述的问题--模型选择错误,而希望每个模型的选择流程都简单而科学,模型预测结果稳定而相对准确。
第三个问题是,无法实现快速动态预测。当有一列新的数据需要建模和预测时,需要重新开始建模流程,分析,建模,评估。显然,这不能满足快速动态的进行预测。而希望这列数据像其他已经建模完的数据一样,能智能地选用某个现成的模型,进行预测和相关处理,并能保证结果的准确性。
技术实现要素:
为了解决上述问题,本发明针对三个问题进行了具体的分析,发现三个问题的一些共同之处,大数据量时,预测值与观测值常常有较大误差,误差会随着预测长度的增加而增大。为了避免误差过大,本发明提供一种大数据量预测的三层联合动态选择最优模型方法,在预测时,可以动态地选择最合适的模型,摒弃预测效果不好的模型,这样做一方面,保证了效果的稳定型,另一方面将误差控制在合理的范围内。
本发明的技术解决方案是:
一种大数据量预测的三层联合动态选择最优模型方法,包括预测模型算法库、权重算法库、最优权重算法甄选算法三层,预测模型算法库放置在的最底层,在预测算法模型库之上是权重算法库,在权重算法库之上是最优权重算法甄选算法;
预测模型算法库:包含若干种预测模型算法,这些算法被抽象成共同的接口,放置在联合算法的最底层,提供预测功能,支撑更上层的功能;
权重算法库:对预测算法库的最底层算法的多样性进行屏蔽,根据底层算法的预测结果,按若干种标准对底层算法进行甄选组合,形成若干种权重算法;
最优权重算法甄选算法:根据验证集中权重算法的效果,选择最优的权重算法,进行预测。
进一步地,预测模型算法库具体的实现步骤如下。
输入训练数据;对训练数据预处理后,得到待用数据;
使用两种以上的不同算法对待用数据进行模型拟合,得到各待选模型。
进一步地,对训练数据预处理,具体包括:
数据筛选:去除过于稀疏的数据列;
时间格式的处理:将时间列映射为连续的整数;
数据补值:缺失数据插值、错误数据插值。
进一步地,权重算法采用如下算法:
算法一:给予所有预测模型相同的权重;
算法二:剔除百分之二十预测结果相对较差的模型,并给予剩下的模型相同的权重;
算法三:计算各模型误差均方根,然后根据误差均方根大小,设计一个反趋势的函数,并根据该函数给各模型赋予权重;
算法四:计算各模型最小绝对误差,然后根据最小绝对误差大小,设计一个反趋势的函数,并根据该函数给各模型赋予权重;
算法五:计算各模型最小二乘计算的误差,然后根据最小二乘计算的误差大小,设计一个反趋势的函数,并根据该函数给各模型赋予权重;
算法六:计算各模型赤池信息量准则,然后根据赤池信息量准则大小,设计一个反趋势的函数,并根据该函数给各模型赋予权重。
进一步地,预测模型算法库具体的实现步骤如下:
调用预测模型库,得到预测模型的预测数据集;
分别调用各个权重算法,并计算权重;
赋予各预测模型相应权重,进行数据预测,存储预测的数据。
进一步地,最优权重算法依据各权重算法在测试集上的预测效果,来甄选最优权重算法;最优权重算法甄选算法的具体步骤如下:
调用权重算法库的算法,得到权重预测的数据的集合;
利用权重库预测的数据集,与验证集比对,得到误差;
由最小误差,得到最优权重算法;
将最优权重方法预测的数据存储,得到预测结果。
本发明的有益效果是:本发明一种大数据量预测的三层联合动态选择最优模型方法,三层结构具有高扩展性、预测稳定性、模型的动态调整特性、预测数据对模型的无差异性这四种特性。本申请运用了联合算法,该算法规避了常用算法的一些缺点,利用赋予多种模型权重的方法,将多种算法有机地组合在一起,将最适应的算法赋予高权重,而将相对不好的算法赋予的低的权重,这样既保证了数据预测的准确性,也保证了数据长度增加后,预测的稳定性。
附图说明
图1是本发明实施例大数据量预测的三层联合动态选择最优模型方法的说明示意图。
图2是实施例中ARIMA算法KPI综合误差率的示意图。
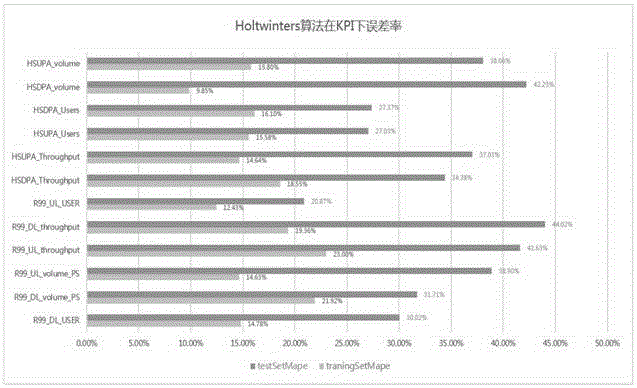
图3是实施例中Holtwinters算法在KPI下误差率的示意图。
图4是实施例中Arima算法KPI下误差率的示意图。
具体实施方式
下面结合附图详细说明本发明的优选实施例。
在小区KPI预测时,需要预测的数据准确而稳定,但是实际运用中往往不好,这是因为,一般算法有一定的局限性和适用性,导致有的数据预测不好。在这种情况下,实施例运用了联合算法,该算法规避了常用算法的一些缺点,利用赋予多种模型权重的方法,将多种算法有机地组合在一起,将最适应的算法赋予高权重,而将相对不好的算法赋予的低的权重,这样既保证了数据预测的准确性,也保证了数据长度增加后,预测的稳定性。随后,将联合算法运用于实验中,取得了预期的效果,在稳定性和准确性方面都取得了具佳的效果。
实施例
如图1,大数据量预测的三层联合动态选择最优模型方法由预测模型算法库、权重算法库、最优权重算法甄选算法三层组成。
预测模型算法库包含了各种经典算法、经典算法改进型及部分专利算法,这些算法被抽象成共同的接口,放置在联合算法的最底层,提供预测功能,支撑更上层的功能。
在预测算法模型库之上是权重算法,权重算法对预测算法库进行了一层包装,屏蔽了最底层算法的多样性,用户不需要考虑底层各种算法的参数、周期、收敛性、误差等,权重算法根据底层算法的预测结果,按若干种标准(如,将所有底层算法结果做平均、摒弃部分最差的结果、按RMSE结果分配权重、按OLS结果分配权重、按AIC结果分配权重、按LAD结果分配权重)对底层算法进行甄选组合,形成若干种权重算法。
这若干种权重算法没有物理意义上的差别,只有数学特性上的差异,这些差异既来源于预测数据本身的特性,也与选取的权重公式有关,这些权重算法适应不同的数据,在确定具体选用哪种权重算法之前,我们需要根据验证集的结果来判断。而这样的判断,我们希望有一种算法自动完成,这就是联合算法里的第三层--最优权重算法甄选算法,第三层算法是对权重算法的包装,根据验证集中权重算法的效果,选择最优的权重算法,进行预测。
大数据量预测的三层联合动态选择最优模型方法的三层结构具有高扩展性、预测稳定性、模型的动态调整特性、预测数据对模型的无差异性这四种特性。然而,这种算法也有她的不足之处--低效性。在权衡了计算机软硬件性能的高速发展,以及分布式技术的快速成熟后,相对于其它四大特性,她的不足显得微不足道。
大数据量预测的三层联合动态选择最优模型方法的最底层的预测模型算法库包含了各种经典算法、经典算法改进型及部分专利算法。这些算法包括ar,mr,arma,holtwinters,var,svar,svec,garch,svm,fourier。这些算法有各自的适用场景,比如平稳数列可用arma,arima,var,svar,svec,对于非平稳序列要做平稳化处理后方能使用平稳算法,除了平稳算法,其余算法的可以用于非平稳序列。对于高纬数据可以考虑用svm。多时间序列数据可以用var算法,而garch模型对于远期预测有一定的优势。另外,每种算法都包含了多种参数,比如arima的参数p,d,q在设置时就有多种组合。每种算法也会有若干变种算法,比如,svar和svec是var的变化,garch算法是arch的算法在使用范围上的扩展。不同算法之间对数据输入数据的格式也有差别,有些算法的训练集的预测数据和测试集的预测数据也不禁相同,比如HOLT-WINTERS的训练集中,训练集中第一个周期的边界值是不能预测的,而ARIMA是可以预测的。还有就是有些模型需要多重周期的,比如VAR,需要特别处理。
因为要对其上一层提供无差异接口,所以,所有上述差异因素需要被屏蔽。具体作法是,如果模型有多种参数的,按每种参数设置一个独立的模型,变种也设置独立的模型,如arima模型的参数p,d,q有32种组合,那么,我们就设置32种模型,如arima(1,1,0)和arima(2,1,0)就属于两种模型,另外,变种我们也单独设置了模型,如var和svec是同类模型的不同变种,我们也将其独立设置为不同模型。边界不能预测的模型,在计算误差时,边界值不考虑进去,如HOLT-WINTERS模型训练集的第一个周期的预测值是没有的,在计算误差时,这部分误差我们不计入整体误差,经评估,在实际预测时不计入部分的影响很小。多重周期的模型单独处理,预测后再拼成按时间顺序排列的数组,如VAR模型,VAR根据多重时间预测后的值是一个矩阵,我们将矩阵按行依次取值后存为一个数组,这样,数组中的值正好是按时间排序的值,使其和其他形式的预测结果格式统一,方便比较。
在预测算法库之上是权重算法库,权重算法库的原则是择优录用,即便如此,择优的原则仍然不是唯一的,或者说,这里的“优”难以确定,验证集的“优”可能无法延续到更远的未来,比如过拟合的模型,在验证集表现得很好,在预测集却不然。因此,权重算法库选用了六种权重方法,如概述中涉及。
这六种权重算法按各自的原则,对预测模型库中结果进行甄选组合,形成六种算法,这六种算法侧重不一,这样做的目的是尽量捕捉多的数据特性,希望这种特性能很好的延续到预测集,即便不能,也能动态地调整参数,使“坏”的模型的影响降低,增加预测的准确性。
这六种权重算法分别是:
1)给予所有预测模型相同的权重,w=1/n,n为模型数;
2)对所有模型误差(e1,e2,...,en)进行排序,筛选误差较小的80%的模型,并给予余下模型相同的权重wnew,wnew=1/m,m为筛选后的模型个数;
3)计算各模型误差均方根(RMSE),然后根据误差均方根大小,设计一个反趋势的函数,并根据该函数给各模型赋予权重,
w=g(f(e1,e2,,en)),ei=error_value;
f~f(1/rmse(x1,x2,,xn;y1,y2,,yn)),xi=forecast_value,yi=observation_value;;
上式子中ei表示第i个模型的误差,xi表示第i个变量的预测值,yi表示第i个变量的观察值,g则按式中定义了一个反趋势函数。
4)跟3)原理一样,依据的原则是最小绝对误差;
5)跟3)原理一样,依据的原则是最小二乘计算的误差;
6)跟3)原理一样,先计算赤池信息量准则(AIC),据此设计反趋势函数,然后计算权重。
预测模型算法库具体的实现步骤如下。
输入:训练数据;
输出:权重模型库预测的数据;
调用预测模型库,得到预测模型的预测数据集data_fcst;
i为(1~权重算法数)中的一个整数,调用权重算法i,计算权重。
赋予各预测模型相应权重,进行数据预测,存储预测的数据。
最上层是最优权重算法甄选算法,在六种权重算法的基础上,最优权重算法甄选算法选择其中最好的权重算法,选择的原则是六种权重算法在测试集上的预测效果。
最优权重算法甄选算法具体的实现步骤如下。
输入:训练数据
输出:预测的数据
1)调用权重算法库的算法,得到权重预测的数据的集合。
2)利用权重库预测的数据集,与验证集比对,得到误差。
3)由最小误差,得到最优权重算法。
4)将最优权重方法预测的数据存储,得到预测结果。
当多个指标下(KPI)多个数据列(CELL)预测时步骤如下:
输入:训练数据
输出:预测数据
对每个指标的每个数据列,调用最优权重算法甄选算法,得到预测的数据,将数据存储。
实验验证
为评估联合算法的效果,选取了1500个小区的12个KPI数据进行了实验,以得到联合算法和一般算法的准确性、稳定性的对比结果。
实验步骤如下:
首先是数据收集,数据的处理,按三层结构建立算法模型,分别运用联合算法和一般算法进行数据预测,得到预测结果。
然后整理两种算法的结果,比对联合算法模型和一般模型的准确性,稳定性,并以此综合评估联合算法模型的效果。
实验分为两部分,第一部分是将训练数据放到常用模型中训练,预测,以得到误差数据,接着将训练数据放到联合算法模型中训练,预测,得到误差数据。第二部分是将联合算法模型与一般模型训练集的误差,测试集的误差对比,以评估联合算法的效果。
实验数据
首先是数据的收集和处理,数据产生的频率是半小时,共收集了121天,1500个小区6个上行KPI和1500个6个下行KPI的的各5808个数据,即从2014年7月29日到2014年11月26日的数据。
为确保数据的完整性,需要对数据缺值和错误值进行处理。缺值和NaN值需要进行相应的插值,如果NaN和缺值过多的情况下,则需要剔除该小区的数据。
实验方法
首先将训练数据放到一般模型中训练,预测,将每个模型得到的预测数据和误差数据保存,接着将训练数据放到联合算法模型中训练,预测,将得到预测数据和误差数据保存。最后是对比联合算法和一般模型的预测效果,分别计算一般模型和联合算法在训练集预测误差、预测集上的预测误差、训练集的预测误差与预测集的预测误差之差。分别给这三个值一个权重,取0.3,0.3,0.4。最后得到综合误差值。
实验结果
在运用联合算法和一般算法对比后,分别得到了1500个小区12个KPI训练集和测试集的误差如图2、图3、图4。图2是实施例中ARIMA算法KPI综合误差率的示意图。图3是实施例中Holtwinters算法在KPI下误差率的示意图。图4是实施例中Arima算法KPI下误差率的示意图。
由图2、图3、图4得到的数据可知,联合算法的误差在训练集和预测集上比一般算法分别提高9%和13%左右。综合误差值提高在12%左右。
- 还没有人留言评论。精彩留言会获得点赞!