一种洗钱账户的确定方法及装置与流程
本发明涉及计算机
技术领域:
,尤其涉及一种洗钱账户的确定方法及装置。
背景技术:
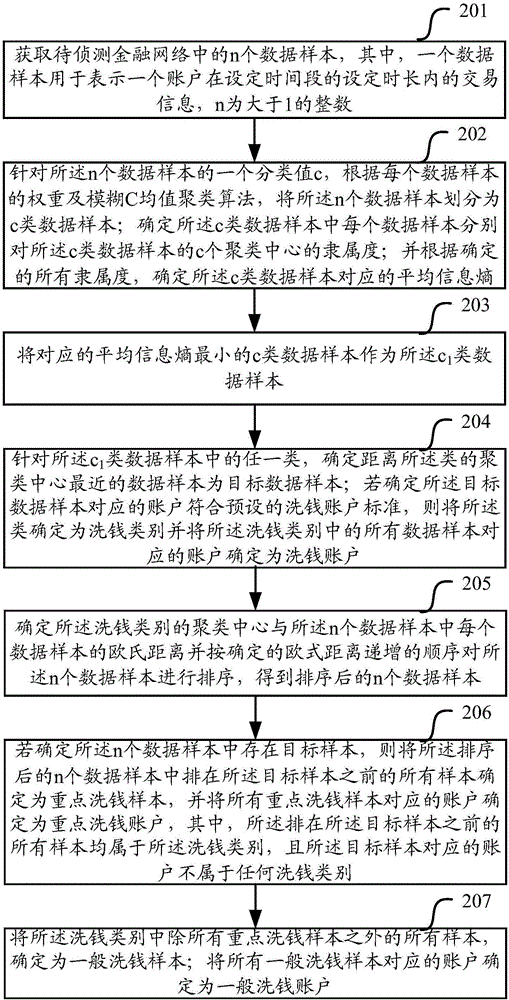
:在金融网络中存在着洗钱账户,进行着非法交易,洗钱账户是金融网络中洗钱路径中的节点,如何从错综复杂的金融网络中找到可疑洗钱账户,对打击洗钱行为有重要意义。现有技术在查找洗钱账户时,存在一种首先对待测金融网络中的所有数据样本进行分类,然后根据分类的数据样本,找到每个类中的孤立点数据样本,最终将孤立点数据样本对应的账户确定为洗钱账户。上述方法主要存在的问题是:第一,上述方法在对所有数据样本进行分类时,是根据每个数据样本的系数来分类的,其中,一个数据样本的系数是根据数据样本之间的欧式距离来定义的,该种系数定义方法不能很好地反映数据样本之间的内在联系,因而不能很准确地得到数据样本的最佳分类;第二,上述方法在得到数据样本的分类之后,是根据每个分类中的孤立点来确定最终的洗钱账户,这种方法对于识别像贪腐腐败等偶然行为的洗钱账户是有效的,但对于像非法集资、诈骗洗钱、地下钱庄等具有连续洗钱活动的账户,则无能为力。综上所述,现有技术中的洗钱账户侦测,存在侦测准确率不高,且无法侦测具有连续洗钱活动行为的账户。技术实现要素:本发明提供一种洗钱账户的确定方法及装置,用以解决现有技术存在的在洗钱账户侦测时,侦测准确率不高,且无法侦测具有连续洗钱活动行为的账户的技术问题。一方面,本发明实施例提供一种洗钱账户的确定方法,包括:获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的,所述平均信息熵是根据所述n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度,m为正整数;针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。可选地,所述根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,包括:针对所述n个数据样本的一个分类值c,根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的隶属度;并根据确定的所有隶属度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本,包括:确定c个聚类中心初始值;根据所述c个聚类中心的初始值,确定所述n个数据样本对应的隶属度矩阵,以及根据确定的所述n个数据样本对应的隶属度矩阵,确定所述n个数据样本对应的目标函数值;根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心;根据更新后的所述c类数据样本中每个类的聚类中心,更新所述隶属度矩阵;根据更新后的所述隶属度矩阵及更新后的所述c类数据样本中每个类的聚类中心,更新所述n个数据样本对应的目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则根据更新后的所述隶属度矩阵,将所述n个数据样本划分为c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则返回到根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心的步骤。可选地,所述将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户之后,还包括:确定所述洗钱类别的聚类中心与所述n个数据样本中每个数据样本的欧氏距离并按确定的欧式距离递增的顺序对所述n个数据样本进行排序,得到排序后的n个数据样本;若确定所述n个数据样本中存在目标样本,则将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户,其中,所述排在所述目标样本之前的所有样本均属于所述洗钱类别,且所述目标样本对应的账户不属于任何洗钱类别。可选地,所述将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户之后,还包括:将所述洗钱类别中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Σi=1cΣj=1nρjμij2dij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n,]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,ρj为数据样本xj的权重,dij为第i个聚类中心与数据样本xj之间未加权的的欧氏距离。可选地,根据下列公式确定所述c个聚类中心初始值:Dk*=max{Di(k),i=1,2,...,n},k=2,3,...,c,]]>Di(k)=Di(k-1)-rm1(xi,xk-1*)*Dk-1**e-||xi-xk-1*||m2,k=2,3,...,c,i=1,2,...,n,]]>D1*=max{Di(1),i=1,2,...,n},]]>其中,表示当前n个数据样本中每个数据样本的样本密度中的最大值,表示对应的数据样本且表示第k个聚类中心的初始值(k=1,2,...,c),用于对所述n个数据样本的样本密度进行更新,表示数据样本xi与数据样本之间的皮尔逊相关系数,表示数据样本xi与数据样本之间的欧式距离,m1和m2为预设的系数。可选地,根据下列公式确定一个数据样本的权重:ρi=density(i)Σh=1ndensity(h),]]>density(i)=Σh=1,h≠inr2(i,h)1dihe-dih2,]]>dih=Σj=1mwj2(xij-xhj)2,]]>r(i,h)=Σj=1m(wjxij-x‾i)(wjxhj-x‾h)Σj=1m(wjxij-x‾i)2Σj=1m(wjxhj-x‾h)2,]]>x‾i=1mΣj=1mwjxij,]]>x‾h=1mΣj=1mwjxhj,]]>其中,ρi表示第i个数据样本的权重,i=1,2,...,n,density(i)表示第i个数据样本的样本密度,r(i,h)表示数据样本xi与数据样本xh之间的皮尔逊相关系数,wj表示所述n个数据样本的第j个属性的权重,xij表示数据样本xi的第j个属性值,m表示所述n个数据样本中每个数据样本包含的属性数量,dih表示数据样本xi与数据样本xh之间加权的欧氏距离。可选地,根据下列公式确定所述n个数据样本的属性权重:wj=HPjΣj′=1mHPj′,]]>HPj=CVj*HjCVj2+Hj2,]]>CVj=σjμj,]]>Hj=-Σk=1Kpjklog2(pjk),]]>μj=1KΣk=1KNjk=nK,]]>σj=1KΣk=1K(Njk-μj)2,]]>pjk=NjkΣk′=1KNjk′,]]>其中,wj表示所述n个数据样本的第j个属性的权重,CVj为属性j的离散系数且用于表示属性j偏离均匀分布的程度,Hj为属性j的信息熵且用于表示属性j的有序结构情况,并且,K是根据下列方式得到的:以所述n个数据样本在第j个属性上的最小值为起点,以所述n个数据样本在第j个属性上的最大值为终点,等划分成K组;Njk表示所述K组中第k组中的数据样本的个数(k=1,2,...,K)。另一方面,本发明实施例提供一种洗钱账户的确定装置,包括:数据样本获取单元,用于获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;数据样本划分单元,用于根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的,所述平均信息熵是根据所述n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度,m为正整数;洗钱账户确定单元,用于针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。可选地,所述数据样本划分单元,具体用于:针对所述n个数据样本的一个分类值c,根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的隶属度;并根据确定的所有隶属度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述数据样本划分单元,具体用于:确定c个聚类中心初始值;根据所述c个聚类中心的初始值,确定所述n个数据样本对应的隶属度矩阵,以及根据确定的所述n个数据样本对应的隶属度矩阵,确定所述n个数据样本对应的目标函数值;根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心;根据更新后的所述c类数据样本中每个类的聚类中心,更新所述隶属度矩阵;根据更新后的所述隶属度矩阵及更新后的所述c类数据样本中每个类的聚类中心,更新所述n个数据样本对应的目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则根据更新后的所述隶属度矩阵,将所述n个数据样本划分为c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则返回到根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心的步骤。可选地,所述洗钱账户确定单元还用于:将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户之后,确定所述洗钱类别的聚类中心与所述n个数据样本中每个数据样本的欧氏距离并按确定的欧式距离递增的顺序对所述n个数据样本进行排序,得到排序后的n个数据样本;若确定所述n个数据样本中存在目标样本,则将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户,其中,所述排在所述目标样本之前的所有样本均属于所述洗钱类别,且所述目标样本对应的账户不属于任何洗钱类别。可选地,所述洗钱账户确定单元还用于:将所述洗钱类别中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Σi=1cΣj=1nρjμij2dij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n,]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,ρj为数据样本xj的权重,dij为第i个聚类中心与数据样本xj之间未加权的的欧氏距离。可选地,所述数据样本划分单元,还用于根据下列公式确定所述c个聚类中心初始值:Dk*=max{Di(k),i=1,2,...,n},k=2,3,...,c,]]>Di(k)=Di(k-1)-rm1(xi,xk-1*)*Dk-1**e-||xi-xk-1*||m2,k=2,3,...,c,i=1,2,...,n,]]>D1*=max{Di(1),i=1,2,...,n},]]>其中,表示当前n个数据样本中每个数据样本的样本密度中的最大值,表示对应的数据样本且表示第k个聚类中心的初始值(k=1,2,...,c),用于对所述n个数据样本的样本密度进行更新,表示数据样本xi与数据样本之间的皮尔逊相关系数,表示数据样本xi与数据样本之间的欧式距离,m1和m2为预设的系数。可选地,所述装置还包括数据样本权重确定单元,用于根据下列公式确定一个数据样本的权重:ρi=density(i)Σh=1ndensity(h),]]>density(i)=Σh=1,h≠inr2(i,h)1dihe-dih2,]]>dih=Σj=1mwj2(xij-xhj)2,]]>r(i,h)=Σj=1m(wjxij-x‾i)(wjxhj-x‾h)Σj=1m(wjxij-x‾i)2Σj=1m(wjxhj-x‾h)2,]]>x‾i=1mΣj=1mwjxij,]]>x‾h=1mΣj=1mwjxhj,]]>其中,ρi表示第i个数据样本的权重,i=1,2,...,n,density(i)表示第i个数据样本的样本密度,r(i,h)表示数据样本xi与数据样本xh之间的皮尔逊相关系数,wj表示所述n个数据样本的第j个属性的权重,xij表示数据样本xi的第j个属性值,m表示所述n个数据样本中每个数据样本包含的属性数量,dih表示数据样本xi与数据样本xh之间加权的欧氏距离。可选地,所述数据样本权重确定单元,还用于根据下列公式确定所述n个数据样本的属性权重:wj=HPjΣj′=1mHPj′,]]>HPj=CVj*HjCVj2+Hj2,]]>CVj=σjμj,]]>Hj=-Σk=1Kpjklog2(pjk),]]>μj=1KΣk=1KNjk=nK,]]>σj=1KΣk=1K(Njk-μj)2,]]>pjk=NjkΣk′=1KNjk′,]]>其中,wj表示所述n个数据样本的第j个属性的权重,CVj为属性j的离散系数且用于表示属性j偏离均匀分布的程度,Hj为属性j的信息熵且用于表示属性j的有序结构情况,并且,K是根据下列方式得到的:以所述n个数据样本在第j个属性上的最小值为起点,以所述n个数据样本在第j个属性上的最大值为终点,等划分成K组;Njk表示所述K组中第k组中的数据样本的个数(k=1,2,...,K)。本发明实施例,获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的,所述平均信息熵是根据所述n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度,m为正整数;针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中,该分类方式是一个最佳分类,并且一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的;以及针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。本发明实施例一方面,根据n个数据样本的m个属性的权重得到每个数据样本的属性,将数据样本的属性进行了内在地联系,因而最终可以提高洗钱账户的识别准确率;另一方面,在确定洗钱账户时,是将符合预设的洗钱账户标准一个洗钱类别中的所有账户确定为洗钱账户,从而可以确定出具有连续交易特性的洗钱账户。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的一种洗钱账户的确定方法流程图;图2为本发明实施例提供的一种洗钱账户的确定方法详细流程图;图3为本发明实施例提供的一种洗钱账户的确定装置示意图。具体实施方式为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。下面结合说明书附图对本发明实施例作进一步详细描述。如图1所示,本发明实施例提供的一种洗钱账户的确定方法,包括:步骤101、获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;步骤102、根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的,所述平均信息熵是根据所述n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度,m为正整数;步骤103、针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。在待侦测金融网络中,有很多账户,其中有些账户是洗钱账户,从事着非法洗钱交易,如何侦破获取这些洗钱账户对打击洗钱犯罪活动有着重大意义。本发明方法通过以上步骤101~步骤103可以实现找到可疑洗钱账户。上述步骤101中,首先获取待侦测金融网络中的n个数据样本,其中一个数据样本表示一个账户在设定时间段的设定时长内的交易信息,且n为大于1的整数。举例来说,假设设定时间段为最近一个月(假设有30天),设定时长为10天,则每个账户对应有3个数据样本;再比如,假设设定时间段为一年时间,设定时长为1个月,则每个账户对应有12个数据样本。可选地,本发明实施例中,对于得到的n个数据样本中的每个数据样本,定义为一个8维向量(当然也可以不是8维向量,根据实际需要来定义),具体地,任意一个数据样本xi形式如下:xi=(Tai0,Tai1,Tai2,Tadi0,Tadi1,Tadi2,Tfwi,Tfdi)。其中,Tai0表示在设定时间段的设定时长内的总交易金额,Tai1表示在设定时间段的设定时长内的总转出交易金额,Tai2表示在设定时间段的设定时长内的总转入交易金额,Tadi0表示交易金额离散系数,Tadi1表示转出金额离散系数,Tadi2表示转入金额离散系数,Tfwi表示转出频率,Tfdi表示转入频率,其中所述交易金额离散系数Tadi0为数据样本在设定时间段的设定时长内交易金额方差与交易金额均值的比值,所述转出金额离散系数Tadi1为数据样本在设定时间段的设定时长内转出金额方差与转出金额均值的比值,所述转入金额离散系数Tadi2为数据样本在设定时间段的设定时长内转入金额方差与转入金额均值的比值。举例来说,假设设定时间段为一个月,设定时长为10天,则对于任意一个账户k,可以得到3个数据样本,假设分别为xk1,xk2,xk3,其中xk1表示在这一个月中的前10天的相关交易信息,xk2表示在这一个月中的中间10天的相关交易信息,xk3表示在这一个月中的后10天的相关交易信息,并且每个数据样本都是1个由8个量组成的向量。对于每个数据样本的8个分量,具体地,可以通过下列方式得到:1、总交易金额Tai0假设数据样本i在设定时长内总共有ni0笔交易,每笔交易金额taij按照时序排列为则数据样本的总交易金额为:2、总转出交易金额Tai1假设数据样本i在设定时长内总共有ni1笔转出交易,每笔交易金额tbij按照时序排列为则数据样本的总转出交易金额为:3、总转入交易金额Tai2假设数据样本i在设定时长内总共有ni2笔转出交易,每笔交易金额tcij按照时序排列为则数据样本的总转出交易金额为:4、交易金额离散系数Tadi0假设数据样本i在设定时长内总交易金额均值为:总交易金额的方差为则交易金额离散系数Tadi0为:5、转出金额离散系数Tadi1假设数据样本i在设定时长内总转出交易金额均值为:总转出交易金额的方差为则转出金额离散系数Tadi1为:6、转入金额离散系数Tadi2假设数据样本i在设定时长内总转入交易金额均值为:总转入交易金额的方差为则转入金额离散系数Tadi2为:7、转出频率Tfwi将数据样本i在设定时长内转出交易次数与总交易次数的比值,定义为转出频率Tfwi。8、转入频率Tfdi将数据样本i在设定时长内转入交易次数与总交易次数的比值,定义为转入频率Tfdi。通过上述步骤101,可以得到n个数据样本,假设这n个数据样本构成的集合为X={x1,x2,…,xn}。上述步骤102中,根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,信息熵是信息论中的概念,当信源发出的信息越确定,其信息熵越小,因此在本发明中当分类的划分越合理,数据样本偏向于分类中心越确定,即表明该分类的信息熵越小。因此满足条件的c1类是最合理的分类。在对上述步骤102进行具体介绍之前,首先对本发明实施例中将要用到的一些参数进行解释说明。一、确定每个数据样本的权重本发明实施例中,一个数据样本的权重是根据n个数据样本的m个属性的权重得到的,具体地确定方式有很多种,例如将n个数据样本在第j个属性的属性值之和与所述n个数据样本在所有属性的属性值之和的比值,作为第j个属性的权重,然后继续对每个属性进行加权,从而得到一个数据样本的权重。下面将介绍另外一种更为复杂和全面的确定一个数据样本的权重的方式,该方法可以突出数据样本中的重要属性对聚类过程的作用,并采用基于皮尔逊相关系数的密度函数为数据样本加权,解决模糊C均值聚类算法对数据样本进行等划分的问题。1、确定所述n个数据样本中的m个属性权重对于给定的数据集合X={x1,x2,…,xn},它的第i个数据样本为xi=(xi1,xi2,…,xij,…,xim),其中xij是样本点xi的第j个属性(也就是第j维度),m表示所述n个数据样本中每个数据样本包含的属性数量(即数据样本的维数,并且n个数据样本的属性维度相同,均为m)。为了得到全体数据样本在第j个属性上的分布情况,我们将所述n个数据样本在第j个属性上的最小值为起点,以所述n个数据样本在第j个属性上的最大值为终点,等划分成K组,每组长度为然后统计出所述K组中第k组中的数据样本的个数,用Njk表示,显然,通过上述划分我们得到一组数据:Nj1,Nj2,…,Njk,…,NjK。以此为基础,我们可以求出第j个属性的离散系数CVj和信息熵Hj:其中,这里,CVj为属性j的离散系数且用于表示属性j偏离均匀分布的程度,CVj取值越大说明属性j越集中于某些区域,然而当它取值太大时,很可能是属性j过度集中于一两个区域,如果聚类数目c>2,则它不利于区分不同类别。Hj为属性j的信息熵且用于表示属性j的有序结构情况,Hj越小则越有序,代表此时形成了一个聚集中心,然而当它取值过小时,很可能是属性j过度集中于某个区域。由以上分析可知,当CVj和Hj都取适当值时最有利于聚类过程,因此综合两者的作用,得到“波动-有序变量”,由它衡量属性j对聚类过程的贡献。对它进行归一化,可以求出第j个属性的权重值:其中,wj表示所述n个数据样本的第j个属性的权重。2、确定所述n个数据样本中每个数据样本的样本密度为了求出基于皮尔逊相关系数的样本密度,首先需要求出任意两个样本点之间的皮尔逊相关系数。对于任意两个样本点xi=(xi1,xi2,…,xij,…,xim)、xh=(xh1,xh2,…,xhj,…,xhm),它们之间的皮尔逊相关系数为:其中,r(i,h)表示数据样本xi与数据样本xh之间的皮尔逊相关系数。x‾i=1mΣj=1mwjxij,x‾h=1mΣj=1mwjxhj.]]>在本发明实施例中,取密度函数为(当然,根据实际需要也可以去其他密度函数),则数据样本xi的样本密度定义为:其中,density(i)表示第i个数据样本的样本密度,是加权后两个数据样本之间的欧氏距离。由于同一个聚类中的两个数据样本的皮尔逊相关系数一般较大,而不同类别的两个数据样本的皮尔逊相关系数一般比较小,因此上面的样本密度公式中包含有r(i,h),就是为了突出数据样本在同类中的密度大小,减弱其它类对它的干扰。对样本密度进行归一化,就得到了每个数据样本的权重:其中,ρi表示第i个数据样本的权重,i=1,2,...,n因而,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的。二、确定一个聚类对应的平均信息熵定义类的平均信息熵,这里引入平均信息熵,是为了帮助我们确定数据集的最终聚类数目,定义平均信息熵为:需要说明的是,信息熵是信息论中的概念,当信源发出的信息越确定,其信息熵越小。在模糊聚类中,当聚类的划分越合理,则它信息熵越小,因此我们可以根据这个来确定聚类数目c的最终取值。其中,μij表示在C模糊均值聚类算法中数据样本xj对第i个聚类的隶属度,因而本发明实施例中的平均信息熵是根据n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度。三、对传统模糊C均值聚类算法的中的目标函数的重新定义假设数据样本集合X={x1,x2,…,xn}将被分成c类,{A1,A2,…,Ac}表示相应的c个类,U是一个c*n的隶属矩阵且μij为U中的元素,U中的任意一个元素μij表示数据样本xj对第i个聚类的隶属度,各类别的聚类中心为{v1,v2,…,vc},本发明中,将模糊C均值聚类算法对应的目标函数定义为:Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n,]]>其中,ρj为数据样本xj的权重,dij为第i个聚类中心与数据样本xj之间未加权的的欧氏距离。其中,vi为聚类中心更新公式,μij为隶属度矩阵更新公式。在传统的模糊C均值聚类算法中,将目标函数定义为其中不包含样本权重ρj,而本发明中将模糊C均值聚类算法对应的目标函数进行重新定义,主要在传统的模糊C均值聚类算法对应的目标函数中增加了样本权重ρj,之所以如此定义,原因在于:由于基于传统的目标函数的划分方法,每个样本对最终划分结果的影响程度相同的,然而实际应用中不同的账户在洗钱的频繁程度、交易金额的大小等方面都是不一样的,因此金融交易数据的分布不可能是均匀或对称的,传统的模糊C均值聚类算法对数据集的样本等划分特性将造成很大的误差;而本发明中在目标函数中增加了样本权重ρj之后,表明每个数据样本对最终的分类结果造成的影响程度是不一样的,因而可以得到的样本划分结果也更加真实和准确。在有了以上关于数据样本的权重、聚类对应的平均信息熵、模糊C均值聚类算法对应的目标函数的定义之后,下面对步骤102中,将n个数据样本划分为c1类数据样本的具体过程做详细描述,其中,c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小。可选地,所述根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,包括:针对所述n个数据样本的一个分类值c,根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的隶属度;并根据确定的所有隶属度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本,包括:确定c个聚类中心初始值;根据所述c个聚类中心的初始值,确定所述n个数据样本对应的隶属度矩阵,以及根据确定的所述n个数据样本对应的隶属度矩阵,确定所述n个数据样本对应的目标函数值;根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心;根据更新后的所述c类数据样本中每个类的聚类中心,更新所述隶属度矩阵;根据更新后的所述隶属度矩阵及更新后的所述c类数据样本中每个类的聚类中心,更新所述n个数据样本对应的目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则根据更新后的所述隶属度矩阵,将所述n个数据样本划分为c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则返回到根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心的步骤。下面对上述分类方法做详细解释和说明。步骤1、初始化工作。设定变化量阈值为ε,确定初始聚类中心个数的取值范围[cmin,cmax]。一般取cmin=2,步骤2、在聚类中心数目c从c=cmin增加到c=cmax的过程中,对于任意确定的c,由以下步骤A~步骤E确定对应的隶属矩阵U=(μij)cxn,和此时的平均信息熵H(c):步骤A、求出m个属性权重值wj(j=1,2,...,m)、样本密度density(i)、数据样本的权重ρi,1≤i≤n;具体地,可以通过上述公式(7)、公式(9)、公式(10)来计算。步骤B、求出聚类中心的初始值对于c个聚类中每个聚类中心的初始值的设置方法,有很多种方法,例如可以是依次从n个数据样本中挑出权重最大的c个数据样本作为c个聚类中每个聚类中心的初始值;或者是从n个数据数据样本中随机选择c个数据样本作为c个聚类中每个聚类中心的初始值,本发明实施例不做具体限定。下面给出一种本发明实施例提供的确定c个聚类中每个聚类中心的初始值的方法。可选地,根据下列公式确定所述c个聚类中心初始值:其中,表示当前n个数据样本中每个数据样本的样本密度中的最大值,表示对应的数据样本且表示第k个聚类中心的初始值(k=1,2,...,c),用于对所述n个数据样本的样本密度进行更新,表示数据样本xi与数据样本之间的皮尔逊相关系数,表示数据样本xi与数据样本之间的欧式距离,m1和m2为预设的系数。其中,对于m1和m2的取值,可根据实际需要而定,例如可以将m1取值为2,以及将m2取值为2。举例来说,假设数据样本数量n=6,分别用N1,N2,N3,N4,N5,N6来表示。且假设当前c值等于3,则可以根据下列过程得到3个聚类的聚类中心初始值:第一步、计算每个数据样本对应的样本密度,假设分别为8.5,6.3,7.7,9.9,12.5,2.6;第二步、根据公式(17)得到第一个聚类中心的初始值数据样本N5;因为数据样本N5对应的样本密度最大,所以数据样本N5为第一个聚类中心的初始值。第三步、根据(公式16)更新每个数据样本的样本密度。假设更新后的6个数据样本的样本密度分别为:7.6,5.9,7.2,6.7,6.5,1.6;第四步、根据公式(15)得到第二个聚类中心的初始值数据样本N1;第五步、根据(公式16)更新每个数据样本的样本密度。假设更新后的6个数据样本的样本密度分别为:5,5.2,6,5.9,5.8,1;第四步、根据公式(15)得到第二个聚类中心的初始值数据样本N3。从而,根据以上步骤,即可得到3个聚类的初始聚类中心。由于上述方法来(公式16)中增加了相关系数这样做是为了最大限度削弱与同属一类的数据样本对后续选取初始聚类中心的干扰,同时尽可能保持其它类别的密度值不受影响。步骤C、根据(公式14)计算μij,由(公式12)求出目标函数的初始值J0;步骤D、根据(公式13)计算vi;步骤E、根据(公式14)计算μij;步骤F、根据(公式12)计算目标函数J,如果跟上次计算得到的目标函值相比,它们的更新变化量(更新变化量指的是此次计算得到的目标函数值与上次计算得到的目标函数值的差值)小于变化量阈值ε,则根据当前得到的隶属度矩阵,确定数据样本的分类方式,并且根据(公式11)计算该分类方式对应的平均信息熵;同时计算出此时的平均信息熵H(c);否则返回步骤D;具体地,对于一个隶属度矩阵U,可以根据下列方式得到c个分类:根据最大隶属度原则对数据集合X={x1,x2,…,xn}进行分类:在U=Ucxn的第k列中,如果则将xk归入第i1类。举例来说,假设数据样本数量n=6,分别用N1,N2,N3,N4,N5,N6来表示。假设当前要对c=2确定一个分类方式,当前隶属度矩阵U为:U=0.40.80.60.70.90.30.60.20.40.30.10.7]]>由于0.6>0.4,因此数据样本N1划分到第二类中;由于0.8>0.2,因此数据样本N2划分到第一类中,以此类推,得到的两个分类分别为:第一类:N2,N3,N4,N5;第二类:N1,N6。从而根据上述步骤A~步骤F,对于任意一个c值,都可以计算得到一种分类方式以及对应的平均信息熵。步骤3、对比聚类中心数目c在不同取值时的平均信息熵H(c),找到使平均信息熵H(c)取最小值的聚类中心数目c1,H(c1)=minH(c),从而最终的聚类数目为c1以及对应的分类方式。根据上述步骤1~步骤3,可以得到一个最佳分类c1及对应的分类方式。从而有利于提高最终确定洗钱账户的精度和准确度。基于上述步骤102中得到的一个最佳分类c1及对应的分类方式,下面通过步骤103,从该分类方式中找到洗钱账户。上述步骤103中,针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。因为洗钱行为有别于正常的账户交易行为,所以洗钱账户对应的数据样本跟正常账户对应的数据样本会聚集到不同的类别当中。同时,对于任何一个类i,它的类中心vi是该类所含数据点的最典型代表,因此我们只需抓取距离类中心vi最近的那个数据点,找到这个数据点对应的账户,再根据《金融机构大额交易和可疑交易报告管理办法》来判断该账户是否同时满足大额交易和可疑交易的标准,如果满足,则类i就是洗钱账户的数据样本集合,从而类i中任意一个数据样本对应的账户就是洗钱账户。具体过程如下:1)根据《金融机构大额交易和可疑交易报告管理办法》(即预设的洗钱账户标准)确定洗钱的类别。通过之前的聚类结果,我们可以得到c1个聚类中心:因为聚类中心是通过算法计算出来的,它们没有对应的真实账户,所以我们首先要找到距离聚类中心最近的那个数据样板及其对应的账户,假设距离vi最近的点为x1,x1对应的账户为Z1、距离v2最近的点为x2,x2对应的账户为Z2,……,距离最近的点为对应的账户为然后再根据《金融机构大额交易和可疑交易报告管理办法》判断哪些账户同时满足大额交易和可疑交易标准,假设最终Z1,Z2,…,Zk满足大额交易和可疑交易标准,那么对应的类1,类2,类k就是洗钱类别。2)找到洗钱账户。根据上述结果,我们已经知道类1,类2,……,类k就是洗钱类别,现在对类1,类2,……,类k中的任何一个数据样板,我们找到它们对应的账户,那么这些账户就是洗钱账户。通过上述过程,我们已经找到了所有洗钱账户。由于《金融机构大额交易和可疑交易报告管理办法》把洗钱账户划分为一般洗钱账户及重点洗钱账户,因此我们根据以下步骤来进一步划分一般及重点洗钱账户:可选地,所述将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户之后,还包括:确定所述洗钱类别的聚类中心与所述n个数据样本中每个数据样本的欧氏距离并按确定的欧式距离递增的顺序对所述n个数据样本进行排序,得到排序后的n个数据样本;若确定所述n个数据样本中存在目标样本,则将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户,其中,所述排在所述目标样本之前的所有样本均属于所述洗钱类别,且所述目标样本对应的账户不属于任何洗钱类别。可选地,所述将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户之后,还包括:将所述洗钱类别中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。下面详细说明上述确定一般洗钱账户和重点洗钱账户的方法。1)对于任何一个洗钱类别j(其中j=1,2,…,k),求出类中心vj与数据集X={x1,x2,…,xn}中任意一点xh之间的欧氏距离d(vj,xh),h=1,2,…,n,然后对它们进行从小到大排列,找到如下一个临界点(即目标样本),它满足两个条件:A)必须是不属于任何洗钱类别的数据样本,换言之它是属于正常交易类别的数据样板;B)所有满足的点xh,都必须属于洗钱类别j;则所有满足的点xh,它们对应的账户就是重点洗钱账户。2)将洗钱类别j中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。这里说明一下为何这样划分,因为类与类之间在属性空间上有可能存在交叉现象,只有那些距离洗钱类别的中心点最近的那些数据样本才是重点疑的,而那些处于与正常交易类别相交叉的区域中的点,是一般可疑的。通过以上所有步骤,我们不但找到了洗钱账户,还对洗钱账户进行了划分,得到了重点洗钱账户及一般可疑洗钱账户。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中,该分类方式是一个最佳分类,并且一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的;以及针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。本发明实施例一方面,根据n个数据样本的m个属性的权重得到每个数据样本的属性,将数据样本的属性进行了内在地联系,因而最终可以提高洗钱账户的识别准确率;另一方面,在确定洗钱账户时,是将符合预设的洗钱账户标准一个洗钱类别中的所有账户确定为洗钱账户,从而可以确定出具有连续交易特性的洗钱账户。下面对本发明实施例提供的一种洗钱账户的确定做详细描述,如图2所示,包括:步骤201、获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;步骤202、针对所述n个数据样本的一个分类值c,根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的隶属度;并根据确定的所有隶属度,确定所述c类数据样本对应的平均信息熵;在该步骤中,所述根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本,包括以下步骤:步骤A、确定c个聚类中心初始值;步骤B、根据所述c个聚类中心的初始值,确定所述n个数据样本对应的隶属度矩阵,以及根据确定的所述n个数据样本对应的隶属度矩阵,确定所述n个数据样本对应的目标函数值;步骤C、根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心;步骤D、根据更新后的所述c类数据样本中每个类的聚类中心,更新所述隶属度矩阵;步骤E、根据更新后的所述隶属度矩阵及更新后的所述c类数据样本中每个类的聚类中心,更新所述n个数据样本对应的目标函数值;步骤F、判断所述目标函数值的更新变化量是否小于或等于变化量阈值;若是,则转到步骤G,若否,则转到步骤C;步骤G、根据更新后的所述隶属度矩阵,将所述n个数据样本划分为c类数据样本。步骤203、将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本;步骤204、针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户;步骤205、确定所述洗钱类别的聚类中心与所述n个数据样本中每个数据样本的欧氏距离并按确定的欧式距离递增的顺序对所述n个数据样本进行排序,得到排序后的n个数据样本;步骤206、若确定所述n个数据样本中存在目标样本,则将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户,其中,所述排在所述目标样本之前的所有样本均属于所述洗钱类别,且所述目标样本对应的账户不属于任何洗钱类别;步骤207、将所述洗钱类别中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中,该分类方式是一个最佳分类,并且一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的;以及针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。本发明实施例一方面,根据n个数据样本的m个属性的权重得到每个数据样本的属性,将数据样本的属性进行了内在地联系,因而最终可以提高洗钱账户的识别准确率;另一方面,在确定洗钱账户时,是将符合预设的洗钱账户标准一个洗钱类别中的所有账户确定为洗钱账户,从而可以确定出具有连续交易特性的洗钱账户。基于相同的技术构思,本发明实施例还提供一种洗钱账户的确定装置,如图3所示,包括:数据样本获取单元301,用于获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;数据样本划分单元302,用于根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,一个数据样本的权重用于表示所述数据样本对分类的影响程度,一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的,所述平均信息熵是根据所述n个数据样本的隶属度得到的,所述隶属度用于表示一个数据样本对一个聚类的隶属程度,m为正整数;洗钱账户确定单元303,用于针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。可选地,所述数据样本划分单元302,具体用于:针对所述n个数据样本的一个分类值c,根据每个数据样本的权重及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的隶属度;并根据确定的所有隶属度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述数据样本划分单元302,具体用于:确定c个聚类中心初始值;根据所述c个聚类中心的初始值,确定所述n个数据样本对应的隶属度矩阵,以及根据确定的所述n个数据样本对应的隶属度矩阵,确定所述n个数据样本对应的目标函数值;根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心;根据更新后的所述c类数据样本中每个类的聚类中心,更新所述隶属度矩阵;根据更新后的所述隶属度矩阵及更新后的所述c类数据样本中每个类的聚类中心,更新所述n个数据样本对应的目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则根据更新后的所述隶属度矩阵,将所述n个数据样本划分为c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则返回到根据所述隶属度矩阵,更新所述c类数据样本中每个类的聚类中心的步骤。可选地,所述洗钱账户确定单元303还用于:将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户之后,确定所述洗钱类别的聚类中心与所述n个数据样本中每个数据样本的欧氏距离并按确定的欧式距离递增的顺序对所述n个数据样本进行排序,得到排序后的n个数据样本;若确定所述n个数据样本中存在目标样本,则将所述排序后的n个数据样本中排在所述目标样本之前的所有样本确定为重点洗钱样本,并将所有重点洗钱样本对应的账户确定为重点洗钱账户,其中,所述排在所述目标样本之前的所有样本均属于所述洗钱类别,且所述目标样本对应的账户不属于任何洗钱类别。可选地,所述洗钱账户确定单元303还用于:将所述洗钱类别中除所有重点洗钱样本之外的所有样本,确定为一般洗钱样本;将所有一般洗钱样本对应的账户确定为一般洗钱账户。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Σi=1cΣj=1nρjμij2dij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n,]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,ρj为数据样本xj的权重,dij为第i个聚类中心与数据样本xj之间未加权的的欧氏距离。可选地,所述数据样本划分单元302,还用于根据下列公式确定所述c个聚类中心初始值:Dk*=max{Di(k),i=1,2,...,n},k=2,3,...,c,]]>Di(k)=Di(k-1)-rm1(xi,xk-1*)*Dk-1**e-||xi-xk-1*||m2,k=2,3,...,c,i=1,2,...,n,]]>D1*=max{Di(1),i=1,2,...,n},]]>其中,表示当前n个数据样本中每个数据样本的样本密度中的最大值,表示对应的数据样本且表示第k个聚类中心的初始值(k=1,2,...,c),用于对所述n个数据样本的样本密度进行更新,表示数据样本xi与数据样本之间的皮尔逊相关系数,表示数据样本xi与数据样本之间的欧式距离,m1和m2为预设的系数。可选地,所述装置还包括数据样本权重确定单元304,用于根据下列公式确定一个数据样本的权重:ρi=density(i)Σh=1ndensity(h),]]>density(i)=Σh=1,h≠inr2(i,h)1dihe-dih2,]]>dih=Σj=1mwj2(xij-xhj)2,]]>r(i,h)=Σj=1m(wjxij-x‾i)(wjxhj-x‾h)Σj=1m(wjxij-x‾i)2Σj=1m(wjxhj-x‾h)2,]]>x‾i=1mΣj=1mwjxij,]]>x‾h=1mΣj=1mwjxhj,]]>其中,ρi表示第i个数据样本的权重,i=1,2,...,n,density(i)表示第i个数据样本的样本密度,r(i,h)表示数据样本xi与数据样本xh之间的皮尔逊相关系数,wj表示所述n个数据样本的第j个属性的权重,xij表示数据样本xi的第j个属性值,m表示所述n个数据样本中每个数据样本包含的属性数量,dih表示数据样本xi与数据样本xh之间加权的欧氏距离。可选地,所述数据样本权重确定单元304,还用于根据下列公式确定所述n个数据样本的属性权重:wj=HPjΣj′=1mHPj′,]]>HPj=CVj*HjCVj2+Hj2,]]>CVj=σjμj,]]>Hj=-Σk=1Kpjklog2(pjk),]]>μj=1KΣk=1KNjk=nK,]]>σj=1KΣk=1K(Njk-μj)2,]]>pjk=NjkΣk′=1KNjk′,]]>其中,wj表示所述n个数据样本的第j个属性的权重,CVj为属性j的离散系数且用于表示属性j偏离均匀分布的程度,Hj为属性j的信息熵且用于表示属性j的有序结构情况,并且,K是根据下列方式得到的:以所述n个数据样本在第j个属性上的最小值为起点,以所述n个数据样本在第j个属性上的最大值为终点,等划分成K组;Njk表示所述K组中第k组中的数据样本的个数(k=1,2,...,K)。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后根据每个数据样本的权重,将所述n个数据样本划分为c1类数据样本,其中,该分类方式是一个最佳分类,并且一个数据样本的权重是根据所述n个数据样本的m个属性的权重得到的;以及针对所述c1类数据样本中的任一类,确定距离所述类的聚类中心最近的数据样本为目标数据样本;若确定所述目标数据样本对应的账户符合预设的洗钱账户标准,则将所述类确定为洗钱类别并将所述洗钱类别中的所有数据样本对应的账户确定为洗钱账户。本发明实施例一方面,根据n个数据样本的m个属性的权重得到每个数据样本的属性,将数据样本的属性进行了内在地联系,因而最终可以提高洗钱账户的识别准确率;另一方面,在确定洗钱账户时,是将符合预设的洗钱账户标准一个洗钱类别中的所有账户确定为洗钱账户,从而可以确定出具有连续交易特性的洗钱账户。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1