一种用于实现稀疏神经网络的装置和方法与流程
本发明的目的在于提供一种稀疏神经网络加速器的实现装置和方法,以便达到提高运算效率的目的。
背景技术:
人工神经网络(artificialneuralnetworks,ann)也简称为神经网络(nns),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。近年来神经网络发展很快,被广泛应用于很多领域,包括图像识别、语音识别,自然语言处理,天气预报,基因表达,内容推送等等。
如图1所示,神经元的积累的刺激是由其他神经元传递过来的刺激量和对应的权重之和,用xj表示这种积累,yi表示某个神经元传递过来的刺激量,wi表示链接某个神经元刺激的权重,得到公式:
xj=(y1*w1)+(y2*w2)+...+(yi*wi)+...+(yn*wn)(1)
当xj完成积累后,完成积累的神经元本身对周围的一些神经元传播刺激,将其表示为yj得到如下所示:
yj=f(xj)(2)
神经元根据积累后xj的结果进行处理后,对外传递刺激yj。用f函数映射来表示这种处理,将它称之为激活函数。
在近几年里,神经网络的规模不断增长,公开的比较先进的神经网络都有数亿个链接,属于计算和访存密集型应用。
现有技术方案中通常是采用通用处理器(cpu)或者图形处理器(gpu)来实现,随着晶体管电路逐渐接近极限,摩尔定律也将会走到尽头。在神经网络逐渐变大的情况下,模型压缩就变得极为重要。
模型压缩可以将稠密神经网络变成稀疏神经网络,可以有效减少计算量、降低访存量。然而,cpu与gpu无法充分享受到稀疏化后带来的好处,取得的加速极其有限。而传统稀疏矩阵计算架构并不能够完全适应于神经网络的计算。
技术实现要素:
本发明提出一种用于实现稀疏神经网络的装置,包括:输入单元,用于接收多个输入向量a0,a1,…;稀疏矩阵读取单元,用于读取所述稀疏神经网络的权重矩阵w,其中所述稀疏矩阵w被用于表示所述稀疏神经网络中的一层的权重;m*n个计算单元pexy,x取值0,1,…m-1,y取值0,1,…n-1,x表示第x组pe,y表示某组pe中的第y个pe;控制单元,用于进行:把m个输入向量ai提供给对应的m组计算单元pe,以及把稀疏矩阵w的一部分wp提供给各组计算单元中的第j个计算单元,j取值0,1,…n-1,其中各个计算单元pe对所分配的输入向量ai和稀疏矩阵的一部分wp进行计算;输出缓存模块,用于把多个计算单元的计算结果进行累加并输出多个输出向量b0,b1…。
根据本发明的实施例,其中所述控制单元被进一步配置为:把m个输入向量ai提供给对应的m组计算单元pe,其中i的选取方式为:i(modm)=0,1,…m-1。
根据本发明的实施例,其中所述控制单元被进一步配置为:把稀疏矩阵w的所述部分wp提供给各组计算单元中的第j个计算单元pexj,其中对应于该j个计算单元pexj的稀疏矩阵w的所述部分wp的选取方式为:p(modn)=j,p取值为0,…,p-1,j=0,1,…n-1,所述矩阵w的大小为p*q。
根据本发明的实施例,输出缓存单元中,可以使用乒乓结构或类似方法来实现数据缓存。通过减少运算数据准备时间,达到提高运算效率的目的。
根据本发明的实施例,还可以在位置信息模块、译码模块使用乒乓结构或类似方法来实现数据缓存。
根据本发明的另一方面,提出了一种用于实现稀疏神经网络的方法,包括:接收多个输入向量a0,a1,…;读取所述稀疏神经网络的权重矩阵w,其中所述稀疏矩阵w被用于表示所述稀疏神经网络中的一层的权重;把所述输入向量和权重矩阵w输入给m*n个计算单元pexy,x取值0,1,…m-1,y取值0,1,…n-1,x表示第x组pe,y表示某组pe中的第y个pe,其中把m个输入向量ai提供给对应的m组计算单元pe,把稀疏矩阵w的一部分wp提供给各组计算单元中的第j个计算单元,j取值0,1,…n-1,使用各个计算单元pe对所分配的输入向量ai和稀疏矩阵的一部分wp进行计算;把多个计算单元的计算结果进行累加并输出多个输出向量b0,b1…。
根据本发明的实施例,其中所述把m个输入向量ai提供给对应的m组计算单元pe包括:i的选取方式为i(modm)=0,1,…m-1。
根据本发明的实施例,其中把稀疏矩阵w的所述部分wp提供给各组计算单元中的第j个计算单元pexj包括:对应于该j个计算单元pexj的稀疏矩阵w的所述部分wp的选取方式为,p(modn)=j,p取值为0,…,p-1,j=0,1,…n-1,所述矩阵w的大小为p*q。
本发明提出的并行计算结构,可以同时支持多路运算,也可以根据需求进行一路运算,该发明提高了计算效率也具有一定的灵活度。
本发明提出的并行计算方法,不仅可以在输入向量维度上做共享,也可以在稀疏神经网络的权值矩阵维度上做共享,这大大降低了内存访问量,同时也减少了片上缓存数量。本发明有效地平衡了片上缓存、i/o访问以及计算之间的关系,较好提高了计算模块的性能。
附图说明
图1示出了神经网络中神经元的积累和激励的原理图。
图2示出了一种高效推理引擎(eie),适用于用于机器学习应用的压缩深度神经网络模型。
图3示出了矩阵w和向量a和b在4个计算单元pe之间交错。
图4示出了以ccs格式保存权重矩阵w的一部分,其对应图3的pe0。
图5示出了图2的eie架构中解码器部分的更详细结构图。
图6示出了根据本发明实施例的实现神经网络的硬件架构。
图7示出了本发明实施例提出的硬件架构的简化图。
图8示出了本发明实施例提出的硬件架构在使用4个计算单元(pe)时的示意图。
图9示出了基于图8的本发明实施例的计算矩阵w和输入向量a时的示意图。
图10示出了基于图9的实施例来以ccs格式保存权重矩阵w。
具体实施方式
深度神经网络(dnn)的压缩和计算
dnn的fc层执行计算如下:
b=f(wa+v)(3)
其中a是输入激励向量,b是输出激励向量,υ是偏置,w是权重矩阵,f是非线性函数,在cnn和一些rnn中典型的线性纠正单元(relu)。有时候通过添加额外的给向量a,将υ与w结合,因此在以下段落中忽略偏置。
对于典型的fc层,像vgg-16或alexnet的fc7,激励向量长4k,权重矩阵是4k×4k(16m权重)。权重表示为单精度浮点数,所以这样的一层需要64mb的存储。方程(3)的输出激励是逐个元素计算的,如:
韩松等人的“deepcompression:compressingdeepneuralnetworkswithpruning,trainedquantizationandhuffmancoding”一文介绍了一种方法,通过结合修剪和权重共享不损失精度地压缩dnns。修剪使得矩阵w稀疏,我们基准层的密度d范围从4%到25%。使用4位索引iij,具有16种可能权重值的共享表s,权重共享取代权重wij。
随着深度压缩,方程(4)的每个激励计算变成:
其中,xi是wij≠0的列j的集合,y是aj≠0的索引j的集合,iij是替代wij的共享权重索引,s是共享权重的表。
这里xi代表w的静态稀疏,y表示a的动态稀疏。对于给定的模型,集合xi是固定的。集合y随着各个输入各不相同。
加速方程(5)用来加速实现压缩dnn。执行索引s[iij],乘-加那些wij和aj为非零的列,这样矩阵和向量的稀疏性质都得到了利用。这导致了一个动态不规则计算。执行索引本身包含了一些位处理,用于提取4位iij和额外负载。
crs和ccs
对于稀疏矩阵的处理,为了减少内存,往往需要对矩阵进行压缩存储,比较经典的存储方法包括:行压缩(compressedrowstoragecrs)和列压缩存储(compressedcolumnstorageccs)。
为了利用激励函数的稀疏性,我们将编码稀疏权重矩阵w存入压缩列存储(ccs)格式的变量中。
对于w矩阵每列wj,我们存储一个包含非零权重的向量v,以及等长向量z,向量z用于编码v的相应条目之前零的个数,v和z各自由一个四位数值表示。如果超过15个零出现在一个非零的条目,在向量v中添加一个零。例如,以下列被编码为:
[0,0,1,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,3]
v=[1,2,0,3],z=[2,0,15,2]。
所有列的v和z的都存储在一对大阵列中,其中指针向量p指向每个列的向量的开始。p指针向量中的最后一项指向超过最后一个向量元素,这样pj+1-pj给出了第j列中的非零数(包括填补的零)。
通过压缩列存储格式(ccsformat)中列存储稀疏矩阵,使得利用激励函数的稀疏性变得容易。只需要用每个非零激励与其相应列中的所有非零元素相乘。
美国专利uspatent9317482“universalfpga/asicmatrix-vectormultiplicationarchitecture”中更详细地披露了如何使用compressedsparserow(csr)在基于cpu和gpu的方案中,其中也采用compressedvariablelengthbitvector(cvbv)format。
采用eie并行处理压缩dnn
本发明的发明人之一曾经提出了一种高效的推理引擎(eie)。为了更好的理解本发明,在此简要介绍eie的方案。
图2显示了一种高效的推理引擎(eie),适用于用于机器学习应用的压缩深度神经网络模型,尤其是采用上述ccs或crs格式存储的压缩dnn。
中央控制单元(ccu)控制pes的阵列,每个pes计算压缩网络中的一片(slice)。ccu从分布式前置零检测网络接收非零输入激励,并把它们广播给pes。
上述方案中,几乎所有eie中的计算对于pes是局部的,除了向所有pes广播的非零输入激励的集合。然而,激励集合和广播的时间并不是关键的,因多数pes需要多种周期来完成每个输入激励的计算。
激励队列和负载平衡
输入激励向量aj的非零元素和相应的指标索引j被ccu广播到每个pe中的激励队列。如果任何一个pe有一个完整的队列,广播失效。在任何时间,每个pe处理在其队列头部的激励。
激励队列:允许每个pe建立一个工作队列,以消除可能出现的过载不平衡。因为在一个给定列j中的非零的数量可能对于不同pe会有所不同。
指针读取单元:在激励队列头部的条目的索引j被用来查找开始和结束的指针pj和pj+1,对应于第j列的v和x阵列。为了允许在一个周期中读取两个指针且使用单口sram阵列,在两sram内存库中存储指针,使用地址的lsb在内存库之间进行选择。pj,pj+1总会在不同的内存库中。eie指针的长度是16位。
稀疏矩阵读取单元:稀疏矩阵读取单元使用指针的pj,pj+1从稀疏矩阵sram读ij列的该pe片(slice)的非零元素(如果有的话)。sram中的每个条目是8位长度,包含v的4位数据和x的4位数据。
为了效率,编码的稀疏矩阵i的pe的片(slice)被存储在64位宽的sram中。因此,每次从sram读取8条。当前指针p的高13位用于选择sram行,低3位选择该行中的八条之一。单个(v,x)条被提供给每个周期的算术单元。
运算单元:算术单元从稀疏矩阵读取单元接收(v,x)条,执行乘法累加操作bx=bx+v×aj。索引x是用来索引一个累加器阵列(目的地激励寄存器),而v乘以在激励队列头部的激励值。因为v以4位编码形式存储,它首先通过查表(codebook)扩展成16位定点数。如果在两个相邻的周期上选择相同的累加器,则提供旁路通路,将加法器的输出导向其输入。
激励读/写:激励读/写单元包含两个激励寄存器文件,分别容纳一轮fc层计算期间的源激励值和目的地激励值。在下一层,源和目标寄存器文件交换它们的角色。因此,不需要额外的数据传输来支持多层前馈计算。
每个激励寄存器文件拥有64个16位激励。这足以容纳64pes的4k激励向量。更长的激励向量可容纳在2kb的激励sram中。当激励向量大于4k长度时,m×v将分批次(batch)完成,其中每个批次的长度是4k或更少。所有本地减法是在寄存器完成,sram只在批次的开始时被读取、在结束时被写入。
分布式前置非零检测:输入激励分层次地分布于各个pe。为了利用输入向量稀疏性,我们使用前置非零检测逻辑来选择第一个正向(positive)的结果。每一组4pes进行输入激励的局部前置非零检测。结果被发送到前置非零检测节点(lnzd节点),如图2所示。4个lnzd节点找到下一个非零激励,并发送结果给lnzd节点树。这样的布线不会因为添加pes而增加。在根lnzd节点,正向激励是通过放置在h树的单独导线被广播给所有pes。
中央控制单元:中央控制单元(ccu)是根lnzd节点。它与主控器,如cpu通讯,通过设置控制寄存器来监控每个pe的状态。中央单元有两种模式:i/o和计算。
在i/o模式,所有的pes闲置,每个pe的激励和权重可以通过与中央单元连接的dma访问。
在计算模式,ccu会持续地从源激励存储库顺序收集和发送数值,直到输入长度溢出。通过设置指针阵列的输入长度和起始地址,eie将被指示执行不同的层。
图3显示了如何使用多个处理单元(pes),交织计算矩阵w的各个行,分配矩阵w和并行化矩阵向量计算。
对于n个pes,pek拥有所有列wi,输出激励bi和输入激励ai,因子i(modn)=k。pek中的列wj的部分被存储为ccs格式,但计数的零仅指这个pe的列的子集的零。每个pe有自己的v,x和p阵列,v,x和p阵列用于编码其所计算的稀疏矩阵的一部分。
图3中,显示了矩阵w和向量a和b在4pes交错。相同颜色的元素都存储在相同的pe里。
图3中,将输入激励向量(长度为8)乘以一个16×8权重矩阵w产生一个输出激励向量b(长度为16)在n=4的pes上。a,b和w的元素根据他们的pe配置情况进行颜色编码。每一个pe拥有w的4行,a的2个元素,和b的4个元素。
通过扫描向量a以找到它的下一个非零值aj,依据索引j向所有pes广播aj,进行稀疏矩阵×稀疏向量运算。每个pe再将aj乘以在列wj部分的非零元素,在累加器中累加各个部分和,以输出激励向量b中的每个元素。在ccs表示中,这些非零权重被连续存储,每个pe只需沿着其v阵列从位置pj到pj+1-1加载权重。为了寻址输出累加器,通过保持x阵列条目的运行总和,产生对应于每个权重wij的行数i。
在图3的例子中,第一个非零是pe2上的a2。a2的值和其列索引2向所有pes广播。每个pe将a2乘以其列2部分中的每个非零值。pe0将a2乘以w0,2和w12,2;pe1在列2中全为零,故不执行乘法;pe2将a2乘以w2,2和w14,2,等等。将每个点积的结果相加到相应的行累加器。例如,pe0计算b0=b0+w0,2a2和b12=b12+w12,2a2。在每层的计算前,累加器被初始化为零。
交错(interleaved)ccs表示法有助于利用激励向量a的动态稀疏性,权重矩阵w的静态稀疏性。
通过仅广播输入激励a的非零元素,利用了输入激励的稀疏性。a中对应于零的列被完全跳过。交错(interleaved)ccs表示法允许每个pe迅速在每列找到非零并乘以aj。这种组织方式也保持了所有的计算在本地pe,除了广播输入激励以外。
图3中的矩阵的交错ccs表示法如图4所示。
图4显示了对应图3的pe0的相对索引的存储器布局、间接加权和交错的ccs格式。
相对行索引(relativerowindex):当前非零权值与前一个非零权值之间的零元素的个数;
列位置(columnpointer):当前“列位置”与前一个“列位置”之差=本列的非零权值的个数。
基于图4的编码方式来读取非零权值方式:
(1)读取2个连续的“列位置”,求差,该差值=本列的非零权重的个数;
(2)利用相对行索引,获得该列的非零权重的行位置,从而获得非零权重的行、列位置信息。
此外,图4所示的权重值是被进一步压缩后得到的虚拟权重(virtualweight)。
图5示出了根据eie的硬件结构中的解码器(weightdecoder)部分。
如图5所示,权重查找表(weightlook-up)和索引(indexaccum)对应于图2的权重解码器(weightdecoder)。通过权重查找表和索引,解码器把虚拟权重(例如,4bit)解码为真实权重(例如,16bit)。
这是因为压缩dnn模型具有稀疏性,以索引方式存储和编码。在对输入数据进行处理时,压缩dnn的编码权重被解码,通过权重查找表被转换为真实权重,再进行计算。
对eie方案的改进
近年来随着神经网络规模的增大,对高并发计算需求也越来越强烈。依某些应用为例,权值维度2048*1024,输入向量为1024,非稀疏化的计算量为2048*1024*2。随着技术的提高芯片计算性能也在提高,中等规模定制芯片计算核也有上千甚至几千。
如果使用前述eie的方案,存在如下问题:
首先,根据eie设计方案,在计算单元(pe)数量增加时,指针向量(pointervector,具体而言,图2的evenptrsrambank和oddptrsrambank)占用太多sram资源。所占用的存储量也会线性增长。如果采用1024个pe,eie的设计就需要1024*2=2048存储单元;
其次,随着pe数量的增加,权值译码模块采用的查找表(codebook)个数也线性增加,如采用1024个pe也需要1024个存储表。
在定制芯片中,上述两个问题随着pe量的增加都是很大的挑战。如何解决上述方案的上述两个问题?
本发明的实施例中,不仅把输入向量广播,还广播wi(w的一部分)。上述方案的eie仅把输入向量x0广播给多个pe。
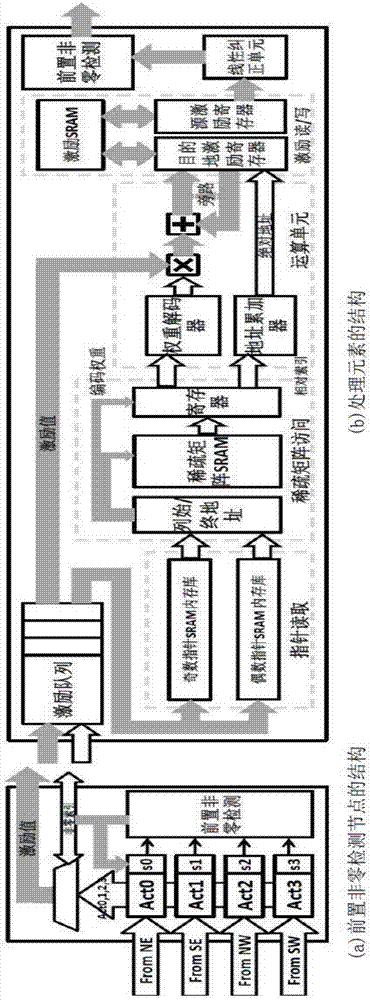
本发明提出了一种用于实现稀疏神经网络的装置。根据本发明实施例的基本结构图如图6所示。
如图6所示的装置包括如下各个模块。
输入激励队列(act),用于接收多个输入向量a0,a1,…。
根据本发明的实施例,所述输入激励队列还包括多个先进先出缓存(fifo)单元,各个先进先出缓存(fifo)单元与各组计算单元相对应。
多组计算单元(arithmunit),每组的计算单元编号为0,1,…n-1,
多个指针读取单元(ptrread),用于读取被存储的权重矩阵w的指针信息(即,位置信息),并输出给稀疏矩阵读取单元。
多个稀疏矩阵读取单元(spmatread),基于指针信息,读取所述稀疏神经网络的权重矩阵w中的非零值,所述稀疏矩阵w被用于表示所述稀疏神经网络中的一层的权重。
根据本发明的一个实施例,所述稀疏矩阵读取单元进一步包括解码单元,用于编码权重矩阵进行解码,以获得稀疏矩阵中的非零权重值。
控制单元(未示出),用于多个输入向量广播给多组计算单元,以及把稀疏矩阵的一部分广播给各组计算单元中的相应计算单元。
具体而言,假设有总数256个计算单元pemn,被分组为m*n。假设m=8,n=32,m取0,1,…7,n取0,1,…31,则有8组计算单元,每组有32个计算单元。
控制单元控制输入激励队列每次输入8个输入向量给8组计算单元,例如分别编号为a0,a1,…a7。
控制单元还控制多个稀疏矩阵读取单元(spmatread),每次输入权重矩阵的一部分wp给8组计算单元中的各个计算单元pexj,j取0,1…n-1。其中假设矩阵w的大小为1024*512(p*q),则pexj对应的wj的选取方式为:p(mod32)=j,p=0,…1023,n=0,1,…31。
这种选取wj的方式的优点在于,每隔n行抽选w中的1行以组成wj。当稀疏矩阵步均匀时,即,稀疏矩阵的非零权重不是均匀分布时,这种分配方式尽可能地把非零权重均匀地分配给各个pe,从而避免了各个pe之间的负载不均衡。
当然,上述选取wj的方式仅仅是示意性而非限制性的。本发明还可以采用其他分配方式。例如,wj可以是从w中连续选取n行。或者,wj可以是以其他间隔从w中抽选相应的行。
此外,还可以采用不同的方式对多个计算单元进行分组。例如4*64,m=4,n=64,每次算4个输入向量a1,…,a4。还例如,2*128,m=2,n=128,每次算2个输入向量a1,a2。
简言之,控制单元把m个输入向量广播给对应的m组计算单元pe,以及把稀疏矩阵w的一部分wj广播给各组计算单元中的第j个计算单元,j取值0,1,…n-1。
随后,各个计算单元pe对所分配的输入向量ai和稀疏矩阵的一部分wj进行计算。
图6所示的架构还包括输出缓存模块(actbuf),用于把多个计算单元的计算结果进行累加并输出。
根据本发明的另一方面,还包括前置零检测单元(图6未示出),用于检测所述输入向量中的非零值,并输出给所述输入单元。
根据本发明的实施例,所述输出缓存模块采用乒乓结构(ping-pang)。输出缓存模块具有第一输出缓冲器和第二输出缓冲器,所述第一、第二输出缓冲器交替地接收并输出各个计算结果,其中在一个输出缓冲器接收当前计算结果时,另一个输出缓冲器输出前一个计算结果。
图7的模块是对图6的硬件结构的简化示图。
图7的位置模块对应图6的指针读取单元(ptrread),图7的译码模块对应图6的多个稀疏矩阵读取单元(spmatread),图的计算单元pe对应图6的计算单元(arithmunit),图7的输出缓存对应图6的actbuf。
基于本发明实施例提出的并行计算方法,不仅可以在输入向量维度上做共享,也可以在稀疏神经网络的权值矩阵维度上做共享,这大大降低了内存访问量,同时也减少了片上缓存数量。有效地平衡了片上缓存、i/o访问以及计算之间的关系,较好提高了计算模块的性能。
依1024个计算核为例,本设计发明可以采用32个pe做一个wx运算,同时计算32个wx(32*32=1024),其中位置模块需要32个,译码模块需要32,上述两个模块都没有随pe数量的增加也线性增加。
根据本发明的另一实施例,也可以采用16个pe计算一个矩阵向量乘,可以同时计算64个矩阵向量乘(16*64=1024),其中位置模块16个,译码模块16个,位置和译码模块被64个矩阵向量运算共享。
上述的两种配置32*32和16*64区别在于,单个矩阵向量乘的并发度,前者是32个pe计算一个wx,后者是16个pe计算一个wx,前者单个计算并发度比较高,单路延时较短。前者同时运算32路,后者同时计算64路。综上具体设计可以根据实际业务诉求、io访问瓶颈、芯片资源等来具体配置。
例子1
为了简单说明本发明实施例的基本思路,依权重矩阵w为8*8、输入向量x为8为例,4个计算单元(2*2)对该设计发明进行详细描述。
本发明实施例以2个计算单元(processelementpe)为一组计算单元来计算一个矩阵向量乘,可以同时处理两个输入向量,采用列存储(ccs)为例进行详细说明。
参见图8,显示了该例子的硬件结构示意图。
位置模块0(pointer):存储奇数行非零元素的列位置信息,其中p(j+1)-p(j)为第j列中非零元素的个数。
译码模块0:存储奇数行非零元素的权值和相对行索引。如果权值做编码,该模块完成权值的解码。
权值矩阵w的奇数行元素(在译码模块0中存储)会广播给两组pe00和pe10。权值矩阵w的偶数行元素(在译码模块1中存储)会广播给两组pe01和pe11。同时计算y0=wx0和y1=wx1。
输入缓存0:存储输入向量x0。
为了平衡计算单元间元素稀疏度的差异,每个计算单元的入口都添加先进先出缓存(fifo)来提高计算效率。
控制模块:实现计算控制,使得各模块间信号同步,从而实现权值与对应输入向量的元素做乘,对应行值做累加。
计算单元pe00:完成权值矩阵奇数行元素与输入向量x0对应元素的乘累加。
输出缓存00:存放中间计算结果以及最终y0的奇数元素。
与上类似,位置模块1、译码模块1、计算单元pe01、输出缓存01,计算y0的偶数元素。
位置模块0、译码模块0、计算单元pe10、输出缓存10,计算y1的奇数元素。
位置模块1、译码模块1、计算单元pe11、输出缓存11,计算y1的偶数元素。
图9显示了图8的硬件结构如何操作进行计算矩阵w和输入性向量a。
如图9所示,奇数行元素由pex0完成,偶数行元素由pex1完成,输出向量的奇数元素由pex0计算所得,输出向量的偶数元素由pex1计算所得。
如图9所示,wx0矩阵向量乘,权值矩阵w的奇数行元素(图8中w的黄色元素)与x0的运算由pe00完成,权值矩阵w的偶数行元素(图8中w的非黄色)与x0的运算pe01完成,输出向量y0的奇数元素(图8中y0黄色元素)由pe00计算所得,输出向量的偶数元素由pe01计算所得(图8中y0非黄色元素)。
wx1矩阵向量乘,权值矩阵w的奇数行元素与x1的运算由pe10完成,权值矩阵w的偶数行元素由与x1的运算pe11完成,输出向量y1的奇数元素由pe10计算所得,输出向量的偶数元素由pe11计算所得。
输入向量x0会广播给两个pe00,pe01。
输入向量x1会广播给两个pe10,pe11。
权值矩阵w的奇数行元素(在译码模块0中存储)会广播给两组pe00和pe10。
权值矩阵w的偶数行元素(在译码模块1中存储)会广播给两组pe01和pe11;
w权值矩阵的分割需要软件算法或者matlab的支持,拆解完的数据通过接口直接写到存储模块中。
图10为pe00和pe10对应的权重信息是如何保存的。
相对行索引:当前非零权值与前一个非零权值之间的零元素的个数;
列位置:当前“列位置”与前一个“列位置”之差=本列的非零权值的个数。
基于图10的编码方式来读取非零权值方式:首先,读取2个连续的“列位置”,求差,该差值=本列的非零权重的个数;然后,利用相对行索引,获得该列的非零权重的行位置,从而获得非零权重的行、列位置信息。
根据本发明的一个实施例,图10的列位置信息(第三行元素)存储在位置模块0中,相对行索引和对应权值(第一行和第二行)存储在译码模块0中。
性能对比
在本发明的实施例中,不会随着计算单元pe的增加导致位置模块成线性增加,io读写需求也不会线性增长。在定制电路中,能够做到片上存储、io访问带宽、计算能力等之间的有效平衡。
例如,上述例子1如果采用eie方案:完成矩阵向量乘,4个pe计算一个矩阵向量乘需要4个位置模块,4个译码模块,4个计算单元,4个输出缓存。
例子1使用相同计算单元,即,4个计算单元,可以同时计算两个矩阵向量乘,其中两个矩阵向量乘共享位置模块和译码模块,仅需要2个位置模块,2个译码模块,4个计算单元,4个输出缓存。
基于上述技术方案可知,根据实施例的架构,稀疏神经网络加速器的实现装置及方法具有以下有益的效果:
通过采用该方法,解决了cpu和gpu运算性能不足,计算中有效数据占比率低的问题,有效的提高了运算效率,提高了有效运算数;
通过针对稀疏神经网络的特点,采用专用片上缓存,充分挖掘了稀疏矩阵作为权值数据的重用性,避免了反复向片外存储单元读取数据,降低了对片外存储空间访问的带宽,避免了权值数据读取带宽成为稀疏神经网络的性能瓶颈。
需要说明的是,本说明书中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,也可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和框图显示了根据本发明的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!