一种轻量级的数据密集型文件系统的自治块管理方法与流程
本发明涉及计算机安全技术,尤其涉及一种轻量级的数据密集型文件系统的自治块管理方法。
背景技术:
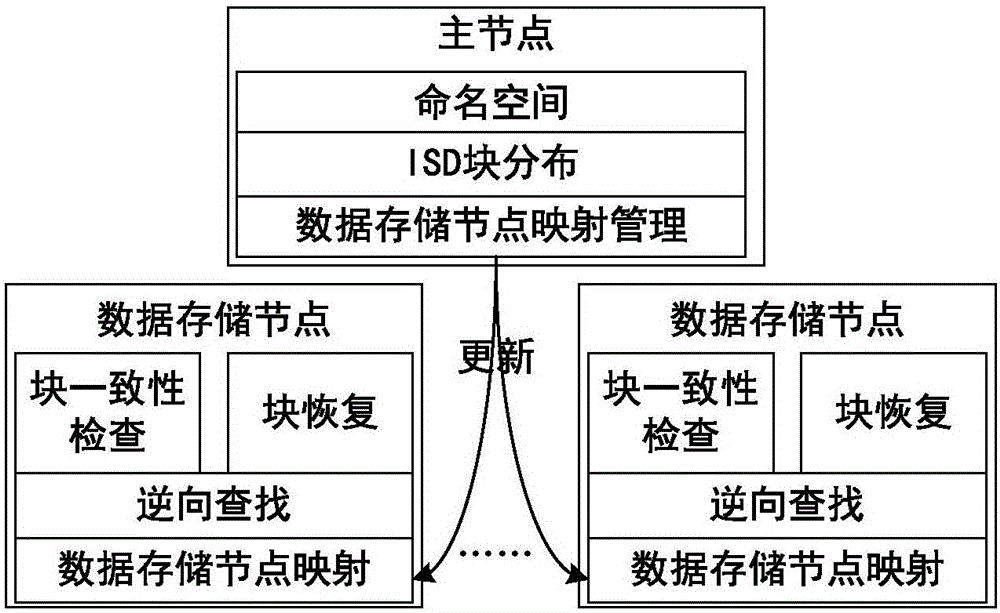
:数据密集型文件系统DiFS,例如谷歌文件系统GFS、Hadoop分布式文件系统HDFS等,已经成为大数据存储管理的主要文件系统。当前的数据密集型文件系统DiFS采用主从式架构,主节点(元数据服务器)管理所有的元数据,从节点(数据存储节点)只负责数据存储。为了维持高可用性,这些存储系统通常将数据文件分为固定大小的块,每个数据块通常有3个副本,并将它们都分配到不同的集群的数据存储节点中。主节点必须记录成百上千个数据存储节点的地址,以及记录所有数据文件的数据块到这些存储节点的映射信息。并且,主节点必须定期地检查所有数据块的地址映射信息的变化。随着数据量的不断增大,这些元数据信息不仅占据了主节点的内存空间,影响主节点的处理能力,而且严重地限制了主节点的可扩展性。为了解决数据密集型文件系统存在的问题,将数据文件物理块的分配和维护从元数据管理中分离出来,由每个数据存储节点执行数据块到存储节点映射信息的维护方法应运而生。应用此方法,主节点不需要再保存大量的数据块元数据信息以及数据块到数据存储节点的映射表信息,而是需要用一组数据块到数据存储节点、数据存储节点到数据块之间的可逆映射函数完成。数据密集型文件系统管理海量的数据,这些数据具有以下特点:1)数据量大,数据总量增长快;2)数据存储性能需求高;3)要求高可靠性和高可恢复性:当数据发生丢失或数据存储节点失效时,在不影响正常工作的前提下,能够快速的恢复原数据;4)要求能够快速的查找数据块的存储位置;5)要求尽量少的占用主节点的内存空间和尽量少的影响主节点的处理能力;从以上分析可以看出,传统文件系统的管理方法不适应数据密集型文件系统的管理,主要原因:1)随着数据量的不断增大,文件数据块地址表的存储将占用大量的存储空间;2)主节点负责文件数据块地址表的维护,随着文件数据块地址表的不断增加,大大降低了主节点的处理能力;3)数据量的不断增加不仅占用了主节点大量的存储空间,增大了地址等元数据维护成本,同时还降低了主节点的可扩展性;4)每个数据存储节点在进行存储和查询时都要先咨询主节点,这样增加寻址的时间。技术实现要素:针对数据密集型文件系统的数据块存储和查询管理需求,本发明提供了一种轻量级的数据密集型文件系统的自治块管理方法,通过将物理数据块的分配、查询和相关元数据维护从传统的元数据管理中分离出来,由每个数据存储节点完成,减少主节点存储空间的开销和负担。本发明可提升大数据环境下的数据密集型文件系统的可扩展性、减少数据块寻址时间,并可大副度提高整个系统的性能。本发明的技术原理在于,本发明是通过交叉迁移划分方法(ISD,IntersectedShiftedDeclustering)实现数据块的自治管理,即通过用一组可逆数学函数实现数据块到数据存储节点,以及数据存储节点到数据块的映射,完成数据块的分布式存储和快速查询等。本发明具体包含以下几种操作:操作1、数据块存储操作;操作2、数据块查找操作;操作3、失效数据存储节点失效处理操作;操作4、添加新数据存储节点操作。(1)数据块存储操作包括以下步骤:步骤1.1、主节点通过可逆的线性哈希函数选择数据块所在逻辑组(LG);步骤1.2、主节点通过可逆的位移分割函数选择逻辑组中数据存储节点存储数据块数据;步骤1.3、数据存储节点存储数据块数据和数据块地址映射信息。(2)数据块查找操作包括以下步骤:步骤2.1、数据块b所在数据存储节点根据其索引号用反向可逆函数计算数据块b所在逻辑组的新ID;步骤2.2、数据块b所在数据存储节点根据数据块b所在逻辑组ID,用反向可逆函数计算数据块b的物理ID,为文件系统恢复完整的数据文件提供条件;步骤2.3、数据存储节点根据数据块的物理ID,获取数据块在存储节点的映射信息;步骤2.4、数据存储节点根据数据块b的映射信息取数据块b的数据送文件系统。(3)失效数据存储节点失效处理操作包括以下步骤:步骤3.1、确定失效数据存储节点所在逻辑分组;步骤3.2、选择数据存储失效节点以外的逻辑分组中负载最小的数据存储节点作为后备节点;步骤3.3、多个后备数据存储节点采用智能重组映射方法并行复制各个逻辑组中对应的该失效数据存储节点中包含的数据。(4)添加新数据存储节点操作包括以下步骤:步骤4.1、计算整个系统中所有逻辑组中数据存储节点的平均负载COVave;步骤4.2、选择一个逻辑组,计算该组中所有数据存储节点中最大的负载COVmax;步骤4.3、比较COVmax和COVave的大小,如果COVmax≥COVave,用新加入数据存储节点替换逻辑组该数据存储节点。否则,选取下一个逻辑组,重复步骤4.1、步骤4.2和步骤4.3,直到新加入的数据存储节点的负载达到或接近系统中数据存储节点的平均负载为止。这种数据密集型文件系统自治块管理方法的优势在于:(1)大大减少了主节点存储空间开销。将数据块到数据存储节点映射信息从传统的元数据中分离出来,由每个数据存储节点自主的进行存储和管理,主节点不需要保存和维护大量的数据块地址信息,使主节点保存的元数据信息比传统文件系统减少90%以上。(2)大大的提高主节点的处理能力。数据块和数据存储节点之间的映射信息由每个数据存储节点自主的存储和维护,消除了主节点的负担。此种方法与分布式文件系统HDFS相比,可使主节点的处理性能提高了30%以上。(3)提高了系统的可恢复性和可扩展性。当数据存储节点故障时通过采用智能重组映射方法,当添加新数据存储节点时通过采用解耦地址映射方法,这样只迁移少数数据块就能完成失效数据节点数据的恢复和新添加数据节点数据的复制,大大提高了系统的可恢复性和可扩展性。附图说明图1为本发明具体操作的流程图;图2为本发明中主节点和数据存储节点管理功能划分的示意图;图3为连续块到数据节点的映射和数据节点到块的查找的示例;图4为数据节点失效恢复过程的示例;图5为新数据节点添加过程的示例。具体实施方式为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合图示与具体实施例,进一步阐述本发明提出的一种轻量级的数据密集型文件系统的自治块管理方法。一种轻量级的数据密集型文件系统的自治块管理方法,通过一组可逆数学函数实现数据块到数据节点及数据节点到数据块的映射。如图2所示,本发明中各节点具体功能的划分:主节点只负责系统命名空间维护、数据块到数据存储节点的分布、各个数据存储节点的管理;各个数据存储节点负责数据块的一致性检查、数据块恢复和数据存储节点的映射信息存储和维护。如图1所示,本发明所述的自治块管理方法,具体包括以下几种操作:操作1、数据块存储操作;操作2、数据块查找操作;操作3、失效数据存储节点失效处理操作;操作4、添加新数据存储节点操作。(1)数据块存储操作,包括以下步骤:步骤1.1、主节点通过可逆的线性哈希函数选择块所在逻辑组(LG);步骤1.2、主节点通过可逆的位移分割函数选择逻辑组中数据存储节点存储数据块数据;步骤1.3、数据存储节点存储数据块数据和数据块地址映射信息。数据块存储操作的步骤1.1中,通过可逆的线性哈希函数选择数据块所在的逻辑组(LG)公式:其中,g是要映射的逻辑组ID,x是系统中当前的组数,X是开始时系统中的逻辑组数,b是要存储数据块在其文件中的块ID,s是新增的逻辑组数,数据块存储操作的步骤1.2中,通过可逆的位移分割函数选择逻辑组中数据存储节点的过程包括:A)计算数据块b映射到逻辑组g后的新块标识,其公式:其中,a是数据块在逻辑组g中的新标识,x是当前逻辑组数,X是初始的逻辑组数,b给定数据块ID,s是新增的逻辑组数,B)计算数据块b映射到逻辑组g中的数据存储节点的索引ID,其公式:d=node(a,i)=(a+i)%4(3)其中,a是数据块b在逻辑组g中的新数据块标识,i是数据块b的副本号(取值0、1、2),d为数据块b在逻辑组选择的数据存储节点的索引(取值0、1、2、3)。所述的副本号,是指密集型文件系统为每个数据块提供三个副本,充分保证其可用性,其编号为0、1、2;所述数据存储节点的索引,是指一个逻辑组中的所有数据存储节点的编号,本发明中每个逻辑组包括4个数据存储节点,其索引号分别为0、1、2、3。(2)数据块查找操作包括以下步骤:步骤2.1、数据块b所在数据存储节点根据其索引号用反向可逆函数计算数据块b所在逻辑组的新ID;步骤2.2、数据块b所在数据存储节点根据数据块b所在逻辑组ID,用反向可逆函数计算数据块b的物理ID,为文件系统恢复完整的数据文件提供条件;步骤2.3、数据存储节点根据数据块的物理ID,获取数据块在存储节点的映射信息;步骤2.4、数据存储节点根据数据块b的映射信息获取数据块b的数据送至文件系统。数据块查找操作中的步骤2.1根据数据存储节点索引号d用反向可逆函数计算数据块b所在逻辑组的新ID,其公式:d=(a+i)%4→可逆运算→a=4·j+(d-i)%4(4)其中i表示数据块的副本号,可以迭代取0、1、2,j可取0、1、2、…、n等;数据块查找操作中的步骤2.2反向可逆函数计算数据块b的物理ID,其公式:其中,g是包含给定数据存储节点逻辑组的索引,图3(a)是连续的数据块通过线性哈希映射到各个逻辑组,并通过迁移划分实现数据块在逻辑组中各个数据存储节点的分布式存储;图3(b)是以数据节点2为例,演示通过可逆函数实现逆向查找数据块的过程。(3)失效数据存储节点失效处理操作包括以下步骤:步骤3.1、确定失效数据存储节点所在逻辑分组;步骤3.2、选择数据存储失效节点以外的逻辑分组中负载最小的数据存储节点作为后备节点;步骤3.3、多个后备数据存储节点采用智能重组映射方法并行复制各个逻辑组中对应的该失效数据存储节点中包含的数据。所述的智能重组映射方法,是选取后备数据存储节点数与包含失效数据存储节点的逻辑组数相等,一个失效数据存储节点可能被包含在多个逻辑组中,每一个后备数据存储节点只负责复制一个对应的逻辑组中该失效数据存储节点中的部分数据。图4以数据节点2失效为例,演示了各个逻辑组对数据节点2替换恢复过程。(4)添加新数据存储节点操作,主要采用解耦地址映射方法,包括以下步骤:步骤4.1、计算整个系统中所有逻辑组中数据存储节点的平均负载COVave;步骤4.2、选择一个逻辑组,计算该组中所有数据存储节点中最大的负载COVmax;步骤4.3、比较COVmax和COVave的大小,如果COVmax≥COVave,用新加入数据存储节点替换逻辑组中负载最大的数据存储节点。否则,选取下一个逻辑组,重复步骤4.1、步骤4.2和步骤4.3,直到新加入的数据存储节点的负载达到或接近系统中数据存储节点的平均负载为止。图5演示了系统添加新数据节点node128构成新的新逻辑组LG1000时,整个系统的数据块迁移过程。通过图4和图5可以看出,系统通过可逆函数并采用智能重组映射方法和采用解耦地址映射方法,使数据节点失效和新数据节点添加时,只有很少的数据块迁移,充分保证了系统的稳定性和对用户的可用性。下面用一个实例来阐述本方法。选择HDFS作为数据密集型文件系统,通过仿真10000个数据节点,1000000个数据块的大数据环境下,在采用轻量级的数据密集型文件系统的自治块管理方法和不采用该方法时主节点内存占用情况如表1所示,主节点CUP占用情况如表2所示。其中1000000数据块是均匀分布在10000数据节点中,每个数据块大小为64MB。表1主节点管理数据块内存占用情况数据节点数1000200050007000900010000优化后占用内存(MB)152027364250未优化占用内存(MB)180186189192194196表2主节点管理数据块CPU占用情况数据节点数5002000300040005000优化后CPU占用率(%)1.42.32.53.14.2未优化后CPU占用率(%)6.312.116.619.823.2从表1和表2可知,采用轻量级的数据密集型文件系统的自治块管理方法后,主节点的内存占用情况和CPU的占用情况明显优于未采用轻量级的数据密集型文件系统的自治块管理方法的情况。尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1