面向大规模数据的情报系统中文本聚合及展现方法及系统与流程
本发明涉及计算情报学领域,更具体的说,是涉及一种面向大规模数据的情报系统中文本聚合及展现方法及系统。
背景技术:
随着互联网的快速发展,网络媒体作为一种新的信息传播形式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国内还是国际重大事件,都能马上形成网上舆论,通过这种网络来表达观点、传播思想,进而产生巨大的舆论压力,达到任何部门、机构都无法忽视的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
网络情报服务系统是利用搜索引擎技术和网络信息挖掘技术,通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、主题检测、专题聚焦、统计分析,实现各单位对自己相关网络情报监督管理的需要,最终形成情报简报、情报专报、分析报告、移动快报,为决策层全面掌握情报动态,做出正确舆论引导,提供分析依据。
传统的情报服务系统上信息阅读方式是逐条浏览,如果页面上出现了重复了相似的文本,也不得不在阅读以后才会发现内容重复,这样就造成了用户时间的浪费。另一方面,用户阅读一条信息后,发现对此类信息比较有兴趣,希望快速并集中地获得此类信息,传统的情报服务系统并没有一种简单快捷的操作方式完成此目的。
技术实现要素:
有鉴于此,有必要针对上述问题,提供一种面向大规模数据的情报系统中文本聚合及展现方法及系统,能够快速将相似的文本聚合在一起,页面上展现代表性文章的标题和摘要等基本信息,方便用户快速浏览发现自己感兴趣的信息以及在发现感兴趣信息后,点开详细阅读,极大地提高了用户阅读效率以及关键情报信息定位的准确率。
为了实现上述目的,本发明的技术方案如下:
一种面向大规模数据的情报系统中文本聚合及展现方法,包括以下步骤:
S1、对长短文本进行多维度划分,包括长文本、短文本和无意义文本;
S2、对长文本通过topN相似度算法计算相似度度量;
S3、对短文本进行SimHash算法计算相似度度量;
S4、文本聚合展示,在展示文本时,将相似的文本聚合到一起进行展示。
作为优选的,所述步骤S1中包括,将来源文本划分成长文本、短文本及无意义文本三种,其中无信息文本会直接抛弃而不做处理。
作为优选的,所述无意义文本为信息量低或无意义信息。
作为优选的,所述步骤S2具体包括:从文本中提取N句代表性的词语,组成特征词语,将此N个句子按从长到短拼接成一个特征句,使用MD5生成此特征句的hash值,存入数据库,拥有相同hash值的文本被认为是相似文本。
作为优选的,所述步骤S3具体包括:将文本进行分词,分词后过滤去掉标点符号,使用SimHash计算各个文本间的相似度,相似的文本会被赋予相同的ID号,将此ID号存入数据库。
作为优选的,所述步骤S4具体包括:将相似类文本聚合成一个按关注度排序的堆上,展示堆顶上的文本摘要信息,浏览时只有点击率排名最高的文本摘要会展示,点击进入会展示详细的文本列表。
一种根据上述方法进行文本聚合及展现的系统,包括长短文本分类器、topN算法模块和SimHash算法模块和数据库;
所述长短文本分类器用于对长短文本进行分类区别,并将长文本传输到topN算法模块、短文本传输到SimHash算法模块、无意义文本直接抛弃;
所述topN算法模块用于将长文本文本按照标点符号分割成有意义的句子,提取N句代表性的语句,将此N个句子按从长到短拼接成一个特征句,使用MD5生成此特征句的hash值,存入数据库;
所述SimHash算法模块用于将短文本进行分词,分词后过滤去掉标点符号,使用SimHash计算各个文本间的相似度,对相似的文本会赋予相同的ID号,将此ID号存入数据库。
作为优选的,所述长短文本分类器通过海量情报系统的海量文本训练得出。
与现有技术相比,本发明的有益效果在于:本发明能够快速将相似的文本聚合在一起,页面上展现代表性文章的标题和摘要等基本信息,方便用户快速浏览发现自己感兴趣的信息以及在发现感兴趣信息后,点开详细阅读。此系统极大地提高了用户阅读效率以及关键情报信息定位的准确率。
附图说明
图1为本发明实施例的方法流程图;
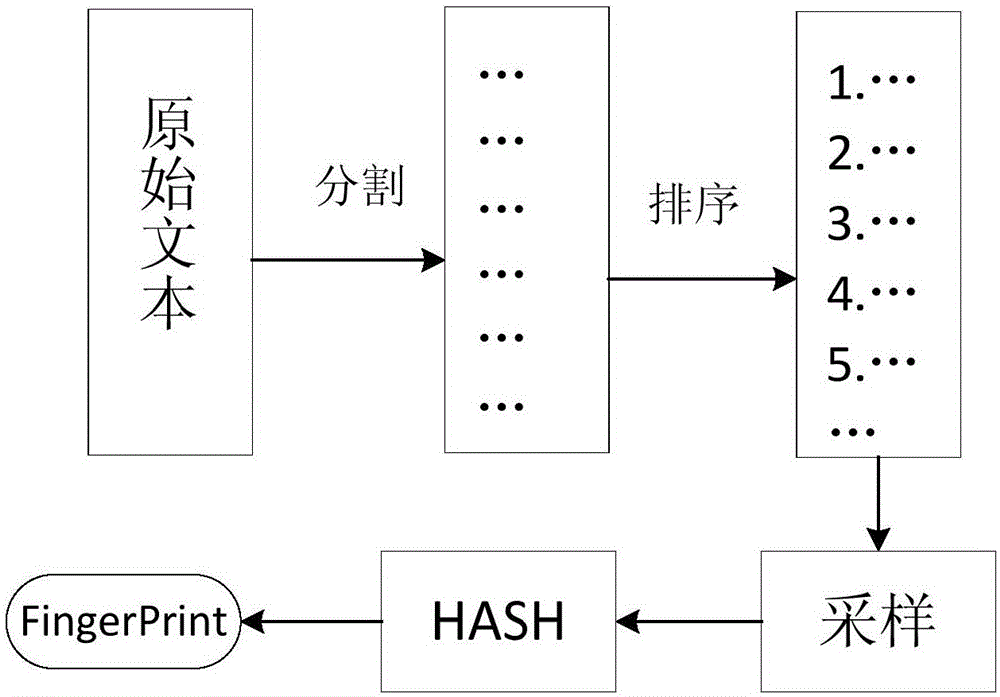
图2为本发明实施例中topN算法生成长文本流程图;
图3为本发明实施例中系统结构框图;
图4为本发明实施例中长短文本分类器结构示意图。
具体实施方式
下面结合附图和实施例对本发明所述的一种面向大规模数据的情报系统中文本聚合及展现方法及系统作进一步说明。
以下是本发明所述的面向大规模数据的情报系统中文本聚合及展现方法及系统的最佳实例,并不因此限定本发明的保护范围。
图1示出了一种面向大规模数据的情报系统中文本聚合及展现方法,包括以下步骤:
S1、对长短文本进行多维度划分,包括长文本、短文本和无意义文本;
S2、对长文本通过topN相似度算法计算相似度度量;
S3、对短文本进行SimHash算法计算相似度度量;
S4、文本聚合展示,在展示文本时,将相似的文本聚合到一起进行展示。
在本实施例中,所述步骤S1中包括,将来源文本划分成长文本、短文本及无意义文本三种,其中无信息文本会直接抛弃而不做处理。
作为优选的,所述无意义文本为信息量低或无意义信息。
当前查看情报信息是否相似是采用文本精确匹配技术的扫描技术,尽管该方法处理速度快,但是其存在模糊识别能力不强、学习能力不足的缺点,匹配出来文本间并不存在明显的相似性。情报信息中往往存在如新闻类的长文本和如微博、论坛的短文本。SimHash算法在计算文本间相似度上具有优势,但是其在计算长文本时需先分词,然后按照文本中每个词来生成整篇文章的Hash值,造成对于海量的长文本效率不高。
当前相似文档度量算法一般基于精准匹配技术的扫描策略,该方法效率低,准确度也不够理想,更是无法满足海量文本数据的处理需求。为提升相似度测量的效率和准确度,在本实施例中,如图2所示,所述步骤S2具体包括:从文本中提取N句代表性的词语,组成特征词语,将此N个句子按从长到短拼接成一个特征句,使用MD5生成此特征句的hash值,存入数据库,拥有相同hash值的文本被认为是相似文本;在本实施例中,通过基于长文本的topN相似度度量算法,该算法通过提取长文本中最具代表性句子组成内容指纹;topN算法只需要从长文本中提取很少几句话组成特征语句,效率较SimHash要高许多,极大满足了处理海量数据的效率要求。
在本实施例中,所述步骤S3具体包括:将文本进行分词,分词后过滤去掉标点符号,使用SimHash计算各个文本间的相似度,相似的文本会被赋予相同的ID号,将此ID号存入数据库,通过基于短文本的SimHash相似度度量算法,该算法生可用来度量文本间的相似度。topN算法效率较SimHash高,但是在短文本上由于语句太少,没有办法发挥topN算法的优势,同时由于文本短,处理效率显得没那么重要,同时topN算法在长文本上的效率优势弥补了整个系统的处理效率。
在本实施例中,所述步骤S4具体包括:将相似类文本聚合成一个按关注度排序的堆上,展示堆顶上的文本摘要信息,浏览时只有点击率排名最高的文本摘要会展示,点击进入会展示详细的文本列表。
本实施例中还提出了一种根据上述方法进行文本聚合及展现的系统,如图3至图4所示,包括长短文本分类器、topN算法模块和SimHash算法模块和数据库;
如图4所示,所述长短文本分类器用于对长短文本进行分类区别,并将长文本传输到topN算法模块、短文本传输到SimHash算法模块、无意义文本直接抛弃;
所述topN算法模块用于将长文本文本按照标点符号分割成有意义的句子,提取N句代表性的语句,将此N个句子按从长到短拼接成一个特征句,使用MD5生成此特征句的hash值,存入数据库;
所述SimHash算法模块用于将短文本进行分词,分词后过滤去掉标点符号,使用SimHash计算各个文本间的相似度,对相似的文本会赋予相同的ID号,将此ID号存入数据库。
作为优选的,所述长短文本分类器通过海量情报系统的海量文本训练得出。
与现有技术相比,本发明的有益效果在于:本发明能够快速将相似的文本聚合在一起,页面上展现代表性文章的标题和摘要等基本信息,方便用户快速浏览发现自己感兴趣的信息以及在发现感兴趣信息后,点开详细阅读。此系统极大地提高了用户阅读效率以及关键情报信息定位的准确率。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!