支持带有伪列的分级查询集群数据库系统及分级查询方法与流程
本发明涉及集群数据库领域,特别是涉及一种支持带有伪列的分级查询集群数据库系统及分级查询方法。
背景技术:
集群数据库是使用多台普通服务器,协同提供高性能的数据库服务,适用于海量数据的保存、查询和分析。
分级查询是集群数据库提供的一种数据查询方式,即先在数据表中找到一组指定的起点结点,然后以这些起点结点为父结点,找到它们的子结点。然后不断以上一次新找到的子结点作为下一次查询中的父结点,再找到它们的子结点。这样,按照父结点与子结点之间的关系,一级一级地逐步找到相关联的所有结点,便得到分级查询的结果集。
伪列是指每一条查询结果在此次查询过程中产生的额外信息,伪列具体包括:1、根(root):此结点的最初的父结点;2、级数(level):此结点的与根结点之间的距离,即从根结点经过多少级查询才得到此结点;3、路径(path):从根结点到此结点的查询过程中的所有结点;4、循环(iscycle):此结点的子结点是否会与某个父结点重合;5、叶子结点(isleaf):此结点没有子结点,则被称为叶子结点。
现有的分析查询方法和查询系统只能对父结点以下的子结点进行查询,无法获得相应的伪列信息,如果需要得到相应的伪列信息还要需要采用其他的方法对集群数据库进行查询,不仅繁琐,而且耗时较长。
技术实现要素:
本发明要解决的技术问题是提供一种分级查询快捷、耗时短的支持带有伪列的分级查询集群数据库系统及分级查询方法。
本发明支持带有伪列的分级查询集群数据库系统,其中,包括数据表查询器,数据表查询器内部设置有分级查询模块、起点过滤模块、待处理结点列表模块、查询路径模块和子结点查询模块,
分级查询模块用于单个数据表上的分级查询操作;
起点过滤模块用于在单个数据表上查询时查询起点的结点;
待处理结点列表模块用于保存还没有进行查询的子结点的结点;
查询路径模块用于保存查询的整个过程;
子结点查询模块用于对指定的父结点进行其子结点的查询,并在查询结束后生成相应的伪列。
本发明支持带有伪列的分级查询集群数据库系统,其中所述分级查询模块分别对起点过滤模块、待处理结点列表模块、查询路径模块和子结点查询模块的工作状态进行控制。
本发明支持带有伪列的分级查询方法,其中,包括如下步骤:
步骤S1,查询开始后,使用起点过滤模块查询起点结点;
步骤S2,将查询到的起点结点放入待处理结点列表和结果表;
步骤S3,对待处理的起点结点是否存在进行判断:如果未查询到待处理的起点结点,输出结果表,查询结束;如果存在待处理的起点结点,从待处理结点列表的末尾取出待处理的起点结点;
步骤S4,对待处理的起点结点是否在查询路径中进行判断:如果该待处理的起点结点在查询路径中,从查询路径和待查询结点列表中删除此结点,并将删除后的待处理的起点转回步骤S3进行重新判断;如果待处理的起点结点不在查询路径中,将该起点结点放入查询路径的末尾;
步骤S5,使用子结点查询模块获得查询路径中的起点结点的子结点和伪列;
步骤S6,将获得的子结点添加到待处理结点列表的末尾和结果表中;
步骤S7,将获得的子结点转回到步骤S3进行重新判断。
本发明支持带有伪列的分级查询方法,其中所述具体的待处理结点列表和结果表由用户预先设定。
本发明支持带有伪列的分级查询集群数据库系统及分级查询方法与现有技术不同之处在于:本发明设置有起点过滤模块、待处理结点列表模块、查询路径模块和子结点查询模块,起点过滤模块用于查询起点结点;子结点查询模块用于获得指定结点的子结点和伪列;待处理结点列表模块用于保存还未查询子结点的结点;查询路径模块用于保存查询过程中的结点,采用上述技术方案,能够实现带有伪列的分级查询功能,查询速度快、耗时短,大大提高了集群数据库查询功能的多样性和实用性。
下面结合附图对本发明的支持带有伪列的分级查询集群数据库系统及分级查询方法作进一步说明。
附图说明
图1为本发明支持带有伪列的分级查询集群数据库系统的结构示意图;
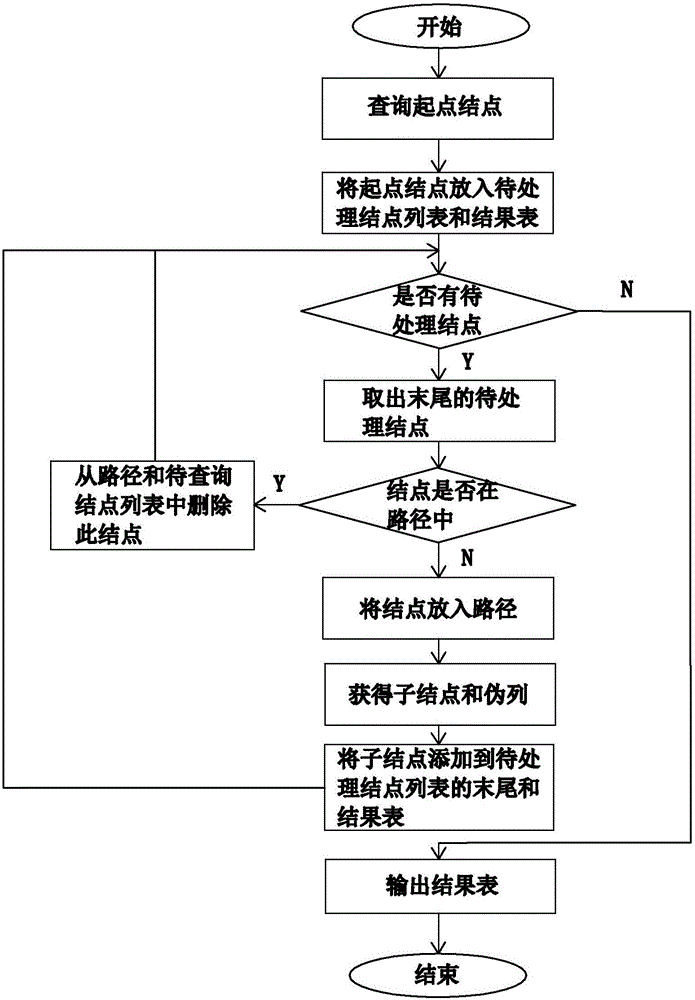
图2为本发明支持带有伪列的分级查询方法的流程图;
图3为本发明支持带有伪列的分级查询集群数据库系统及分级查询方法的实例示意图。
具体实施方式
如图1所示,为本发明支持带有伪列的分级查询集群数据库系统的结构示意图,包括数据表查询器1,数据表查询器1内部又设置有分级查询模块2、起点过滤模块3、待处理结点列表模块4、查询路径模块5和子结点查询模块6。分级查询模块2分别对起点过滤模块3、待处理结点列表模块4、查询路径模块5和子结点查询模块6的工作状态进行控制。通过数据表查询器1对单个数据表上的查询工作进行总的操作控制;分级查询模块2通过控制起点过滤模块3、待处理结点列表模块4、查询路径模块5和子结点查询模块6,完成对单个数据表上的分级查询操作;起点过滤模块3用于在单个数据表上查询时查询起点的结点;待处理结点列表模块4用于保存还没有进行查询的子结点的结点;查询路径模块5用于保存查询的整个过程;子结点查询模块6用于对指定的父结点进行其子结点的查询,并在查询结束后生成相应的伪列。
如图2所示,为本发明支持带有伪列的分级查询方法的流程图,包括如下步骤:
步骤S1,查询开始后,使用起点过滤模块3查询起点结点;
步骤S2,将查询到的起点结点放入待处理结点列表和结果表,具体的待处理结点列表和结果表由用户预先设定;
步骤S3,对待处理的起点结点是否存在进行判断:如果未查询到待处理的起点结点,输出结果表,查询结束;如果存在待处理的起点结点,从待处理结点列表的末尾取出待处理的起点结点;
步骤S4,对待处理的起点结点是否在查询路径中进行判断:如果该待处理的起点结点在查询路径中,从查询路径和待查询结点列表中删除此结点,并将删除后的待处理的起点转回步骤S3进行重新判断;如果待处理的起点结点不在查询路径中,将该起点结点放入查询路径的末尾;
步骤S5,使用子结点查询模块6获得查询路径中的起点结点的子结点和伪列;
步骤S6,将获得的子结点添加到待处理结点列表的末尾和结果表中;
步骤S7,将获得的子结点转回到步骤S3进行重新判断,从而以子结点作为父结点,获得该子结点的子结点。
本发明支持带有伪列的分级查询集群数据库系统及分级查询方法可应用于公司的组织数据库表中查询某个员工的多有上司或者应用于户籍数据库中查询某个人的所有后代。
如图3所示,为本发明支持带有伪列的分级查询集群数据库系统及分级查询方法的实例示意图。本实施例是一个分级查询过程,在一个公司的团队中有10名成员,工号依次为从A至J,且已知每个人的主管(NULL表示没有主管)。现给定起点结点为C,要求查询上司C的所有下属。分级查询模块2的运行过程如下:
1.使用起点过滤模块3,按照条件(下属=‘C’)查询起点结点,得到起点结点C,将C放入待处理结点列表的末尾和结果表末尾;
2.从待处理结点列表末尾取出C,由于C不在查询路径上,使用子结点查询模块6,按照(子结点.上司=父结点.工号=‘C’)的条件进行查询,得到C的子结点G和H,并生成C的伪列(如:path=‘/C’,level=1,isleaf=0),将G和H分别放入待处理结点列表的末尾和结果表的末尾;
3.从待处理结点列表末尾取出H,由于H不在查询路径上,使用子结点查询模块6,按照(子结点.上司=父结点.工号=‘H’)的条件进行查询,得到H没有子结点,并生成H的伪列(如:path=‘/C/H’,level=2,isleaf=1);
4.从待处理结点列表末尾取出H,由于H在查询路径上,将H从查询路径上和待处理结点列表末尾删除;
5.从待处理结点列表末尾取出G,由于G不在查询路径上,使用子结点查询模块6,按照(子结点.上司=父结点.工号=‘G’)的条件进行查询,得到G有子结点J,并生成G的伪列(如:path=‘/C/G’,level=2,isleaf=0);
6.从待处理结点列表末尾取出J,由于J不在查询路径上,使用子结点查询模块6,按照(子结点.上司=父结点.工号=‘J’)的条件进行查询,得到J没有子结点,并生成J的伪列(如:path=‘/C/G/J’,level=3,isleaf=1);
7.从待处理结点列表末尾取出J,由于J在查询路径上,将J从查询路径上和待处理结点列表末尾删除;
8.从待处理结点列表末尾取出G,由于G在查询路径上,将G从查询路径上和待处理结点列表末尾删除;
9.从待处理结点列表末尾取出C,由于C在查询路径上,将C从查询路径上和待处理结点列表末尾删除;
10.没有待处理结点,输出结果表,结束。
本发明支持带有伪列的分级查询集群数据库系统及分级查询方法,设置有起点过滤模块3、待处理结点列表模块4、查询路径模块5和子结点查询模块6,起点过滤模块3用于查询起点结点;子结点查询模块6用于获得指定结点的子结点和伪列;待处理结点列表模块4用于保存还未查询子结点的结点;查询路径模块5用于保存查询过程中的结点,采用上述技术方案,能够实现带有伪列的分级查询功能,查询速度快、耗时短,大大提高了集群数据库查询功能的多样性和实用性。本发明分级查询快捷、实用性高,与现有技术相比具有明显的优点。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!