一种用于大数据K‑Mean聚类算法的加速系统和方法与流程
本发明涉及大数据技术领域,特别是涉及一种用于大数据K-Mean聚类算法的加速系统和方法。
背景技术:
随着信息技术的发展,当前已经进入了大数据时代。为了保证大数据的处理性能,出现了多种方式对大数据进行处理。
Spark是一种通用的并行框架,其Job中间输出结果可以保存在内存中,而无需读写HDFS,因此,其能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。在Spark的整个生态圈中,最底层为资源管理器,底层存储为文件系统或者其他格式的存储系统如HBase。Spark作为计算框架,为上层多种应用提供服务,如数据挖掘和机器学习服务,以提供高可靠和高吞吐量的计算服务。MLlib是Spark的机器学习库,为其核心部件之一,MLlib机器学习的性能、功耗等指标不仅涉及大数据处理系统的价值,还影响着大数据处理平台的任务调度和管理以及数据吞吐率。
因此,如何提升机器学习的性能,降低其功耗,以缩短大数据处理周期,是本领域技术人员目前需要解决的技术问题。
技术实现要素:
本发明的目的是提供一种用于大数据K-Mean聚类算法的加速系统和方法,可以提升机器学习的性能,降低其功耗,缩短大数据处理周期。
为解决上述技术问题,本发明提供了如下技术方案:
一种用于大数据K-Mean聚类算法的加速系统,包括:
数据处理服务器主机端,用于对数据处理任务按照预设的任务分发机制进行分配;
n个数据处理服务器,用于获取Spark集群中的待处理数据和K-Mean聚类算法,其中,n为大于1的整数;
FPGA加速装置,用于获取并存储预设数据量的所述待处理数据以及计算要求超过预设阈值的K-Mean聚类算法,并通过迭代的方式逐次调取所述待处理数据,执行所述K-Mean聚类算法对调取的所述待处理数据进行计算,并将计算结果返回至所述数据处理服务器主机端。
优选地,所述FPGA加速装置包括:
板载存储器,用于获取并存储各所述数据处理服务器发送来的预设数据量的待处理数据,以及存储所述K-Mean聚类算法对调取的待处理数据进行计算的计算结果;
FPGA芯片,用于获取计算要求超过预设阈值的K-Mean聚类算法,并通过迭代的方式逐次调取所述板载存储器中的待处理数据,执行所述K-Mean聚类算法以对该待处理数据进行计算,并将每次的计算结果暂存于所述板载存储器中;
FPGA加速装置接口,用于在通过所述FPGA芯片完成当前批次的待处理数据处理完毕后,将所有的计算结果返回至所述数据处理服务器主机端。
优选地,所述FPGA芯片包括:
K-Mean聚类算法加速模块,用于实现所述K-Mean聚类算法在所述FPGA芯片上的逻辑,针对不同维度、不同聚类中心节点数的聚类任务进行动态更新;
FPGA功能模块,用于根据所述K-Mean聚类算法加速模块中的K-Mean聚类算法对调取的所述板载存储器中的待处理数据进行并行计算。
优选地,所述板载存储器为双倍速率同步动态随机存储器。
优选地,所述数据处理服务器包括:
任务获取模块,用于从所述Spark集群中获取对应的待处理数据和K-Mean聚类算法;
数据分配模块,用于根据所述FPGA加速装置中的板载存储器的内存量分次将所述任务获取模块所获取的待处理数据保存至所述板载存储器;
算法分类模块,用于将所述任务获取模块获取的K-Mean聚类算法中计算要求超过预设阈值的K-Mean聚类算法进行分离,并发送至所述FPGA加速装置。
一种用于大数据K-Mean聚类算法的加速方法,包括:
通过预设的任务分发机制,将待处理数据和K-Mean聚类算法分发至各数据处理服务器;
将所述待处理数据以及计算要求超过预设阈值的K-Mean聚类算法存储在FPGA加速装置中;
通过所述FPGA加速装置执行所述K-Mean聚类算法,对所述待处理数据进行计算,获取计算结果。
优选地,所述将所述待处理数据以及计算要求超过预设阈值的K-Mean聚类算法存储在FPGA加速装置中,包括:
将所述待处理数据分次存储至所述FPGA加速装置的板载存储器中;
将超过预设阈值的K-Mean聚类算法进行分离,将分离出的所述超过预设阈值的K-Mean聚类算法发送至所述FPGA加速装置的FPGA芯片中。
优选地,所述通过所述FPGA加速装置执行所述K-Mean聚类算法,对所述待处理数据进行计算,获取计算结果,包括:
通过迭代的方式逐次调取所述板载存储器中的待处理数据;
通过所述FPGA芯片对所述超过预设阈值的K-Mean聚类算法进行加速优化,并对调取的所述待处理数据进行计算;
判断所述板载存储器中的待处理数据是否计算完毕;
若是,则将相应的计算结果返回至数据处理服务器主机端。
优选地,所述K-Mean聚类算法与所述K-Mean聚类算法所在的Spark集群的上层应用松耦合。
与现有技术相比,上述技术方案具有以下优点:
本发明所提供的一种用于大数据K-Mean聚类算法的加速系统,包括:数据处理服务器主机端,用于对数据处理任务按照预设的任务分发机制进行分配;n个数据处理服务器,用于获取Spark集群中的待处理数据和K-Mean聚类算法,其中,n为大于1的整数;FPGA加速装置,用于获取并存储预设数据量的待处理数据以及计算要求超过预设阈值的K-Mean聚类算法,并通过迭代的方式逐次调取待处理数据,执行K-Mean聚类算法对调取的待处理数据进行计算,并将计算结果返回至数据处理服务器主机端。本发明的技术方案,采用FPGA加速装置,为大数据的K-Mean聚类算法提供了硬件加速平台,K-Mean聚类算法在FPGA加速装置上进行加速优化实现,为Spark的机器学习提供了计算支持,从而实现了更为高效的对机器学习负载进行加速处理,以提供实时性更优的大数据处理服务,降低其功耗,缩短大数据处理周期。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种具体实施方式所提供的用于大数据K-Mean聚类算法的加速系统结构示意图;
图2为本发明一种具体实施方式所提供的用于大数据K-Mean聚类算法的加速方法流程图。
具体实施方式
本发明的核心是提供一种用于大数据K-Mean聚类算法的加速系统和方法,可以提升机器学习的性能,降低其功耗,缩短大数据处理周期。
为了使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
在以下描述中阐述了具体细节以便于充分理解本发明。但是本发明能够以多种不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广。因此本发明不受下面公开的具体实施的限制。
请参考图1,图1为本发明一种具体实施方式所提供的用于大数据K-Mean聚类算法的加速系统结构示意图。
本发明的一种具体实施方式提供了一种用于大数据K-Mean聚类算法的加速系统,包括:
数据处理服务器主机端1,用于对数据处理任务按照预设的任务分发机制进行分配;
n个数据处理服务器2,用于获取Spark集群中的待处理数据和K-Mean聚类算法,其中,n为大于1的整数;
FPGA加速装置3,用于获取并存储预设数据量的待处理数据以及计算要求超过预设阈值的K-Mean聚类算法,并通过迭代的方式逐次调取待处理数据,执行K-Mean聚类算法对调取的待处理数据进行计算,并将计算结果返回至数据处理服务器主机端。
在本实施方式中,数据处理服务器主机端、各数据处理服务器和FPGA加速装置形成了基于FPGA异构平台的数据处理底层实现模型。以对机器学习负载进行加速处理,提供实时性更优的大数据处理服务。采用FPGA加速装置,为大数据的K-Mean聚类算法提供了硬件加速平台,K-Mean聚类算法在FPGA加速装置上进行加速优化实现,为Spark的机器学习提供了计算支持,从而实现了更为高效的对机器学习负载进行加速处理,以提供实时性更优的大数据处理服务,降低其功耗,缩短大数据处理周期。
在上述实施方式的基础上,本发明一种实施方式中,FPGA加速装置包括:板载存储器,用于获取并存储各数据处理服务器发送来的预设数据量的待处理数据,以及存储K-Mean聚类算法对调取的待处理数据进行计算的计算结果,优选地,板载存储器为双倍速率同步动态随机存储器。
采用了板载存储器,使得Spark框架充分利用了内存计算技术,改进了IO的使用频度,有效地提升了大数据处理的性能。
FPGA芯片,用于获取计算要求超过预设阈值的K-Mean聚类算法,并通过迭代的方式逐次调取板载存储器中的待处理数据,执行K-Mean聚类算法以对该待处理数据进行并行计算,并将每次的计算结果暂存于板载存储器中。
FPGA加速装置接口,用于在通过FPGA芯片完成当前批次的待处理数据处理完毕后,将所有的计算结果返回至数据处理服务器主机端。
在本实施方式中,FPGA加速装置设计为了扩展卡式,其接口优选为PCIE3.0接口,核心部件为FPGA(现场可编程门阵列)芯片,板卡上进一步优选为DDR3/DDR4作为板载存储器,以提高存储速率。
进一步地,FPGA芯片包括:
K-Mean聚类算法加速模块,用于实现K-Mean聚类算法在FPGA芯片上的逻辑,针对不同维度、不同聚类中心节点数的聚类任务进行动态更新,经过对算法的优化,可以较好地匹配FPGA加速装置的硬件属性;
FPGA功能模块,用于根据K-Mean聚类算法加速模块中的K-Mean聚类算法对调取的板载存储器中的待处理数据进行并行计算。
更进一步地,数据处理服务器包括:
任务获取模块,用于从Spark集群中获取对应的待处理数据和K-Mean聚类算法;
数据分配模块,用于根据FPGA加速装置中的板载存储器的内存量分次将任务获取模块所获取的待处理数据保存至板载存储器;
算法分类模块,用于将任务获取模块获取的K-Mean聚类算法中计算要求超过预设阈值的K-Mean聚类算法进行分离,并发送至FPGA加速装置。
在本实施方式中,数据处理服务器主机端根据各数据处理服务器的自身性能对数据处理任务按照预设的任务分发机制进行分配,即性能高的数据处理服务器会分配到更多的数据处理任务,以提高数据处理的速度。而为了进一步提高数据处理性能,各数据处理服务器并不是一次性地将全部的待处理数据输送至板载存储器,而是根据板载存储器的内容容量来分次将待处理数据输送过去,这样保证了数据处理的效率。尤其是,数据处理服务器将K-Mean聚类算法中计算要求超过预设阈值的,即计算要求较高的部分分离,发送至FPGA加速装置中,通过FPGA加速装置对这部分的K-Mean聚类算法进行加速优化,并对相应的待处理数据进行并行处理。这样,对数据处理任务的分配和调度策略,可以有效提升机器学习的性能,还可以细化大数据处理平台的任务分配、调度等粒度,可以更加充分利用硬件计算资源更合理地完成数据分析任务。
此外,当前我国的电能主要由火力发电提供,对环境污染严重,而有效地提高MLlib机器学习的性能,同时可以降低其功耗,可以科学地精确地调度管理计算集群,这样可以有效降低数据中心能耗,减少排放污染,达到绿色环保的目的。
请参考图2,图2为本发明一种具体实施方式所提供的用于大数据K-Mean聚类算法的加速方法流程图。
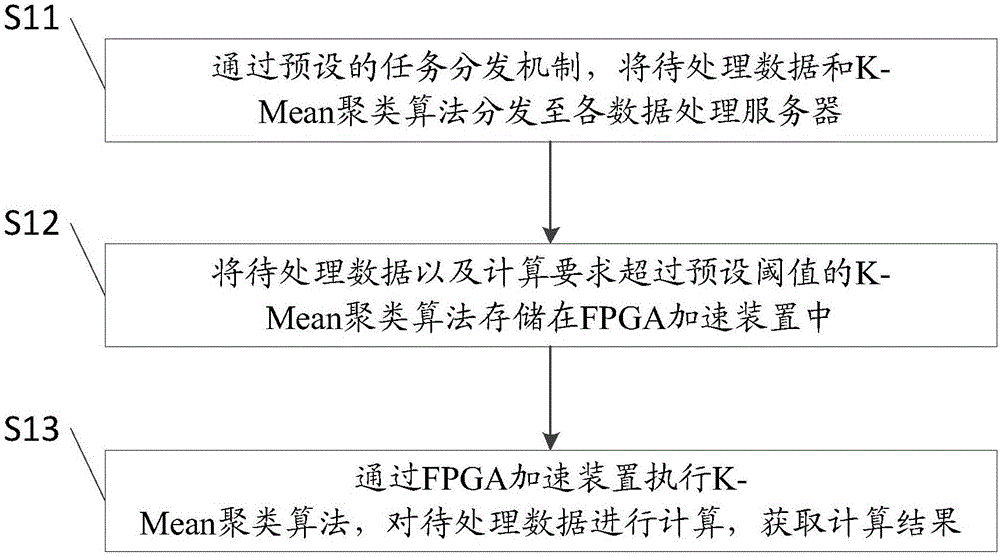
一种用于大数据K-Mean聚类算法的加速方法,包括:
S11:通过预设的任务分发机制,将待处理数据和K-Mean聚类算法分发至各数据处理服务器。
其中,通过预设的任务分发机制,指的是根据各数据处理服务器的性能来相应地分发任务,即性能较高的数据处理服务器分发到较多的数据处理任务。
S12:将待处理数据以及计算要求超过预设阈值的K-Mean聚类算法存储在FPGA加速装置中。
在本发明的一种实施方式中,将待处理数据以及计算要求超过预设阈值的K-Mean聚类算法存储在FPGA加速装置中,包括:
将待处理数据分次存储至FPGA加速装置的板载存储器中;
将超过预设阈值的K-Mean聚类算法进行分离,将分离出的超过预设阈值的K-Mean聚类算法发送至FPGA加速装置的FPGA芯片中。
采用了板载存储器,使得Spark框架充分利用了内存计算技术,改进了IO的使用频度,有效地提升了大数据处理的性能。将K-Mean聚类算法中计算要求超过预设阈值的,即计算要求较高的部分分离,发送至FPGA加速装置中,通过FPGA加速装置对这部分的K-Mean聚类算法进行加速优化,并对相应的待处理数据进行并行处理。这样,对数据处理任务的分配和调度策略,可以有效提升机器学习的性能,还可以细化大数据处理平台的任务分配、调度等粒度,可以更加充分利用硬件计算资源更合理地完成数据分析任务。
S13:通过FPGA加速装置执行K-Mean聚类算法,对待处理数据进行计算,获取计算结果。
通过FPGA加速装置执行K-Mean聚类算法,对待处理数据进行计算,获取计算结果,包括:
通过迭代的方式逐次调取板载存储器中的待处理数据;
通过FPGA芯片对超过预设阈值的K-Mean聚类算法进行加速优化,并对调取的待处理数据进行计算;
判断板载存储器中的待处理数据是否计算完毕;
若是,则将相应的计算结果返回至数据处理服务器主机端。
在本实施方式中,是按批次来进行数据处理,待当前批次的数据处理完毕后,可以将结果返回给数据处理服务器主机端,即管理节点,如果数据处理服务器还有数据待处理,则进行下一批次的数据的计算,直至分配的所有任务均被处理完成。
在本发明的一种实施方式中,K-Mean聚类算法与K-Mean聚类算法所在的Spark集群的上层应用松耦合。这就使得对上层应用透明,使用户无需关心底层的实现。
综上所述,本发明所提供的用于大数据K-Mean聚类算法的加速系统和方法,能够有效提升大数据K-Mean聚类算法的性能,进而缩短大数据处理周期,且能够降低其功耗,从而降低数据中心的能耗,减少排放污染,实现绿色环保。
以上对本发明所提供的一种用于大数据K-Mean聚类算法的加速系统和方法进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!