一种基于RCNN的图像检测以及流量统计方法与流程
本发明涉及图像检测方法及流量统计方法,尤其是涉及一种基于RCNN的图像检测以及流量统计方法。
背景技术:
所谓图像检测,就是通过图像对感兴趣的特征区域(检测目标)进行提取的过程,其中图像是承载检测目标的载体,检测目标需要事先进行特征提取、归纳,最终通过相应算法分离出来。图像检测方法主要是利用图像的灰度信息对目标进行分割,主要包括基于灰度闽值的日标检测方法和基于边缘信息的目标检测方法。
在RCNN之前,大部分的图像检测算法在很多年间都达到了瓶颈,难以突破,最好的算法也是将多种底层特征和高层语义结合进行图像检测。对于特征的提取,一直以来都是SIFT(D.Lowe.Distinctive image features from scale-invariant keypoints.IJCV,2004.1)以及HOG(N.Dalal and B.Triggs.Histograms of oriented gradients for human detection.In CVPR,2005.)的变形,难以有重大突破。SIFT和HOG都是像素块上的模型进行特征表示,我们可以粗略的把其和大脑皮层中V1层联系到一起,而我们也知道识别发生在高层皮层区,所以对于高层特征的提取和检测就即为重要。
CNN(K.Fukushima.Neocognitron:A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biological cybernetics,36(4):193–202,1980)由Fukushima受生物学发现的影响提出,虽然中间因SVM崛起且当时计算能力不足而受到压制,但是2012年LeCun(A.Krizhevsky,I.Sutskever,and G.Hinton.ImageNet classification with deep convolutional neural networks.In NIPS,2012.)在CNN中使用了max(x;0)rectifying non-linearities and“dropout”regularization等技巧而使得CNN在ImageNet比赛中表现突出,体现了其极强的特征提取能力,并且具有较好的高层特征提取能力。因此考虑将CNN应用到图像检测领域,经验证,取得了显著成果。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于RCNN的图像检测以及流量统计方法。
本发明的目的可以通过以下技术方案来实现:
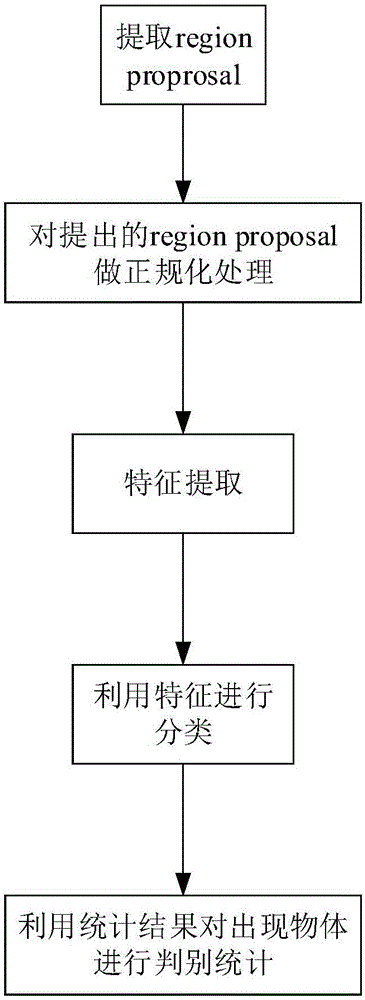
一种基于RCNN的图像检测以及流量统计方法,采用了先提取region proposal,然后利用ROI正规化到指定大小,利用卷积网络进行特征提取,最后利用SVM为每个类别做一个分类器进行分类以确定是否采用某个proposal;并对视频中通过的特定物体的数量进行流量统计。
该方法具体包括以下步骤:
第一步:利用与检测物体无关的普适提取region proposal的方法提取region proprosal;
第二步:因为提取得到的region proposal看做是任意大小的矩形,而CNN的输入应为227x227pixel size的图片,所以对提出的region proposal做正规化处理,使得处理后的图像为227x227pixel size;
第三步:特征提取,利用5层卷积2层全连接的CNN网络对图片进行特征提取,其中227x227pixel size的图片得到4096维特征;
第四步:利用特征进行分类,根据分类结果选取proposal;
第五步:利用统计结果对出现物体进行判别统计,得出流量统计的结果。
优选地,所述的第五步包括:通过结合前后几张picture的信息,将个别性的误判消除。
优选地,所述的第五步包括:
如果一个object从未被遮挡状态转入被遮挡状态,之后再次出现不会被判定为两次出现;
如果一个物体从被遮挡状态直接出现,而不是从视频到边缘处出现,可以进行识别并计数。
优选地,所述的第五步包括:RCNN将一些物体认为成我们所需要的object,并且持续的标记通过对圈的形状的设定,进行了规避。
优选地,所述的第五步包括:利用相邻两帧之间的物体距离进行物体判定与跟踪,包括四种状态以及四种状态之间的转换,具体为:
待定出现到确认出现:利用待定出现的累计次数作为变量进行判断,当其达到特定数量时进行转换;
确认出现到待定消失:若物体消失,则判断是否出现遮挡,如果不存在遮挡则由确认出现转换到待定消失;
待定消失到确认消失:利用待定消失的累计次数作为变量进行判断,当其达到特定数量时进行转换。
与现有技术相比,本发明基于RCNN的处理结果,充分利用视频中时间轴的信息得到了一个适用于普通视频,可以任意位置方向进出的流量统计算法,并可以处理物体重叠现象,测试结果与人眼结果比较达到了95%的准确率,较原算法有了极大的改进。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
RCNN为了克服之前提到的缺点,并充分利用CNN强大的提取特征以及分类的能力,采用了先提取region proposal,然后利用ROI正规化到指定大小,利用卷积网络进行特征提取,最后利用SVM为每个类别做一个分类器进行分类以确定是否采用某个proposal.
流量统计是对视频中通过的特定物体的数量进行统计,由于视角、检测质量等因素的影响,精确测量流量对于计算机来说是个较困难的任务。通过对情况进行限定,然后再逐步处理特定的特殊情况,可以对流量进行较准确的测量。经测试,这里给出的流量统计算法可以达到超过80%的准确率。
本次因为问题的特殊性,我们对每个特定的物体(如人、车等)进行分类训练,进行微调。以下是RCNN以及利用结果进行流量统计的具体实现步骤:
第一步:利用与检测物体无关的普适提取region proposal的方法提取region proprosal.如objectness(B.Alexe,T.Deselaers,and V.Ferrari.Measuring the objectness of image windows.TPAMI,2012),selective search(J.Uijlings,K.van de Sande,T.Gevers,and A.Smeulders.Selective search for object recognition.IJCV,2013.),category-independent object proposals(I.Endres and D.Hoiem.Category independent object proposals.In ECCV,2010)等等。
第二步:因为提取得到的region proposal可以看做是任意大小的矩形,而CNN的输入应为227x227pixel size的图片,所以对提出的region proposal做正规化处理,使得处理后的图像为227x227pixel size.正规化的方法有很多种,如tightest square with context,tightest square without context(前者的变形),warp等等。
第三步:特征提取。利用5层卷积2层全连接的CNN网络对图片进行特征提取。227x227pixel size的图片得到4096维特征。
第四步:利用特征进行分类,根据分类结果选取proposal。
第五步:利用统计结果对出现物体进行判别统计,得出流量统计的结果。此步骤也是我们的主要创新点。利用这个创新点,主要解决了以下几个问题。
1)RCNN有时会有误判,将本来不是object的部分标记。我们通过结合前后几张picture的信息,将个别性的误判消除,对此特殊情况进行了有效的避免。
2)RCNN对于有遮挡的物体无法识别。在这方面我们也进行了一些处理,通过我们的程序可以达到如下目标:如果一个object从未被遮挡状态转入被遮挡状态,之后再次出现不会被判定为两次出现;如果一个物体从被遮挡状态直接出现(而不是从视频到边缘处出现)可以进行识别并计数;
3)RCNN可能会对将一些物体认为成我们所需要的object,并且持续的标记(不同于第一种情况),这个我们通过对圈的形状(长宽比)的设定,进行了规避。
目前的利用图像的流量检测算法均是针对特定限制条件下的视频进行处理,比如高角度的监控视频等等。然而监控视频具有分辨率低,获取难度高的缺点,而且即便是高角度视频仍然具有图像重叠等问题。
为了方便个体以及小公司的使用,我们基于RCNN的处理结果,充分利用视频中时间轴的信息得到了一个适用于普通视频,可以任意位置方向进出的流量统计算法,并可以处理物体重叠现象,测试结果与人眼结果比较达到了95%的准确率,较原算法有了极大的改进。
下面对本次工作的实施例作详细说明,本实施例在以本创新工作技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本创新工作的保护范围不限于下述的实例。
本实例包括以下步骤:
第一步:利用selective search即选择搜索法选取region proposal。选择性搜索综合了蛮力搜索(exhaustive search)和分割(segmentation)的方法。选择性搜索意在找出可能的目标位置来进行物体的识别。与传统的单一策略相比,选择性搜索提供了多种策略,并且与蛮力搜索相比,大幅度降低搜索空间,让我们可以用到更好的识别算法。现实中,很多图像是包含多类别,多层次的信息的。所以我们要用到多层分割的方法,并且要用多种分割策略。
区域包含的信息比像素多,所以我们的特征是基于区域的。选择性搜索首先需要利用(Felzenszwalb,P.F.,&Huttenlocher,D.P.(2004).Efficient graph-based image segmentation.International Journal of Computer Vision,59,167–181.)的方法得到许多小的初始化区域。基于以下考虑1)捕获所有尺度,2)多样化归并方法,3)速度快,我们采用以下算法。使用贪心算法将区域归并到一起:先计算所有临近区域间的相似度,将最相似的两个区域归并,然后重新计算临近区域间的相似度,归并相似区域直至整幅图像成为一个区域。
第二步:对得到的proposal进行正规化,变成227x227pixel size的图片。这里采用了最简单的warp变换。
第三步:特征提取。利用5层卷积2层全连接的卷积神经网络进行特征提取。因为图像检测的监督数据需要物体类别以及物体位置,所以这方面的数据库较少较小,所以可以得到的监督数据相对较少。为了训练深度的卷积网络,需要在大数据训练样本数据中进行预训练。我们采用了Imagenet的超大图片级别标签数据进行预训练。之后再在特定领域内进行优化,使用的是随机梯度下降stochastic gradient descent(SGD)的方法,只修改最后一层全连接层。我们把所有的proposal中与实际box比较>=0.5IoU overlap的算作正数据,其他是负数据。SGD的初始学习率为预训练时候的十分之一即0.001.对每次迭代,训练样本中国含有32个正数据,96个负数据。
第四步:对每个类别训练一个SVM分类器。SVM分类器是快速的线性分类器,加入核技巧后可以看做为非线性的分类器。
第五步:首先声明四种状态:待定出现、确认出现、待定消失、确认消失。对于这四种状态之间的转换如下。当突然出现某个物体时使其处于待定出现,当待定出现累计次数超过特定数目的时候即转换到确认出现;当确认出现的物体消失的进行判断,如果存在物体遮挡的情况则不进行状态转换,否则转换到待定消失;如果待定消失累计超过特定数目则转换为确认消失,不再进行跟踪。对于物体的跟踪则利用相邻两帧之间特定物体出现的位置远近进行判断。
实施效果
实验条件:VS2010,Matlab 2014a,openCV 2.4.0。计算机处理器是Intel(R)Core(TM)2i5-42000M CPU@2.50GHz,内存4GB。
实验对象:针对RCNN的训练集和在校园门口拍的视频。
结果显示:对处理的两个视频中的车流量和人流量统计准确率达到了95%,取得了很高的识别效率。这一实验表明,本实施例的流量统计算法能有效地对流量行为进行检测。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!