一种基于多实例学习的视频目标追踪方法与流程
本发明涉及一种视频目标追踪方法,尤其是涉及一种基于多实例学习的视频目标追踪方法。
背景技术:
目标追踪是视频监控和视频分析中的重要内容,在社区安防、家庭护理等方面有着广泛的应用。尽管目前已经有了许多对于特定领域的目标追踪算法(例如专门对于面部或者人类的追踪),但在视频中追踪一般目标仍是一个比较有挑战的任务。
一些已有的算法大多使用了静态的外观模型(appearance model),即不会更新,而是一直使用第一个帧中目标的外观特征来判断之后所有视频帧中的情况,或者需要人工标定。这些方法有一个致命的缺点,就是在目标外观变化后就失效了。因此,那些会随着时间推移不断更新的适应性外观模型更加合理和合适,且也被证明拥有更好的追踪性能。
此外,一些算法仅使用目标物体的外观建模,而另一些则同时也使用了背景的外观特征。有实验证明,后者使用带有区别性的分类器来分离背景和目标物体,以训练模型拥有更好的追踪结果。
但这些方法都很少提及在更新外观模型时,如何选取正样本和负样本。正样本为包含目标的样本,负样本为不包含目标的样本。最常见的方法是,即把为每一帧追踪到的目标位置处作为一个正样本,而把其周围的采样作为负样本。然而,如果这个追踪到的位置本身就是不精确的,那么误差就会积累,结果会越来越偏差。另外,如果取多个目标位置周围的样本都作为正样本,则模型的分辨能力将会大大减弱。
为此,Boris Babenko,Ming-Hsuan Yang和Serge Belongie在论文“Visual Tracking with Online Multiple Instance Learning”中提出了一种利用多实例学习(Multiple Instance Learning),简称MIL,来更新模型,主要是解决如何选取正负样本来更新模型的问题。其主要思想是,在当前已追踪到的目标位置点一定范围内,选取一定样本。虽然不能判断它们每个是不是正样本,但可以确定它们中至少一个为正样本,因此将它们都放入一个正样本包中。在离追踪点较远的区域,同样选取一部分样本,可以确定它们不包含目标,所以将它们各自放入一个负样本包之中。然后用这些样本包,通过多实例学习方法来更新模型。
MIL算法的主要思想是维持一个含有M个弱分类器的池,并从中逐步选出K个组合成一个强分类器。每个弱分类器在含义上对应样本特征向量中的一维特征。其每次迭代选择的原则是在剩余的弱分类器中选出一个能使得包似然函数L最大化的弱分类器。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于多实例学习的视频目标追踪方法,具有提高目标跟踪精准度、提高跟踪效率等优点。
本发明的目的可以通过以下技术方案来实现:
一种基于多实例学习的视频目标追踪方法,包括以下步骤:
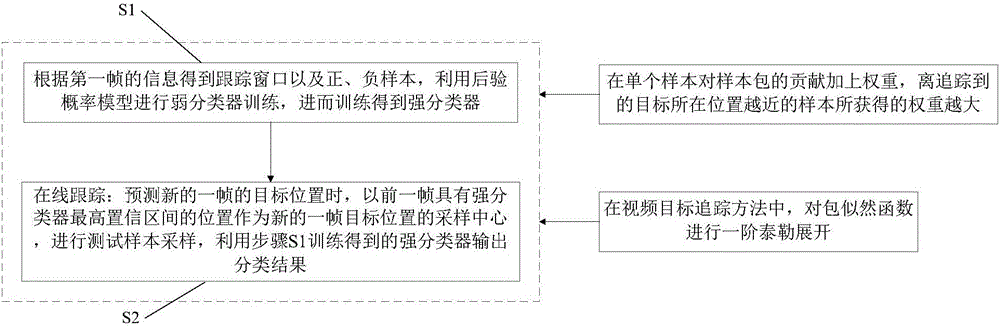
S1:根据第一帧的信息得到跟踪窗口以及正、负样本,利用后验概率模型进行弱分类器训练,进而训练得到强分类器;
S2:在线跟踪:预测新的一帧的目标位置时,以前一帧具有强分类器最高置信区间的位置作为新的一帧目标位置的采样中心,进行测试样本采样,利用步骤S1训练得到的强分类器输出分类结果;
在获取弱分类器的过程中,在单个样本对样本包的贡献加上权重,离追踪到的目标所在位置越近的样本所获得的权重越大。
所述权重采用与样本位置和追踪到的目标所在位置有关的欧式单调递减函数。
在视频目标追踪方法中,对包似然函数进行一阶泰勒展开。
在包似然函数进行一阶泰勒展开的基础上,对单个样本为正样本的概率和该单个样本所在样本包为正样本的概率的关系进行重新定义。
所述步骤S2获得的分类结果作为下一帧的输出位置的预测。
与现有技术相比,本发明具有以下优点:
1、针对现有离追踪到的目标所在位置较远的样本和较近的样本对样本包为正的重要性是一样的问题,本发为单个样本对样本包的贡献加上权重,离追踪到的目标所在位置越近的样本所获得的权重越大,大大提高了目标跟踪精准度。
2、针对现有算法运行效率低的问题,通过将包似然函数做一阶泰勒展开,并且对单个样本为正样本的概率和其所在的样本包为正样本的概率的关系进行重新定义之后,能够得到包似然函数,能够避免在每轮迭代中计算单个样本为正样本的概率和其所在的样本包为正样本的概率,加快计算的速度。
附图说明
图1为本发明方法示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
现有MIL算法描述中,单个样本为正样本的概率和其所在的样本包为正样本的概率的关系应用可Noisy-OR模型。也就是说,对于正样本包中的每个样本,该算法认为它们对于所在的包为正的概率的贡献度是一样的。然而,仔细思考一下并不是这样,因为该算法认为离追踪到的目标所在位置较远的样本和较近的样本对样本包为正的重要性是一样的,不是很合理。这样会导致最终选出的弱分类器并不是很有效。
因此,在改进算法中,我们为单个样本对样本包的贡献加上权重,离追踪到的目标所在位置越近的样本所获得的权重越大。即,离追踪到的目标所在位置越近的样本,为正样本的概率更大,对于样本包为正的概率的贡献度就越大。
此外,在运行原算法程序时,发现速度较慢,因而思考如何能加快算法的时间效率。在算法中,本发明注意到单个样本为正样本的概率和其所在的样本包为正样本的概率在循环中都需要被计算K*M次,略显多余。主要原因是计算包似然函数需要依赖于单个样本为正样本的概率和其所在的样本包为正样本的概率。如果能将包似然函数的每一轮计算与其前一轮计算的结果关联起来的话,就可以避免在M个循环中每次都重新计算一遍。通过将包似然函数做一阶泰勒展开,并且对单个样本为正样本的概率和其所在的样本包为正样本的概率的关系进行重新定义之后,能够得到上述形式的包似然函数,能够避免在每轮迭代中计算单个样本为正样本的概率和其所在的样本包为正样本的概率,加快计算的速度。不过同时,上述形式的包似然函数并不和原来的函数完全等价,而是牺牲了一些精度,换取了速度。
综上,本发明提出一种基于多实例学习的视频目标追踪方法,如图1所示,包括以下步骤:
S1:根据第一帧的信息得到跟踪窗口以及正、负样本,利用后验概率模型进行弱分类器训练,进而训练得到强分类器;
S2:在线跟踪:预测新的一帧的目标位置时,以前一帧具有强分类器最高置信区间的位置作为新的一帧目标位置的采样中心,进行测试样本采样,利用步骤S1训练得到的强分类器输出分类结果;
在获取弱分类器的过程中,在单个样本对样本包的贡献加上权重,离追踪到的目标所在位置越近的样本所获得的权重越大。
权重采用与样本位置和追踪到的目标所在位置有关的欧式单调递减函数。
在视频目标追踪方法中,对包似然函数进行一阶泰勒展开。
在包似然函数进行一阶泰勒展开的基础上,对单个样本为正样本的概率和该单个样本所在样本包为正样本的概率的关系进行重新定义。
步骤S2获得的分类结果作为下一帧的输出位置的预测。
实施效果
依据上述步骤,对于三个视频tiger2,twining和dollar,用原有方法和改进方法皆进行了实验。三个视频文件夹可在release文件夹中找到。文件夹内为视频的图片序列。文件夹格式为“VidClip1/imgs”,其中VidClip1为视频的名字,例如名为twining,tiger2等文件夹,每个代表了不同的输入。在各自的目录下,有一个“img”文件夹和两个文件——VidClip1/VidClip1_frames.txt以及VidClip1/VidClip1_gt.txt。img文件夹内就包含了这个视频的所有图片帧序列,且命名需要为img00000.png,img00001.png,以此类推。文件VidClip1/VidClip1_frames.txt则只包含了一行,指出了视频的开始的帧序列和结束的帧序列,
用逗号隔开。例如0,100就表示这个视频是从img00000.png到img00100.png。文件VidClip1/VidClip1_gt.txt则是ground truth file,其中每行有4个数据,即[x,y,width,height],分别代表了每个frame中object实际在的位置x与y,以及tracker框的宽度和高度。这个文件中的数据是用来与程序实际跑出来的结果做对比的,这个文件中的数据是最理想情况下的结果。
程序输出有两个,一个为txt文件,包含了程序对于每一个frame算出的tracker location。类似上述的VidClip1_gt.txt文件,每一行也都有4个数据[x,y,width,height]。但注意,在和VidClip1_gt.txt比较时,因为gt文件里每隔5个frame才有数据,因此,也只能把结果中的对应frame的结果与之比较。
另外一个输出为视频,格式为avi的格式。txt文件和视频文件都会在运行程序之后出现在VidClip1/文件夹下,其中,视频文件名中有MIL后缀的为原算法的结果,有newMIL后缀的则是改进算法的结果。
首先我们看改进算法对于追踪效果上的改进,通过比较两个输出视频截取的部分帧的追踪结果以及各自与ground truth file中的理想情况的比较。
先看视频tiger2在两个算法下的输出结果对比。通过比较可以发现,在没有什么遮挡物的情况下,改进算法比原来算法的效果只好一点点,基本没有太大的区别。但是在有遮挡物的情况下,改进算法的效果就比较好,仍然可以很好的跟踪到目标所在的位置,而不是丧失了焦点。
此外,通过将两个算法生成的txt文件与gt文件做了对比,计算出了各自平均的中心点误差(像素点),即将生成文件中追踪到的点位置与gt文件中对应帧的实际点位置的距离的平均。原算法的平均误差为17pixel,而改进的算法可以达到9pixel。
接下来看一下视频twining的结果。通过比较也可以发现,改进算法比原来算法的效果要更好一点。通过与gt文件的比较,原算法的平均误差为7pixel,改进算法为5pixel。
再来看改进算法对速度上的优化。原方法在搜索tiger2时平均用时在317s左右,用改进算法则只需要103s左右,快了2倍多,因此对速度上的改进是很大的。原因也很显然,因为避免了K*M次的两次运算,大大减少了运算量。
综上所述,本发明是一种基于多实例学习来更新分类器,以判别出目标在新视频帧内所在的位置,而最终追踪目标在每一视频帧中的位置的视频目标追踪方法。每次,在当前已追踪到的目标位置点一定范围内,选取一定样本。将它们都放入一个正样本包中。在离追踪点较远的区域,同样选取一部分样本,将它们各自放入一个负样本包之中。然后用这些样本包,通过多实例学习方法来更新模型。之后在处理新视频帧时,用这个更新过的模型来识别新视频帧中目标所在的位置。
- 还没有人留言评论。精彩留言会获得点赞!