一种异构网络中多维个性化推荐方法与流程
本发明涉及异构信息网络中基于元路径的相关性搜索方法和结合用户反馈信息与从属信息的多维个性化推荐方法,属于数据挖掘和机器学习的
技术领域:
。
背景技术:
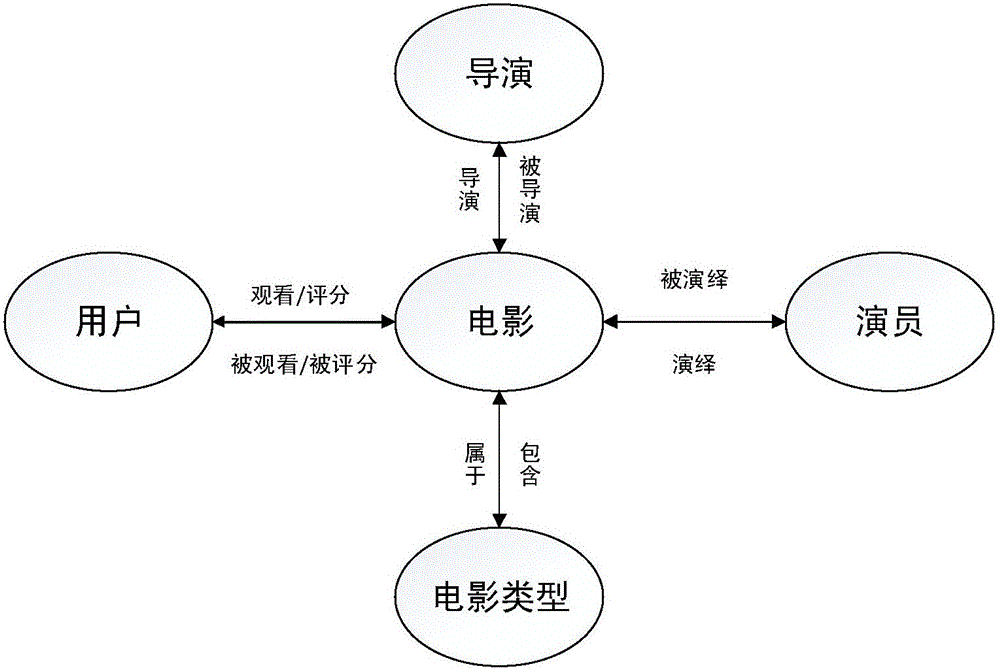
:近年来,异构信息网络因擅长表示不同类型实体之间各种不同的关系且能够准确地区分信息网络中的不同语境挖掘出更具有意义的知识而被广泛研究。其中,表示两个实体间关系的元路径是异构信息网络中一个独特的概念,不同的元路径代表着不同的物理意义,元路径所蕴含的丰富的语义特征,是异构信息网络的一大非常重要的特征。许多异构信息网络中基于元路径的数据挖掘任务正在被开展,推荐更是其中的最具活力的研究方向之一。在海量数据爆炸性增长的今天,推荐系统作为一种解决信息过载的有效手段,重要且必不可少,而个性化推荐系统通过建立用户与产品之间的二元关系,利用用户已有的选择过程或相似性关系挖掘每个用户潜在感兴趣的对象,能够做到更有针对性的推荐用户真正需要的产品。传统的推荐系统多是基于用户和项目矩阵做文章,其中最成功影响最广泛的是协同过滤算法。传统的协同过滤算法分为基于记忆的协同过滤算法和基于模型的协同过滤算法,两者都是只利用了单一用户项目矩阵的信息,推荐精度有限。面对传统推荐系统用户与物品间单一的关系并且未考虑物品内容和用户属性以及没有考虑用户与物品间丰富的语义信息等缺点,如何将含有用户反馈信息的传统推荐方法与异构信息网络强大的综合信息集成能力和蕴含的丰富的语义信息相结合,进行个性化推荐,是一个有待解决的问题。技术实现要素:针对现有技术的不足,本发明提供了一种异构网络中多维个性化推荐方法;本发明提供一种基于元路径的异构网络中多维个性化推荐方法。该方法利用不同元路径蕴含的不同的语义信息的基础上,结合用户反馈信息,为用户提供一种多维度的个性化推荐方法,使得推荐结果更具有准确性、实用性和多样性。术语解释1、非负矩阵分解,是找到非负矩阵与使得。在计算中等式两者很难完全相等。在计算中往往是根据某更新法则迭代更新出两个乘子,当上式左右两端的距离(如欧式距离)满足我们设定的大小,停止迭代;2、异构信息网络(HeterogeneousInformationNetwork),可以简称为异构网络。若一个信息网络中顶点的类型或者是边的类型的个数超过一个,则此信息网络称为异构信息网络,否则为同构信息网络。本发明的技术方案为:一种异构网络中多维个性化推荐方法,具体步骤包括:(1)获取信息:获取用户自身信息及用户间社会关系信息,项目自身信息及项目间互动关系信息和用户对项目的反馈信息;所述项目是指除用户类型之外的其它类型;用户自身信息,例如,用户的年龄、地区、喜好等;用户间社会关系信息,例如,关注与被关注关系、朋友关系等;项目,例如,电影;当项目是指电影时,项目自身信息,例如,包括电影的上映时间、电影的类型等;项目间互动关系信息,例如,包括电影项目与主演项目间有演绎和被演绎等互动关系,用户对电影项目有标注、评分等互动信息。以最经典的电影推荐网络来说,项目代表电影、演员、导演、电影类别标签等多种类型。可以为用户推荐与其相似的电影、演员、导演、电影类别等,达到多维推荐的目的。(2)构建用户与项目间相似度矩阵:所述用户与项目间相似度矩阵表示用户对项目喜爱与否的直接反映,用户对项目的偏好程度;(3)构建半结构化异构信息网络,基于半结构化异构信息网络,计算不同元路径下每一个用户与每一个项目之间和任意用户之间的相似度,得到在该元路径下用户与用户之间和用户与项目之间的相似度矩阵;用户与项目之间的相似度矩阵中行与行之间的相似度表征用户之间的相似性,用户与项目之间的相似度矩阵中列与列之间的相似度表征项目之间的相似性;对每一条元路径下所生成的用户与项目之间的相似度矩阵都能得到一种用户之间的相似性以及项目之间的相似性,根据领域知识对不同的相似性分配不同的权重,融合为半结构化异构信息网络中用户与项目间的相似度矩阵,矩阵中的值表示了每个用户与每个项目之间的相似性大小;值越大,相似度越高;(4)分配不同的权重,将半结构化异构信息网络中用户与用户之间相似度矩阵、用户与项目之间相似度矩阵,与用户对项目的反馈信息融合,得到最终的相似度矩阵;例如,当项目是指电影时,用户对项目的反馈信息是指用户对电影的评分。与用户对项目的反馈信息融合,使得结果更加个性化。(5)将最终的相似度矩阵中相似度较大的若干项目推荐给用户。根据本发明优选的,所述步骤(2),具体是指:若存在用户对项目的评分数据,则获取用户对项目的评分数据,构造评分矩阵,并采用非负矩阵分解算法补全评分矩阵;否则,则利用收集到的用户从属信息和项目从属信息计算用户与项目间相似度矩阵;从属信息包括:社交网络信息(信任关系、粉丝追随关系和朋友关系等)和用户贡献的信息(用户的标签、用户评论内容、用户地理位置和用户发布的动态等信息)。例如在电影推荐网络中,用户从属信息包括年龄、性别和其标签等,当项目是指电影时,项目从属信息包括电影的上映时间、电影体裁等;当项目指导演时,项目从属信息包括年龄、性别和其经常导演的电影的体裁表示;采用非负矩阵分解算法补全评分矩阵,因为根据收集的信息所构建的评分矩阵维数很高并且是非常稀疏的,此处最直接的方法就是用矩阵分解方法将评分矩阵补全,而用户对项目的评分数据都是非负数,所以此处选用非负矩阵分解算法。根据本发明优选的,所述步骤(2),具体步骤包括:①若存在用户对项目的评分数据,则将用户原始评分矩阵记为Um×n,m为用户数目,n为项目的数目,进入步骤②,若不存在用户对项目的评分数据,进入步骤③;②对Um×n采用非负矩阵分解算法分解为两个非负矩阵Pm×k和Qk×n,使得分解后矩阵满足式(Ⅰ):Um×n≈Pm×k×Qk×n=U~m×n---(I)]]>式(Ⅰ)中,矩阵Pm×k为用户因子矩阵,矩阵Pm×k中所有元素非负,矩阵Qk×n为项目因子矩阵,矩阵Qk×n中所有元素非负;通过式(Ⅰ)将高维矩阵Um×n分解成为两个低维的用户因子矩阵Pm×k和项目因子矩阵Qk×n。③调整余弦相似度或皮尔逊相似系数距离度量方式,计算任意用户与任意项目之间的相似度,构成相似度矩阵。将原始的评分矩阵Um×n分解成两个矩阵Pm×k和Qk×n的乘积,将这个问题转化为机器学习中的回归问题。此处,采用的损失函数为原始的评分矩阵Um×n与重新构建的评分矩阵之间的误差的平方作为损失函数,为防止过拟合,可以加入正则化项;根据本发明优选的,所述步骤(3),具体步骤包括:a、构建半结构化异构信息网络G,G=(V,E),V表示半结构化异构信息网络G中顶点,E表示半结构化异构信息网络G中的边;将半结构化异构信息网络G中任意两个实体表示为和,如果这两个实体之间通过元路径可达(或者说两实体间存在连接边即存在某种关系),则这两个实体间存在边E;任意一个节点v∈V,V属于节点类型集合A中的元素;A=A1,A2,A3,···Al+1,任意一个边e∈E,E属于边的类型集合R中的元素;所述实体包括所述项目、所述用户;如果两个实体类型都表示同一个类型的项目,例如两个顶点都表示电影项目类型或者是都表示主演项目类型等,则这两个顶点是同一个类型的,标识的实体类型相同。如果两条边连接着同一种类型的源节点和目的节点,则两条边属于同一种边的类型。b、根据步骤a构建的半结构化异构信息网络G,提取半结构化异构信息网络G的网络模式,表示为TG=(A,R);网络模式TG=(A,R)是半结构化异构信息网络G=(V,E)的基础模板,对网络中节点和边的类型进行了限制,正是这种限制导致了网络的半结构化,指导了网络的语义内涵探索。c、根据半结构化异构信息网络G的网络模式,构建元路径P:元路径P定义在网络模式TG=(A,R)上,在不引起歧义的情况下,直接用节点类型来表示元路径P,表示如式(Ⅱ)所示:P=(A1A2A3···Al+1)(Ⅱ)例如,直接表示为APA,若P1=(A1A2A3···Al),P2=(B1B2B3···Bk),则P=(P1P2)=(A1A2A3···AlB2B3···Bk),例如,元路径MAM(电影-演员-电影)代表的是由同一个演员主演的电影,而元路径MGM(电影-类别-电影)则代表同属于一个类别的电影。否则,元路径P的表示如式(Ⅲ)所示:式(Ⅲ)中,表示了从实体A1到实体Al+1的复杂的关系,R=R1οR2οR3ο···οRl;ο代表关系上的连接操作,元路径P的长度即为R的个数;不同元路径代表着不同的物理意义,元路径所蕴含丰富的语义特征,是异构信息网络区别于同构网络的一大非常重要的特征。在不引起歧义的情况下可以直接用节点类型来表示元路径。d、根据不同的元路径,应用Hetesim算法获得不同元路径下用户和项目间的相似度矩阵。根据本发明优选的,所述步骤(4),包括:将步骤(2)得到的用户与项目间相似度矩阵和步骤(3)得到的用户与其他类型实体间的相似度矩阵进行融合,得到用户和项目之间的相似度矩阵。根据本发明优选的,采用取多个结果平均值的融合方法,将步骤(2)得到的用户与项目间相似度矩阵和步骤(3)得到的用户与其他类型实体间的相似度矩阵进行融合,得到用户和项目之间的相似度矩阵。经过融合之后可以得到最终的用户和任意一种类型的项目之间的相似度。本发明的有益效果为:1、在传统的推荐方法中加入了用户从属信息和项目从属信息,并且考虑了用户与项目之间的丰富的语义信息,提高了推荐的准确率和覆盖率。2、在推荐过程中考虑了用户与项目之间的互动信息,体现了用户的偏好程度,实现了个性化推荐。3、本发明可以计算任意用户和任意类型的项目之间的相似度,不拘泥于向用户推荐某一种类型的商品,可以向用户推荐任意类型的商品,实现多维度的推荐。附图说明图1是实施例电影推荐网络的场景描述示意图。图2是图1对应的异构网络网络模式示意图。图3(a)是图2中对应的元路径“电影-演员-电影”示意图。图3(b)是图2中对应的元路径“电影-类别-电影”示意图。图3(c)是图2中对应的元路径“用户-电影-演员-电影”示意图。图3(d)是图2中对应的元路径“用户-电影-类别-电影”示意图。图4是实施例用户从属信息、电影从属信息举例示意图。图5是Hetesim算法计算方法示意图。图6是本发明的详细流程图。具体实施方式下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。实施例本实施例参照电影推荐网络,如图1所示,电影推荐网络是一个有权有向的异构信息网络,在此网络中存在5种不同的实体类型:用户(包括用户1、用户2)、电影(包括电影1、电影2、电影3、电影4)、导演(包括导演1、导演2)、主演(包括演员1、演员2)和电影类别(包括电影风格1、电影风格2)。针对每一个电影实体都会有它的主演、导演和电影类别实体跟其相连。用户对其看过的电影给予1--5分的评分。根据用户的属性信息,按照观影兴趣将用户分为不同的用户组,划分可重叠,同一用户组喜欢相同风格的电影或喜欢同样的明星导演等。在本实施例中,为用户推荐其可能喜欢的电影、兴趣小组、导演、演员等,实现个性化的多维推荐。该电影推荐网络中多维个性化推荐方法,具体步骤包括:根据用户对电影的评分数据构建表征用户偏好度的评分矩阵U,U矩阵中数据为非负数、维数很高且极为稀疏。非负矩阵分解是指将一个高维矩阵分解为两个或多个低维的非负矩阵乘积的形式,达到降维的目的,并可对原稀疏矩阵中的空值进行预测。应用到本实施例的用户对电影评分数据中,将用户原始评分矩阵记为Um×n,m为用户数目,n为电影数目。对其应用非负矩阵分解算法分解为两个非负矩阵Pm×k和Qk×n,使得分解后矩阵满足:矩阵Pm×k中所有元素非负,表示的是m个用户与k个主题之间的关系,而矩阵Qk×n中所有元素非负,表示的是k个主题与n个电影之间的关系。将原始的评分矩阵Um×n分解成两个矩阵Pm×k和Qk×n的乘积,将这个问题转化为机器学习中的回归问题。此处,采用的损失函数为原始的评分矩阵Um×n与重新构建的评分矩阵之间的误差的平方作为损失函数,为防止过拟合,可以加入正则化项;为保证运算过程中所有矩阵为非负的,所以采用乘性更新规则,如下所示:及逐步迭代,直到算法最终收敛。利用上述的过程,得到矩阵Pm×k和Qk×n,这样便可以为用户i对商品j进行打分:Σk=1Kpi,kqk,j]]>最终得到处理后的用户对项目的评分矩阵来表征用户对该项目的偏好度。本实施例获取的数据中有用户对电影的评分数据,可以得到用户对电影的偏好度矩阵。若收集到的信息中没有用户评分信息,则用用户的从属信息表征用户,用项目的从属信息表示项目,本实施例中用户和电影的从属信息情况如图4所示。在本实施例中,将常用的电影类型作为一个有顺序的属性池。用该用户喜欢的电影类型的标签作为用户的属性,第i个用户ui的值按照属性池中的位置赋值1和0,则ui=(0,1,0,0,0,1,1,0,。。。),用该导演经常导的电影的体裁作为导演的属性,第j个导演dj的值按照是否存在属性池中的对应位置的属性在对应的位置赋值1和0,则dj=(1,0,0,0,0,1,1,1,。。。)。此处使用余弦相似度作为相似度度量标准计算用户和导演之间的相似度。任意用户和任意导演之间都有一个相似度值,这样就构成了用户和导演之间的相似度矩阵UD,可表征用户对导演的偏好度。用户和演员之间的相似度矩阵UA,用户和电影类型之间的相似度矩阵UG构建原理和过程与上相同。得到:用户对电影、导演、演员和电影类型的偏好度矩阵。根据获取的信息构建有权有向半结构化异构信息网络,信息网络可以定义为一个有向图G=(V,E),任意一个节点v∈V都属于特定的节点类型集合A中的元素;任意一个边e∈E都属于特定的边的类型集合R中的元素。如果两条边属于同一种边的类型,则这两条边连接着同一种类型的源节点和目的节点。如果节点的类型数目或边的类型数目大于1,则称此信息网络为异构信息网络,否则为同构信息网络。接下来我们根据异构信息网络信息构建该网络的网络模式,可以帮助我们更好地理解一个复杂异构信息网络中的节点的类型和边的类型。根据异构信息网络的定义,我们将图1场景图映射到异构信息网络中,根据异构网络有向图的定义,把物品实体映射为图中相应的节点,如电影、导演、演员等都是一个实体,用实体的类型作为相应节点的类型。若任意两个实体之间有联系,则对应的两个节点之间存在连边。网络模式TG=(A,R)是异构网络G=(V,E)的基础模板,对网络中节点和边的类型进行了限制,正是这种限制导致了网络的半结构化,指导了网络的语义内涵探索。本实施例中网络模式如图2所示,用户和用户之间可以有互动可以组成用户组,用户和电影之间有评分和被评分的关系,电影和导演之间有被导演和导演的关系,电影和演员之间有演绎和被演绎之间的关系,电影和类别之间有属于和包含的关系。为了更好地分析异构信息网络中隐含的各种不同的语意,可以分析网络中的元路径,元路径是两个对象类型之间的一系列的关系序列,通过元路径可以有效地挖掘网络中丰富的语义信息和隐藏的知识。元路径P是定义在网络模式TG=(A,R)上的,如表示了从实体A1到实体Al+1的复杂的关系,P=R1οR2οR3ο···οRl。其中,ο代表关系上的连接操作。元路径P的长度即为关系R的个数。在不引起歧义的情况下也可以直接用节点类型来表示元路径P=(A1A2A3···Al+1),例如:可以直接表示为APA。若P1=(A1A2A3···Al),P2=(B1B2B3···Bk),则P=(P1P2)=(A1A2A3···AlB2B3···Bk)。不同元路径代表着不同的物理意义,元路径所所蕴含的丰富的语义特征,是异构信息网络区别于同构网络的一大非常重要的特征。图3(a)是元路径“电影-演员-电影”示意图。图3(b)是元路径“电影-类别-电影”示意图。图3(c)是元路径“用户-电影-演员-电影”示意图。图3(d)是元路径“用户-电影-类别-电影”示意图。在元路径MAM(电影-演员-电影)代表的是由同一个演员主演的电影,而元路径MGM(电影-类别-电影)则代表同属于一个类别的电影。表1为不同的元路径所蕴含的不同的语义信息示例图:表1元路径物理意义电影-演员-电影(MAM)由同一个演员主演的电影用户-电影-演员-电影(UMAM)用户看过的由同一个演员主演的电影电影-类别-电影(MGM)同属于一个类别的电影用户-电影-类别-电影(UMGM)用户看过的同属于一个类别的电影构建元路径步骤完成后,接下来是应用Hetesim算法构建不同元路径下实体(同种类型和不同种类型)间的相关度,组成相关度矩阵。Hetesim的基本思想是:如果两个实体被相似的两个实体指向或分别指向两个相似的实体,那么这两个实体也相似。例如:相似的研究者会发表相似主题的论文,相似的顾客会购买相似的商品等。给定相关路径P=R1οR2οR3ο···οRl,任意两个实体s和t之间的相关度Hetesim的定义是:O(s|R1)是s基于关系R1的出度,I(t|Rl)是实体t基于关系Rl的入度。若s没有任何出度或t没有任何入度,则定义两实体间的相似度为0.如图5所示,计算作者(A)Tom和会议(C)KDD之间基于元路径APC的相关度,则:因为O(Tom|AP)={P1,P2}且I(KDD|PC)={P1,P2},所以Hetesim(Tom,DD|APC)=0.5。也就是说沿着该元路径,Tom和KDD相遇的概率是0.5。Hetesim可以计算任意类型的两个实体基于不同元路径的相关度。本实施例中,采用Hetesim算法计算每一个用户与任意电影之间的相关度,构成用户和电影之间的相关度矩阵hete_UM,用户和导演、演员、电影类型之间的相关度矩阵hete_UD,hete_UA,hete_UG也可以得到。在上述推荐方法中,将得到的用户偏好度矩阵和得到的用户与项目间相关度矩阵进行融合,最终得到用户和项目之间的相似度矩阵。融合方法很多,本发明采用了较简单的取多个结果平均值的融合方法,经过融合之后可以得到最终的用户和任意一种类型的项目之间的相似度。例如为用户A推荐电影,直接取用户-电影相似度矩阵中用户A的那一行数据中相似度值最大的若干部电影即可。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1