一种针对医疗诊断文本的概念连接方法与流程
本发明涉及一种概念连接方法,尤其涉及一种针对医疗诊断文本的概念连接方法。
背景技术:
知识图谱(KG)以符号方式整理收纳了大量知识,易于演算和推论。但是,它也有先天缺陷。由于知识图谱是经多人手工制作的,符号性导致其相对难处理,要知道,使用经过编码的知识并不是轻而易举的事。通常,使用知识图谱面临几项挑战:有些概念或者是太专业,或者是太宽泛;同一属性的概念出现在图谱的不同部分前后矛盾;一些概念模糊不清。此外,知识图谱一般只有通过加进新的概念和关系才能扩充,由此重构成本也相当昂贵。
在医学领域中,术语和词汇表使用得特别多,因为在该领域,重大的工程努力已造就了海量的使用标准词汇表的知识图谱。这些知识图谱保存有大量的重要数据,其中包括医生看病时写下的原始文本医疗诊断记录。如需搜寻、索引、特征化相关病例,通常的预处理步骤是对知识图谱进行相关的概念连接。
概念连接:亦称文本spans和概念的连接,是开发知识图谱中储存的信息财富的重要的第一步。常用的快捷概念连接方法是直接从同义词数据库中提取与之相配的字符串,这样做的优点是精确率比较高,但缺点是召回率低。众所周知,召回率是检索出的相关文档数和数据库中所有的相关文档数的比率,而精确率是检索出的相关文档数与检索出的文档总数的比率。凡是设计到大规模数据集合的检索和选取,都涉及到“召回率”和“精确率”这两个指标。由于这两个指标相互制约,召回率高时,精确率低,精确率高时,召回率低,人们通常也会根据需要为检索策略选择一个合适的度,不能太严格也不能太松,寻求在召回率和精确率中间的一个平衡点。这个平衡点由具体需求决定。
在医疗诊断文本的概念连接中,更看重的是精确率,但召回率也不能过低。
技术实现要素:
有鉴于此,提供一种对医疗诊断文本进行概念连接的新方法。该方法利用循环神经网络模型,模拟基于规则的系统采用的一系列复杂的形态和句法的转 换,并使用向量式概念符号在测试时概括整理不可见的概念,共有其特征,然后沿图谱多层预测整个遍历,进行概念连接。
其中,一系列复杂的形态和句法的转换包括词根提取、后缀替换、首字母缩写词扩展。
所述的针对医疗诊断文本的概念连接方法包括以下步骤:
第一步,构建循环神经网络系统(RNNs),所述的循环神经网络系统包括span编码器,概念编码器,解码器;
第二步,对模型进行训练,所述的模型的基本数据源取自知识图谱中的医学系统命名法——临床术语(SNOMED-CT)和输入-输出数值;
第三步,采用基于规则的算法,应用一系列复杂的形态和句法的转换,准确识别医疗记录的spans,并加注标签,形成相关概念的大数据集;
第四步,对上述步骤的结果进行概念连接。
本发明实施技术方案的有益效果包括:
1、方案易实现和移植,采用了通用的循环神经网络系统(RNNs)基于规则的算法,包括一个span编码器,一个概念编码器和一个解码器,这套基本框架是通用的,可以很容易的移植到如不同医院的信息系统里并根据实际疾病的情况进行二次开发和升级。
2、本方案的实验基于大量的医学文本数据,体现了技术方案的可行性。
3、方案的其中一个重要目的是对医疗记录加注标签,从而形成相关概念的数据集为下一步的概念连接做准备。而本方案对训练好的模型采用基于规则的算法,应用一系列复杂的形态和句法的转换如词根提取、后缀替换、首字母缩写词扩展等,准确识别医疗记录的spans,并加注标签,形成相关概念的大数据集。规则引用了专家知识,而专家知识可以根据不同疾病的实际情况添加修改,从另一角度也体现了方案可移植性的优点。而经实验证明可以达到对医疗记录spans识别的需求,从而实现了较高的精确率和召回率。
附图说明
图1一种针对医疗诊断文本的概念连接方法的模型的结构图。
图2一种针对医疗诊断文本的概念连接方法的步骤图。
具体实施方式
下面结合具体实施例对本发明进行详细的说明。
一种针对医疗诊断文本的概念连接方法,该方法利用循环神经网络(RNNs)处理概念连接问题,特别着眼于用向量式概念符号在测试时概括整理不可见的概念,共有其特征,然后沿图谱多层预测整个遍历,使模型能满意地取得较好的连接效果。该方法包括以下步骤,如图2所示,
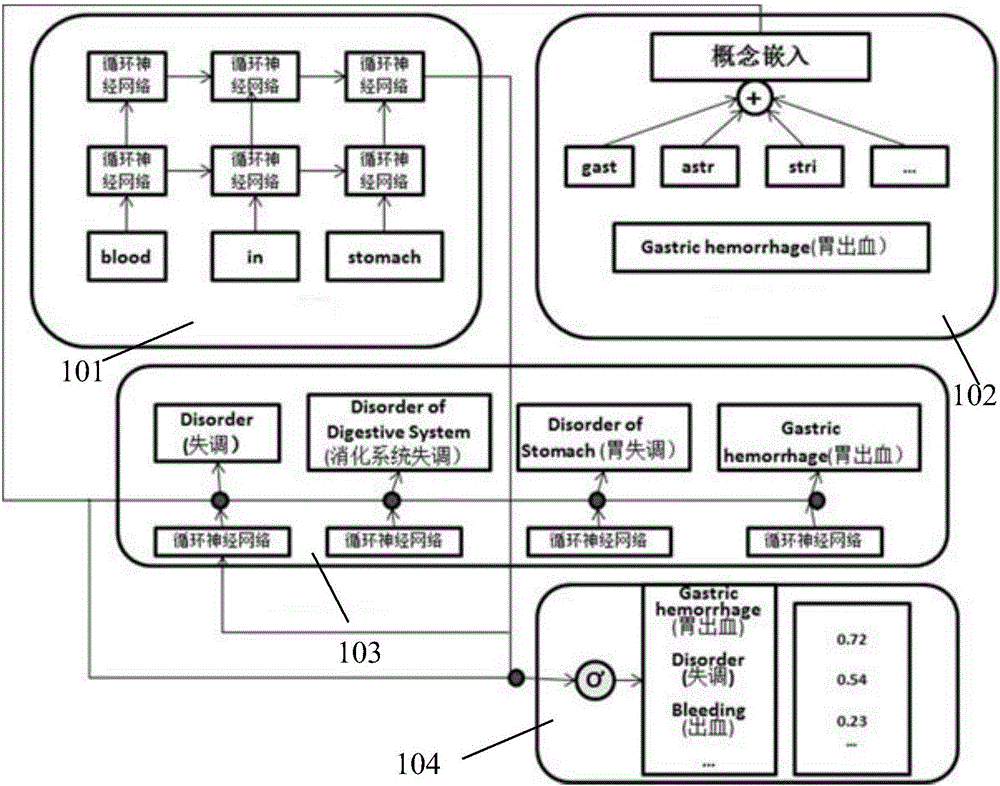
第一步201,构建循环神经网络系统(RNNs),如图1所示,组成件包含:
一个span编码器101,这是一个2层256单位的长短时记忆编码器,输入的span用词向量(由GloVe预训练)表示,产生256维的元素嵌入es,该输出对应于上一时间步的隐状态。
一个概念编码器102:该编码器通过平均每一概念的4-grams嵌入(此4-grams嵌入为随机初始化),产生一个256维的嵌入ec,然后将这些向量叠加为矩阵Ec。
一个解码器,本实施例设计了两种可能的解码器,一种是扁平解码器104,一种是序列解码器103,用于读取span和概念嵌入,以预测输出概念。
第二步202,对模型进行训练。本模型的基本数据源取自知识图谱中的医学系统命名法——临床术语(SNOMED-CT)和输入-输出数值,而后者包括大量文本和注释概念,分别取自ShARe/CLEF或者Synthetic。其中,SNOMED包括有疾病、症状和其它医学发现在内的共182,719个概念的子集。而输入-输出数值为合成数据集,包括美国MIMIC-III(重症监护医疗信息中心)的ICU医生搜集的约50,000例医疗记录。每种模型的训练约需8-12小时。
第三步203,采用基于规则的算法,应用一系列复杂的形态和句法的转换如词根提取、后缀替换、首字母缩写词扩展等,准确识别医疗记录的spans,并加注标签,形成相关概念的大数据集。
第四步204,按前面步骤的结果进行概念连接。
如图1为本发明的模型结构图,该模型分成三个主要部分:span编码器101、 概念编码器102和解码器(103和104)。输入模型的是医疗诊断文本的span,标签是代表遍历的分层概念表(由根概念起,到实际概念止)。
span编码器101:这是一个2层256单位的长短时记忆编码器,输入的span用词向量(由GloVe预训练)表示,产生256维的元素嵌入es,该输出对应于上一时间步的隐状态。
设xt代表词向量输入的序列。
h1,t=GRU1(xt,h1,t-1)
h2,t=GRU2(h1,t,h2,t-1)
es=[h1,T,h2,T]T
概念编码器102:该编码器通过平均每一概念的4-grams嵌入(此4-grams嵌入为随机初始化),产生一个256维的嵌入ec,然后将这些向量叠加为矩阵Ec。
设一个概念的ngrams(型)标注为n1到nk,则:
eci=mean(ni1,ni2,…nik)
Ec=[ec1,ec2,…]T
解码器(103和104):本申请设计了两种可能的解码器,用于读取span和概念嵌入,以预测输出概念。这两种解码器都采用了抽样的叉熵损失函数(扁平解码器使用0-1叉熵,序列解码器使用多级叉熵)总结训练样本,在序列解码器的场合,还需平均各个时间步的均值。需要注意的是,每次使用的时候只需用一种解码器。
扁平解码器104简单地取每个span(转换为256维后)和概念嵌入的点积,并将其代入sigmoid函数,产生每个概念的或然率。
Es,proj=Wprojes
在此解码器中,标签是一个沿遍历对应于各概念位置的稀疏向量。
序列解码器103是在解码时运行一个2层256单位的长短时记忆编码器,产生对应于遍历的概念序列。每一层的隐状态是由编码器中各层的最终隐状态初始化的。
h0=es
h1,t=GRU1(xt,h1,t-1)
h2,t=GRU2(h1,t,h2,t-1)
这里,m是沿遍历对应于有效子集位置含有1的掩码。
本申请采用了门控性单位(GRU)——特定形式的包含结构修改以减少消失的梯度问题的循环神经网络。GRU的正向传播方程是:
初态:h0=0
门:
输出:ct=tanh(Wxt+rt⊙Uht-1)
ht=zt⊙ht-1+(1-zt)⊙ct
此处,X1,……Xt是输入序列,⊙表示元素相乘。
本申请模型的基本数据源取自知识图谱中的医学系统命名法——临床术语(SNOMED-CT)和输入-输出数值,而后者包括大量文本和注释概念,分别取自ShARe/CLEF或者Synthetic。
使用的SNOMED中包括有疾病、症状和其它医学发现在内的共182,719个概念的子集。为去除SNOMED数据库可用性组的继承结构,选择带有大部分叶子节点的节点。
输入-输出数值为合成数据集,包括美国MIMIC-III(重症监护医疗信息中心)的ICU医生搜集的约50,000例医疗记录,由麻省理工学院计算生理学 实验室提供。这些记录是原始文本,无注释和概念标签。与之相对应的是ShARe/CLEF数据组,包含spans和人为标签的注释。本申请对UMLS(统一医学语言系统)词表的同义词集应用了扩展规则,包括插入停用词、后缀转换(如“dilated”转换为“dilation”)、词序颠倒等,得到了大约80,000个带标签的独特spans。
本发明的实验效果:本申请的模型在谷歌人工智能系统Tensorflow上完成,并在装有NVIDIAGTX 970显卡和4GB内存的计算机上接受训练。训练每个模型约需8-12小时。
本申请对两种模型(扁平解码器、序列解码器)执行四种不同任务进行评估:
1、合成数据组:这一评估在训练的700,000个spans中,测试了300,000个。
2、ShARe/CLEF:这一评估共有199个训练文本,99个测试文本。训练组包含5,816个spans,测试组包含5,351个spans。
3、ShARe/CLEF新概念:这一评估基于对训练组之外的ShARe/CLEF概念进行测试。
4、ShARe/CLEF新概念(Relax):这一评估测度新概念的表现。
每种评估的结果显示在表1中。
表1:两种模型在每项评价任务中的精确率/召回率/F1得分
实验结果表明,两种循环神经网络模型在处理合成数据组时,有着较高的精确率和召回率,达到了预期的效果,在大型数据库的概念连接方面潜力无限。序列解码器在处理ShARe/CLEF数据组时表现糟糕,主要原因是它的任务难得多(它必须依序预测遍历),更重要的是,当下的概念嵌入缺乏与层次相关的信 息。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!