基于泊松‑伽玛置信网络主题模型的文本分析方法与流程
本发明属于自然语言处理技术领域,更进一步涉及自然语言处理技术领域中的一种基于泊松-伽玛置信网络PGBN(Poisson Gamma Belief Network)主题模型的文本分析方法。本发明可用于对各类电子类文本进行主题提取、分类和新文本的生成。
背景技术:
目前,主题模型在自然语言处理领域受到越来越多的关注,同时被广泛应用于实际生活中,如对各类电子类文本进行主题提取、分类和新文本的生成等。随着互联网架构、存储科技以及其他有关技术的发展,各种各样的网络数据飞速增长,使得高效利用这些大规模数据进行文本分析具有很大的挑战。
和传统的基于统计的一些文本归纳方法相比,主题模型在可观测的文档层和单词层间增加了一个隐含的主题层,并认为文档包含一个或若干多个主题,每个主题又是不同比例单词的组合。这一新增加的主题隐含层能表征一篇文档所蕴含的语义内容,而且对海量数据通过主题进行表达而达到降维效果。
中国科学技术大学在其申请的专利“文本分类方法”(专利申请号200910142286.6,公开号CN101587493B)中公开了一种基于LDA主题模型对文本的分类方法。该方法实现的具体步骤是,首先,根据类别将初始训练文本集划分为多个子集,并从每个子集中抽去对应的概率主题模型,其中每个子集包含相同类别的文本;其次,利用对应的概率主题模型生成新的文本来均衡所述多个子集的类别;然后,根据所述多个子集对应的均衡训练文本集构造分类器;最后,利用所述分类器进行文本分类。该专利申请所公开的方法,虽然在传统文本分类方法的基础上改善了数据倾斜的问题,提高了文本的分类正确率,但是,该方法仍然存在的不足之处是,由于该方法只能提取单层主题信息,无法对多层的主题信息进行提取,所以在表达文本所蕴含的语义内容方面无法得到令人满意的结果。
贾会玲、吴晟、李英娜、李萌萌、杨玺、李川在其发表的论文“基于PLSA模型的观点句聚类算法研究”(Value Engineering,1006-4311(2015)31-0167-03)提出一种基于PLSA模型针对互联网评论文本中观点句聚类的算法。该方法实现的具体步骤是,首先,对观点句集合做分词和词性标注处理,并过滤掉与评价对象相关但不是聚类方面的高频词,得到相应的词集;其次,利用所得词集,建立词-观点句矩阵,并利用SVD对矩阵进行降维处理;然后,利用PLSA对降维后的矩阵进行处理,得到观点句-潜在变量概率矩阵;最后,计算观点句相似度,并将相似度最大的归为一类,输出观点句聚类结果。虽然,PLSA主题模型对其原始模型进行了完善,文本聚类效果得到了显著提高,但是,该方法仍然存在的不足之处是,如果训练数据存在噪音或者训练数据太少会出现过拟合现象。
技术实现要素:
本发明针对上述内容所公开的方法的不足,提出基于泊松-伽玛置信网络主题模型的文本分析方法,有效地避开了过拟合现象,完成文本内容多层主题信息的提取,并实现较高的文本分类正确率。
实现本发明目的的具体思路是,本发明的泊松-伽玛置信网络属于贝叶斯网络中的一种,本发明采用逐层训练和联合训练的方法对泊松-伽玛置信网络进行训练,利用吉布斯采样方法对网络参数进行学习,从而获得多层字典矩阵,完成对文本内容的多层主题信息的提取。
为实现本发明目的的具体步骤包括如下:
(1)建立训练集和测试集:
(1a)从文本语料库中随机选取训练文本集和测试文本集;
(1b)采用词袋方法,将训练文本集和测试文本集的格式由文本信息转化为数字信息的训练集和测试集;
(2)设置泊松-伽玛置信网络及其参数:
(2a)设置泊松-伽玛置信网络的总网络层数、输入层维度、隐层维度、输出层内容;
(2b)设置泊松-伽玛置信网络的网络参数;
(2c)在{1000,1500}两个值中任意选取一个值作为训练迭代次数;
(2d)将测试迭代次数设置为1500次;
(3)对泊松-伽玛置信网络进行分层:
(3a)将泊松-伽玛置信网络的第1层作为第1个子网络;
(3b)将泊松-伽玛置信网络的第1层和第2层,作为第2个子网络;
(3c)将泊松-伽玛置信网络的第1层、第2层和第3层,作为第3个子网络;
(3d)将泊松-伽玛置信网络的第1层、第2层、第3层和第4层,作为第4个子网络;
(3e)将泊松-伽玛置信网络的第1层、第2层、第3层、第4层和第5层,作为第5个子网络;
(4)对第1个子网络的参数进行初始化;
(4a)按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化;
φa(1)~Dir(η(1),....,η(1))
其中,φa(1)表示第1个子网络第1层初始化后的字典矩阵第a列的所有元素,a的取值范围是{1,2,....,K1max},K1max表示所有子网络第一个隐层维度的最大值,~表示等价关系符号,Dir表示狄利克雷分布,η(1)表示第1个子网络第1层狄利克雷分布的参数;
(4b)按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的概率分布对应参数和超参数进行初始化;
pi(1)=1-e-1
其中,pi(1)表示第1个子网络初始化后的第1层中服从负二项式分布的第i个样本的参数;
rm~Gamma(γ0/K1max,1/c0)
其中,rm表示第1个子网络初始化后的顶层生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,K1max表示所有子网络第一个隐层维度的最大值,γ0/K1max表示伽玛分布的形状参数,c0=1,表示伽玛分布尺度参数的倒数;
(4c)按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化;
其中,θh(1)表示第1个子网络初始化后的第1层隐层单元矩阵第h列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,pi(1)表示第1层中服从负二项式分布的第i个样本的参数,h与i的大小相等;
(5)判断当前子网络的网络层数是否为2,若是,则执行步骤(6),否则,执行步骤(7);
(6)对第2个子网络的参数进行初始化:
(6a)将第1个子网络中的全局参数值,作为第2个子网络全局参数的初始值;
(6b)按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化;
φb(T)~Dir(τ(T),....,τ(T))
其中,φb(T)表示第2个子网络顶层初始化后的字典矩阵第b列的所有元素,b的取值范围是{1,2,....,KT},KT表示第2个子网络顶层的维度值,~表示等价关系符号,Dir表示狄利克雷分布,τ(T)表示第2个子网络第T层狄利克雷分布参数的初始值;
(6c)按照下式,对第2个子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行初始化;
pc(2)~Beta(a0,b0)
其中,pc(2)表示第2个子网络初始化后的第2层中服从负二项式分布的第c个样本的参数,~表示等价关系符号,Beta表示贝塔分布,a0表示贝塔分布的参数1,a0=0.01,b0表示贝塔分布的参数2,b0=0.01;
cd(2)=(1-pc(2))/pc(2)
其中,cd(2)表示第2个子网络初始化后的第2层伽玛分布尺度参数的倒数,d表示输入数据中的第d个样本,pc(2)表示第2个子网络的第2层中服从负二项式分布的第c个样本的参数,d与c的大小相等;
ce(3)~Gamma(e0,1/f0)
其中,ce(3)表示第2个子网络的下一个子网络的第3层初始化后的伽玛分布尺度参数的倒数值,e表示输入数据中的第e个样本,~表示等价关系符号,Gamma表示伽玛分布,e0表示伽玛分布的形状参数,e0=1,f0表示伽玛分布尺度参数的倒数值,f0=1;
(6d)按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的生成向量进行初始化;
rm~Gamma(γ0/KT,1/c0)
其中,rm表示第2个子网络初始化后的顶层生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,KT表示顶层的维度值,c0表示伽玛分布尺度参数的倒数值,c0=1;
(6e)按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化;
其中,θg(2)表示第2个子网络顶层初始化后的隐层单元矩阵第g列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,表示第2个子网络的下一个子网络的第3层伽玛分布的尺度参数,e表示输入数据中的第e个样本,g与e的大小相等;
(6f)按照下式,对第2个子网络第1层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化;
其中,θh(1)表示第2个子网络第1层初始化后的隐层单元矩阵第h列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,Φ(2)θg(2)表示第2个子网络的第2层伽玛分布的形状参数,Φ(2)表示第2个子网络的第2层字典矩阵,θg(2)表示第2个子网络的第2层隐层单元矩阵第g列的所有元素,表示第2个子网络的第2层伽玛分布的尺度参数,d表示输入数据中的第d个样本,h、g与d的大小相等;
(7)对当前子网络的参数进行初始化:
(7a)将上一个子网络中的全局参数值,作为当前子网络全局参数的初始值;
(7b)对当前子网络顶层的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化;
φW(T)~Dir(ι(T),....,ι(T))
其中,φW(T)表示当前子网络顶层初始化后的字典矩阵第W列的所有元素,W的取值范围是{1,2,....,KT},KT表示顶层的维度值,~表示等价关系符号,Dir表示狄利克雷分布,ι(T)表示当前子网络顶层的狄利克雷分布参数;
(7c)按照下式,对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行初始化;
pr(T)=-ln(1-py(T-1))/[cu(T)-ln(1-py(T-1))]
其中,pr(T)表示当前子网络顶层初始化后服从负二项式分布的第r个样本的参数,ln表示对数符号,py(T-1)表示上一个子网络的顶层中服从负二项式分布的第y个样本的参数,cu(T)表示当前子网络顶层伽玛分布尺度参数的倒数值,u表示输入数据中的第u个样本,r、y与u的大小相等;
cl(T+1)~Gamma(e0,1/f0)
其中,cl(T+1)表示当前子网络的下一个子网络的顶层伽玛分布尺度参数的倒数值,l表示输入数据中的第l个样本,~表示等价关系符号,Gamma表示伽玛分布,e0表示伽玛分布的形状参数,e0=1,f0表示伽玛分布尺度参数的倒数值,f0=1;
(7d)按照下式,对当前子网络顶层的泊松-伽玛置信网络参数中所包含的生成向量进行初始化;
rm~Gamma(γ0/KT,1/c0)
其中,rm表示当前子网络顶层初始化后的生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,KT表示顶层的维度值,c0表示伽玛分布尺度参数的倒数值,c0=1;
(7e)按照下式,对当前子网络顶层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化;
其中,θo(T)表示当前子网络顶层初始化后的隐层单元矩阵第o列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,表示第T+1层伽玛分布的尺度参数,l表示输入数据中的第l个样本,o与l的大小相等;
(7f)按照下式,对当前子网络除顶层以外每一层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化;
其中,θj(t)表示当前子网络第t层初始化后的隐层单元矩阵第j列的所有元素,t的取值范围是{T-1,....,2,1},T表示当前子网络的层数,~表示等价关系符号,Gamma表示伽玛分布,Φ(t+1)θw(t+1)表示当前子网络的第t+1层伽玛分布的形状参数,Φ(t+1)表示当前子网络的第t+1层字典矩阵,θw(t+1)表示当前子网络的第t+1层隐层单元矩阵第w列的所有元素,w表示输入数据中的第w个样本,表示第t+1层伽玛分布的尺度参数,x表示输入数据中的第x个样本,j、w与x的大小相等;
(8)训练当前子网络:
(8a)按照从底层到顶层的顺序,对当前子网络每一层的泊松-伽玛置信网络参数中所包含的对应参数和全局参数字典矩阵进行更新;
(8b)将当前子网络的顶层作为当前训练层,对泊松-伽玛置信网络参数中所包含的对应参数、全局参数生成向量和隐层单元矩阵进行更新;
(8c)将当前子网络的第T-1层、第T-2层直到第一层依次作为当前训练层;
(8d)对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新;
(8e)对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行更新;
(9)判断当前子网络的训练次数是否等于训练迭代次数,若是,则执行步骤(10),否则,执行步骤(8);
(10)将训练后的当前子网络的字典矩阵和生成向量等全局参数保存在Matlab工作空间中,并作为当前子网络的全局参数;
(11)测试当前子网络:
(11a)将带有标号的训练集和测试集一起作为当前子网络的输入数据;
(11b)将当前子网络的顶层作为当前训练层,对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新;
(11c)将当前子网络的第T-1层、第T-2层直到第一层依次作为当前训练层;
(11d)对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新;
(12)判断当前子网络的测试次数是否等于测试迭代次数,若是,执行步骤(13),否则,执行步骤(11);
(13)对文本进行分类;
(13a)利用带有标号的训练集和更新后的隐层单元矩阵和参数,对支持向量机SVM分类器进行训练;
(13b)支持向量机SVM分类器对测试集进行分类,输出预测的文本类别;
(13c)比较测试集的预测文本类别和标准文本类别,输出当前子网络的文本分类正确率;
(14)判断当前子网络的网络层数是否为5,若是,则执行步骤(15),否则,将下一个子网络作为当前子网络,执行步骤(5);
(15)输出文本分类正确率和预测文本类别:
(15a)从五个子网络的文本分类正确率中选取最大的文本分类正确率;
(15b)输出最大的文本分类正确率及其与该正确率对应的子网络的预测文本类别。
本发明与现有的技术相比具有以下优点:
第1,由于本发明属于贝叶斯网络,并且将字典矩阵的先验分布设置为狄利克雷分布,将隐层单元矩阵的先验分布设置为伽玛分布,克服了现有技术中由于训练样本存在噪音或者训练样本太少,无法对网络参数进行全面学习而造成的过拟合问题,本发明削弱了网络的参数学习对训练样本的依赖性,使得参数学习不再受到训练样本数量的限制。
第2,由于本发明是多层主题模型,通过对模型进行训练,获得多层字典矩阵,提取到了文本内容的多层主题信息,克服了现有技术中只能对文本内容的单层主题信息进行提取的问题。本发明中提取的多层主题信息对文本所蕴含的语义内容表达效果更好,使得文本分类正确率高于其他主题模型,并在以困惑度为评价指标方面,也具有明显优势。
附图说明
图1是本发明的流程图;
图2是使用本发明对20个新闻组20newsgroups数据库进行文本分类的仿真图;
图3是使用本发明对非监督特征学习能力测评的仿真图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照附图1,对本发明的具体步骤描述如下。
步骤1,建立训练集和测试集。
从文本语料库中随机选取训练文本集和测试文本集。
采用词袋方法,将训练文本集和测试文本集的格式由文本信息转化为数字信息的训练集和测试集。
步骤2,设置泊松-伽玛置信网络及其参数。
设置泊松-伽玛置信网络的总网络层数、输入层维度、隐层维度、输出层内容。
所述的泊松-伽玛置信网络的总网络层数、输入层维度、隐层维度、输出层内容设置如下:总网络层数为5层,输入层的维度值与文本语料库对应的词表维度值相等,在{50,100,200,400,600,800}六个值中任意选取一个值作为所有子网络第一层隐层维度的最大值,并且所有子网络中第一层隐层维度为其他层隐层维度的上限;输出层输出文本分类正确率和预测文本类别。
设置泊松-伽玛置信网络的网络参数。
所述设置的泊松-伽玛置信网络的网络参数包括:输入数据、先验分布为狄利克雷分布的全局参数字典矩阵、先验分布为伽玛分布的隐层单元矩阵、生成向量、层内增广矩阵和层间增广矩阵以及涉及到的概率分布对应的参数和超参数。
在{1000,1500}两个值中任意选取一个值作为训练迭代次数。
将测试迭代次数设置为1500次。
步骤3,对泊松-伽玛置信网络进行分层。
将泊松-伽玛置信网络的第1层作为第1个子网络。
将泊松-伽玛置信网络的第1层和第2层,作为第2个子网络。
将泊松-伽玛置信网络的第1层、第2层和第3层,作为第3个子网络。
将泊松-伽玛置信网络的第1层、第2层、第3层和第4层,作为第4个子网络。
将泊松-伽玛置信网络的第1层、第2层、第3层、第4层和第5层,作为第5个子网络。
步骤4,对第1个子网络的参数进行初始化。
按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化。
φa(1)~Dir(η(1),....,η(1))
其中,φa(1)表示第1个子网络第1层初始化后的字典矩阵第a列的所有元素,a的取值范围是{1,2,....,K1max},K1max表示所有子网络第一个隐层维度的最大值,~表示等价关系符号,Dir表示狄利克雷分布,η(1)表示第1个子网络第1层狄利克雷分布的参数。
按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的概率分布对应参数和超参数进行初始化。
pi(1)=1-e-1
其中,pi(1)表示第1个子网络初始化后的第1层中服从负二项式分布的第i个样本的参数。
rm~Gamma(γ0/K1max,1/c0)
其中,rm表示第1个子网络初始化后的顶层生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,K1max表示所有子网络第一个隐层维度的最大值,γ0/K1max表示伽玛分布的形状参数,c0=1,表示伽玛分布尺度参数的倒数。
按照下式,对第1个子网络的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化。
其中,θh(1)表示第1个子网络初始化后的第1层隐层单元矩阵第h列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,pi(1)表示第1层中服从负二项式分布的第i个样本的参数,h与i的大小相等。
步骤5,判断当前子网络的网络层数是否为2,若是,则执行步骤6,否则,执行步骤7。
步骤6,对第2个子网络的参数进行初始化。
将第1个子网络中的全局参数值,作为第2个子网络全局参数的初始值。
按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化。
φb(T)~Dir(τ(T),....,τ(T))
其中,φb(T)表示第2个子网络顶层初始化后的字典矩阵第b列的所有元素,b的取值范围是{1,2,....,KT},KT表示第2个子网络顶层的维度值,~表示等价关系符号,Dir表示狄利克雷分布,τ(T)表示第2个子网络第T层狄利克雷分布参数的初始值。
按照下式,对第2个子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行初始化。
pc(2)~Beta(a0,b0)
其中,pc(2)表示第2个子网络初始化后的第2层中服从负二项式分布的第c个样本的参数,~表示等价关系符号,Beta表示贝塔分布,a0表示贝塔分布的参数1,a0=0.01,b0表示贝塔分布的参数2,b0=0.01。
cd(2)=(1-pc(2))/pc(2)
其中,cd(2)表示第2个子网络初始化后的第2层伽玛分布尺度参数的倒数,d表示输入数据中的第d个样本,pc(2)表示第2个子网络的第2层中服从负二项式分布的第c个样本的参数,d与c的大小相等。
ce(3)~Gamma(e0,1/f0)
其中,ce(3)表示第2个子网络的下一个子网络的第3层初始化后的伽玛分布尺度参数的倒数值,e表示输入数据中的第e个样本,~表示等价关系符号,Gamma表示伽玛分布,e0表示伽玛分布的形状参数,e0=1,f0表示伽玛分布尺度参数的倒数值,f0=1。
按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的生成向量进行初始化。
rm~Gamma(γ0/KT,1/c0)
其中,rm表示第2个子网络初始化后的顶层生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,KT表示顶层的维度值,c0表示伽玛分布尺度参数的倒数值,c0=1。
按照下式,对第2个子网络顶层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化。
其中,θg(2)表示第2个子网络顶层初始化后的隐层单元矩阵第g列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,表示第2个子网络的下一个子网络的第3层伽玛分布的尺度参数,e表示输入数据中的第e个样本,g与e的大小相等。
按照下式,对第2个子网络第1层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化。
其中,θh(1)表示第2个子网络第1层初始化后的隐层单元矩阵第h列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,Φ(2)θg(2)表示第2个子网络的第2层伽玛分布的形状参数,Φ(2)表示第2个子网络的第2层字典矩阵,θg(2)表示第2个子网络的第2层隐层单元矩阵第g列的所有元素,表示第2个子网络的第2层伽玛分布的尺度参数,d表示输入数据中的第d个样本,h、g与d的大小相等。
步骤7,对当前子网络的参数进行初始化。
将上一个子网络中的全局参数值,作为当前子网络全局参数的初始值。
对当前子网络顶层的泊松-伽玛置信网络参数中所包含的字典矩阵进行初始化。
φW(T)~Dir(ι(T),....,ι(T))
其中,φW(T)表示当前子网络顶层初始化后的字典矩阵第W列的所有元素,W的取值范围是{1,2,....,KT},KT表示顶层的维度值,~表示等价关系符号,Dir表示狄利克雷分布,ι(T)表示当前子网络顶层的狄利克雷分布参数。
按照下式,对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行初始化。
pr(T)=-ln(1-py(T-1))/[cu(T)-ln(1-py(T-1))]
其中,pr(T)表示当前子网络顶层初始化后服从负二项式分布的第r个样本的参数,ln表示对数符号,py(T-1)表示上一个子网络的顶层中服从负二项式分布的第y个样本的参数,cu(T)表示当前子网络顶层伽玛分布尺度参数的倒数值,u表示输入数据中的第u个样本,r、y与u的大小相等。
cl(T+1)~Gamma(e0,1/f0)
其中,cl(T+1)表示当前子网络的下一个子网络的顶层伽玛分布尺度参数的倒数值,l表示输入数据中的第l个样本,~表示等价关系符号,Gamma表示伽玛分布,e0表示伽玛分布的形状参数,e0=1,f0表示伽玛分布尺度参数的倒数值,f0=1。
按照下式,对当前子网络顶层的泊松-伽玛置信网络参数中所包含的生成向量进行初始化。
rm~Gamma(γ0/KT,1/c0)
其中,rm表示当前子网络顶层初始化后的生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,KT表示顶层的维度值,c0表示伽玛分布尺度参数的倒数值,c0=1。
按照下式,对当前子网络顶层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化。
其中,θo(T)表示当前子网络顶层初始化后的隐层单元矩阵第o列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,表示第T+1层伽玛分布的尺度参数,l表示输入数据中的第l个样本,o与l的大小相等。
按照下式,对当前子网络除顶层以外每一层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行初始化。
其中,θj(t)表示当前子网络第t层初始化后的隐层单元矩阵第j列的所有元素,t的取值范围是{T-1,....,2,1},T表示当前子网络的层数,~表示等价关系符号,Gamma表示伽玛分布,Φ(t+1)θw(t+1)表示当前子网络的第t+1层伽玛分布的形状参数,Φ(t+1)表示当前子网络的第t+1层字典矩阵,θw(t+1)表示当前子网络的第t+1层隐层单元矩阵第w列的所有元素,w表示输入数据中的第w个样本,表示第t+1层伽玛分布的尺度参数,x表示输入数据中的第x个样本,j、w与x的大小相等。
步骤8,训练当前子网络。
按照从底层到顶层的顺序,对当前子网络每一层的泊松-伽玛置信网络参数中所包含的对应参数和全局参数字典矩阵进行更新。
所述对当前子网络每一层的泊松-伽玛置信网络参数中所包含的对应参数和全局参数字典矩阵进行更新的具体步骤如下。
第1步,将当前子网络的第一层、第二层直到顶层依次作为当前训练层。
第2步,按照下式,对当前训练层的泊松-伽玛置信网络参数中所包含的层内增广矩阵,针对当前训练层的维度进行多项式采样。
其中,{xvn1(t),xvn2(t),....,xvnKt(t)}表示对xvn(t)针对当前子网络的当前训练层的维度进行多项式采样的结果,每一个都是维度为V*N的矩阵,V表示当前子网络的当前训练层输入数据矩阵的维度值,N表示样本个数,v的取值范围是{1,2,....,Kt-1},Kt-1表示当前子网络的第t-1层隐层的维度值,n表示输入数据中的第n个样本,Kt表示当前子网络的当前训练层的维度值,v与n固定时,{xvn1(t),xvn2(t),....,xvnKt(t)}分别对应一个元素,xvn(t)表示当前子网络的当前训练层的层内增广矩阵,φs:(t)表示{φs1(t),φs2(t),....,φsKt(t)},s的取值范围是{1,2,....,Kt-1},{φs1(t),φs2(t),....,φsk(t),....,φsKt(t)}分别表示当前训练层字典矩阵第1,2,....,k,....,Kt列的所有元素,θj(t)表示当前子网络的当前训练层隐层单元矩阵第j列的所有元素,~表示等价关系符号,Mult表示多项式分布,{θ1j(t),θ2j(t),....,θkj(t),....,θKtj(t)}分别表示当前训练层隐层单元矩阵第1,2,....,k,....,Kt行的所有元素,v与s的大小相等,n与j的大小相等。
第3步,按照下式,根据层间增广矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的层间增广矩阵进行更新。
其中,mpf(t)(t+1)表示当前子网络的第t层层内增广矩阵与第t+1层层内增广矩阵之间的关系,p的取值范围是{1,2,....,Kt},Kt表示当前子网络的第t层隐层的维度值,f表示输入数据中的第f个样本,Kt-1表示当前子网络的第t-1层隐层的维度值,xvzn(t)表示第2步采样结果中对应的元素,p与z的大小相等,f与n的大小相等。
第4步,按照下式,根据层内增广矩阵的后验概率,对当前训练层下一层的泊松-伽玛置信网络参数中所包含的层内增广矩阵进行更新。
(xJI(t+1)|mpf(t)(t+1),φS:(t+1),θw(t+1))~CRT(mpf(t)(t+1),φS:(t+1),θw(t+1))
其中,xJI(t+1)表示当前子网络第t+1层的层内增广矩阵,J的取值范围是{1,2,....,Kt+1},Kt+1表示当前子网络的第t+1层隐层的维度值,I表示输入数据中的第I个样本,mpf(t)(t+1)表示当前子网络的第t层层内增广矩阵与第t+1层层内增广矩阵之间的关系,p的取值范围是{1,2,....,Kt},Kt表示当前子网络的第t层隐层的维度值,f表示第f个样本,φS:(t+1)表示{φS1(t+1),φS2(t+1),....,φSKt(t+1)},S的取值范围是{1,2,....,Kt},{φS1(t+1),φS2(t+1),....,φSKt(t+1)}分别表示当前子网络的第t+1层字典矩阵第1,2,....,Kt列的所有元素,θw(t+1)表示当前子网络的第t+1层隐层单元矩阵第w列的所有元素,CRT表示中国餐馆过程中的最大餐桌分布,J、p与S的大小相等,I、f与w的大小相等。
第5步,按照下式,根据字典矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的字典矩阵进行更新。
P(φZ(t)|-)~Dir(λ(t)+x1.z(t),λ(t)+x2.z(t),....,λ(t)+xKt-1.z(t))
其中,φZ(t)表示当前子网络的当前训练层更新后的字典矩阵第Z列的所有元素,~表示等价关系符号,Dir表示狄利克雷分布,λ(t)表示当前子网络的当前训练层狄利克雷的分布参数,x1nz(t),x2nz(t),....,xKt-1nz(t)分别对应第2步采样结果中的元素,Kt-1表示当前子网络的第t-1层隐层的维度值,Z与z的大小相等。
将当前子网络的顶层作为当前训练层,对泊松-伽玛置信网络参数中所包含的对应参数、全局参数生成向量和隐层单元矩阵进行更新。
所述对泊松-伽玛置信网络参数中所包含的对应参数、全局参数生成向量和隐层单元矩阵进行更新的具体步骤如下。
第1步,按照下式,根据层内增广矩阵的后验概率,对第T+1层的泊松-伽玛置信网络参数中所包含的层内增广矩阵进行更新。
(xHG(T+1)|mPF(T)(T+1),r)~CRT(mPF(T)(T+1),r)
其中,xHG(T+1)表示当前子网络第T+1层的层内增广矩阵,H的取值范围是{1,2,....,KT+1},KT+1表示当前子网络的第T+1层隐层的维度值,G表示输入数据中的第G个样本,mPF(T)(T+1)表示当前子网络的第T层层内增广矩阵与第T+1层层内增广矩阵之间的关系,P的取值范围是{1,2,....,KT},KT表示顶层的维度值,F表示第F个样本,r表示顶层的生成向量,CRT表示中国餐馆过程中的最大餐桌分布,H与P的大小相等,G与F的大小相等。
第2步,按照下式,根据生成向量的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的生成向量进行更新。
其中,rm表示当前子网络的当前训练层更新后的生成向量的第m个元素,~表示等价关系符号,Gamma表示伽玛分布,γ0=1,KT表示当前子网络顶层的维度值,xL.(T+1)表示当前子网络第T+1层的层内增广矩阵针对第T+1层隐层维度求和的结果,L表示当前子网络顶层的维度值,c0=1,ln表示对数符号,pR(T+1)表示第T+1层中服从负二项式分布的第R个样本的参数,m与L的大小相等。
第3步,按照下式,根据参数的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的对应的参数进行更新。
P(cl(T+1)|-)~Gamma(e0+r.,[f0+θ.o(T)]-1)
其中,cl(T+1)表示当前子网络的第T+1层更新后的伽玛分布尺度参数的倒数值,l表示输入数据中的第l个样本,~表示等价关系符号,Gamma表示伽玛分布,e0=1,r.表示顶层的生成向量针对顶层维度求和的结果,f0=1,KT表示当前子网络顶层隐层的维度值,θDo(T)表示当前子网络的顶层隐层单元矩阵的第D行、第o列元素,l与o的大小相等。
其中,pr(T)表示当前子网络顶层更新后的服从负二项式分布的第r个样本的参数,py(T-1)表示当前子网络的第T-1层中服从负二项式分布的第y个样本的参数,cu(T)表示当前子网络顶层的伽玛分布尺度参数的倒数值,u表示输入数据中的第u个样本,r、y与u的大小相等。
第4步,按照下式,根据隐层单元矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行更新。
P(θo(T)|-)~Gamma(r+mF(T)(T+1),[cl(T+1)-ln(1-pr(T))]-1)
其中,θo(T)表示当前子网络顶层更新后的隐层单元矩阵第o列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,mF(T)(T+1)表示当前子网络的第T层层内增广矩阵与第T+1层层内增广矩阵之间的关系,F表示输入数据中的第F个样本,cl(T+1)表示当前子网络的第T+1层伽玛分布尺度参数的倒数值,l表示第l个样本,pr(T)表示当前子网络的第T层中服从负二项式分布的第r个样本的参数,o、F、l与r的大小相等。
将当前子网络的第T-1层、第T-2层直到第一层依次作为当前训练层。
对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新。
所述对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新的具体步骤如下。
第1步,按照下式,根据参数的后验概率,对当前训练层上一层中对当前训练层具有影响的泊松-伽玛置信网络参数中所包含的参数进行更新。
P(cx(t+1)|-)~Gamma(e0+θ.w(t+1),[f0+θ.j(t)]-1)
其中,cx(t+1)表示当前子网络的当前训练层的上一层更新后的伽玛分布尺度参数的倒数值,x表示输入数据中的第x个样本,~表示等价关系符号,Gamma表示伽玛分布,e0=1,θ.w(t+1)表示当前子网络的第t+1层隐层单元矩阵针对第t+1层隐层维度求和的结果,w表示第w个样本,f0=1,θ.j(t)表示当前子网络的第t层隐层单元矩阵针对第t层隐层维度求和的结果,j表示第j个样本,x、w与j的大小相等。
第2步,按照下式,对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数进行更新。
其中,pA(t)表示当前子网络的当前训练层更新后的服从负二项式分布的第A个样本的参数,pB(t-1)表示当前子网络的第t-1层中服从负二项式分布的第B个样本的参数,cE(t)表示当前子网络的t层伽玛分布尺度参数的倒数,E表示输入数据中的第E个样本,A、B与E的大小相等。
第3步,按照下式,根据隐层单元矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行更新。
P(θj(t)|-)~Gamma(Φ(t+1)θw(t+1)+mf(t)(t+1),[cx(t+1)-ln(1-pA(t))]-1)
其中,θj(t)表示当前子网络的当前训练层更新后的隐层单元矩阵第j列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,Φ(t+1)表示当前子网络的第t+1层字典矩阵,θw(t+1)表示当前子网络的第t+1层隐层单元矩阵第w列的所有元素,mf(t)(t+1)表示当前子网络的第t层层内增广矩阵与第t+1层层内增广矩阵之间的关系,f表示输入数据中的第f个样本,cx(t+1)表示当前子网络的第t+1层伽玛分布尺度参数的倒数值,x表示第x个样本,pA(t)表示当前子网络的第t层中服从负二项式分布的第A个样本的参数,j、w、f、x与A的大小相等。
对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行更新。
所述对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行更新的具体步骤如下。
第1步,按照下式,根据参数的后验概率,对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数和超参数进行更新。
(pc(2)|-)~Beta(a0+m.Q(1)(2),b0+θ.g(2))
其中,pc(2)表示当前子网络第2层更新后的服从负二项式分布的第c个样本的参数,~表示等价关系符号,Beta表示贝塔分布,a0表示贝塔分布参数1的初始值,a0=0.01,Q表示输入数据中的第Q个样本,K0表示当前子网络输入层的维度值,xUO(1)表示当前子网络输入层的层内增广矩阵的第U行、第O列元素,b0表示贝塔分布参数2的初始值,b0=0.01,θ.g(2)表示当前子网络的第2层隐层单元矩阵针对第2层隐层维度求和的结果,g表示第g个样本,c、Q与g的大小相等。
第2步,按照下式,对当前子网络的泊松-伽玛置信网络参数中所包含的概率分布对应的参数进行更新。
cd(2)=(1-pc(2))/pc(2)
其中,cd(2)表示当前子网络第2层更新后的伽玛分布尺度参数的倒数值,d表示输入数据中的第d个样本,pc(2)表示当前子网络的第2层中服从负二项式分布的第c个样本的参数,d与c的大小相等。
步骤9,判断当前子网络的训练次数是否等于训练迭代次数,若是,则执行步骤10,否则,执行步骤8。
步骤10,将训练后的当前子网络的字典矩阵和生成向量等全局参数保存在Matlab工作空间中,并作为当前子网络的全局参数。
步骤11,测试当前子网络。
将带有标号的训练集和测试集一起作为当前子网络的输入数据。
将当前子网络的顶层作为当前训练层,对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新。
对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新的具体步骤如下。
第1步,按照下式,根据参数的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的对应的参数进行更新。
P(cl(T+1)|-)~Gamma(e0+r.,[f0+θ.o(T)]-1)
其中,cl(T+1)表示当前子网络的第T+1层更新后的伽玛分布尺度参数的倒数值,l表示输入数据中的第l个样本,~表示等价关系符号,Gamma表示伽玛分布,e0=1,r.表示顶层的生成向量针对顶层维度求和的结果,f0=1,KT表示当前子网络顶层的维度值,θDo(T)表示当前子网络顶层的隐层单元矩阵的第D行、第o列元素,l与o的大小相等。
其中,pr(T)表示当前子网络顶层更新后的服从负二项式分布的第r个样本的参数,py(T-1)表示当前子网络的第T-1层中服从负二项式分布的第y个样本的参数,cu(T)表示当前子网络顶层的伽玛分布尺度参数的倒数值,u表示输入数据中的第u个样本,r、y与u的大小相等。
第2步,按照下式,根据隐层单元矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行更新。
P(θo(T)|-)~Gamma(r+mF(T)(T+1),[cl(T+1)-ln(1-pr(T))]-1)
其中,θo(T)表示当前子网络顶层更新后的隐层单元矩阵第o列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,r表示顶层的生成向量,mF(T)(T+1)表示当前子网络的第T层层内增广矩阵与第T+1层层内增广矩阵之间的关系,F表示输入数据中的第F个样本,cl(T+1)表示当前子网络的第T+1层伽玛分布尺度参数的倒数值,l表示第l个样本,pr(T)表示当前子网络顶层中服从负二项式分布的第r个样本的参数,o、F、l与r的大小相等。
将当前子网络的第T-1层、第T-2层直到第一层依次作为当前训练层。
对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新。
对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数和隐层单元矩阵进行更新的具体步骤如下。
第1步,按照下式,根据参数的后验概率,对当前训练层的上一层中对当前训练层具有影响的泊松-伽玛置信网络参数中所包含的参数进行更新。
P(cx(t+1)|-)~Gamma(e0+θ.w(t+1),[f0+θ.j(t)]-1)
其中,cx(t+1)表示当前子网络的当前训练层的上一层更新后的伽玛分布尺度参数的倒数值,x表示输入数据中的第x个样本,~表示等价关系符号,Gamma表示伽玛分布,e0=1,θ.w(t+1)表示当前子网络的第t+1层隐层单元矩阵针对第t+1层隐层维度求和的结果,w表示第w个样本,f0=1,θ.j(t)表示当前子网络的第t层隐层单元矩阵针对第t层隐层维度求和的结果,j表示第j个样本,x、w与j的大小相等。
第2步,按照下式,对当前训练层的泊松-伽玛置信网络参数中所包含的对应参数进行更新。
其中,pA(t)表示当前子网络的当前训练层更新后的服从负二项式分布的第A个样本的参数,pB(t-1)表示当前子网络的第t-1层中服从负二项式分布的第B个样本的参数,cE(t)表示当前子网络的第t层伽玛分布尺度参数的倒数值,E表示输入数据中的第E个样本,A、B与E的大小相等。
第3步,按照下式,根据隐层单元矩阵的后验概率,对当前训练层的泊松-伽玛置信网络参数中所包含的隐层单元矩阵进行更新。
P(θj(t)|-)~Gamma(Φ(t+1)θw(t+1)+mf(t)(t+1),[cx(t+1)-ln(1-pA(t))]-1)
其中,θj(t)表示当前子网络的当前训练层更新后的隐层单元矩阵第j列的所有元素,~表示等价关系符号,Gamma表示伽玛分布,Φ(t+1)表示当前子网络的第t+1层字典矩阵,θw(t+1)表示当前子网络的第t+1层隐层单元矩阵第w列的所有元素,mf(t)(t+1)表示当前子网络的第t层层内增广矩阵与第t+1层层内增广矩阵之间的关系,f表示输入数据中的第f个样本,cx(t+1)表示当前子网络的第t+1层伽玛分布尺度参数的倒数值,x表示第x个样本,pA(t)表示当前子网络的第t层中服从负二项式分布的第A个样本的参数,j、w、f、x与A的大小相等。
步骤12,判断当前子网络的测试次数是否等于测试迭代次数,若是,执行步骤13,否则,执行步骤11。
步骤13,对文本进行分类。
利用带有标号的训练集和更新后的隐层单元矩阵和参数,对支持向量机SVM分类器进行训练。
支持向量机SVM分类器对测试集进行分类,输出预测的文本类别。
比较测试集的预测文本类别和标准文本类别,输出当前子网络的文本分类正确率。
步骤14,判断当前子网络的网络层数是否为5,若是,则执行步骤15,否则,将下一个子网络作为当前子网络,执行步骤5。
步骤15,输出文本分类正确率和预测文本类别。
从五个子网络的文本分类正确率中选取最大的文本分类正确率。
输出最大的文本分类正确率及其与该正确率对应的子网络的预测文本类别。
下面结合附图2,3,对本发明的效果做进一步说明。
1.仿真实验条件:
仿真实验1:
采用20个新闻组数据库(http://www.qwone.com/~jason/20Newsgroups/),该数据库共包含18,774篇文档,涉及20种不同类别的新闻组,对应的词表大小为61,188,其中11,269篇文档作为训练文本集,其余7,505篇文档作为测试文本集。
预处理:去除掉20个新闻组数据库对应词表中的停用词和出现频率低于5次的词,则词表大小变为33,420。根据该词表信息,采用词袋方法分别将训练文本集和测试文本集中的每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息,得到训练集和测试集。
仿真实验2:
采用神经信息处理系统会议文集数据库(http://www.cs.nyu.edu/~roweis/data.html),遍历该数据库,从每一类别中随机抽出30%的文档作为训练文本集,剩下70%的文档作为测试文本集。
预处理:将神经信息处理系统会议文集数据库对应词表中出现频率最高的前2000个词,作为该数据库的新词表,再根据新词表信息,采用词袋方法分别将训练文本集和测试文本集中的每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息,得到测试过程的训练集和测试集。
2.仿真内容及分析:
仿真1,用本发明对20个新闻组数据库进行分类,具体参数设置如表1所示。
表1仿真1的具体参数设置一览表
由于LDA主题模型在文本分析方面的性能相较于其他主题模型具有明显优势,经常被当作此领域模型性能的比较基准。而本发明的单层网络模型等价于泊松因子分析PFA模型,在文本分析方面的性能近似于LDA主题模型,所以本发明对文本的分类正确率只需要和自身的单层网络模型相比即可。
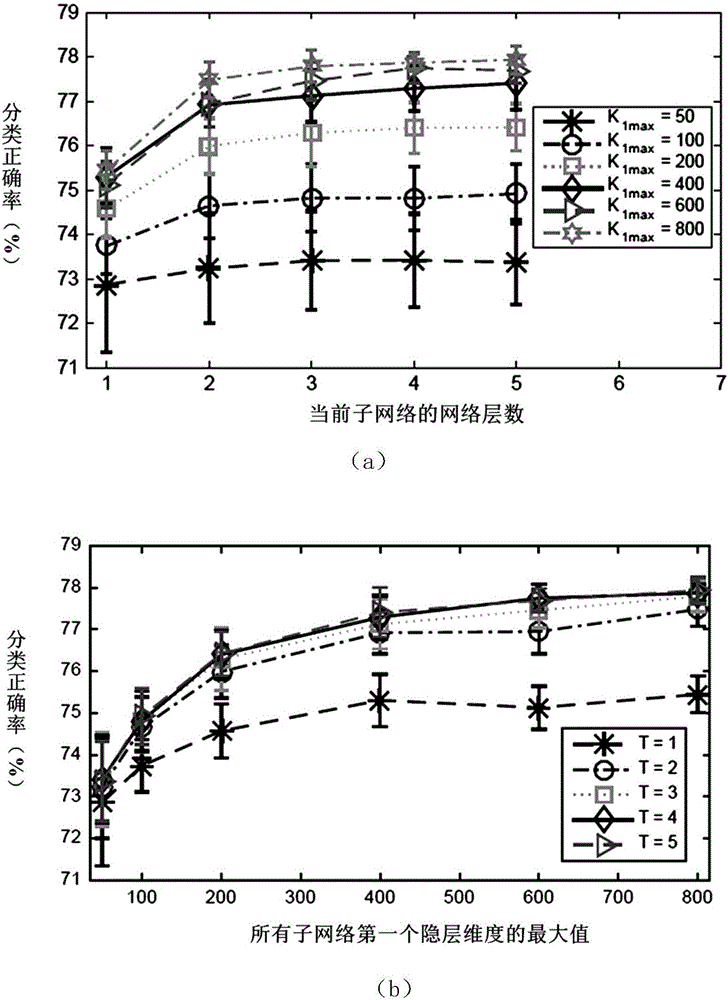
图2表示使用本发明对20个新闻组数据库进行文本分类,当前子网络的网络层数和泊松-伽玛置信网络的所有子网络第一个隐层维度的最大值对分类正确率的影响。
图2(a)表示当前子网络的网络层数对分类正确率的影响。图2(a)中的横坐标表示泊松-伽玛置信网络当前子网络的网络层数,纵坐标表示文本的分类正确率。以叉形标示的曲线表示所有子网络第一个隐层维度的最大值是50,以圆圈标示的曲线表示所有子网络第一个隐层维度的最大值是100,以方块标示的曲线表示所有子网络第一个隐层维度的最大值是200,以菱形标示的曲线表示所有子网络第一个隐层维度的最大值是400,以三角标示的曲线表示所有子网络第一个隐层维度的最大值是600,以六角星标示的曲线表示所有子网络第一个隐层维度的最大值是800。
图2(b)表示泊松-伽玛置信网络的所有子网络第一个隐层维度的最大值对分类正确率的影响,图2(b)中的横坐标表示泊松-伽玛置信网络的所有子网络第一个隐层维度的最大值,纵坐标表示文本的分类正确率。以叉形标示的曲线表示当前子网络的网络层数是1,以圆圈标示的曲线表示当前子网络的网络层数是2,以方块标示的曲线表示当前子网络的网络层数是3,以菱形标示的曲线表示当前子网络的网络层数是4,以三角标示的曲线表示当前子网络的网络层数是5。
从图2可见,本发明对20个新闻组数据库的分类正确率相较于现有技术有所提高。并且当当前子网络第一个隐层的维度最大值固定时,文本的分类正确率随着当前子网络的网络层数增加而增加。当当前子网络的网络层数固定时,文本的分类正确率随着当前子网络第一个隐层维度的最大值的增大而增加。特别地,当单层子网络第一个隐层的维度最大值固定为100时,在此子网络的基础上增加一层或多层泊松-伽玛置信网络所获得的新的子网络,基于该子网络文本的分类正确率略胜于第一个隐层的维度最大值固定为200的单层子网络。当单层子网络第一个隐层的维度最大值固定为200时,在此子网络的基础上增加一层或多层泊松-伽玛置信网络所获得的新的子网络,基于该子网络文本的分类正确率明显高于第一个隐层的维度最大值固定为800的单层子网络。
仿真2,基于神经信息处理系统会议文集数据库对本发明关于非监督特征学习的能力进行测评。
困惑度是衡量主题模型性能好坏的一种评价指标,其数值越小越好。模型具体参数设置如表2所示。
表2仿真2的具体参数设置一览表
图3表示使用本发明基于神经信息处理系统会议集数据库对非监督特征学习能力进行测评,所有子网络第一个隐层维度的最大值对困惑度的影响。
图3中的横坐标表示泊松-伽玛置信网络所有子网络第一个隐层维度的最大值,纵坐标表示该主题模型的困惑度。图3中以叉形标示的曲线表示当前子网络的网络层数是1,以圆圈标示的曲线表示当前子网络的网络层数是2,以方块标示的曲线表示当前子网络的网络层数是3,以菱形标示的曲线表示当前子网络的网络层数是4,以三角标示的曲线表示当前子网络的网络层数是5。
从图3可见,本发明在以困惑度为评价指标方面,相较于其他主题模型,拥有更好的性能。
综上所述,本发明与现有技术在文本分析方面的性能相比,不仅克服了现有技术中由于训练样本存在噪音或者训练样本太少,无法对网络参数进行全面学习而造成的过拟合问题,而且通过对泊松-伽玛置信网络进行训练,获得多层字典矩阵,从而能够提取文本内容的多层主题信息,更好地表达文本所蕴含的语义内容,提高了文本的分类正确率,并且在以困惑度为评价指标方面,相较于其他主题模型,具有明显优势。
- 还没有人留言评论。精彩留言会获得点赞!