一种企业名称的相似性检索方法与流程
本发明涉及相似性检索技术领域,尤其涉及一种企业名称的相似性检索方法。
背景技术:
数据库的精确查询速度是相当快的,但是模糊查询在数据量超过百万级以后,尤其是针对“包含”关系的查询速度会急速降低,通常都会超过10秒。例如:通过输入关键字“计算机”想要命中“长城计算机软件”速度上就会很慢。更何况按照判断名称近似的规则需要使用循环嵌套的模糊查询,性能完全无法接受。
通常遇到这种问题,会使用到“全文检索技术”,例如:百度、搜狗等,实现了根据少量关键字在海量数据中快速检索得到结果。但是,发明人在实施本分的过程中发现:通用的全文检索技术,仍然达不到名称近似检索要求,主要问题如下:
首先,一般的全文检索技术是以分词检索为基础的,即,首先将输入的检索串进行分词,然后将分词后的词组到分词索引库中进行检索,然后整合检索结果按命中度高低排序。但名称近似检索并不完全是以词为单位的,例如“支付宝”、“欧付宝”两个字串,如果分词进行检索,很可能会认为它们不相似。
其次,通用的全文检索引擎也可以支持按字检索的模式,但性能上的优势就没有了,例如:对于一个15字的名称字符串,按字全排列进行检索得到的结论是:仅仅通过“全文检索”也无法完全实现关于企业名称近似检索的业务需求,其检索时限会超过30秒,且检索结果的排序也不准确,与人们通常感觉的名称近似差异较大,远远无法满足业务需求。
技术实现要素:
本发明所要解决的技术问题是针对现有技术的不足,提供一种企业名称的相似性检索方法。
本发明解决上述技术问题的技术方案如下:一种企业名称的相似性检索方法,包括:
对输入的检索关键字进行分解处理,得到处理后的检索关键字,其中,所述检索关键字为待检索的企业名称;
根据处理后的所述检索关键字,确定检索词组;
对确定的所述检索词组进行相似性检索,得到检索结果;
显示所述检索结果中排在前N位的企业名称,以供用户查看,N取大于1整数。
本发明的有益效果是:通过对输入的检索关键字进行分解处理,得到处理后的检索关键字,并根据处理后的检索关键字,确定检索词组,再对确定的检索词组进行相似性检索,得到检索结果,最后显示检索结果中排在前N位的企业名称,以供用户查看,不仅可以使得检索效率大大的提高,而且方便用户查看相似性检索的结果,以及满足相似性检索业务的需求。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步地,所述对输入的检索关键字进行分段处理,得到处理后的检索关键字,包括:判断所述检索关键字中是否包含行政区划和组织形式企业类型的组成部分;
若不包含,则将所述检索关键字分解为企业字号和/或行业特点以作为处理后的检索关键字;否则,将所述检索关键字分解为行政区划、组织形式企业类型、企业字号和行业特点,并将企业字号和/或行业特点作为处理后的检索关键字。
进一步地,所述根据处理后的所述检索关键字,确定检索词组,包括:
将处理后的所述检索关键字按照分解处理之前的顺序排列;
将与所述检索关键字中M个字不同的词组确定为所述检索词组,M取0、1或2;或者,
将与所述检索关键字同义和/或同音的词组确定为所述检索词组;或者,
将与所述检索关键字中K个相同且相邻的字组成的词组确定为所述检索词组;或者,
将与所述检索关键字中Q个相同但分散的字组成的词组确定为所述检索词组。
采用上述进一步方案的有益效果是:通过将输入的检索关键字进行分解,去除行政区划和组织形式企业类型等通用信息,根据企业字号和/或行业特点确定检索词组,可以大大的减少检索式的数量,从而有效的提高了检索效率。
进一步地,所述对确定的所述检索词组进行相似性检索,得到检索结果,包括:判断所述检索词组的数量是否超过预设值;
若超过,则采用分布式多节点检索,并将每个节点得到的检索结果进行汇总,得到所述检索结果;否则,采用单节点检索,得到所述检索结果。
采用上述进一步方案的有益效果是:通过判断检索词组的数量,确定采用分布式多节点检索或单节点检索,可以大大的增快检索速率,从而有效的提高了检索效率。
进一步地,得到检索结果之后,还包括:计算所述检索关键字与所述检索结果中的每个检索结果的相似度值;根据所述相似度值,对所述检索结果进行排序。
进一步地,所述根据所述相似度值,对所述检索结果进行排序,包括:根据所述相似度值由高到低,对所述检索结果进行排序。
进一步地,在对输入的检索关键字进行分段处理,得到处理后的检索关键字之前,还包括:构建企业名称检索库。
进一步地,所述构建企业名称检索库,包括:将企业名称数据增加至全文检索数据库中,并保持实时同步;建立所述企业名称数据与所述全文检索数据库的索引。
进一步地,所述建立所述企业名称数据与所述全文检索数据库的索引,包括:将所述企业名称数据对应的每个企业名称包含的企业字号和行业特点作为索引列,建立所述企业名称数据与所述全文检索数据库的索引。
进一步地,所述显示所述检索结果中排在前N位的企业名称,以供用户查看,包括:显示所述检索结果中排在前10位的企业名称,以供用户查看。
采用上述进一步方案的有益效果是:通过显示检索结果中排在前10位的企业名称,可以方便用户查看相似性检索的结果,以便用户进行对比判断,并作出选择,大大的降低了相关工作人员的工作负担。
本发明附加的方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明实践了解到。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种企业名称的相似性检索方法的示意性流程图;
图2为本发明另一实施例提供的一种企业名称的相似性检索方法的示意性流程图;
图3为本发明另一实施例提供的一种企业名称的相似性检索方法的示意性流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
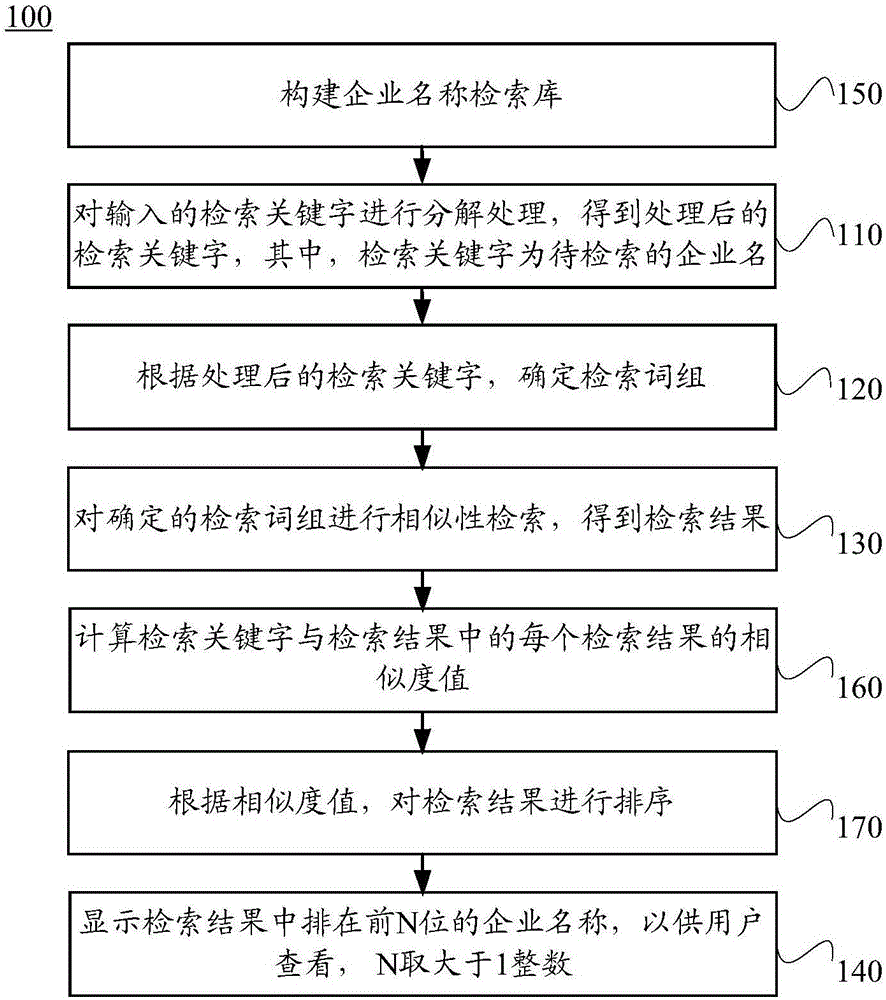
图1给出了本发明实施例提供的一种企业名称的相似性检索方法100的示意性流程图。如图1所示的企业名称的相似性检索方法100包括:
110、对输入的检索关键字进行分解处理,得到处理后的检索关键字,其中,检索关键字为待检索的企业名称。
120、根据处理后的检索关键字,确定检索词组。
130、对确定的检索词组进行相似性检索,得到检索结果。
140、显示检索结果中排在前N位的企业名称,以供用户查看,N取大于1整数。
本发明提供的一种企业名称的相似性检索方法,通过对输入的检索关键字进行分解处理,得到处理后的检索关键字,并根据处理后的检索关键字,确定检索词组,再对确定的检索词组进行相似性检索,得到检索结果,最后显示检索结果中排在前N位的企业名称,以供用户查看,不仅可以使得检索效率大大的提高,而且方便用户查看相似性检索的结果,以及满足相似性检索业务的需求。
具体的,在该实施例中,步骤110可以包括:判断输入的检索关键字中是否包含行政区划和组织形式企业类型的组成部分。若不包含,则将检索关键字分解为企业字号和/或行业特点以作为处理后的检索关键字。否则,将检索关键字分解为行政区划、组织形式企业类型、企业字号和行业特点,并将企业字号和/或行业特点作为处理后的检索关键字。
例如:输入的检索关键字为“北京联信永昶有限公司”,该检索关键字中包含了行政区划“北京”和组织形式企业类型“有限公司”的组成部分,则需要将其去除,将企业字号“联信永昶”作为处理后的检索关键字。
步骤120可以包括:将处理后的检索关键字按照分解处理之前的顺序排列。将与检索关键字中M个字不同的词组确定为检索词组,M可以取0、1或2。
例如:检索词组可以包括:
1)、将与“联信永昶”中0个字不同的词组:*联信永昶、联*信永昶、联信*永昶、联信永*昶、联信永昶*、等等;
2)、将与“联信永昶”中1个字不同的词组:*信永昶、联*永昶、联信*昶、联信永*、等等;
3)、将与“联信永昶”中2个字不同的词组:**永昶、联信**、联**昶;联*永*、*信*昶;*信永*、等等。
或者,在另一个实施例中,步骤120可以包括:将处理后的检索关键字按照分解处理之前的顺序排列。将与检索关键字同义和/或同音的词组确定为检索词组。
例如:检索词组可以包括与“联信永昶”同音的词组:如,连心咏唱、连新咏昌、琏鑫泳长等等。应理解,“联信永昶”这四个字,每个字都有其同音字,那么四个字的同音字之间的全排列组合后的结果都属于的与“联信永昶”同音的词组,而这里仅仅列举了几个作为例子,对本发明实施例的技术方案进行说明,并不对本发明实施例的技术方案构成任何限定。
或者,在另一个实施例中,步骤120可以包括:将处理后的检索关键字按照分解处理之前的顺序排列。将与检索关键字中K个相同且相邻的字组成的词组确定为检索词组。应理解,K的取值取决于检索关键字所包含的字数,最大取与检索关键字所包含的字数相同的数值,最小取2。
例如:检索词组可以包括:
1)、与“联信永昶”中4个相同且相邻的字组成的词组:*联信永昶、联信永昶*、等等;
2)、与“联信永昶”中3个相同且相邻的字组成的词组:联*信永昶、联信永*昶、*信永昶、联信永*、等等;
3)、与“联信永昶”中2个相同且相邻的字组成的词组:联信*永昶、联*信永*昶、**永昶、联信永**、*信永*、等等。
或者,在另一个实施例中,步骤120可以包括:将处理后的检索关键字按照分解处理之前的顺序排列。将与检索关键字中Q个相同但分散的字组成的词组确定为检索词组。应理解,Q的取值取决于检索关键字所包含的字数,最大取与检索关键字所包含的字数相同的数值,最小取2。
例如:检索词组可以包括:
1)、与“联信永昶”中4个相同但分散的字组成的词组:联*信*永*昶、*联*信*永*昶、联*信*永*昶*、等等;
2)、与“联信永昶”中3个相同但分散的字组成的词组:联*信*永*、*信*永*昶、*联*信*永*、*信*永*昶*、等等;
3)、与“联信永昶”中2个相同但分散的字组成的词组:联*信*、*信*永*、联*永*、联**昶、*信*昶、等等。
在该实施例中,通过将输入的检索关键字进行分解,去除行政区划和组织形式企业类型等通用信息,根据企业字号和/或行业特点确定检索词组,可以大大的减少检索式的数量,从而有效的提高了检索效率。
步骤130可以包括:判断检索词组的数量是否超过预设值。若超过,则采用分布式多节点检索,并将每个节点得到的检索结果进行汇总,得到检索结果。否则,采用单节点检索,得到检索结果。
例如:当检索词组的数量超过10个时,可以采用分布式检索,即:使用多个节点进行检索,然后将每个节点的检索结果进行汇总,得到最终的检索结果。当检索词组的数量小于10个时,采用单节点检索,即:使用一个搜索引擎进行检索,得到检索结果。
在该实施例中,通过判断检索词组的数量,确定采用分布式多节点检索或单节点检索,可以大大的增快检索速率,从而有效的提高了检索效率。
应理解,在该实施例中,仅是以预设值取10作为一个例子,对本发明实施例的技术方案进行说明,并不对本发明实施例的技术方案构成任何限定。也就是说,预设值还可以取8、12、15、16、18、20等等,本发明实施例对此并不在任何限定。
步骤140具体可以为:显示检索结果中排在前10位的企业名称,以供用户查看。
应理解,在上述实施例中,最终显示的检索结果可以是步骤130中得到的检索结果中排在前10位的企业名称,仅是以显示排在前10位作为一个例子,对本发明实施例的技术方案进行说明,并不对本发明实施例的技术方案构成任何限定。也就是说,也可以是显示排在前8位的企业名称、前12位的企业名称、前15位的企业名称、前20位的企业名称等,本发明实施例对此并不在任何限定。
在该实施例中,通过显示检索结果中排在前10位的企业名称,可以方便用户查看相似性检索的结果,以便用户进行对比判断,并作出选择,大大的降低了相关工作人员的工作负担。
可选地,作为本发明的一实施例,如图2所示,在步骤110之前,该企业名称的相似性检索方法100还可以包括:
150、构建企业名称检索库。
具体的,在该实施例中,将企业名称数据增加至全文检索数据库中,并保持实时同步。建立企业名称数据与全文检索数据库的索引。
例如:将企业名称数据对应的每个企业名称包含的企业字号和行业特点作为索引列,建立企业名称数据与全文检索数据库的索引。具体的建立索引的方式可以采用现有的技术完成,为了描述的简洁,在此不再赘述。
可选地,作为本发明的另一实施例,如图2所示,在步骤130之后,该企业名称的相似性检索方法100还可以包括:
160、计算检索关键字与检索结果中的每个检索结果的相似度值。
170、根据相似度值,对检索结果进行排序。
具体的,在该实施例中,可以根据相似度值由高到低,对检索结果进行排序。关于相似度的计算方法可以采用现有的计算相似度的方法,例如:根据以下情况出现时所占的权重值,计算每一个检索结果与输入的检索关键字,即:企业名称的相似度:
1)和输入的企业名称相差的字数。
2)匹配企业的所属行业和输入的企业名称的所属行业的关联程度。
3)同音词占整个字数的比重。
为了描述的简洁,具体的计算过程在此不再赘述。
下面结合图3对本发明提供的一种企业名称的相似性检索方法的技术方案进行详细的描述。如图3所示的企业名称的相似性检索方法200包括:
211、将企业名称数据增加至全文检索数据库中,并保持实时同步。
具体的,在该实施例中,数据同步的具体方法采用现有的数据同步的方法,为了描述的简洁,在此不再赘述。
212、建立企业名称数据与全文检索数据库的索引。
具体的,在该实施例中,可以将企业名称数据对应的每个企业名称包含的企业字号和行业特点作为索引列,建立企业名称数据与全文检索数据库的索引。
220、判断检索关键字中是否包含行政区划和组织形式企业类型的组成部分,若包含,则执行步骤231。否则,执行步骤232。
231、将检索关键字分解为行政区划、组织形式企业类型、企业字号和行业特点。
232、将分解得到的企业字号和/或行业特点作为处理后的检索关键字。
241、将处理后的检索关键字按照分解处理之前的顺序排列。
例如:输入的检索关键字是“北京轻创知识产权代理有限公司”,则该检索关键字中包含行政区划“北京”和组织形式企业类型“有限公司”,那么将企业字号“轻创”和行业特点“知识产权代理”作为处理后的检索关键字,并且按照“轻创知识产权代理”的顺序排列,而不是将其进行任意组合。
242、将与检索关键字中0个字或1个字或2个字不同的词组确定为检索词组。也就是说,可以将与“轻创知识产权代理”0个字不同的词组确定为检索词组;或者,可以将与“轻创知识产权代理”1个字不同的词组确定为检索词组;或者,可以将与“轻创知识产权代理”2个字不同的词组确定为检索词组,具体的形成不在此一一列举。
或者,243、将与检索关键字同义和/或同音的词组确定为检索词组。也就是说,可以将与“轻创知识产权代理”同义和/或同音的词组确定为检索词组,具体的形成不在此一一列举。
或者,244、将与检索关键字中2个相同且相邻的字组成的词组确定为检索词组。也就是说,可以将与“轻创知识产权代理”中2个相同且相邻的字组成的词组确定为检索词组,具体的形成不在此一一列举。
或者,245、将与检索关键字中2个相同但分散的字组成的词组确定为检索词组。也就是说,可以将与“轻创知识产权代理”中2个相同但分散的字组成的词组确定为检索词组,具体的形成不在此一一列举。
251、判断上述步骤242或步骤243或步骤244或步骤245中得到的检索词组的数量是否超过预设值。若超过,则执行步骤253。否则,执行步骤252。
252、采用单节点检索,得到检索结果。
253、采用分布式多节点检索,并将每个节点得到的检索结果进行汇总,得到检索结果。
261、计算检索关键字与上述步骤252或步骤253中得到的检索结果中的每个检索结果的相似度值。
262、根据相似度值由高到低,对检索结果进行排序。
270、显示检索结果中排在前10位的企业名称,以供用户查看。
应理解,在该实施例在中,出现的数值,如:“0个字或1个字或2个字”、“2个相同且相邻”、“2个相同但分散”、“排在前10位”,这些仅是用于举例说明本发明实施例的技术方案,并不对本发明实施例构成任何限定。
还应理解,在本发明各实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
通过本发明提供的一种企业名称的相似性检索方法,可以使得检索效率大大的提高,通常情况下可以确保在10秒中内完成企业名称的相似性检索。检索关键字的字数的不同,对应生成的检索词组的数量也不同,如:检索关键字的字数越多,则得到的检索词组的数量越多。根据检索关键字的字数的不同,对应的检索时长分布如下:
因此,通过本发明提供的一种企业名称的相似性检索方法,可以应用于工商名称登记系统中,能够大大提高工商名称登记的近似检索环节的工作效率,为工商名称登记全面实现快速的企业核名提供了强有力的技术手段,为商事制度改革提供了助力。
另外,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!