一种在流式计算中消息ID的生成方法与流程
本发明涉及大数据处理的技术领域,尤其涉及一种在流式计算中消息ID的生成方法。
背景技术:
在加工处理流式输入的消息数据时,往往会面临流式消息的标识问题,流式消息的标识的目的是表达消息的唯一性,并且在消息重复消费时消息ID需要保持前后一致。
现有的技术方案如下:
方法一:logid的生成方法,使用13位时间戳拼接上随机生成的随机数字。
根据当前系统时间可以取出一个13位的整型时间戳,在一毫秒内可能要同时生成多个logid,需要再加上一个使用random(随机)方式使用的一个定长的随机数。
存在问题:
1、ID生成与时间相关,消息ID不可重复生成,会导致同一条消息在重复消费后所产生的消息ID不是相同的。
2、流式计算一般是在一个集群中所进行中,在这样的一个分布式系统中,各服务器在同时运算的情况下ID生成的唯一性无法保证,导致ID不可用。
方法二:由独立服务器来统一控制消息id的生成。
部署一个独立的服务器,向外提供接口,每调用一次接口,服务器会通过自增的方式来生成一个唯一的新消息ID,通过接口返回给调用方。
存在的问题:
1、消息ID虽然保证了唯一性,但是在流量计算的海量数据处理的场景下,ID生成服务压力非常大,生成代价非常高。
2、消息在重复消费的情况下,消息ID会重新生成,不能保证消息重复消费情境下的一致性。
技术实现要素:
为克服现有技术的缺陷,本发明要解决的技术问题是提供了一种在流式计算中消息ID的生成方法,其能够确保消息ID的唯一性,消息ID可以重复生成且重复生成后消息ID没有任何变化。
本发明的技术方案是:这种在流式计算中消息ID的生成方法,该方法通过kafka集群进行消息的发布与订阅;
使用kafka集群中的一个topic来标识一个消息的来源,以便唯一标
识消息的来源;
使用每个topic的分区的编号partitionid;
使用每个分区中的消息的偏移量offset来标识每条消息;
topic、paritionid以及offset这三个变量组成的三元组,唯一确定
每条消息,并且实现无限次地重复生成。
本发明通过topic、paritionid以及offset这三个变量组成的三元组,便可以确定每条消息的唯一性,并且可以无限次地重复生成,从而能够确保消息ID的唯一性,消息ID可以重复生成且重复生成后消息ID没有任何变化。
附图说明
图1所示为根据本发明的在流式计算中消息ID的生成方法的流程图。
具体实施方式
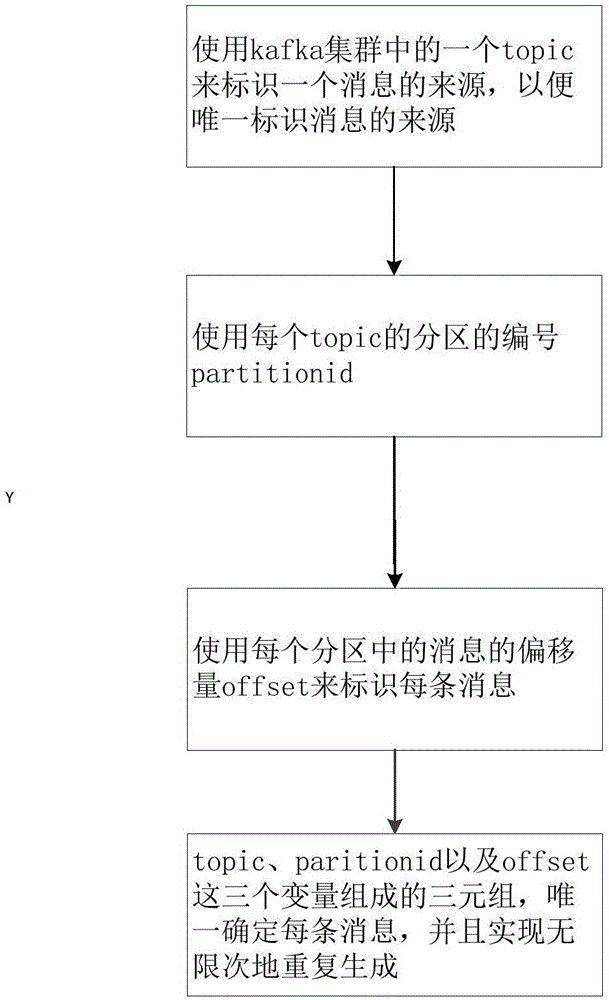
如图1所示,这种在流式计算中消息ID的生成方法,该方法通过kafka集群进行消息的发布与订阅;
使用kafka集群中的一个topic来标识一个消息的来源,以便唯一标识消息的来源;
使用每个topic的分区的编号partitionid;
使用每个分区中的消息的偏移量offset来标识每条消息;
topic、paritionid以及offset这三个变量组成的三元组,唯一确定每条消息,并且实现无限次地重复生成。
本发明通过topic、paritionid以及offset这三个变量组成的三元组,便可以确定每条消息的唯一性,并且可以无限次地重复生成,从而能够确保消息ID的唯一性,消息ID可以重复生成且重复生成后消息ID没有任何变化。
另外,该方法部署到storm集群中,由storm中的topology来负责组织消息ID的生成并落地到Hadoop分布式文件系统hdfs。
另外,该方法应用到Map Reduce程序中,提交到hadoop集群执行,由Map Reduce来生成消息ID并落地到hdfs。
本发明的有益效果如下:
1.消息ID没有重复,重复概率为0,确保了唯一性;
2.本消息ID可以重复生成,重复生成之后,消息ID没有任何变化。
以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!