一种基于Hadoop的大数据索引快速创建方法与流程
本发明涉及计算机软件应用技术领域,具体涉及一种基于Hadoop的大数据索引快速创建方法。
背景技术:
随着信息数据量的增大,单服务器的环境难以满足搜索引擎构建大规模数据索引的时空开销需求,因此如何实施高效信息索引越来越受到人们的关注。特别是近些年,由于网络信息的爆炸式增长,仅靠升级计算机硬件设备来提高数据处理的能力,已经不能适应信息的增长速度和信息处理效率的需求,研究者开始探索能够应对和处理庞大信息数据问题的策略。
单台计算机在构建大数据倒排索引时出现的两个问题:1)数据量越大,构建的时间越长,效率越低;2)建立倒排索引的单个文档不能过大,否则会导致机器内存不足问题,引起死机。
Hadoop作为一个开源的分布式系统基础架构,如今已成为国内外云计算热门研究对象。Hadoop的HDFS分布式存储和MapReduce分布式计算框架提供了高可靠性的分布式存储和高速的海量数据计算。前者是一个面向海量数据密集型应用的、可扩展的分布式文件系统,可在多台廉价的计算机上运行,具有强大的纠错功能,为用户提供可靠的服务;后者是实现对超大数据集的处理和生成算法的分布式编程模型,用户可以在不了解分布式底层细节的情况下开发分布式程序,并充分利用计算机集群的协作能力实现事物的高效运算。Hadoop这一技术使得高效建立大规模索引成为可能。
技术实现要素:
本发明要解决的技术问题是:本发明针对以上问题,提供一种基于Hadoop的大数据索引快速创建方法,针对目前动辄上亿条的数据建立索引,克服了传统单台机器创建索引时的种种缺点,减少了对高性能服务器的依赖,增强了工作稳定性,且拥有较好的可扩展性,便于推广应用。
本发明所采用的技术方案为:
一种基于Hadoop的大数据索引快速创建方法,所述方法通过编写Hbase数据字段与需建索引字段之间的映射xml文件,针对需拼接或需修改的数据,读取映射文件,相应数据组织成索引格式,利用分布式Hadoop集群的并发能力,通过执行MapReduce任务,将大数据自动分拆成数据段到集群中的每个机器中,并行运行,几何倍数的增加工作效率。
通过创建映射配置文件,增强了灵活性和实用性,只需通过修改配置文件即可针对不同的Hbase表建立索引。
所述方法在创建索引前,通过“能否更新”判断机制,对于已经建立过索引的数据,直接跳过,减少不必要的性能损耗,达到索引增量更新的目的。
所述方法采用Nginx负载均衡自动分发机制,向Solr中创建索引,通过配置了Nginx负载均衡的分布式Solr,将接收到的创建索引请求自动分发到相对空闲的Solr主机,进行索引的创建。
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个 IMAP/POP3/SMTP服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日,其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名,2011年6月1日,nginx 1.0.4发布。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
本发明的有益效果为:
本发明针对目前动辄上亿条的数据建立索引,克服了传统单台机器创建索引时的种种缺点,减少了对高性能服务器的依赖,增强了工作稳定性,本发明有着环境易搭建、处理海量数据速度快且拥有良好的扩展性,具有很好的推广使用价值。
附图说明
图1为本发明方法流程图;
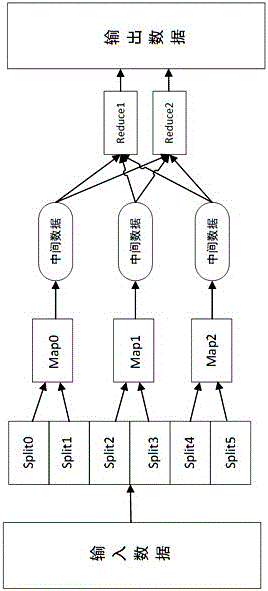
图2为MapReduce处理过程示意图。
具体实施方式
下面根据说明书附图,结合具体实施方式对本发明进一步说明:
实施例1:
一种基于Hadoop的大数据索引快速创建方法,所述方法通过编写Hbase数据字段与需建索引字段之间的映射xml文件,针对需拼接或需修改的数据,读取映射文件,相应数据组织成索引格式,利用分布式Hadoop集群的并发能力,通过执行MapReduce任务,将大数据自动分拆成数据段到集群中的每个机器中,并行运行,几何倍数的增加工作效率,如图2所示。
通过创建映射配置文件,增强了灵活性和实用性,只需通过修改配置文件即可针对不同的Hbase表建立索引。
实施例2
如图1所示,在实施例1的基础上,本实施例所述方法在创建索引前,通过“能否更新”判断机制,对于已经建立过索引的数据,直接跳过,减少不必要的性能损耗,达到索引增量更新的目的。
实施例3
在实施例2的基础上,本实施例所述方法采用Nginx负载均衡自动分发机制,向Solr中创建索引,通过配置了Nginx负载均衡的分布式Solr,将接收到的创建索引请求自动分发到相对空闲的Solr主机,进行索引的创建。
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个 IMAP/POP3/SMTP服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日,其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名,2011年6月1日,nginx 1.0.4发布。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!