一种基于SVM融合多种情感资源的微博情感分类方法与流程
本发明属于自然语言处理
技术领域:
,特别是一种基于SVM融合多种情感资源的微博情感分类方法。
背景技术:
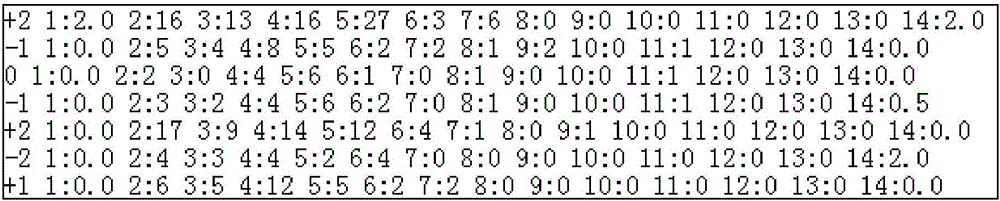
:在微博中潜藏着广大网民极为丰富的主观情感信息。通过对微博进行情感分类,获取广大网民们的情感倾向,可以迅速、准确地了解广大网民的诉求,为网络舆情分析提供可靠依据。目前,已有许多学者对微博情感分类进行研究,主要采用基于情感词典的方法和机器学习的方法,将情感分为正面、负面或者正面、中性和负面三类。基于情感词典的方法是通过构建情感词典,然后通过特定的算法模型进行情感倾向值的计算,进而根据情感倾向值对文本进行极性分析。如通过构建情感词典、否定词典、程度副词词典或在此基础上增加领域词典、网络词典等,通过特定算法对文本进行极性判断,将文本分为正、负两类或者正、负以及中立三类。(2.ShenYang,LiShuchen,ZhengJing,etal.EmotionMiningResearchonMicro-blog[C].In:WebSociety,2009.SWS’09.1stIEEESymposium,2009:71-753.韩忠明,张玉沙,张慧,等.有效的中文微博短文本倾向性分类算法[J].计算机应用与软件,2012,29(10):89-934.张成功,刘培玉,朱振方,等.一种基于极性词典的情感分析方法[J].山东大学学报(理学版),2012,(3):47-50)。以机器学习的方法是将情感分类看作一种特殊的文本分类,通过机器学习算法训练标注好的训练集得到分类模型,再由分类模型来确定文本的倾向性(张阳,刘晓霞,孙凯龙,等.基于情感描述项的文本倾向性识别研究[J].计算机工程与应用,2015,51(4))。如使用SVM模型、KNN模型、朴素贝叶斯模型等对文本进行两级、或三级分类。(5.BorbosaL,FengJ.RobustsentimentdetectiononTwitterfrombiasedandnoisydata[C].In:Proceedingsofthe23rdInternationalConferenceonComputationalLinguistics.Beijing:TsinghuaUniversityPress,2010:36-44.6.DavidovD,TsurO,RappoportA.Enhancedsentimentlearningusingtwitterhashtagsandsmileys[C].In:Proceedingsofthe23rdinternationalconferenceoncomputationallinguistics:posters.AssociationforComputationalLinguistics,2010:241-249.7.林江豪,阳爱民,周咏梅,等.一种基于朴素贝叶斯的微博情感分类[J].计算机工程与科学,2012,34(9):160-165.)通过以上的研究分析发现,无论是基于情感词典的方法还是基于机器学习的方法,对情感分类的研究多以三级分类为主,然而这种划分方法并不能精确的反映网民们的情感立场(1.王雪猛,王玉平.基于情感倾向分析的突发事件网络舆情预警研究[J].西南科技大学学报:哲学社会科学版,2016,33(1):63-66)。在网络舆情中,部分网民会表达自己对某事件的绝对立场,他们很难受其他言论的影响。而有的网民表现的立场并不稳定,他们只是暂时性的受到某些言论的影响,表现出倾向性的立场。所以,将情感划分为三种过于绝对化,不能准确、全面地获取网民们的情感倾向。技术实现要素:本发明的目的在于提供一种基于SVM融合多种情感资源的微博情感分类方法,对微博实现情感5级分类,从而准确、全面地获取网民们的情感倾向。实现本发明目的的技术解决方案为:一种基于SVM融合多种情感资源的微博情感分类方法,包括以下步骤:步骤1、构建相关词典,完善情感词典和程度副词词典,并对程度副词中所有词进行权重赋值;步骤2、文本预处理,将不同的语料预先进行断句、格式处理,利用ICTCLAS对语料进行分词和词性标注,利用StanfordParser对语料进行句法分析;步骤3、情感得分计算,将分词后的词语与正、负面词典比对得到初始词语极性,再将情感词前的词语与词语程度级别词典和否定词词典比对得到修饰词权重,把初始词语极性和修饰词权重相乘得出每条微博的情感分数;步骤4、特征提取,词性特征提取名词、动词、形容词作为特征,情感特征提取正面情感词、负面情感词、程度副词权重、情感得分作为特征,句式特征提取否定词、感叹号、问号作为特征,语义特征提取StanfordParser句式分析后的四种语义关系nsubj、advmod、amod、neg作为特征;步骤5、模型训练,将提取的特征输入Libsvm进行模型训练,得出训练模型,最后利用训练模型对测试语料进行分类。进一步地,步骤1中所述构建相关词典,完善情感词典和程度副词词典,并对程度副词中所有词进行权重赋值,具体步骤如下:步骤1-1、以《知网》情感分析用词语集为基本词汇来源,将其中的《正面评价词语(中文)》与《正面情感词语(中文)》合并得到正面词词典;同样,《负面评价词语(中文)》加上《负面情感词语(中文)》得到负面词词典;同时,利用Word2Vec模型实现网络情感新词发现;步骤1-2、否定词以《中国现代语法》中给出的否定词为基础,并对否定词词典进一步扩展,最终得到20个否定词;步骤1-3、程度副词以HowNet情感词典中的程度副词词典为基础,又通过人工收集,最终得到256个程度副词;对不同语气强度的程度副词,分别赋予0.5、1.0、1.5、2.0的权重。进一步地,步骤2中所述文本预处理步骤如下:步骤2-1、对微博语料进行数据清洗,去除无用信息;步骤2-2、使用中科院计算技术研究所研制的汉语词法分析系统ICTCLAS,实现语料的中文分词及词性标注;步骤2-3、使用StanfordParser句法分析器,实现语料的句法分析。进一步地,步骤3中所述把初始词语极性和修饰词权重相乘得出每条微博的情感分数,公式如下:其中,Score为情感分数,n是一条微博中的句子数,rawscorei是第i个句子中情感词的基本分数,rawscore为+1、-1或0;Intensei是第i个句子的修饰词程度权重或否定词权重。进一步地,步骤4所述特征提取的步骤如下:步骤4-1、步骤2-2对语料中每条微博进行了中文分词及词性标注后,统计每条微博中文分词结果中正面情感词、负面情感词、否定词、程度副词的数量以及词性标注结果为动词、名词、形容词的数量;步骤4-2、统计语料中每条微博!和?的数量;步骤4-3、步骤2-3对语料中每条微博进行了句法分析,统计每条微博句法分析结果为nsubj、advmod、admod、neg的数量;进一步地,步骤5所述模型训练的步骤如下:步骤5-1、用步骤3和步骤4提取的每一个特征值来表示一条微博,之后依照LibSVM工具所需要的数据格式对微博文本进行特征转换;步骤5-2、将提取的特征80%作为训练集,20%作为测试集,导入Libsvm,进行模型训练,得出情感分类模型。步骤5-3、利用得出的情感分类模型对测试语料进行分类。本发明与现有技术相比,其显著优点为:(1)利用word2vec扩充情感词典,对程度副词赋予权重,并将情感得分、程度副词的权重作为分类特征,科学合理;(2)采用句法分析等方法来挖掘微博的语义特征,提高了模型5级分类的准确性;(3)本发明融合多种情感资源,利用SVM模型对微博语料实现了5级分类,能够准确、全面地获取网民们的情感倾向。下面结合附图对本发明作进一步详细描述。附图说明图1是本发明基于SVM融合多种情感资源的微博情感分类方法的流程图。图2是微博特征转换后的格式示意图。图3是使用分类模型对测试语料自动分类的结果图。具体实施方式结合图1,本发明基于SVM融合多种情感资源的微博情感分类方法,包括以下步骤:步骤1、构建相关词典,完善情感词典和程度副词词典,并对程度副词中所有词进行权重赋值,具体步骤如下:步骤1-1、根据《知网》的“《知网》情感分析用词语集”这一基本的词汇来源,将其中的《正面评价词语(中文)》与《正面情感词语(中文)》合并得到正面词词典;同样,《负面评价词语(中文)》加上《负面情感词语(中文)》得到负面词词典;同时,利用Word2Vec模型实现网络情感新词发现;表1情感词典示例名称示例个数正面情感词爱、赞赏、快乐、表扬、称心如意……5161负面情感词哀伤、沮丧、鄙视、后悔、失落……5962步骤1-2、否定词以《中国现代语法》中给出的否定词为基础,并对否定词词典进一步扩展,最终得到20个否定词;表2否定词词典示例步骤1-3、程度副词以HowNet情感词典中的程度副词词典为基础,又通过人工收集,最终得到256个程度副词;对不同语气强度的程度副词,分别赋予0.5、1.0、1.5、2.0的权重。表3程度副词词典示例步骤2、文本预处理,将不同的语料预先进行断句、格式处理,利用中科院计算技术研究所研制的汉语词法分析系统(InstituteofComputingTechnology,ChineseLexicalAnalysisSystem,ICTCLAS),对语料进行分词和词性标注,利用StanfordParser对语料进行句法分析;所述文本预处理步骤如下:步骤2-1、由于微博语料含有大量URL、#话题#、@信息,会产生大量噪声,所以首先对微博语料进行数据清洗,去除无用信息;步骤2-2、使用中科院计算技术研究所研制的汉语词法分析系统ICTCLAS,实现语料的中文分词及词性标注;步骤2-3、使用StanfordParser句法分析器,实现语料的句法分析。步骤3、情感得分计算,将分词后的词语与正、负面词典比对得到初始词语极性,再将情感词前的词语与词语程度级别词典和否定词词典比对得到修饰词权重,把初始词语极性和修饰词权重相乘得出每条微博的情感分数,公式如下:其中,Score为情感分数,n是一条微博中的句子数,rawscorei是第i个句子中情感词的分数,rawscore为+1、-1或0,+1是正面情感词分数、-1是负面情感词分数、0代表句子中没有情感词;Intensei是第i个句子情感词前面的程度副词权重或否定词权重。步骤4、特征提取,词性特征提取名词、动词、形容词作为特征,情感特征提取正面情感词、负面情感词、程度副词权重、情感得分作为特征,句式特征提取否定词、感叹号、问号作为特征,语义特征提取StanfordParser句式分析后的四种语义关系nsubj、advmod、amod、neg作为特征;所述特征提取的步骤如下:步骤4-1、步骤2-2对语料中每条微博进行了中文分词及词性标注后,统计每条微博中文分词结果中正面情感词、负面情感词、否定词、程度副词的数量以及词性标注结果为动词、名词、形容词的数量;步骤4-2、统计语料中每条微博“!”和“?”的数量;步骤4-3、步骤2-3对语料中每条微博进行了句法分析,统计每条微博句法分析结果为nsubj(名词性主语)、advmod(副词性修饰语)、admod(形容词修饰语)、neg(否定修饰词)的数量;步骤5、模型训练,将提取的特征输入Libsvm进行模型训练,得出训练模型,最后利用训练模型对测试语料进行分类;所述模型训练的步骤如下:步骤5-1、用步骤3和步骤4提取的每一个特征值来表示一条微博,之后依照LibSVM工具所需要的数据格式对微博文本进行特征转换;步骤5-2、将提取的特征80%作为训练集,20%作为测试集,导入Libsvm,进行模型训练,得出情感分类模型。步骤5-3、利用得出的情感分类模型对测试语料进行分类。实施例1结合图1,本发明基于SVM融合多种情感资源的微博情感5级分类方法,包括以下步骤:第一步,构建相关词典,完善情感词典和程度副词词典,并对程度副词中所有词进行权重赋值。部分程度副词及其权重如表1所示。第二步,对语料进行预处理,将不同的语料预先进行断句、格式处理、分词和词性标注;(1)由于微博语料含有#话题#、URL和@用户等无用信息,这些信息并不包含用户的观点,还可能影响下一步分词和词性标注的效果。因此在分词之前,首先滤掉微博中的#话题#、URL和@用户等无用信息,然后再对过滤后的语料进行下一步的处理。(2)使用中科院计算技术研究所研制的汉语词法分析系统(InstituteofComputingTechnology,ChineseLexicalAnalysisSystem,ICTCLAS),实现语料的中文分词及词性标注。例如,“诺基亚lumia新款win8系统,用起来很流畅哦,很好用”这句话的分词结果(带词性标注)是:诺基亚/nzlumia/x新款/nwin8/x系统/n,/w用/v起来/v很/d流畅/a哦/o,/w很/d好/a用/v。第三步,情感得分计算,将分词后的词语与正、负面词典比对得到初始词语极性,再将情感词前的词语与词语程度级别词典和否定词词典比对得到修饰词权重,把二者相乘得出每条微博的情感分数;计算公式如下:其中,n是一条微博中的句子数,rawscore是第i个句子中情感词的分数,rawscore为+1、-1或0,+1是正面情感词分数、-1是负面情感词分数、0代表句子中没有情感词;Intense是第i个句子的修饰词程度权重或否定词权重。第四步,特征提取,词性特征提取名词、动词、形容词作为特征,情感特征提取正、负面情感词、程度副词权重、情感得分作为特征,句式特征提取否定词、感叹号、问号作为特征,语义特征提取StanfordParser句式分析后的四种语义关系nsubj、advmod、amod、neg作为特征,如表4所示。表4特征类型及含义第五步,模型训练,将提取的特征按照LibSVM工具所需要的数据格式对微博文本进行特征转换如图2所示,然后输入Libsvm进行模型训练,得出训练模型;再利用训练模型对测试语料进行分类,分类结果如图3所示。实验数据使用部分COAE2014微博评测语料,人工对这些语料分“非常正面”,“正面”、“中立”,“负面”、“非常负面”5个情感级别进行标注。标注工作由课题组成员完成,共标注5000条语料。标注结果如表5所示。表5实验数据分布实验结果采用准确率、召回率和F1值作为评价标准。为了验证本专利方法的有效性,将本专利方法与Ding(DingShenchun,JiangTing,WenNeng.ResearchonsentimentorientationofproductreviewsinChinesebasedoncascadedCRFsmodels[C].In:Proceedingofthe2012InternationalConferenceonMachineLearningandCybernetics(ICMLC2012),Xian:IEEE,2012:1993-1999.)提出的方法进行对比。该方法采用层叠CRFs模型,首先对文本进行3级分类,然后结合合词特征、评价词特征、连词特征以及极性特征(即3级分类的结果),在COAE2008的任务3上,取得了很好的效果,准确率最高达到83.75%,是一种典型的文本倾向性5分类算法。本专利使用该方法在本专利语料集上进行实验,与本专利的方法进行对比,结果如表6所示。表6实验结果由表4可以看出,本专利提出的方法在5级分类的正确率为82.4%,相较于层叠CRFs(75.2%)方法,准确率有较大的提高。召回率为81.9%,相较于层叠CRFs方法,有小幅度提升。F值综合考虑了精确率和召回率,本专利方法的F值为82.1%,与层叠CRFs(74.3%)相比,提升了7.8%。Ding的层叠CRFs方法所提取的特征主要针对中长文本,对于微博短文本并不适用,所以准确率有所下降。本专利充分考虑微博短文本的特性,选择词性特征、情感特征、句式特征和语义特征,并且利用word2vec对情感词典进行了扩充,使得在对微博进行情感5级分类中取得较高的准确率。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1