一种网络新词识别方法与流程
本发明涉及互联网领域,更具体地,涉及一种网络新词识别方法。
背景技术:
语言随着科技的发展而不断演变,从词语层面上看就是新词不断涌现。语言学者对大量新词的出现给予了广泛关注,80年代后,学者们通过不同角度用不同方式对新词识别做了很多研究工作。除此之外,自然语言处理领域的专家们利用计算机技术从大规模语料库进行新词识别。目前,以微软亚洲研究院、北京语言大学、搜狗科技、中科院计算所等机构为代表的科研人员在新词识别领域做了大量的研究工作,取得了诸多优秀成果,加速了中文自然语言处理技术的发展。
新词识别的研究方法总体上分为两种:基于规则的方法和基于统计的方法。基于规则的新词识别的主要思想是根据新词的构词特性去建立规则库和专业词库,然后去匹配制定的语言规则,从而发现新词。这种方法缺点在于会被局限在某一领域,其移植性和适应性差,并且需要建立规则库。基于统计的方法是利用统计模型对频繁出现的字串进行统计,生成候选新词,再利用构词规则和现有词典排除不是新词的垃圾串。这种方法一般适合查找较短的新词语,对于超过四字的新词语基本无效,且存在数据稀疏、准确率低的问题。目前使用得比较多的方法是结合上述两种方法,用统计规则大规模获取候选新词,在此基础上通过对应规则进行垃圾串过滤来控制新词的识别质量。
在这个互联网高速发展的时代,随着网络用户数量快速增长,每分每秒都会有大量网络用语出现,电子商务领域的商品描述信息里肯定也会出现一定数量的网络新词。因此,辨识网络新词并对商品描述信息做出正确的分词具有极高的现实意义,是本领域研究的重点。
技术实现要素:
本发明为解决以上现有技术的难题,提供了一种网络新词识别方法,该方法能够有效的识别出网络新词。
为实现以上发明目的,采用的技术方案是:
一种网络新词识别方法,包括以下步骤:
S1.使用网络蜘蛛对网页进行抓取,然后从抓取的网页中提取文本信息,并对提取文本信息进行预处理;
S2.将文本信息中前后被空格隔开的候选新词提取出来,然后执行步骤S3;将文本信息中重复出现的候选新词提取出来,执行步骤S7;
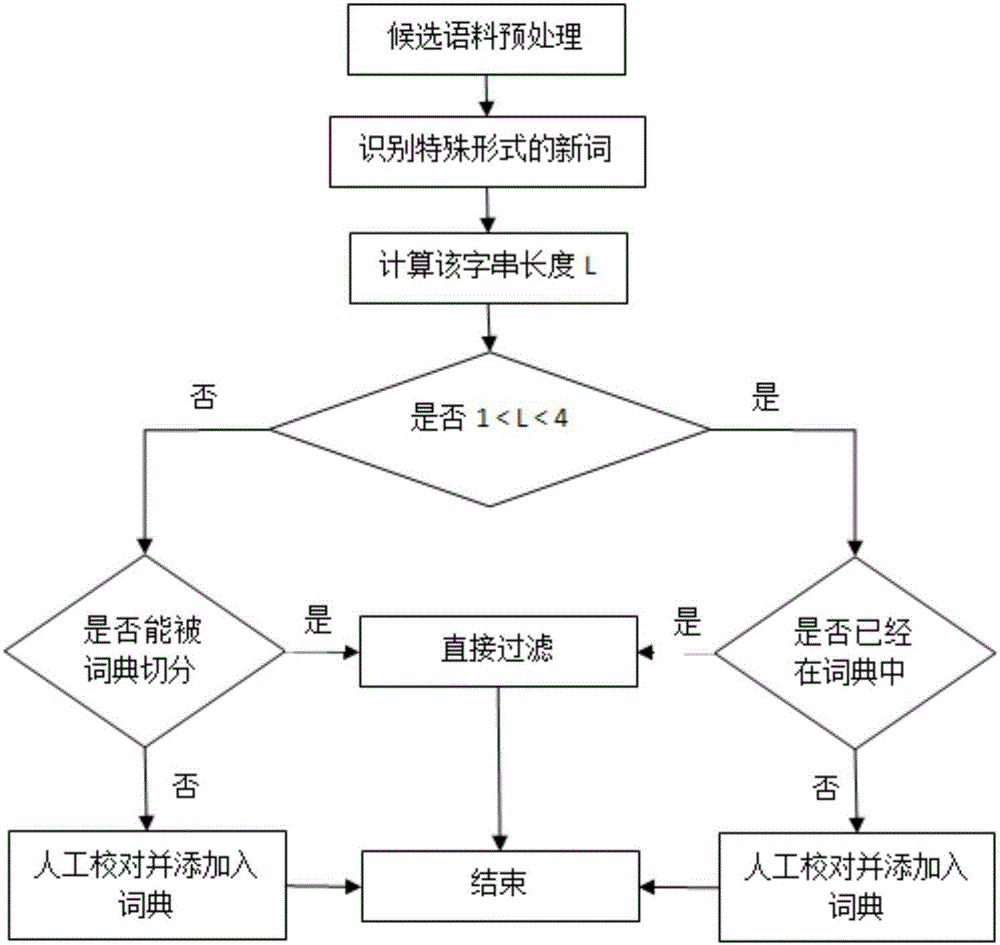
S3计算候选新词i的字串长度L,判断L是否大于1小于4,若是执行步骤S4,否则执行步骤S5;
S4.判断候选新词i是否已经存储在词典中,若是则将候选新词i过滤掉,否则通过人工校对后将候选新词i添加入词典中;
S5.判断候选新词i能否被分词词典切分,若是,则将候选新词i过滤掉,否则通过人工校对后将候选新词i添加入词典中;
S6.令i=i+1,然后执行步骤S3;
S7.统计文本信息中候选新词j的左邻接词个数m和右邻接词个数n,判断m、n是否分别大于设定的阈值,若是则执行步骤S8,否则将候选新词j过滤掉;
S8.统计候选新词j的构词强度,若构词强度大于所设定的阈值,则在通过人工校对后将候选新词j添加入词典中;否则将候选新词j过滤掉;
S9.令j=j+1然后执行步骤S7。
上述方案中,本发明提供的新词识别方法能够对重复串和文章关键词、超链接词、标点符号中间的词这些特殊格式的新词进行识别,因此能够很好地适应于网络新词的特点并将其识别出来,实验证明,本发明提供的新词识别方法能够有效地对网络新词进行识别。
优选地,所述步骤S1中,对文本信息进行预处理具体包括以下操作:
(1)利用标点符号将大段文字分成若干短句;
(2)将短句中构词能力不强的单字删除,如呢、啊、吧、么等。
优选地,所述步骤S8中,统计候选新词j构词强度的具体过程如下:
(1)统计词首的构词强度:
其中,L是词典的词条总数,Head(x,s)是二值函数,定义如下:
(2)统计词中的构词强度:
(3)统计词尾的构词强度:
则候选新词j构词强度表示为:
与现有技术相比,本发明的有益效果是:
本发明提供的新词识别方法能够对重复串和文章关键词、超链接词、标点符号中间的词这些特殊格式的新词进行识别,因此能够很好地适应于网络新词的特点并将其识别出来,实验证明,本发明提供的新词识别方法能够有效地对网络新词进行识别。
附图说明
图1为识别方法的流程示意图。
图2为对重复出现的候选新词进行是识别的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
如图1、2所示,本发明提供的方法具体包括以下步骤:
S1.使用网络蜘蛛对网页进行抓取,然后从抓取的网页中提取文本信息,并对提取文本信息进行预处理;
S2.将文本信息中前后被空格隔开的候选新词提取出来,然后执行步骤S3;将文本信息中重复出现的候选新词提取出来,执行步骤S7;
S3计算候选新词i的字串长度L,判断L是否大于1小于4,若是执行步骤S4,否则执行步骤S5;
S4.判断候选新词i是否已经存储在词典中,若是则将候选新词i过滤掉,否则通过人工校对后将候选新词i添加入词典中;
S5.判断候选新词i能否被分词词典切分,若是,则将候选新词i过滤掉,否则通过人工校对后将候选新词i添加入词典中;
S6.令i=i+1,然后执行步骤S3;
S7.统计文本信息中候选新词j的左邻接词个数m和右邻接词个数n,判断m、n是否分别大于设定的阈值,若是则执行步骤S8,否则将候选新词j过滤掉;
其中,左邻接词个数是指文本中与候选新词(散串)左边相邻的不同元素个数;右邻接词个数是指文本中与候选新词(散串)右边相邻的不同元素个数;
S8.统计候选新词j的构词强度,若构词强度大于所设定的阈值,则在通过人工校对后将候选新词j添加入词典中;否则将候选新词j过滤掉;
S9.令j=j+1然后执行步骤S7。
上述方案中,本发明提供的新词识别方法能够对重复串和文章关键词、超链接词、标点符号中间的词这些特殊格式的新词进行识别,因此能够很好地适应于网络新词的特点并将其识别出来,实验证明,本发明提供的新词识别方法能够有效地对网络新词进行识别。
其中,对文本信息进行预处理具体包括以下操作:
(1)利用标点符号将大段文字分成若干短句;
(2)将短句中构词能力不强的单字删除,如呢、啊、吧、么等。
本实施例中,统计候选新词j构词强度的具体过程如下:
(1)统计词首的构词强度:
其中,L是词典的词条总数,Head(x,s)是二值函数,定义如下:
(2)统计词中的构词强度:
(3)统计词尾的构词强度:
则候选新词j构词强度表示为:
实施例2
本实施例在实施例1的基础上,进行了具体的实验,本次实验利用网络蜘蛛在网上下载大量网页,这些网页主要来自于新浪网、搜狐网、腾讯网、天涯论坛和猫扑论坛等。这些网站包含的文本信息全面,涉及到各个领域,具有很强的时效性。网上出现的新词一般会很快的在这些网站流行起来。本次实验下载了上面几个网站2015年12月的4000张网页,其中科技类、体育类、娱乐类、新闻类各1000张,经过删除HTML网络标签,提取网页正文和其他文字(关键词、标题、超链接等)后,得到大小为32.5M的纯文本。
本次实验中,网络新词识别算法识别出新词1264个。识别出的这些新词中,二字词468个,三字词524个,四字词125个,其他为四字以上词或英文缩略词。
下列是一部分识别的新词,由于使用的词典的词条数目比较少,有些已经不是新词的词条也被识别出来,然后被人工添加到词典中。
二字新词:神马、酱紫、弓强、拍砖、狂顶、呵呵、斑竹、厚厚、咔咔、抛砖、马甲、打铁、盖楼、辣鸡、口年、达人、御姐、口胡、废柴、收声、耽美、攻受、同人、鸭梨、围脖、骚年、智捉、草根、团购、蜗居、杯具、坑爹、李刚、凤姐、恒大、心塞、不造、逗比、补刀、弹幕、浮云、点赞、颜值、悲催、壁咚、灰机、偶吧、给力、吐槽、菜鸟、小强、逼格、闪客、哈韩、跑酷、快闪等。
三字新词:打酱油、犀利哥、南山南、注孤生、涨姿势、我伙呆、何弃疗、么么哒、蒜你狠、高富帅、白富美、洗剪吹、然并卵、啃老族、恶趣味、阿加西、欧巴桑、小鲜肉、闹太套、尴尬癌、伐开心、城会玩、琅琊榜、宫心计、富二代、火星文、思密达、中二病、广场舞、闪电侠、喜当爹、正能量、比特币、毁三观、秀恩爱、乌龙球、马赛克、蒙太奇、一把手、撬墙角、闭门羹、月光族等。
四字新词:累觉不爱、八荣八耻、爱老虎油、非诚勿扰、不明觉厉、十动然拒、男默女泪、火钳刘明、喜大普奔、细思极恐、人艰不拆、你行你上、不忍直视、不作不死、有钱任性、脑洞大开、走召弓强、笑而不语、光盘行动、以房养老、潮汐车道、压力山大、让子弹飞、海绵宝宝、宫锁心玉、药家鑫案等。
其他:羡慕嫉妒恨、快乐大本营、越策越开心、图样图森破、且行且珍惜、duang、主要看气质、hold住、待我长发齐腰、DIY、H1N1、深藏功与名、豆腐渣工程、BB霜、库兹涅佐夫、中国好声音等。
通过以上实验可知,本发明提供的新词识别方法能够有效地对网络新词进行识别。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!