一种多媒体资源的推荐方法及系统与流程
本发明实施例涉及互联网多媒体技术领域,尤其涉及一种多媒体资源的推荐方法及系统。
背景技术:
目前,随着互联网技术的发展,出现了很多供用户使用的多媒体播放产品,该多媒体播放产品能够为用户提供所需的多媒体资源,商家为了使自己设计的多媒体播放产品能够受更多用户的青睐,在为用户提供所需多媒体资源的同时,还增加了其他服务于用户的功能,比如,向用户推荐更多用户喜爱的多媒体资源。
一般地,通常采用协同过滤算法来实现多媒体资源的推荐,其实现过程描述为:首先商家需要收集待推荐多媒体资源与用户之间的共现关系(如浏览、收藏或者观看等),然后依据每个多媒体文件具有的用户向量,来计算多媒体文件与多媒体文件之间的相似度,同时,每个用户依据所关注的多媒体文件确定各自具有的多媒体向量,并依据各自的多媒体向量确定了用户与用户之间的相似度,最终,可以基于所计算的相似度值,选取出用户感兴趣的多媒体资源并推荐给用户或推荐给与该用户具有相同喜好的其他用户。但是,基于该推荐方法进行多媒体资源推荐时,需要花费相当长的一段时间来收集用户的行为信息,对于一个新开发的多媒体播放软件而言,在前期用户使用较少时,容易出现冷启动问题,即前期基于该方法很难向用户推荐准确可靠的多媒体资源;同时,由于该方法使用用户向量以及多媒体向量相互表示,所以随着时间的推移,还会影响多媒体资源推荐系统的工作性能。
此外,还经常采用文本内容匹配的方法来实现多媒体资源的推荐,具体的,获取多媒体库中每个多媒体文件的文本描述信息,然后基于每个多媒体文件的文本描述信息确定该多媒体文件的空间向量,同时确定用户当前所播放多媒体文件的空间向量,最终基于空间向量确定当前所播放多媒体文件与多媒体库中其他多媒体文件的相似度,然后基于相似度值确定待推荐给用户的多媒体资源。但是,基于该方法进行多媒体推荐时,较少考虑多媒体文件的文本描述信息中的同义词以及一词多义,而同义词会影响召回率,一词多义会对多媒体文件推荐的准确性产生影响。
技术实现要素:
本发明实施例提供了一种多媒体资源的推荐方法及系统,能够避免多媒体资源推荐过程中的冷启动问题,同时还能提高多媒体资源推荐的准确性。
一方面,本发明实施例提供了一种多媒体资源的推荐方法,包括:
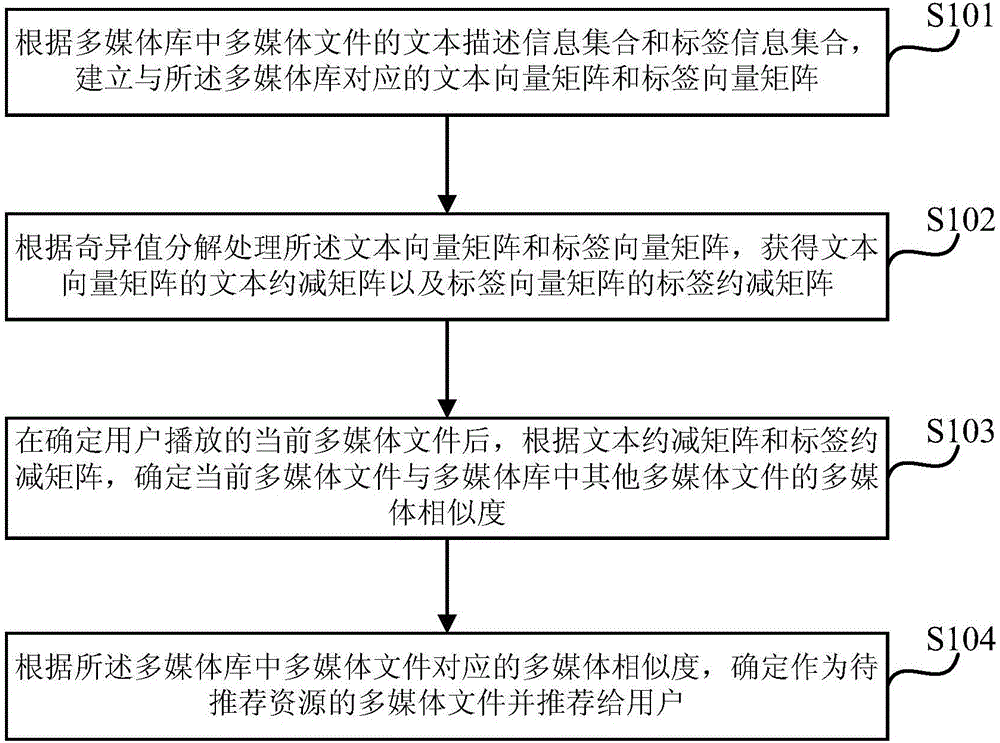
根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵;
根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得所述文本向量矩阵的文本约减矩阵以及所述标签向量矩阵的标签约减矩阵;
在确定用户播放的当前多媒体文件后,根据所述文本约减矩阵和标签约减矩阵,确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的多媒体相似度;
根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件并推荐给用户。
另一方面,本发明实施例提供了一种多媒体资源的推荐系统,包括:
向量矩阵确定模块,用于根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵;
约减矩阵确定模块,用于根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得所述文本向量矩阵的文本约减矩阵以及所述标签向量矩阵的标签约减矩阵;
相似度确定模块,用于在确定用户播放的当前多媒体文件后,根据所述文本约减矩阵和标签约减矩阵,确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的多媒体相似度;
资源推荐模块,用于根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件并推荐给用户。
本发明实施例中提供了一种多媒体资源的推荐方法及系统,该方法首先建立多媒体库的文本向量矩阵和标签向量矩阵;然后对文本向量矩阵和标签向量矩阵根据进行奇异值分解获得各自的文本约减矩阵和标签约减矩阵;之后确定用户播放的当前多媒体文件,并根据文本约减矩阵和标签约减矩阵确定当前多媒体文件与其他多媒体文件的多媒体相似度,最终,根据所确定的多媒体相似度来确定作为待推荐资源的多媒体文件,并将确定的待推荐资源推荐给用户。利用该方法,实现了多媒体文件播放时相关多媒体资源的智能推荐,避免了多媒体资源推荐过程中的冷启动问题,还解决了多媒体资源推荐过程中文本同义词及一词多义对多媒体文件相似度计算的影响,从而提高了多媒体文件的匹配度,进而提高了多媒体资源推荐的准确性。
附图说明
图1为本发明实施例一提供的一种多媒体资源的推荐方法的流程示意图;
图2为本发明实施例二提供的一种多媒体资源的推荐方法的流程示意图;
图3为本发明实施例三提供的一种多媒体资源的推荐系统的结构框图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种多媒体资源的推荐方法的流程示意图,适用于向用户推荐与当前播放的多媒体文件相似的其他多媒体文件的情况,该方法可以由多媒体资源的推荐系统执行,其中该系统可由软件和/或硬件实现,并一般集成在向用户提供多媒体播放资源的多媒体服务平台上。
如图1所示,本发明实施例一提供的一种多媒体资源的推荐方法,包括如下操作:
S101、根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵。
在本实施例中,多媒体库具体可用于存放供用户欣赏的多媒体文件,多媒体文件可以是能够观看的视频文件,如微电影、电影、电视剧以及综艺节目等,也可以是能够播放的各种格式的音乐文件或者图像文件等。一般地,在多媒体库中除了存放多媒体文件外,还存储了与每个多媒体文件对应的文本描述信息以及与每个多媒体文件对应的标签信息,其中,文本描述信息具体可用于概括描述相应多媒体文件中所包括的主要信息内容,且文本描述信息可以由至少一条语句组成;标签信息具体可用于描述对相应多媒体文件所属领域、所属类型以及所属成本规模等信息,但标签信息主要由至少一个词语组成。
示例性地,对于一个名为《碟中谍》的电影文件而言,其文本描述信息可以是一段文字描述,如“中情局获得情报,得知他们的特工中出了一个叛徒,准备将中情局布置在东欧的特工名单出卖给外国特工组织。在特工头目吉姆的策划下,伊森所住的一组特工赶往了他们交易的地点。岂料,当他们按计划赶到时,却中了埋伏,一组人中除了伊森和吉姆的妻子克莱尔。这时,伊森的账户无端端多出了12万美金。伊森成了内鬼的最大的嫌疑犯”;其标签信息可以是多个词语的组合,如“震撼、冒险、剧情、特工、当代、都市、大片、暴力、逃亡、黑帮、杀戮、中成本”。
在本实施例中,首先可以从多媒体库中获取多媒体文件的文本描述信息以及标签信息,由此形成多媒体文件的文本描述信息集合和标签信息集合;然后可以对文本描述信息集合中的文本描述信息进行处理,形成包含各种词语的与文本描述信息集合相对应的用户词典,同时还可以将标签信息集合中的词语汇集在一起构成标签词典;最终,可以根据用户词典中的词语和多媒体库中的多媒体文件一起构成文本向量矩阵,同时也可以根据标签词典中的词语和多媒体库中的多媒体文件一起构成标签向量矩阵。
在本实施例中,用户词典中包括的词语可以是文本描述信息中记录的各种名词,也可以是文本描述信息中经常出现的高频词汇。所形成的文本向量矩阵中的每一行表示用户词典中的一个词语,每一列表示多媒体库中的一个多媒体文件,且行列所对应的元素值可以是简单地用0或1表示,0表示该行对应的词语没有在该列对应的多媒体文件中没有出现,1表示该行对应的词语出现在了该列对应的多媒体文件中;行列所对应的元素值还可以用该行对应的词语在该列对应的多媒体文件中出现的具体次数值表示;此外,行列所对应的元素值也可以通过该行对应的词语在该列对应的多媒体文件中的TF-IDF文本特征值表示。同样,标签向量矩阵中的每一行表示标签词典中的一个词语,每一列也表示多媒体库中的一个多媒体文件,其行列所对应的元素值也可以用0或1表示,还可以用具体出现次数或对应的TF-IDF标签特征值表示。
进一步地,根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵,包括:获取多媒体库中多媒体文件的文本描述信息集合和标签信息集合;根据所述文本描述信息集合,确定用于描述所述多媒体库中多媒体文件的高频词汇;确定所述多媒体库中每一个多媒体文件与所述高频词汇的TF-IDF文本特征值,并基于所述TF-IDF文本特征值建立与所述多媒体库对应的文本向量矩阵;确定所述多媒体库中每一个多媒体文件与所述标签信息集合中标签词汇的TF-IDF标签特征值,并基于所述TF-IDF标签特征值建立与所述多媒体库对应的标签向量矩阵。
在本实施例中,将用户词典中的词语优选为高频词汇;将文本向量矩阵中每个高频词语与每个多媒体文件的元素值优选为对应的TF-IDF文本特征值;同时也将标签向量矩阵每个标签词语与每个多媒体文件的元素值优选为对应的TF-IDF标签特征值。
具体地,在确定多媒体库中多媒体文件的文本描述信息集合和标签信息集合后,可以对文本描述信息集合中的文本描述信息进行分词处理以及去停用词处理,由此获得文本描述时常用的高频词汇,形成用户词典,其中,可以基于现有的分词方法和去停用词方法进行处理;之后还可以对标签信息集合中的标签词语进行汇集形成标签词典。
在本实施例中,可以基于TF-IDF计算公式:TF-IDFi=TFi*IDFi来获取词语ti对应的TF-IDF文体特征值或TF-IDF标签特征值。
具体地,其中,分子ni表示用户词典中第i个词语ti在多媒体文件R对应的文本描述信息中出现的频数;分母max{nk|k=(1,2,...,T)}是所有词语在多媒体文件R对应的文本描述信息中出现的最大次数,T是用户词典中的总词语数;其中,分子|D|是多媒体库对应的文件描述信息集合中包括的文件描述信息的总数;|{j:ti∈R}|是包含词语ti的文件描述信息数目,加1是为了防止该词语ti不在文件描述信息集合中导致被除数为零。
S102、根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得文本向量矩阵的文本约减矩阵以及标签向量矩阵的标签约减矩阵。
一般地,奇异值分解(Singular Value Decomposition,SVD)是线性代数中一种重要的矩阵分解,可以将一个m*n阶矩阵分解成一个m*m阶的酉矩阵与一个半正定m*n阶对角矩阵以及一个n*n阶酉矩阵的共轭转置的乘积,其中,半正定m*n阶对角矩阵中对角线上由大到小排列k个的元素值就相当于m*n阶矩阵的奇异值,且k为m*n阶矩阵的秩。
在本实施例中,可以将文本向量矩阵或标签向量矩阵看做一个m*n阶矩阵,由此可以确定与之对应的半正定m*n阶对角矩阵中对角线上的元素值,从而确定出相应的奇异值;然后可以取半正定m*n阶对角矩阵中对角线上由大到小排列k个的元素值中的前x个值,形成x*x阶的对角矩阵,其中,x小于k;之后,基于所形成x*x阶的对角矩阵,可以获得将文本向量矩阵或标签向量矩阵约减到x维后形成的文本约减矩阵或标签约减矩阵。
S103、在确定用户播放的当前多媒体文件后,根据文本约减矩阵和标签约减矩阵,确定当前多媒体文件与多媒体库中其他多媒体文件的多媒体相似度。
在本实施例中,可以认为文本约减矩阵中的列向量表示多媒体库中任一多媒体文件的文本特征向量,还可以认为标签约减矩阵中的列向量表示多媒体库中任一多媒体文件的标签特征向量。在向用户推荐多媒体资源时,可以首先确定用户此时播放的当前多媒体文件,之后,可以根据所确定的文本约减矩阵以及标签约减矩阵,来确定当前多媒体文件对应的文本特征向量及标签特征向量,由此可基于确定的文本特征向量及标签特征向量以及设定的相似度计算公式来确定当前多媒体文件与多媒体库中其他多媒体文件的多媒体相似度。
S104、根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件并推荐给用户。
在本实施例中,基于步骤S103可以确定当前多媒体文件与多媒体库中其他多媒体文件的多媒体相似度,由此确定了多媒体库中多媒体文件与当前多媒体文件存在对应的多媒体相似度值;本实施例可以对所确定的多媒体相似度值由大到小进行排序,然后选取前N个多媒体相似度值对应的多媒体文件作为待推荐资源,并将待推荐资源推荐给正在播放当前多媒体文件的用户,由此实现多媒体资源的智能推荐。需要说明的是,N的取值可以由系统默认也可以人为设定,其中,N可以优选地设定为10。
本发明实施例一提供的一种多媒体资源的推荐方法,首先建立多媒体库的文本向量矩阵和标签向量矩阵;然后对文本向量矩阵和标签向量矩阵根据进行奇异值分解获得各自的文本约减矩阵和标签约减矩阵;之后确定用户播放的当前多媒体文件,并根据文本约减矩阵和标签约减矩阵确定当前多媒体文件与其他多媒体文件的多媒体相似度,最终,根据所确定的多媒体相似度来确定作为待推荐资源的多媒体文件,并将确定的待推荐资源推荐给用户。利用该方法,实现了多媒体文件播放时相关多媒体资源的智能推荐,避免了多媒体资源推荐过程中的冷启动问题,还解决了多媒体资源推荐过程中文本同义词及一词多义对多媒体文件相似度计算的影响,从而提高了多媒体文件的匹配度,进而提高了多媒体资源推荐的准确性。
实施例二
图2为本发明实施例二提供的一种多媒体资源的推荐方法的流程示意图。本发明实施例二以上述实施例为基础进行优化,在本实施例中,将根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得所述文本向量矩阵的文本约减矩阵以及所述标签向量矩阵的标签约减矩阵,进一步优化为:根据奇异值分解公式,确定所述文本向量矩阵的第一奇异值集合以及所述标签向量矩阵的第二奇异值集合,其中,所述第一奇异值集合和第二奇异值集合中的奇异值由大到小排列;在所述第一奇异值集合中取前r个奇异值,基于所述前r个奇异值确定所述文本向量矩阵的文本约减矩阵;在所述第二奇异值集合中取前s个奇异值,基于所述前s个奇异值确定所述标签向量矩阵的标签约减矩阵,其中,r和s为设定的整数值。
此外,还将根据所述文本约减矩阵和标签约减矩阵,确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的多媒体相似度,具体优化为:根据所述文本约减矩阵确定所述多媒体数据库中多媒体文件的文本特征向量;根据所述标签约减矩阵确定所述多媒体数据库中多媒体文件的标签特征向量;基于所述多媒体数据库中多媒体文件的文本特征向量和标签特征向量,通过余弦定理分别确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的文本相似度和标签相似度;根据所述文本相似度和标签相似度,通过设定相似度计算公式确定所述当前多媒体文件与其他多媒体文件的多媒体相似度。
如图2所示,本发明实施例提供的一种多媒体资源的推荐方法,具体包括如下操作:
S201、根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与多媒体库对应的文本向量矩阵和标签向量矩阵。
示例性地,获取多媒体库中各多媒体文件对应的文本描述信息以及标签信息,形成文本描述信息集合和标签信息集合;基于分词工具对文本描述信息集合中的文本描述信息进行分词处理,比如对“伊森成了内鬼的最大的嫌疑犯”的分词结果为“伊森/内鬼/的/最大/的/嫌疑犯”,并去掉和多媒体文件描述不太相关的停用词,比如“的”,“啊”等,得到有用的高频词汇,比如,最终分词结果为“伊森/内鬼/最大/嫌疑犯”,最终形成包含所有高频词汇的用户词典,并可通过计算用户词典中每个词语与多媒体文件库中多媒体文件的TF-IDF文本特征值,形成与多媒体库对应的文本向量矩阵。同样,也可基于标签信息获得汇集所有标签词汇的标签词典,并可计算标签词典中每个词语与多媒体文件库中多媒体文件的TF-IDF标签特征值,形成与多媒体库对应的文本向量矩阵。
S202、根据奇异值分解公式,确定文本向量矩阵的第一奇异值集合以及标签向量矩阵的第二奇异值集合,其中,第一奇异值集合和第二奇异值集合中的奇异值由大到小排列。
在本实施例中,根据奇异值分解公式,可以将文本向量矩阵或标签向量矩阵分解成一个酉矩阵与一个半正定矩阵以及另一个酉矩阵的共轭转置的乘积,所确定的半正定矩阵中对角线的元素值则相当于文本向量矩阵或标签向量矩阵的奇异值,其中,可以将文本向量矩阵的所有奇异值的集合称为第一奇异值集合,还可以将标签向量矩阵的所有奇异值的集合称为第二奇异值集合。需要说明的是,第一奇异值集合以及第二奇异值集合中的奇异值由大到小排列,在与文本向量矩阵或标签向量矩阵对应的半正定矩阵中,最大的奇异值位于半正定矩阵的左上角,且沿对角线向下排列的奇异值也逐渐减小。
进一步地,所述奇异值分解公式为:Am*n=Um*m∑m*nVTn*n,其中,Am*n表示文本向量矩阵或标签向量矩阵,U是m*m阶酉矩阵,Σ是半正定m*n阶对角矩阵;而VT,即V的共轭转置,V是n*n阶酉矩阵,Σ对角线上的元素Σi,i表示为Am*n的奇异值,且Σi,i按数值大小由大到小排列。
S203、在第一奇异值集合中取前r个奇异值,基于前r个奇异值确定文本向量矩阵的文本约减矩阵。
在本实施例中,根据矩阵的加法公式以及矩阵所具有的分配率,可以通过删除矩阵对应的较小奇异值的方法对矩阵进行约减。具体地,假设文本向量矩阵的第一奇异值集合中包括k个奇异值,则可以取前r个奇异值形成r维的半正定矩阵,之后将新确定的酉矩阵与r维半正定矩阵相乘,并将其乘积再与另一个新的酉矩阵相乘,最终得到的矩阵就相当于文本向量矩阵的文本约减矩阵。
进一步地,所述文本约减矩阵表示为:Bm*n=Um*r∑r*rVTr*n,在本实施例中,r的取值优选地满足r个奇异值的奇异值之和占总奇异值之和的90%,且可认为文本向量矩阵≈文本约减矩阵。
S204、在第二奇异值集合中取前s个奇异值,基于前s个奇异值确定标签向量矩阵的标签约减矩阵,其中,r和s为设定的整数值。
具体地,与步骤S203的操作相同,假设标签向量矩阵的第二奇异值集合中包括t个奇异值,则可以取前s个奇异值形成s维的半正定矩阵,之后将新确定的酉矩阵与s维半正定矩阵相乘,并将其乘积在于另一个新的酉矩阵相乘,最终得到的矩阵就相当于标签向量矩阵的标签约减矩阵。
进一步地,所述标签约减矩阵表示为:Cm*n=Um*s∑s*sVTs*n,在本实施例中,s的取值优选地满足s个奇异值的奇异值之和占总奇异值之和的80%,且可认为标签向量矩阵≈标签约减矩阵,本实施例后续可基于文本约减矩阵以及标签约减矩阵进行多媒体文件的相似度计算。
S205、根据文本约减矩阵确定多媒体数据库中多媒体文件的文本特征向量。
在本实施例中,文本约减矩阵的列向量可看做多媒体库中其中一个多媒体文件相对于用户词典中高频词汇形成的文本特征向量,由此根据已确定的文本约减矩阵可以确定多媒体数据库中各多媒体文件对应的文本特征向量。
S206、根据标签约减矩阵确定多媒体数据库中多媒体文件的标签特征向量。
在本实施例中,与步骤S205的操作相同,标签约减矩阵的列向量可看做多媒体库中其中一个多媒体文件相对于标签词典中标签词汇形成的标签特征向量,由此根据已确定的标签约减矩阵可以确定多媒体数据库中各多媒体文件对应的标签特征向量。
示例性地,假设标签约减矩阵为m*n阶矩阵,m表示标签词典中的m个标签词汇,n表示多媒体库中的n个多媒体文件,则第i列的列向量就相当于多媒体库中第i个多媒体文件与m个标签词汇形成的标签特征向量。
S207、在确定用户播放的当前多媒体文件后,基于多媒体数据库中多媒体文件的文本特征向量和标签特征向量,通过余弦定理分别确定当前多媒体文件与多媒体库中其他多媒体文件的文本相似度和标签相似度。
在本实施例中,对用户进行多媒体资源的推荐,首先需要确定用户播放的当前多媒体文件,之后,可以计算多媒体库中其他多媒体文件与当前多媒体文件之间的多媒体相似度。
具体地,余弦定理表示为其中,D1和D2分别表示两个向量,|D1|和|D2|分别表示两个向量的模。需要说明的是,用余弦定理来表示两向量的相似度时,所确定cosθ值越接近1,则表明两向量的相似度越高,所确定cosθ值越接近1,则表明两向量的相似度越低。
在本实施例中,当前多媒体文件基于文本特征向量与多媒体库中其他任一多媒体文件的文本特征向量通过余弦定理进行相似度计算时,可将计算所得的相似度称作文本相似度,且多媒体库中其他多媒体文件与当前多媒体文件之间均存在一个文本相似度值;同样,当前多媒体文件基于标签特征向量与多媒体库中其他任一多媒体文件的标签特征向量通过余弦定理进行相似度计算时,可将计算所得的相似度称作标签相似度,且多媒体库中其他多媒体文件与当前多媒体文件之间也均存在一个标签相似度值。
S208、根据文本相似度和标签相似度,通过设定相似度计算公式确定当前多媒体文件与其他多媒体文件的多媒体相似度。
在本实施例中,在确定出当前多媒体文件与其他多媒体文件的文本相似度和标签相似度后,可以根据设定的相似度计算公式确定当前多媒体文件与其他多媒体文件的多媒体相似度。在本实施例中,相似度计算公式具体可基于文本相似度以及标签相似度的权重划分设定。
进一步地,所述设定相似度计算公式表示为:
Sim(m1,m2)=w1*Sim_1(m1,m2)+w2*Sim_2(m1,m2),其中,Sim(m1,m2)表示多媒体文件m1和多媒体文件m2之间的多媒体相似度;Sim_1(m1,m2)表示多媒体文件m1和多媒体文件m2之间的文本相似度;Sim_2(m1,m2)表示多媒体文件m1和多媒体文件m2之间的标签相似度;w1和w2表示设定的权重值,且w1大于w2。
在本实施例中,计算多媒体相似度时,文本相似度占的权重高于标签相似度所占有的权重,优选地,w1的取值可以是0.6,w2的取值可以是0.4。
S209、根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件,并推荐给用户。
示例性地,基于上述步骤,多媒体库中多媒体文件与当前多媒体文件均对应存在一个多媒体相似度的值,可以基于Top N算法对多媒体相似度的值进行降序排列,并选择前N个多媒体相似度的值对应的多媒体文件多为待推荐资源,之后将确定的待推荐资源推荐给用户,其中,待推荐资源具体可理解为与当前多媒体文件相似度较高的多媒体文件。
本发明实施例二提供的一种多媒体资源的推荐方法,具体化了约减矩阵的确定过程以及多媒体文件间相似度的确定过程。利用该方法,实现了多媒体文件播放时相关多媒体资源的智能推荐,避免了多媒体资源推荐过程中的冷启动问题,还解决了多媒体资源推荐过程中文本同义词及一词多义对多媒体文件相似度计算的影响,从而提高了多媒体文件的匹配度,进而提高了多媒体资源推荐的准确性。
实施例三
图3为本发明实施例三提供的一种多媒体资源的推荐系统的结构框图,该推荐系统适用于向用户推荐与当前播放的多媒体文件相似的其他多媒体文件的情况,可由软件和/或硬件实现,并一般集成在向用户提供多媒体播放资源的多媒体服务平台上。如图3所示,该推荐系统包括:向量矩阵确定模块31、约减矩阵确定模块32、相似度确定模块33以及资源推荐模块34。
其中,向量矩阵确定模块31,用于根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵;
约减矩阵确定模块32,用于根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得所述文本向量矩阵的文本约减矩阵以及所述标签向量矩阵的标签约减矩阵;
相似度确定模块33,用于在确定用户播放的当前多媒体文件后,根据所述文本约减矩阵和标签约减矩阵,确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的多媒体相似度;
资源推荐模块34,用于根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件并推荐给用户。
在本实施例中,该推荐系统首先通过向量矩阵确定模块31根据多媒体库中多媒体文件的文本描述信息集合和标签信息集合,建立与所述多媒体库对应的文本向量矩阵和标签向量矩阵;然后通过约减矩阵确定模块32根据奇异值分解处理所述文本向量矩阵和标签向量矩阵,获得所述文本向量矩阵的文本约减矩阵以及所述标签向量矩阵的标签约减矩阵;之后通过相似度确定模块33在确定用户播放的当前多媒体文件后,根据所述文本约减矩阵和标签约减矩阵,确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的多媒体相似度;最后通过资源推荐模块34根据所述多媒体库中多媒体文件对应的多媒体相似度,确定作为待推荐资源的多媒体文件并推荐给用户。
本发明实施例三提供的一种多媒体资源的推荐系统,实现了多媒体文件播放时相关多媒体资源的智能推荐,避免了多媒体资源推荐过程中的冷启动问题,还解决了多媒体资源推荐过程中文本同义词及一词多义对多媒体文件相似度计算的影响,从而提高了多媒体文件的匹配度,进而提高了多媒体资源推荐的准确性。
进一步地,向量矩阵确定模块31具体用于:
获取多媒体库中多媒体文件的文本描述信息集合和标签信息集合;根据所述文本描述信息集合,确定用于描述所述多媒体库中多媒体文件的高频词汇;确定所述多媒体库中每一个多媒体文件与所述高频词汇的TF-IDF文本特征值,并基于所述TF-IDF文本特征值建立与所述多媒体库对应的文本向量矩阵;确定所述多媒体库中每一个多媒体文件与所述标签信息集合中标签词汇的TF-IDF标签特征值,并基于所述TF-IDF标签特征值建立与所述多媒体库对应的标签向量矩阵。
进一步地,约减矩阵确定模块32具体用于:
根据奇异值分解公式,确定所述文本向量矩阵的第一奇异值集合以及所述标签向量矩阵的第二奇异值集合,其中,所述第一奇异值集合和第二奇异值集合中的奇异值由大到小排列;在所述第一奇异值集合中取前r个奇异值,基于所述前r个奇异值确定所述文本向量矩阵的文本约减矩阵;在所述第二奇异值集合中取前s个奇异值,基于所述前s个奇异值确定所述标签向量矩阵的标签约减矩阵,其中,r和s为设定的整数值。
在上述实施例的基础上,所述奇异值分解公式为:Am*n=Um*m∑m*nVTn*n,其中,Am*n表示文本向量矩阵或标签向量矩阵,U是m*m阶酉矩阵,Σ是半正定m*n阶对角矩阵;而VT,即V的共轭转置,V是n*n阶酉矩阵,Σ对角线上的元素Σi,i表示为Am*n的奇异值,且Σi,i按数值大小由大到小排列;所述文本约减矩阵表示为:Bm*n=Um*r∑r*rVTr*n;所述标签约减矩阵表示为:Cm*n=Um*s∑s*sVTs*n。
进一步地,相似度确定模块33具体用于:
在确定用户播放的当前多媒体文件后,根据所述文本约减矩阵确定所述多媒体数据库中多媒体文件的文本特征向量;根据所述标签约减矩阵确定所述多媒体数据库中多媒体文件的标签特征向量;在确定用户播放的当前多媒体文件后,基于所述多媒体数据库中多媒体文件的文本特征向量和标签特征向量,通过余弦定理分别确定所述当前多媒体文件与所述多媒体库中其他多媒体文件的文本相似度和标签相似度;根据所述文本相似度和标签相似度,通过设定相似度计算公式确定所述当前多媒体文件与其他多媒体文件的多媒体相似度。
在上述实施例的基础上,所述设定相似度计算公式表示为:
Sim(m1,m2)=w1*Sim_1(m1,m2)+w2*Sim_2(m1,m2),其中,Sim(m1,m2)表示多媒体文件m1和多媒体文件m2之间的多媒体相似度;Sim_1(m1,m2)表示多媒体文件m1和多媒体文件m2之间的文本相似度;Sim_2(m1,m2)表示多媒体文件m1和多媒体文件m2之间的标签相似度;w1和w2表示设定的权重值,且w1大于w2。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!