一种基于支持向量机的情感分类方法与流程
本发明涉及支持向量机和舆情分析技术,尤其涉及一种基于支持向量机的情感分类方法。
背景技术:
随着互联网的快速发展,互联网上的数据呈现爆炸式增长。据不完全统计,1分钟内,Twitter上新增的微博达10万条。而在国内,新浪微博用户数6.5亿,日活跃用户达4600万,腾讯微博用户数6.2亿,日活跃用户约1亿;不仅如此,传统的论坛网站中有价值的信息大约在1年1亿条左右。如此庞大的活跃用户及其所发布的内容丰富、情感鲜明的评论背后,隐藏着众多有价值的信息。对这些信息的分析,可以帮助发现评论者对特定主体的情感,例如:微博/论坛用户对于企业“正面”或“负面”的评价,对于社会群体事件的观点等,从而帮助人们掌握舆论导向,分析问题缘由等。然而,对评论文本进行分类,并发现用户的情感偏好是一项具有挑战性的工作,例如:某用户A发表了“注意冒充电信工作人员的女骗子”的帖子,用户B回复说“老人的钱好骗。”如果不考虑文本的场景,仅对句子本身进行情感判别,往往会取得不一致的判断结果。为此,我们研发了一种基于支持向量机的情感分类方法,用于对用户发表在微博、论坛里的文本信息进行分类,进而分析针对特定主体的舆情状况。
技术实现要素:
针对现有技术存在的不足之处,本发明的目的在于提供一种基于支持向量机的情感分类方法,能够准确地对用户在微博、论坛所发表的评论信息根据用户的情感进行分类,进而发现舆情状况。
本发明的目的通过下述技术方案实现:
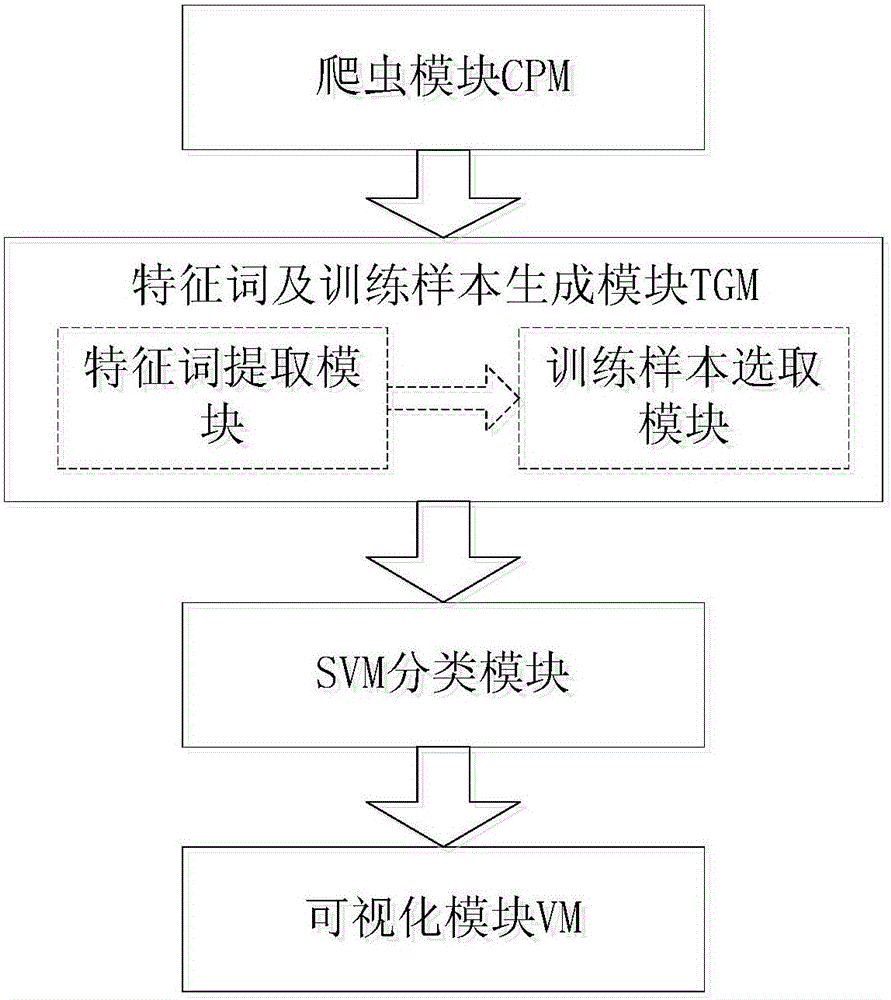
一种基于支持向量机的情感分类方法,包括情感分类系统,所述情感分类系统包括依次通信连接的爬虫模块CPM、特征词及训练样本生成模块TGM、SVM分类模块和可视化模块VM,所述特征词及训练样本生成模块TGM包括特征词提取模块和训练样本选取模块;采用情感分类系统的情感分类方法如下:
A、爬虫模块CPM数据采集流程方法如下:
A1、爬虫模块CPM从指定的站点开始以宽度优先的模式爬取网页,所述站点为起始网站;
A2、爬虫模块CPM针对每一个获取到的网页,对其页面源代码进行解析,获取网页内相关的信息,所述信息包括用户评论信息;
A3、所述爬虫模块CPM包括数据库,所述爬虫模块CPM将步骤A2中所获取到的信息数据写入数据库中;
爬虫模块CPM的数据采集及预处理:利用网络爬虫对微博,论坛进行数据爬取,获取用户所发表的评论信息;对评论信息进行预处理,主要的处理流程为:依托自然语言处理技术,对评论文本进行分词并标注词性等。
B、特征词及训练样本生成模块TGM对数据库中的特征词和训练样本选取流程方法如下:
B1、特征词的选取:情感分类系统支持向量机对评论文本进行分类,所述特征词及训练样本生成模块TGM的特征词提取模块采用算法FindCover来选取典型的特征词;所述特征词及训练样本生成模块TGM选取词性为名词(n),动词(v)和形容词(a)的词语作为特征词,即FindCover算法的输入P为数组{n,v,a};此外在实际计算中,所述特征词及训练样本生成模块TGM选取长度l〉1的词语作为特征词;
算法FindCover
输入:已分词并标注词性的评价文本集合U,特征词个数n,特征词长度l,词性集合P
输出:特征词组
①.初始化集合S,A;
②.计算映射关系Map M,将每个词语word映射到一组包含该word的文本id:M(word);
③.当S未包含n个词语时
④.寻找词语word,使其(i)词性满足P的要求,(ii)长度满足l的要求,(iii)当前的覆盖率coverage=|M(word)-A|最大;
⑤.如果寻找到的word的覆盖率coverage=0
⑥.则终止循环;
⑦.否则
⑧.将word加入S;将M(word)加入A;
⑨.返回S作为特征词组;
B2、训练样本的选取:所述特征词及训练样本生成模块TGM的训练样本选取模块采用以下策略选取训练样本:
首先,输出所有包含特征词的评价文本集合Uf;若|Uf|>1%|U|,则从Uf中随机选择1%|U|个评价文本作为训练样本;否则输出Uf作为训练样本;
其次,选定的训练样本将进行人工情感标注;实际使用过程中,可以将文本根据情感分成2类,即:正面,负面;也可分成三类,即正面,中性,负面;
特征词及训练样本生成模块TGM的特征词及训练样本生成:以经过预处理的评论文本作为输入,选取带有特定词性的高频词作为特征词,并加入特征辞典;选取包含特征词的评价文本作为训练样本,并对训练样本的情感进行人工标注。
C、SVM分类模块分类方法如下:
所述SVM分类模块首先根据步骤B中的特征词将样本数据中的文本转换为形如:“<标记>=特征1:个数;特征2:个数;……特征n:个数”的格式,其中若采用三分法,则<标记>可以取值为positive,negative或neutral;若采用二分法,则<标记>可以取值为positive和negative;所述SVM分类模块随后将转换好的训练数据输入到LIBSVM库中进行分类训练;
SVM分类模块的文本分类:以特征辞典为基础,对训练样本提取特征向量,输入支持向量机生成分类模型;利用分类模型对待分类的评价文本的情感值进行计算,实现分类。
D、可视化模块VM将分析结果在Web端进行展现:
所述可视化模块VM将步骤C中的分析结果在Web端进行展现,主要可视内容包括:a、基于特定关键词的文本的“正面”、“负面”、“中性”的比例;b、情感相关的原始文本;c、按时间维度展现文本的情感变化。
本发明较现有技术相比,具有以下优点及有益效果:
(1)本发明能够准确地对用户在微博、论坛所发表的评论信息根据用户的情感进行分类,进而发现舆情状况。
(2)本申请利用爬虫模块获取用户发表在论坛的评论信息,通过对数据进行分词等预处理,得到评论文本的特征词组以及具有典型性的训练数据,随后对训练数据进行情感标注,并利用支持向量机对训练数据进行计算,得到分类模型;接着依据分类模型,对待分类的评价文本进行分析,得到预计的情感状态;最后利用可视化模块,展示分类结果,帮助用户快速了解基于不同实体对象(关键字)的用户情感,并进而了解互联网舆情。
附图说明
图1为本发明的结构示意图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明:
实施例
如图1所示,一种基于支持向量机的情感分类方法,包括情感分类系统,所述情感分类系统包括依次通信连接的爬虫模块CPM、特征词及训练样本生成模块TGM、SVM分类模块和可视化模块VM,所述特征词及训练样本生成模块TGM包括特征词提取模块和训练样本选取模块;采用情感分类系统的情感分类方法如下:
A、爬虫模块CPM数据采集流程方法如下:
A1、爬虫模块CPM从指定的站点开始以宽度优先的模式爬取网页,所述站点为起始网站;
A2、爬虫模块CPM针对每一个获取到的网页,对其页面源代码进行解析,获取网页内相关的信息,所述信息包括用户评论信息等;
A3、所述爬虫模块CPM包括数据库,所述爬虫模块CPM将步骤A2中所获取到的信息数据写入数据库中;
数据预处理的主要流程为利用中科院研发的中文分词工具包对用户的评价文本进行分词,并标注词性。
B、特征词及训练样本生成模块TGM对数据库中的特征词和训练样本选取流程方法如下:
B1、特征词的选取:情感分类系统支持向量机对评论文本进行分类,因此提取一组具有代表性的特征词,并在此基础上选取高质量的训练样本是保证分类质量的关键。所述特征词及训练样本生成模块TGM的特征词提取模块采用算法FindCover来选取典型的特征词;所述特征词及训练样本生成模块TGM选取词性为名词(n),动词(v)和形容词(a)的词语作为特征词,即FindCover算法的输入P为数组{n,v,a};此外在实际计算中,所述特征词及训练样本生成模块TGM选取长度l〉1的词语作为特征词;
算法FindCover
输入:已分词并标注词性的评价文本集合U,特征词个数n,特征词长度l,词性集合P
输出:特征词组
①.初始化集合S,A;
②.计算映射关系Map M,将每个词语word映射到一组包含该word的文本id:M(word);
③.当S未包含n个词语时
④.寻找词语word,使其(i)词性满足P的要求,(ii)长度满足l的要求,(iii)当前的覆盖率coverage=|M(word)-A|最大;
⑤.如果寻找到的word的覆盖率coverage=0
⑥.则终止循环;
⑦.否则
⑧.将word加入S;将M(word)加入A;
⑨.返回S作为特征词组;
B2、训练样本的选取:所述特征词及训练样本生成模块TGM的训练样本选取模块采用以下策略选取训练样本:
首先,输出所有包含特征词的评价文本集合Uf;若|Uf|>1%|U|,则从Uf中随机选择1%|U|个评价文本作为训练样本;否则输出Uf作为训练样本;
其次,选定的训练样本将进行人工情感标注;实际使用过程中,可以将文本根据情感分成2类,即:正面,负面;也可分成三类,即正面,中性,负面;
C、SVM分类模块分类方法如下:
所述SVM分类模块首先根据步骤B中的特征词将样本数据中的文本转换为形如:“<标记>=特征1:个数;特征2:个数;……特征n:个数”的格式,其中若采用三分法,则<标记>可以取值为positive,negative或neutral;若采用二分法,则<标记>可以取值为positive和negative;所述SVM分类模块随后将转换好的训练数据输入到LIBSVM库中进行分类训练;
在得到训练结果后,STM应用这些分类规则对待分类的文本进行计算,分析文本的情感取向。
D、可视化模块VM将分析结果在Web端进行展现:
所述可视化模块VM将步骤C中的分析结果在Web端进行展现,主要可视内容包括:a、基于特定关键词的文本的“正面”、“负面”、“中性”的比例;b、情感相关的原始文本;c、按时间维度展现文本的情感变化。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!