一种智能视频识别方法及系统与流程
本发明涉及视频领域,特别涉及一种采用计算机图形图像处理以及模式识别技术的智能视频识别方法及系统。
背景技术:
视频识别是基于视频图像特征信息进行识别的一种识别技术,近年来已经在一些领域取得了应用,例如视频识别可以应用于门禁系统、考勤系统、智能手机等等。
在视频识别技术中,主要有两个步骤:从待识别视频图像中提取特征向量;将特征向量与数据库中图像的特征向量进行对比获得识别结果。其中,第一个步骤直接影响视频识别结果的准确性。在现有技术中,视频识别算法很多,但都无法保证适应于所有样本,从而影响视频识别的准确性。
局部二值模式(Local Binary Pattern,LBP)由Ojala提出,在图像局部邻域内度量像素值大小并提取纹理信息,对光照变化具有鲁棒性。其计算简便、抗光照干扰、判别能力强,被广泛应用于光照变化下的人脸识别。但当光照剧烈变化时,LBP无法表示变化的剧烈程度,因此可靠性大幅下降,在此基础上Tan等人又提出了局部三值模式(Local Ternary Pattern,LTP)。
LTP算子对LBP算子进行改进,采用三值编码,以提高整个特征空间的分类能力。在一个3×3的窗口,自定义阈值t,将邻域内像素与中心像素进行比较,像素差值被映射在gc量化为0、宽度为[-t,+t]的区域内,差值大于该区间编码为+1,差值小于该区间编码为-1,差值在区间范围内编码为0。这样,在邻域内可产生一个8位的二进制有符号数,再按其位置赋予不同权重,并对其求和即得到该窗口的局部三值模式(LTP)特征值,用这个数描述该区域的纹理信息。
通过对LBP的研究与改进,LTP解决了光照剧烈变化下的识别问题,对剧烈变化的成像条件(如噪声等)具有鲁棒性。但LTP自身采用自定义阈值,需根据先验知识找寻、设定最佳阈值,时效性会受影响,同时,阈值无法兼顾样本间的差异,还存在普适性问题。因此,需要采用新的算子以提高对视频图像识别的识别率,阈值的优化成为一个可取的方向。
在政务、民生、环境、公共安全、城市服务、工商活动、商场、银行、海关、军事禁区等场景中对于人物或者背景的动态识别对于智能城市的建设存在着内在的动力需求。
视频识别技术是计算机图像处理、图形构造、模式识别、计算机可视化和认知科学等多个技术和领域的复合技术。视频识别技术由于其数据的复杂性和采集、处理技术的困难,其还远远没达到应用的要求。
技术实现要素:
本发明的目的是通过以下技术方案实现的。
本发明提出了一种视频识别系统,所述视频识别系统包括如下功能模块:
视频采集设备,用于对采集对象进行视频图像的采集;
视频图像定位模块,用于获取视频图像后对视频从五官到轮廓的位置建模,确定采集对象的位置与要比对的图像位置相匹配;
图像预处理模块:确定好视频位置后,对图像数据进行预处理,调整图像数据,优化比对效果;
提取图像特征模块,根据算法要求,把预处理好的图像中需要的数据提取出来;
检索数据库,用于获取视频图像训练集,把提取的数据和数据库中视频图像训练集需要认证的数据进行比对
结果显示模块,反馈系统处理结果,根据结果作进一步处理。
根据本发明的一个方面,所述检索数据库进一步用于,确定视频图像的训练集,根据总体复散度矩阵,通过奇异值分解的方法求出一组正交的特征向量。
根据本发明的一个方面,所述提取图像特征模块进一步用于,对于任一幅待识别的视频图像It通过式yk=ETIt,提取其特征。
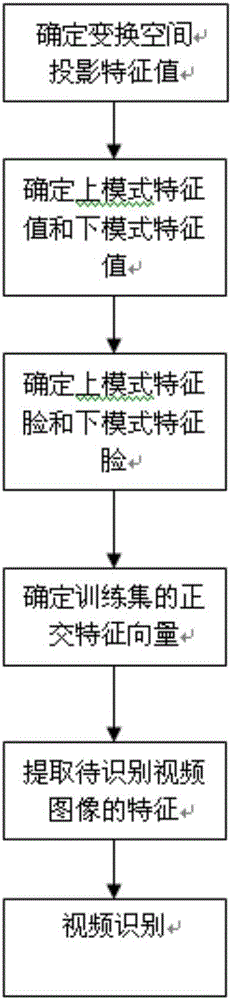
本发明还提出了一种视频识别的方法,其特征在于,包括如下步骤:
步骤一、确定待识别视频图像中的变换空间投影特征值;
步骤二、根据变换空间投影特征值确定上模式特征值以及下模式特征值;
步骤三、确定上模式特征脸以及下模式特征脸,上模式特征脸由每个像素点上模式特征值组成,下模式特征脸由每个像素点下模式特征值组成;
步骤四:确定视频图像的训练集,根据总体复散度矩阵,通过奇异值分解的方法求出一组正交的特征向量;
步骤五、对于任一幅待识别的视频图像It通过式yk=ETIt,提取其特征;
步骤六、采用欧氏距离的最近邻分类器进行视频识别,如果识别的结果等于最小值,则待识别视频图像It与训练图像Ir属于同一类对象。
根据本发明的一个方面,所述步骤四中,将图像在高维空间的表示转换为其在相应低维空间的特征数据,实现对图像特征的提取。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
附图1示出了根据本发明实施方式的智能视频识别系统示意图。
附图2示出了根据本发明实施方式的智能视频识别方法示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施方式。虽然附图中显示了本公开的示例性实施方式,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
视频识别是一种利用视频图像的视觉特征信息进行身份识别的生物特征识别技术。视频识别与其他传统生物识别技术相比,具有便于采集、方便快捷、交互友好等优点,已逐渐被大众接受。
视频识别的几种算法包括:
1、模板匹配算法(Correlationalgorithm):通过获取视频图像直接计算图像位置的向量之间的距离来衡量视频图像是否相似。简单的说就是获取视频最基本、直观的特征(如耳朵,鼻子,脸型)来进行相似度的比较,是视频识别的基准算法。此算法识别速度快,占用系统内存小但是准确率低,不适宜高识别要求的系统。
2、特征脸算法:该算法由基于主成分分析(PCA)方法,在特征脸算法的基础上进行优化可以使算法更有效,是视频图像对比测试时的基准识别算法。
3、Fisher脸算法:线性鉴别分析方法是从高维空间中提取出最具有分类能力的低维特征,投影后的特征数据,在低维空间里不同类别的样本尽可能分得开些,同时希望每个类别的样本尽可能密集,也就是说,样本类间离散度越大越好,而类内离散度越小越好。
4、基于Gabor特征的算法:特征脸和Fisher脸算法采用图像中灰度进行特征分析。而基于Gabor特征的算法可以从多个角度来对图像灰度进行分析,模拟哺乳动物皮质细胞区域剖面,并且对于光照的适应性比特征脸和Fisher脸算法好。视频识别算法的选择要考虑到视频数据采集环境,采集设备条件,图像数据处理优化等客观条件,并不是所有算法都适合所要建立的系统。
为便于说明本发明实施例提供的智能视频识别方法及装置,先对本发明实施例中涉及到的视频识别算法中的各种场景和技术储备进行简单介绍。
图像采集可以采用摄像头作为图像传感器,通过摄像头抓取或者直接从硬盘上选取一张人脸图像,然后将人脸图像数据源存储到数据库中。
图像预处理可以包括灰度变换、二值变换、降噪处理,然后利用基于Adaboost的方法进行视频的检测及定位,若检测到有效视频,则保存于数据库之中。
灰度变换用0~255表示每一点的灰色程度,0为黑色,255为白色。RGB颜色空间直接通过线性变化,将R、G、B三分量依次进行处理,RGB通过公式以下转换为灰度图:Gray=0.299*R+0.587*G+0.114*B。
二值变换将0-1图像的序列转化成255-0的图像序列。
勒比算子是一种灰度范围内描述图像纹理特征的算子,主要用来辅助提取图像局部区域的对比度特征。勒比算子是以中心像素点的灰度值作为阈值,在中心像素点的邻域内进行采样,例如取3×3的邻域,则将与中心像素点相邻的8个像素点的灰度值与阈值进行比较,若相邻像素点灰度值大于阈值(即中心像素点灰度值),则该像素位置被标记为1,否则标记为0。这样可以产生一个8位二进制数,将8位二进制数转换为十进制数,作为中心像素点的LBP特征值,由于8位二进制数转换得到的十进制数取值范围为0-255,因此特征值取值范围即为0-255。如果给出一个求勒比特征值的具体实例,中心像素点的像素灰度值为9,邻域像素灰度值与中心像素灰度值进行比较,得到8位二进制数01000111,转换为十进制数71作为勒比特征值。
但是,勒比算子只比较灰度值的大小而忽略了像素间的对比度值,当邻域内的像素灰度值在保持大小关系的前提下变化时,勒比编码结果保持不变。因此,勒比算子无法描述非线性变化前后的差异,最终可能导致部分重要的纹理特征被丢弃。
倜肶算子是对勒比算子的改进,采用三值编码,以提高整个特征空间的分类能力。用户自定义一个阈值t,极大的增强了对噪声的敏感,在一定程度上均衡了剧烈光照引起的高光、亮光区域的灰度值。具体的倜肶算子运算过程为当邻域像素点灰度值与中心像素点灰度值的差值大于等于t,该像素位置被标记为1,邻域像素点灰度值与中心像素点灰度值的差值小于-t,该像素位置被标记为-1,否则标记为0。为了简化计算,倜肶的编码过程可以分解为正值计算部分和负值计算部分,正值和负值每个部分分别应用勒比算子计算的方法。分解计算过程参见图2所示,提取“+1”的编码结果记为“1”其余记为“0”,通过勒比编码方式得到上模式特征;提取“-1”的编码结果记为“1”其余记为“0”,通过勒比编码方式得到下模式特征。这样经过倜肶特征提取变换后,整个特征空间样本的表征和分类性能得到进一步增强和提高。
视频识别系统的实现视频识别需要完善的软、硬件程序。根据本发明的一个实施方式,智能视频识别系统配置如图1所示,包括如下组成部分:
视频采集设备:对采集对象进行面部图像的采集,一般需要对象不佩戴装饰物(如眼镜、帽子等)保证采集图像的完整性。采集视频需要符合系统要求的光照、拍摄角度、背景等客观条件。
视频图像定位模块:获取图像后对视频从五官到轮廓的位置建模,确定采集对象的位置与要比对的图像位置相匹配。
图像预处理模块:确定好视频位置后,对图像数据进行预处理,调整图像数据,优化比对效果。
提取图像特征模块:根据算法要求,把预处理好的图像中需要的数据提取出来。
检索数据库:用于获取视频图像训练集,把提取的数据和数据库中视频图像训练集需要认证的数据进行比对。
结果显示模块:反馈系统处理结果,根据结果作进一步处理。
假设视频图像的训练集为C。C共有m个视频对象,每个对象均有n幅视频图像。注意每幅图像都包含了深数据(用depth表示)和灰数据(用intn表示)。虚数单位用i表示,则第k幅(1≤k≤n×m)高清视频图像Ik可以表示为:
Ik=depthk+int nk×i (1)
根据本发明的一个实施方式,本发明提出了一种动态识别的视频检测方法。
首先,全部训练集图像复数域下的均值可以表示为:
式中:Ip_q表示训练集中第p个对象的第q张图像。
视频训练集C的总体复散度矩阵S为:
式中:Ik为第k个训练图像,为训练样本的平均值,n×m为训练集的规模。
根据总体复散度矩阵,通过奇异值分解的方法求出一组正交的特征向量:u1,u2,…,ut和其对应的特征值:λ1,λ2,…,λt,其中λ1≥λ2≥…≥λt。选用前d(d<t)个非零特征值对应的特征向量作为正交基。d称为特征维数N。将正交基按图像阵列排列,所得到的图像称为特征脸。在特征脸张成的子空间E中,视频样本Ik就可以投影为yk。通过这样的办法,将一幅图像在高维空间的表示转换为其在相应低维空间的特征数据,实现了对图像特征的提取:
yk=ETIk (4)
经过上述的特征提取,每个训练视频图像都对应一个d×1维的列向量以保存其特征信息。训练集共有m×n张图像,所以最终得到矩阵Y={y1,y2,…,ym×n}
保存所有训练图像的特征信息。任一幅待识别的视频图像It也可通过式(4),提取其的特征,并保存为yt。采用欧氏距离的最近邻分类器,定义:
如果满足:
Dist(yt,yr)=min[Dist(yt,yc)]yc∈Y (6)
则yt,yr属于同一类对象。即待识别视频图像It与训练图像Ir属于同一类对象。
在上述动态识别的视频检测方法的基础上,根据本发明的一个实施方式,提出了一种智能视频识别方法,如图2所示,所述方法包括如下步骤:
步骤一、确定待识别视频图像中的变换空间投影特征值;
每幅图像相应的变换空间投影特征值由该图像中各像素点以及该像素点邻域内各个像素点的灰度差值确定。
步骤二、根据变换空间投影特征值确定上模式特征值以及下模式特征值;
用于进行视频识别的待识别视频图像采用灰度图像,首先根据待识别视频图像中每个像素点及该像素点邻域内像素点的灰度值确定该像素点的自适应阈值,再利用倜肶算子计算该像素点的特征值时采用该像素点的自适应阈值作为倜肶算子的阈值进行计算,即采用具有自适应阈值的倜肶算子确定待识别视频图像中每个像素点的倜肶自适应阈值特征值。
在本发明的一些实施例中,确定待识别视频图像中每个像素点的倜肶自适应阈值特征值的具体实现可以包括:
遍历待识别视频图像中的每个像素点,确定遍历到的当前像素点预设邻域内每个像素点的灰度值与当前像素点的灰度值的灰度差。
计算多个灰度差值的标准差作为当前像素点相应的自适应阈值。
将当前像素点相应的自适应阈值作为倜肶算子的阈值,采用具有自适应阈值的倜肶算子确定当前像素点的倜肶特征值,当前像素点的倜肶特征值为当前像素点的倜肶自适应阈值特征值。
一般预设邻域可以取3×3的邻域块,则除去中心像素点后有8个相邻像素点,分别计算这8个相邻像素点与中心像素点的灰度差,由求得的这组8个灰度差值可以计算出这组灰度差的标准差作为当前像素点相应的自适应阈值,再利用倜肶算子计算当前像素点的倜肶特征值。
在本发明的一些实施例中,本发明实施例提供的视频识别方法还可以包括:将待识别倜肶图像进行预处理并划分为均等的多块;这样可以采用具有自适应阈值的局部三值模式倜肶算子逐块计算每个像素点的倜肶自适应阈值特征值。
步骤三、确定上模式特征脸以及下模式特征脸,上模式特征脸由每个像素点上模式特征值组成,下模式特征脸由每个像素点下模式特征值组成。
像素点上模式特征值的取值范围为0-255,下模式特征值的取值范围也为0-255,这样,将像素点的灰度值替换为对应的上模式特征值或者下模式特征值,可以分别确定上模式特征脸图像以及下模式特征脸图像。一幅待识别视频图像可以转换为上模式特征脸以及下模式特征脸。
步骤四:确定视频图像的训练集,根据总体复散度矩阵,通过奇异值分解的方法求出一组正交的特征向量;
对于上述所获得的正交特征向量,每个训练视频图像都对应一个d×1维的列向量以保存其特征信息。
步骤五、对于任一幅待识别的视频图像It通过式yk=ETIt,提取其特征;
步骤六、采用欧氏距离的最近邻分类器进行视频识别,如果识别的结果等于最小值,则待识别视频图像It与训练图像Ir属于同一类对象。
目前的视频识别多为静态识别,也就是说人必须站在一个固定的位置上进行识别,这样的识别技术存在着识别速度慢,使用范围窄的问题。在很多重要的场合都无法满足社会的要求。根据本发明实施例的动态视频识别能够实现人在路上走,摄像机随机抓取视频图像进行快速识别的技术效果。
根据本发明所述的视频识别方法,能够从动态视频图像中的多个目标中快速的识别出想要识别的对象。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!