词语相似度计算方法及装置与流程
本发明属于自然语言处理技术领域,尤其涉及一种词语相似度计算方法及装置。
背景技术:
词语相似度计算在自然语言处理、智能检索、文本聚类、文本分类、自动应答、词义排歧和机器翻译等领域都有广泛的应用,它是自然语言的基础研究课题,正在被越来越多的研究人员所关注。目前,最常用的词语相似度计算方法是基于语义词典的词语相似度计算。常用的语义词典:在英文方面,具有代表性的有WordNet,FrameNet,Mi ndNet等;在汉语方面,有“知网”(HowNet),“同义词词林”,“中文概念词典”(CCD:Chinese Concept Dictionary)等。该算法即根据同义词词林的编排及语义特点计算两个词语之间的相似度。
在传统的语义词典构建过程中,获取词语相似度的方法通常是人工标注。这种方法的主要缺陷有以下三点:
1、为保证语义词典标注准确性,需要对每一位参加标注的工作人员进行大量的领域相关知识和标注规范的培训,这些培训将消耗大量的时间和资金;同时由于缺乏词语相似度的系统标注规范,在培训结束后也很难保证标注人员能准确高效地对词语相似度语料进行标注。
2、由于标注者常常具有不同的语言认识,这将导致不同标注者对同一语料标注时会出现不同甚至是相反的结果。出现这种情况时,通常需要标注者一起讨论决定最终的标注结果,这一过程往往会消耗标注人员大量的时间与精力,最终会严重拖慢标注进程。
3、由于人类语言理解机制的复杂性,标注者往往很难对自然语言中的词语对准确地判别其相似度,这通常表现在同一标注者在不同时间标注同一语料时也会出现前后矛盾的情况。
技术实现要素:
本发明的目的在于提供一种词语相似度计算方法及系统,旨在提高词语相似度计算的准确性。
本发明是这样实现的,一种词语相似度计算方法,所述方法包括以下步骤:
步骤S1,收集未标注的词典,对所述词典中的词语进行处理,得到待标注词语对;
步骤S2,将所述待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读所述待标注词语对时的脑电信号;
步骤S3,对采集到的脑电信号进行处理,基于处理后的脑电信号对相应的词语对进行相似度标注,构建基于脑电信号标注的词语相似度语料库。
本发明的进一步的技术方案是,所述步骤S1包括:
选取已有的词典中的词语为待标注词语,对所述待标注词语进行一对一组合构成待标注词语对。
本发明的进一步的技术方案是,所述步骤S2包括:
将同一词语对多次间隔呈现给标注者,供标注者阅读,采集标注者每次阅读所述同一词语对时的脑电信号,将采集到的标注者每次阅读所述同一词语对时的脑电信号与相应的词语对成对存储。
本发明的进一步的技术方案是,所述步骤S3包括以下子步骤:
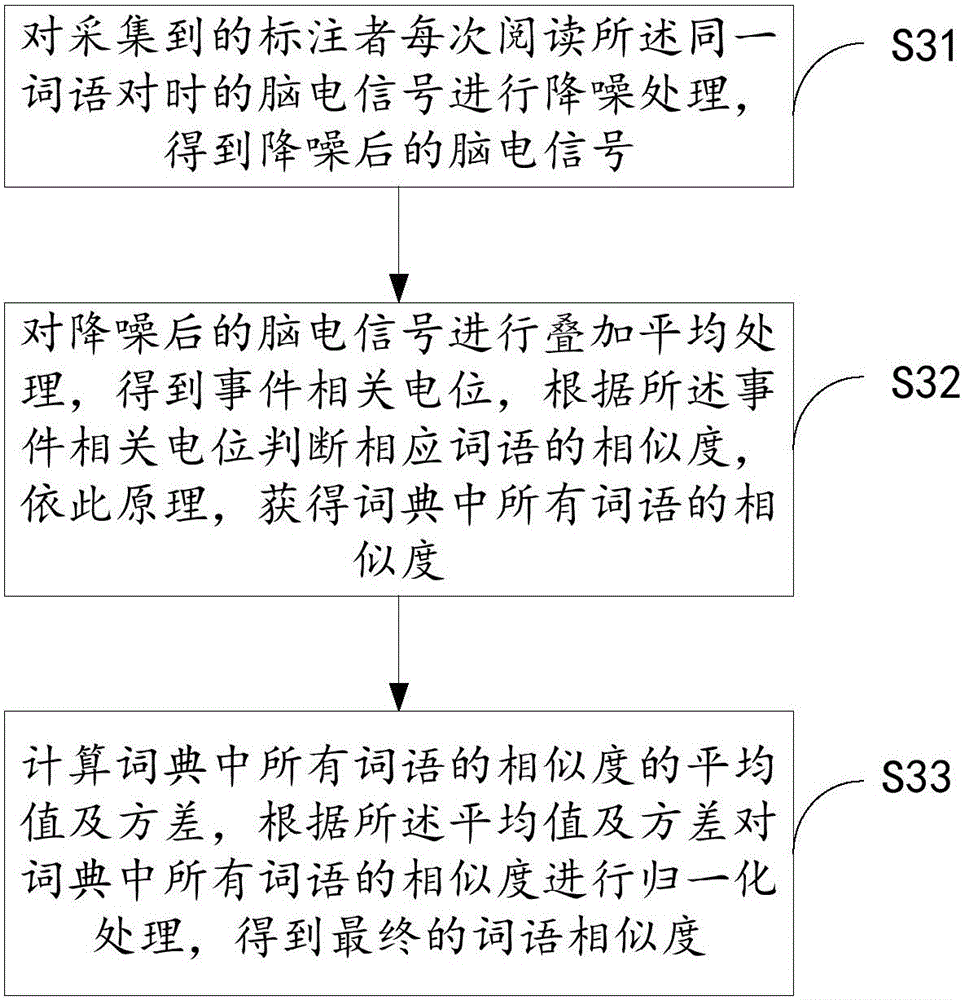
步骤S31,对采集到的标注者每次阅读所述同一词语对时的脑电信号进行降噪处理,得到降噪后的脑电信号;
步骤S32,对所述降噪后的脑电信号进行叠加平均处理,得到事件相关电位,根据所述事件相关电位判断所述词语对的相似度,依此原理,获得词典中所有词语对的相似度;
步骤S33,计算词典中所有词语对的相似度的平均值及方差,根据所述平均值及方差对词典中所有词语对的相似度进行归一化处理,得到最终的词语相似度。
本发明的进一步的技术方案是,所述步骤S31中采用FASTICA算法对采集到的标注者每次阅读所述同一词语对时的脑电信号进行降噪处理,得到降噪后的脑电信号。
本发明还提供了一种词语相似度计算装置,所述装置包括:
收集模块,用于收集未标注的词典,对所述词典中的词语进行处理,得到待标注词语对;
采集模块,用于将所述待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读所述待标注词语对时的脑电信号;
构建模块,用于对采集到的脑电信号进行处理,基于处理后的脑电信号对相应的词语对进行相似度标注,构建基于脑电信号标注的词语相似度语料库。
本发明的进一步的技术方案是,所述收集模块还用于:
选取已有的词典中的词语为待标注词语,对所述待标注词语进行一对一组合构成待标注词语对。
本发明的进一步的技术方案是,所述采集模块还用于:
将同一词语对多次呈现给标注者,供标注者阅读,采集标注者每次阅读所述同一词语对时的脑电信号,将采集到的标注者每次阅读所述同一词语对时的脑电信号与相应的词语对成对存储。
本发明的进一步的技术方案是,所述构建模块包括:
降噪单元,用于对采集到的标注者每次阅读所述同一词语对时的脑电信号进行降噪处理,得到降噪后的脑电信号;
叠加平均处理单元,对所述降噪后的脑电信号进行叠加平均处理,得到事件相关电位,根据所述事件相关电位判断所述词语对的相似度,依此原理,获得词典中所有词语对的相似度;
归一化处理单元,计算词典中所有词语对的相似度的平均值及方差,根据所述平均值及方差对词典中所有词语对的相似度进行归一化处理,得到最终的词语相似度。。
本发明的进一步的技术方案是,所述降噪单元还用于采用FASTICA算法对所述采集到的脑电信号进行降噪处理。
本发明的有益效果是:本发明提供的词语相似度计算方法及装置,通过上述方案:收集未标注的词典,对所述词典中的词语进行处理,得到待标注词语对;将所述待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读所述待标注词语对时的脑电信号;对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库,提高了词语相似度计算的准确性。
附图说明
图1是本发明本发明词语相似度计算方法较佳实施例的流程示意图;
图2是本发明词语相似度计算方法步骤S3的细化流程示意图;
图3是本发明词语相似度计算装置较佳实施例功能模块示意图;
图4是本发明词语相似度计算装置构建模块的细化功能模块示意图。
附图标记:
收集模块-10;
采集模块-20;
构建模块-30:降噪单元-301;叠加处理单元-302;归一化处理单元-303。
具体实施方式
本发明实施例的解决方案主要是:收集未标注的词典,对词典中的词语进行处理,得到待标注词语对;将待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读待标注词语对时的脑电信号;对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库。
请参照图1,图1是本发明词语相似度计算方法较佳实施例的流程示意图,如图1所示,本发明词语相似度计算方法较佳实施例包括以下步骤:
步骤S1,收集未标注的词典,对词典中的词语进行处理,得到待标注词语对;
目前常用的词典有《现代汉语词典》、《现代汉语规范词典》以及《汉语大辞典》等,为了得到词语相似度,本实施例首先将词典中的词语进行一对一组合,构成待标注的词语对。其中待标注的词语对的个数计算公式为:M=N×(N-1)÷2,其中,M为词语对的个数,N为词典中词语的个数。
步骤S2,将待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读待标注词语对时的脑电信号;
目前,获取词语相似度的方法通常是采用人工标注的方法,采用人工标注的方法获取词语相似度,不仅会消耗大量的时间和资金,并且在不同的时间标注同一语料是也会出现前后矛盾的情形。而采用脑电信号计算词语相似度能从认知神经科学的角度真实反映标注者的情绪,具有很高的准确性。
因此,本发明在计算词语相似度时需要标注者佩戴脑电采集装置,采集标注者阅读待标注词语对时的脑电信号。其中,标注者为佩戴脑电采集装置阅读待标注词语对的用户。
步骤S3,对采集到的脑电信号进行处理,基于处理后的脑电信号对相应的词语进行相似度标注,构建基于脑电信号标注的词语相似度语料库。
由于在采集标注者阅读待标注词语对的脑电信号的过程中,容易受到设备噪音、肌点噪音以及眼电噪音等的影响,所以在采集到标注者阅读待标注词语对是的脑电信号后,需要对所采集到的脑电信号进行降噪处理,以提高词语相似度计算的准确性。
具体实施时,为了进一步提高词语相似度计算的准确性,可以将同一词语对多次间隔呈现给标注者,供标注者阅读,将采集到的标注者每次阅读所述同一词语对时的脑电信号与相应的词语对成对存储。其中将同一词语对呈现给标注者的次数以及同一词语对出现的间隔次数可以根据实际经验设定,本实施例中,同一词语对呈现给标注者的次数优选为25-30次,同一词语对出现的间隔次数优选为10次。
本实施例通过上述方案:收集未标注的词典,对词典中的词语进行处理,得到待标注词语对;将待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读待标注词语对时的脑电信号;对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库,提高了词语相似度计算的准确性。
请参照图2,图2是基于图1描述的词语相似度计算方法中步骤S3的细化流程示意图。该步骤S3可以包括:
步骤S31,对采集到的标注者每次阅读同一词语对时的脑电信号进行降噪处理,得到降噪后的脑电信号;
本实施例可以采用FASTICA算法对采集到的标注者每次阅读所述同一词语对时的脑电信号进行降噪处理,得到降噪后的高信噪比的脑电信号。本实施例中降噪后的脑电信号优选为信噪比高于15db的脑电信号。
信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或称为信息),并且这种信号并不随原信号的变化而变化。信噪比的计量单位是dB,其计算方法是10lg(PS/PN),其中PS和PN分别代表信号和噪声的有效功率,信噪比越高,说明噪声越小。
独立成分分析(简称ICA)是非常有效的数据分析工具,它主要用来从混合数据中提取出原始的独立信号。它作为信号分离的一种有效方法而受到广泛的关注。在诸多ICA算法中,固定点算法(简称FASTICA)以其收敛速度快、分离效果好被广泛应用于信号处理领域。该算法能很好地从观测信号中估计出相互统计独立的、被未知因素混合的原始信号。
步骤S32,对降噪后的脑电信号进行叠加平均处理,得到事件相关电位,根据事件相关电位判断相应词语的相似度,依此原理,获得词典中所有词语的相似度;
事件相关电位(ERP)是一种特殊的脑诱发电位,诱发电位(Evoked Potentials,EPs),也称诱发反应(Evoked Response),是指给予神经系统(从感受器到大脑皮层)特定的刺激,或使大脑对刺激(正性或负性)的信息进行加工,在该系统和脑的相应部位产生的可以检出的、与刺激有相对固定时间间隔(锁时关系)和特定位相的生物电反应。广义上讲,事件相关电位(ERP)包括N400,在事件相关电位中,N400反映了语言认知功能。
在对降噪后的脑电信号进行叠加平均处理后,在叠加平均后的信号中300ms至500ms范围内计算信号的负向最小值(即负向电位最低值)作为脑电信号的N400电位值。标注者在阅读不相关电位时,脑电信号会在阅读后400ms左右出现一个较大的负值,这个负值在心理学中被称为N400电位。N400电位越大说明呈现的词语对越不相似,N400电位越小说明呈现的词语对越相似。
依照上述原理,可以得出词典中所有词语的相似度。
步骤S33,计算词典中所有词语的相似度的平均值及方差,根据所述平均值及方差对词典中所有词语的相似度进行归一化处理,得到最终的词语相似度。
通过步骤S32得到词典中所有词语的相似度后,计算出所有词语相似度的平均值以及方差,根据所有词语的相似度的平均值以及方差对词典中所有词语的相似度进行归一化处理,得到最终的词语相似度。其中,归一化处理的计算公式为:A=(B-C)÷D,其中,A为最终的词语相似度值,B为词语的原始相似度,C为所有词语的相似度平均值,D为方差。
综上所述,本发明词语相似度计算方法通过上述方案:收集未标注的词典,对所述词典中的词语进行处理,得到待标注词语对;将所述待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读所述待标注词语对时的脑电信号;对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库,提高了词语相似度计算的准确性。
基于上述词语相似度计算方法,本发明提供了一种词语相似度计算装置。
请参照图3,图3是本发明词语相似度计算装置较佳实施例的功能模块示意图,如图3所示,本发明词语相似度计算装置较佳实施例包括:收集模块10、采集模块20及采构建模块30。
其中,收集模块10用于收集未标注的词典,对词典中的词语进行处理,得到待标注词语对;
目前常用的词典有《现代汉语词典》、《现代汉语规范词典》以及《汉语大辞典》等,为了得到词语相似度,本实施例首先将词典中的词语进行一对一组合,构成待标注的词语对。其中待标注的词语对的个数计算公式为:M=N×(N-1)÷2,其中,M为词语对的个数,N为词典中词语的个数。
采集模块20,用于将待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读待标注词语对时的脑电信号;
目前,获取词语相似度的方法通常是采用人工标注的方法,采用人工标注的方法获取词语相似度,不仅会消耗大量的时间和资金,并且在不同的时间标注同一语料是也会出现前后矛盾的情形。而采用脑电信号计算词语相似度能从认知神经科学的角度真实反映标注者的情绪,具有很高的准确性。
因此,本发明在计算词语相似度时需要标注者佩戴脑电采集装置,采集标注者阅读待标注词语对时的脑电信号。其中,标注者为佩戴脑电采集装置阅读待标注词语对的用户。
采构建模块30,用于对采集到的脑电信号进行处理,基于处理后的脑电信号对相应的词语进行相似度标注,构建基于脑电信号标注的词语相似度语料库。
由于在采集标注者阅读待标注词语对的的脑电信号的过程中,容易受到设备噪音、肌点噪音以及眼电噪音等的影响,所以在采集到标注者阅读待标注词语对是的脑电信号后,需要对所采集到的脑电信号进行降噪处理,以提高词语相似度计算的准确性。
具体实施时,为了进一步提高词语相似度计算的准确性,可以将同一词语对多次间隔呈现给标注者,供标注者阅读,将采集到的标注者每次阅读所述同一词语对时的脑电信号与相应的词语对成对存储。其中将同一词语对呈现给标注者的次数以及同一词语对出现的间隔次数可以根据实际经验设定,本实施例中,同一词语对呈现给标注者的次数优选为25-30次,同一词语对出现的间隔次数优选为10次。
本实施例通过上述方案:收集模块10收集未标注的词典,对词典中的词语进行处理,得到待标注词语对;采集模块20将待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读待标注词语对时的脑电信号;采构建模块30对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库,提高了词语相似度计算的准确性。
请参照图4,图4是基于图3描述的词语相似度计算装置中采构建模块30的细化功能模块示意图。该采构建模块30包括:降噪单元301、叠加处理单元302及归一化处理单元303。
其中,降噪单元301,用于对采集到的标注者每次阅读同一词语对时的脑电信号进行降噪处理,得到降噪后的脑电信号;
本实施例可以采用FASTICA算法对采集到的标注者每次阅读所述同一词语对时的脑电信号进行降噪处理,得到降噪后的高信噪比的脑电信号。本实施例中降噪后的脑电信号优选为信噪比高于15db的脑电信号。
信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或称为信息),并且这种信号并不随原信号的变化而变化。信噪比的计量单位是dB,其计算方法是10lg(PS/PN),其中PS和PN分别代表信号和噪声的有效功率,信噪比越高,说明噪声越小。
独立成分分析(简称ICA)是非常有效的数据分析工具,它主要用来从混合数据中提取出原始的独立信号。它作为信号分离的一种有效方法而受到广泛的关注。在诸多ICA算法中,固定点算法(简称FASTICA)以其收敛速度快、分离效果好被广泛应用于信号处理领域。该算法能很好地从观测信号中估计出相互统计独立的、被未知因素混合的原始信号。
叠加平均处理单元302,用于对降噪后的脑电信号进行叠加平均处理,得到事件相关电位,根据事件相关电位判断相应词语的相似度,依此原理,获得词典中所有词语的相似度;
事件相关电位(ERP)是一种特殊的脑诱发电位,诱发电位(Evoked Potentials,EPs),也称诱发反应(Evoked Response),是指给予神经系统(从感受器到大脑皮层)特定的刺激,或使大脑对刺激(正性或负性)的信息进行加工,在该系统和脑的相应部位产生的可以检出的、与刺激有相对固定时间间隔(锁时关系)和特定位相的生物电反应。广义上讲,事件相关电位(ERP)包括N400,在事件相关电位中,N400反映了语言认知功能。
在对降噪后的脑电信号进行叠加平均处理后,在叠加平均后的信号中300ms至500ms范围内计算信号的负向最小值(即负向电位最低值)作为脑电信号的N400电位值。标注者在阅读不相关电位时,脑电信号会在阅读后400ms左右出现一个较大的负值,这个负值在心理学中被称为N400电位。N400电位越大说明呈现的词语对越不相似,N400电位越小说明呈现的词语对越相似。
依照上述原理,可以得出词典中所有词语的相似度。
归一化处理单元303,用于计算词典中所有词语的相似度的平均值及方差,根据所述平均值及方差对词典中所有词语的相似度进行归一化处理,得到最终的词语相似度。
通过归一化处理单元303得到词典中所有词语的相似度后,计算出所有词语相似度的平均值以及方差,根据所有词语的相似度的平均值以及方差对词典中所有词语的相似度进行归一化处理,得到最终的词语相似度。其中,归一化处理的计算公式为:A=(B-C)÷D,其中,A为最终的词语相似度值,B为词语的原始相似度,C为所有词语的相似度平均值,D为方差。
综上所述,本发明词语相似度计算方法通过上述方案:收集模块10收集未标注的词典,对所述词典中的词语进行处理,得到待标注词语对;采集模块20将所述待标注词语对呈现给标注者,供标注者阅读,采集标注者阅读所述待标注词语对时的脑电信号;采构建模块30对采集到的脑电信号进行分析,基于分析后的脑电信号对相应的词语对进行相似度标注,构建脑电信号标注的词语相似度语料库,提高了词语相似度计算的准确性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!