一种基于隐式马尔科夫模型的科技类复合短语识别方法与流程
本发明涉及一种基于隐式马尔科夫模型的复合短语实体识别方法,属于计算机软件技术领域。
背景技术:
随着多科学研究的逐步深入,现今学术界和研究者发表大量的研究成果呈海量爆炸性增长。如何自动化收集、整合、分析这些工作成为了学术界和工业界关注的问题。包括论文、书籍、技术报告、专利的题目、科技项目名称等。这一类短语在这里统称为科技类复合短语。如何高效的从各类网络语料中抽取需要的科技复合短语实体,是自动化进行学术信息抽取、知识产权保护、科技资源数据库在线建设与维护等诸多应用的基础。
传统意义上的命名实体作为是自然语言处理的基本任务抽取的对象主要包括人名、地名、组织机构名、数字、计量单位等专有名词。这些命名实体具有长度相对稳定、结构规范、命名规则统一的有利特点,这使得传统的命名实体识别系统的f1-measure往往能达到90%以上,几乎接近人类正常识别水平。而科技类名词短语不同于人名和地名。科技类复合短语往往内部结构复杂,内部包含嵌套的科技名词实体。而且科技类名词短语纷繁复杂,词语的出现与否本身具有极大的稀疏性,内部实体之间相互组合的冗余度低。这类词法结构导致识别该类命名实体的难度较大。这使得通过词语本身隐式马尔科夫输入的方法不可行。由于复合短语相对于普通的命名实体(人名、地名、机构名)词语本身词法组成更加复杂,传统的纯手工角色标注容易导致标注错误。
技术实现要素:
针对现有技术中存在的技术问题,本发明的目的在于提供一种复合短语自动识别与提取方法,为解决复合短语自动化识别,本文提出了一种基于隐式马尔科夫模型的复合短语的识别方法。
本发明的技术方案为:
一种基于隐式马尔科夫模型的复合短语识别方法,其步骤为:
1)采用词性标注工具对输入语料进行词性标注和分词;
2)采用隐式马尔科夫模型对步骤1)处理后的语料进行隐状态预测,输出一状态序列;然后对该状态序列进行切分,得到一复合短语集合;
3)判断步骤2)得到的复合短语中是否包含特征词集合中的特征词,将含有设定特征词的复合短语作为识别的科技类复合短语。
进一步的,生成所述特征词集合的方法为:选取一科技名词短语集合,记训练集为p={p1,p2,...,pn},其中pn为第n条文本标题;对该集合p进行分词处理,获取一词典数据w={w1,w2,...,wm},其中wm为词典中第m个单词;然后在该词典w中寻找一个满足最小覆盖的子集s′,使得s′满足:集合s能够覆盖集合p,即集合p的每条语料pi中至少有一个单词在s中出现;以及集合s中元素个数最小;然后将得到的子集s′作为所述特征词集合。
进一步的,采用贪心算法在词典w中寻找一个满足最小覆盖的子集s′。
进一步的,在该词典w中寻找一个满足最小覆盖的子集s′的方法为:
a)利用训练集p和词典w构造一个m×n维的二值矩阵m,其中,该二值矩阵m中的元素mij为矩阵m的第i行第j列元素;若词典w中第i个单词wi在训练集p中的第j条文本标题pj中出现过,则令mij=1,否则mij=0;
b)选择该矩阵m中1数量最多的一行,记为第i行,计算s′=s′∪wi、
c)重复步骤b),直到该矩阵m为空矩阵,此时单词集s′即所求的最小覆盖集s′。
进一步的,构造该二值矩阵m的方法为:将训练集p中每一短语为矩阵m的一列向量,训练集p中各短语的所有分词构成矩阵m的行向量。
进一步的,采用隐式马尔科夫模型对步骤1)处理后的语料进行隐状态预测的方法为:将词性标注状态作为输入隐式马尔科夫模型的显状态;当输入显状态对应的分词命中上文提示词词典、下文提示词词典或维基百科条目时,将该分词的词性标注显状态置换为命中对象对应的设定值。
进一步的,当该状态序列中的一段序列以前缀开头,中间为核心成分,以后缀结束,则将该段序列截取作为一复合短语。
进一步的,通过启发式规则建立所述上文提示词词典、下文提示词词典。
进一步的,所述特征词为科技类复合短语中的高频词。
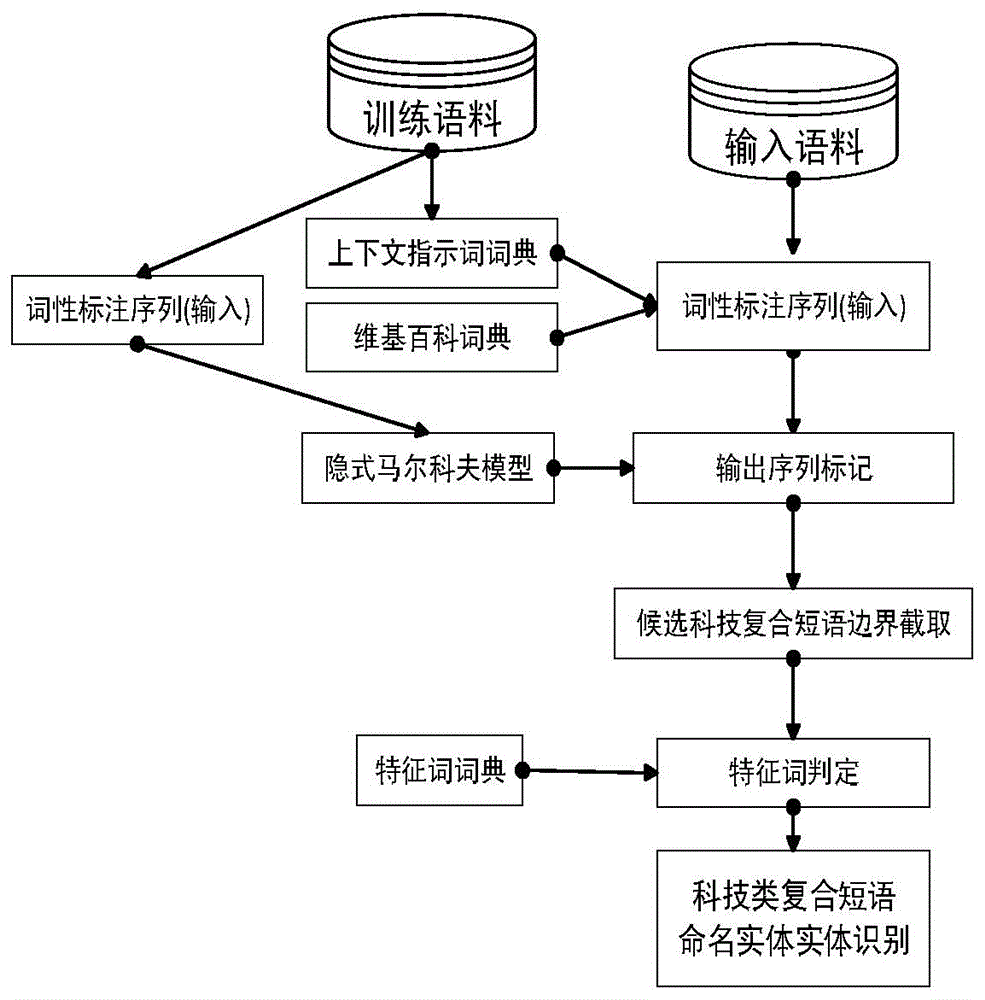
本方法模型主要分为三部分:第一部分为首先采用词性标注工具对输入语料进行词性标注和分词。第二部分采用隐式马尔科夫进行输出序列即隐状态的预测,将得到的输出状态序列进行切分,即得到分词组合为复合短语后的结果。第三部分判断上一步的复合短语是否包含特征词,所谓特征词,是指在科技类复合短语中反复出现的一类词语,而在其他命名实体中极少出现的一类词语。将含有特征词的复合短语作为识别的科技类复合短语结果。整个流程如图1所示:
科技类复合短语在上下文中词语转移之间的冗余度低的特性,无法直接采用字面值作为隐式马尔科夫模型输入显状态。在这里采用词性标注状态作为输入的显状态。当输入的显状态对应的分词命中上文提示词词典、下文提示词词典和维基百科条目,此时将其默认的词性标注显状态置换为表1中规定的值。其中上文与下文提示词词典为实现通过启发式规则建立。修改后的显状态序列作为隐式马尔科夫训练与预测的输入序列。在隐式马尔科夫模型输出预测序列中,和候选词语识别左右边界采用表2中规定的前缀、后缀以及核心成分在序列中对应的最大边界。当一段序列以上述三者开头以及结束,中间为表2中除非项目成分中的其他状态,将这样的序列截取作为候选的复合短语。
表1上下文指示词词典和维基百科词典显状态、隐状态例子
表2复合科技名词短语角色标注成分
在切分后的候选科技复合短语实体中,需要对候选的集合进行判断。注意到科技类科技复合短语中包含一类特殊的高频词语、例如上述短语中的“技术”、“研究”和“应用”。我们将这一类词语称为科技复合短语的特征词。特征词集合规模过大会导致过匹配非复合短语。而特征词集合规模过小又会导致遗漏。为了解决上述问题,我们基于最小集合覆盖问题,进行特征词集合的生成。所谓最小集合覆盖,是指给定全集u,以及一个包含n个u的子集且这n个子集的并集为全集u,这些子集本身作为集合s的元素。集合覆盖问题是要找到集合s中最小的子集s′,使得集合s′中元素的并集等于全集u,并且s′的规模最小。给定科技名词短语集合,记训练集为p={p1,p2,...,pn},其中pi为第i条文本标题。通过对p进行分词处理后可以获取一个词典数据w={w1,w2,...,wm},其中wi为词典中第i个单词。关系类型的特征词提取可以转化为在词典w中寻找一个满足最小覆盖的子集s′,使得s′满足:
1.集合s′能够覆盖集合p,即集合p的每条语料pi中至少有一个单词在s中出现;
2.s′中元素个数最小。由于求解最小集合覆盖问题是一个np-hard问题。这里采用贪心算法求解特征词的覆盖问题。
将求解训练集p的最小覆盖单词集s′问题记为wlan(wordswiththeleastnumber)。定理1可以证明wlan问题是一个np难问题
定理1.wlan问题是np-hard难题。
证明:对于每个单词w∈w,可以构造一个语料集
本发明通过以下方法求解特征词的最小覆盖集合。通过训练集p和词典w可以构造一个m×n维的二值矩阵m(由图2所示),mij为矩阵m的第i行第j列元素,若词典中第i个单词wi在pj中出现过则mij=1,否则mij=0。定义二元运算符
构造布尔矩阵m,对训练语料中所有科技复合短语看作矩阵m的列向量,对于训练语料中所有科技复合短语中所有的分词构成矩阵m的列向量。若一个单词在某条科技复合短语中出现,则把其对应结果置为1。
矩阵m作为初始输入值,令单词集
选择m中1数量最多的一行,假设为第i行(矩阵第i行对应的就是第i个单词wi),计算s′=s′∪wi;
令
重复上述两个步骤直到m为空矩阵为止,此时单词集s′即所求的最小覆盖集。
本发明针对科技类复合名词短语自身的特点,通过设置上下文词典、维基百科词典以及表1和表2中设定的隐状态和显状态,通过表1中规定的显状态自动置换,通过隐式马尔科夫模型预测生成的序列中,通过表2中定义的候选复合名词短语的边界,从而达到候选科技类复合短语的识别。通过最小集覆盖的思想获取,实现了候选科技复合名词短语的自动预提取。其中上下文词典是通过启发式规则编制,维基百科词典通过jpwl开发包,对维基百科条目名称做提取并导出得到。
本发明根据复合短语特征词中富含特征词这一重要特性,采用了特征词来实现候选科技复合名词短语的最终识别。本专利采用了最小集合覆盖的思想,来获得合适规模的特征词集合。
与现有技术相比,本发明的有益效果:
在测试数据集上,本算法专利取得了48.8%的查全率,47.8%的查准率以及48.3的f1测度。另外本算法在进行算法标注的时候,采取了上下文显状态与隐状态自动置换。另外在自动判定候选边界切分的方法上采用了特征词匹配,采用了最小覆盖的思想构建特征词集合,该过程不需要人工标注。基于以上两点,一定程度上缓解了角色标注的巨大人工成本代价。
附图说明
图1为命名实体识别处理流程;
图2为二元运算
图3为特征词词频曲线。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,可以理解的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:
以输入语料“我校参与完成的项目‘两系法杂交水稻技术研究与应用’与获得国家科技进步一等奖”为例”,处理流程首先对整句话进行分词与词性标注,得到词性标注序列“我校/r参与/v完成/v的/ude1项目/n"/wyz两/m系/n法/b杂交水稻/wiki技术/n研究/vn与/cc应用/vn"/wyy与/cc获得/v国家/wiki科技/wiki进步/vn一等奖/n”。利用词性标注序列自动置换对应的显状态序列:<r>我校</r><cao>参与</cao><cao>完成</cao><ude1>的</ude1><wio>科技</wio><n>项目</n><wyz>"</wyz><m>两</m><n>系</n><b>法</b><wio>杂交水稻</wio><n>技术</n><vn>研究</vn><cc>与</cc><vn>应用</vn><wyy>"</wyy><cc>与</cc><cbo>获得</cbo><wio>国家<wio><wio>科技</wio><vn>进步</vn><n>一等奖</n>。该序列作为隐式马尔科夫模型的输入模型,通过维特比算法得到预测输出的隐状态:<n>我校</n><cas>参与</cas><cas>完成</cas><n_ab>的</n_ab><n_ab>科技</n_ab><n_ab>项目</n_ab><sp>"</sp><cwp>两</cwp><cwp>系</cwp><cwp>法</cwp><cw>杂交水稻</cw><cws>技术</cws><cws>研究</cws><ccll>与</ccll><cws>应用</cws><sp>"</sp><cbs>获得</cbs><n>国家</n><n>科技</n><n>进步</n><n>一等奖</n>。在序列中,由表2定义的前缀、后缀以及核心成分的最大边界,其对应的序列为:<cwp>两</cwp><cwp>系</cwp><cwp>法</cwp><cw>杂交水稻</cw><cws>技术</cws><cws>研究</cws><ccll>与</ccll><cws>应用</cws>。故提取序列“两系法杂交水稻技术研究与应用“作为候选复合实体短语。由于其中包含特征词“技术”与“研究”,故其匹配为科技复合短语。
本文采用最小覆盖的算法产生特征词。特征词的训练集合来源为训练集来源与8所高校的1119个国家自然科学基金。图3表示所有特征词按照词频降序的曲线。如图3,当特征词规模大于72时,可以看到特征词覆盖规模呈幂律分布减小,这表明随着高频特征词往往数量有限,在获取一定规模的特征词,就可以有效避免误匹配科技复合名词短语。我们在这里将特征词的词频规模设置为72。
我们利用包含从2005年到2014年的获得国家科技进步奖的1522个获奖项目的文本作为种子,爬取并选取679条数据作为实验数据。本文将其中146条数据按照表2和进行角色标注,剩余的533条语料作为测试数据。本文的实验结果显示,基于层叠隐式马尔科夫链模型取得了81.1%的准确率,90.1%的召回率以及85.3%的f1值。与不采用上下文词典与维基百科角色标注、以及特征词词典,基于表2中中角色标注的单层隐士马尔科夫模型,层叠隐士马尔科夫模型提高了20.7%的准确率,10.1%的召回率和16.5%的f1值。
- 还没有人留言评论。精彩留言会获得点赞!