面向个性化学习的教育资源推荐方法及系统与流程
本发明涉及面向个性化学习的教育资源推荐及大数据研究
技术领域:
,具体涉及面向个性化学习的教育资源推荐方法及系统。
背景技术:
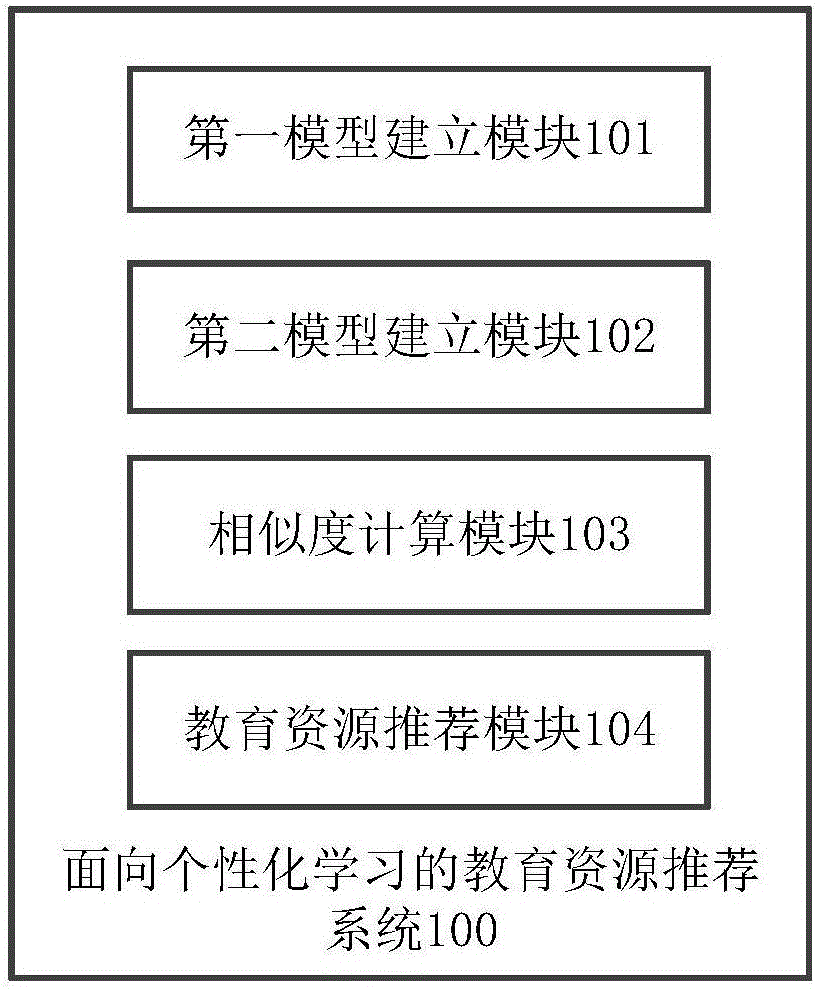
:近年来,随着全民学习、终身学习等观念的普及,非正式学习得到了越来越多的人的关注。移动通信技术的发展使得非正式学习的方式经历了由数字学习到移动学习再到如今的泛在学习的发展过程,学习方式变得更加灵活、便捷和个性化。泛在学习因其可以使学习者根据自己的需求随时随地利用任何终端学习的特性,适应了现代社会对学习的需求,受到人们的普遍欢迎,并成为未来学习的发展趋势。而泛在学习资源是泛在学习得以开展的重要支撑,因此,如何设计与开发高效、便捷、个性化的泛在学习资源成为了泛在学习研究的一项重要内容。现阶段,互联网成为了学习者获取学习资源的重要渠道,然而,随着网络资源数量爆炸性的增长,仅仅通过传统的搜索引擎方式来获取信息存在着返回结果多、准确性差等缺点,这使得学习者无法获得满意的学习资源。学习资源的获取平台增加,资源类型也变得更加多样,面对海量的学习资源,如何根据学习者的行为轨迹,分析学习者兴趣,推荐能够反映学习者学习兴趣的学习资源,实现“因材施教”变得越来越重要,网络的个性化学习已经成为当今世界网络教育领域的发展趋势。而近年来个性化推荐技术在商务领域的成功应用为解决这一问题提供了一个新的思路。个性化推荐在互联网电子商务领域的应用已经非常成熟,研究学者们也纷纷开始探索推荐技术在教育领域的应用。将个性化推荐技术引入教育领域,并与泛在学习资源相结合,可以很好地帮助学习者获得个性化的泛在学习资源。技术实现要素:有鉴于此,本发明的目的在于克服现有技术的不足,提供面向个性化学习的教育资源推荐方法及系统,实现网络教育资源的个性化推荐。为实现以上目的,本发明采用如下技术方案:面向个性化学习的教育资源推荐方法,包括:步骤S1、采集学习者的基本特征数据,并根据所述基本特征数据建立学习者的资源兴趣度模型和学习风格模型;其中,所述基本特征数据包括学习者身份信息、学习行为记录和教育资源操作记录;步骤S2、根据所述资源兴趣度模型和学习风格模型建立学习者特征模型;步骤S3、根据所述学习者特征模型,计算不同学习者之间的相似度或不同教育资源之间的相似度;步骤S4、根据所述不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。优选地,所述步骤S1中资源兴趣度模型中存储有学习者登录教育资源网站的学习者名和密码、浏览对象ID和教育资源兴趣度评分;其中,所述教育资源兴趣度评分intrScore根据公式(1)进行计算:IntrScore=Score/5+(st+scc+sds)+Score(1)其中,Score为学习者使用或浏览教育资源后,对教育资源的评分,Score∈[1,5],IntrScore∈[1,10];st为对象ID浏览时长得分,根据公式(2)计算:其中,ToltalTime为使用或浏览教育资源的总耗时长,Mintime为该教育资源对应的最短学习时间,ToltalTime和Mintime的单位皆为分钟;Click为点击次数;scc为收藏评论得分,根据公式(3)计算:其中,Collect为收藏次数,Comment为评论标记次数;sds为下载推荐得分,根据公式(4)计算:其中,Download为下载次数,Share为推荐给好友次数。优选地,所述步骤S1中学习风格模型中存储有学习者的学习风格偏向值,所述学习风格偏向值根据如下步骤进行计算:根据学习者在线填写的学习风格评估表,将学习者划分为四种学习风格并计算每种学习风格的偏向值tpi,i=1、2、3、4;根据所述四种学习风格分别对应的教育资源操作行为类别取值、偏向权重和偏向阈值,建立学习者教育资源操作行为类别偏向阀值模型;其中,所述教育资源操作行为类别取值包括每种学习风格对应的教育资源操作行为类别的时长、点击率、时间比和次数比;根据公式(5)和公式(6)计算每种学习风格偏向值tyi,i=1、2、3、4;其中,ctypej为第i种学习风格对应的教育资源操作行为类别取值,j为正整数,wj为ctypej所对应的偏向权重,lj为第一偏向阈值,hj为第二偏向阈值;若学习者的教育资源操作记录次数小于预设值,以公式(7)计算每种学习风格偏向值sti,否则,以公式(8)计算每种学习风格偏向值sti;sti=0.8*tpi+0.2tyi(7);sti=0.8*tyi+0.2tpi(8)。优选地,所述步骤S3中的学习者特征模型为n*(m+4)的矩阵信息表;所述学习者特征模型中存储有第n个学习者对使用或浏览过的第m个教育资源兴趣度评分及第n个学习者第i种学习风格的偏向值;1≤n≤学习者总人数,1≤m≤学习者使用或浏览过的总教育资源数,i=1、2、3、4。优选地,所述步骤S3中不同学习者之间的相似度根据如下步骤进行计算:统计任一学习者Ua使用或浏览过的教育资源集合Sa和任一学习者Ub使用或浏览过的教育资源集合Sb,并求Sa和Sb的交集:Sab=Sa∩Sb;根据公式(9)计算出学习者Ua和Ub对使用或浏览过的教育资源兴趣度评分的平均值:其中,k=a、b,gk,m为学习者Uk对使用或浏览过的第m个教育资源的兴趣度评分,|Sk|为学习者Uk使用或浏览过的教育资源集合Sk中的元素个数,gk,x和|Sk|皆从所述学习者特征模型查询得到;根据公式(10)计算学习者ua和ub的学习风格偏向值的平均值:其中,fk,i为学习者Uk第i种学习风格的偏向值;根据公式(11)计算学习者ua和ub的相似度:其中,0.7和0.3为相似度评分权重。优选地,所述步骤S4中根据所述不同学习者之间的相似度生成针对目标学习者的教育资源推荐结果,包括:根据Usim(ua,ub)的计算结果,将Usim(ua,ub)降序排序;取降序排列后的Usim(ua,ub)的前K1个值对应的ub作为目标学习者ua的参考学习者集合:根据公式(12)预测目标学习者ua对参考学习者ub使用或浏览过的第m个教育资源的兴趣度评分:其中,gb,m为参考学习者ub对使用或浏览过的第m个教育资源的兴趣度评分,从所述学习者特征模型查询得到;为参考学习者ub对使用或浏览过的教育资源兴趣度评分的平均值;根据Pa,m的计算结果,将Pa,m降序排列;取降序排列后的Pa,m的前N个值对应的教育资源推荐给目标学习者ua,1≤N≤m。优选地,所述步骤S3中不同教育资源之间的相似度根据如下步骤进行计算:统计使用或浏览过任一教育资源ra的学习者集合统计使用或浏览过任一教育资源rb的学习者集合并求和的交集根据公式(13)分别计算教育资源ra和rb的兴趣度评分的平均值:其中,k=a、b,为第n个学习者对教育资源rk的兴趣度评分,为使用或浏览过教育资源rk的学习者集合中的元素个数,和皆从所述学习者特征模型查询得到;根据公式(14)计算教育资源ra和rb的相似度:优选地,所述步骤S4中根据所述不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果,包括:根据Rsim(ra,rb)的计算结果,将Rsim(ra,rb)降序排序;取降序排列后的Rsim(ra,rb)的前K2个值对应的rb作为目标教育资源ra的参考教育资源集合:根据公式(15)预测目标学习者ua对目标教育资源ra的兴趣度评分:其中,为目标学习者ua对教育资源rb的兴趣度评分,从所述学习者特征模型查询得到;根据的计算结果,将降序排列;取降序排列后的的前N个值对应的教育资源ra推荐给目标学习者ua。优选地,所述步骤S1~S4的输出结果以网页图表的形式呈现出来。一种面向个性化学习的教育资源推荐系统,包括:第一模型建立模块,用于采集学习者的基本特征数据,并根据所述基本特征数据建立学习者的资源兴趣度模型和学习风格模型;其中,所述基本特征数据包括学习者身份信息、学习行为记录和教育资源操作记录;第二模型建立模块,用于根据所述学习者资源兴趣度模型和学习风格模型,建立学习者特征模型;相似度计算模块,用于根据所述学习者特征模型,计算不同学习者之间的相似度或不同教育资源之间的相似度;教育资源推荐模块,用于根据所述不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。本发明采用以上技术方案,至少具备以下有益效果:由上述技术方案可知,本发明提供的这种面向个性化学习的教育资源推荐方法,利用云计算和大数据技术,采集学习者的基本特征数据,建立学习者的资源兴趣度模型和学习风格模型,并根据资源兴趣度模型和学习风格模型建立学习者特征模型,以计算不同学习者之间的相似度或不同教育资源之间的相似度,最后根据不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。通过本发明提供的技术方案,能实现针对目标学习者的网络教育资源的个性化推荐。另外,本发明基于软件工程领域电子商务中较为成熟的个性化推荐技术,采用协同过滤推荐算法,并对该算法进行改进优化,使其适用于学习资源的个性化推荐。通过本发明的技术方案,能提高学习者的学习效率、学习质量,提高教育教学质量,学习者无需访问庞杂的学习资源库盲目搜寻自己感兴趣的教育资源,使学习者方便快捷地获取有用信息,避免了学习者盲目地查找学习资源,同时也节省了管理者的管理成本。再者,本发明充分利用云计算和大数据处理技术,实现海量数据的采集、存储、计算和可视化效果呈现,能充分利用和节省计算资源,具有很好的拓展性和灵活性,对海量结构化和非结构化数据进行快速采集、处理和计算,能快速完成面向个性化学习的教育资源推荐系统中各种的海量计算。附图说明图1为本发明一实施例提供的面向个性化学习的教育资源推荐方法的流程示意图;图2为本发明一实施例提供的面向个性化学习的教育资源推荐系统的示意框图。具体实施方式下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。参见图1,本发明一实施例提供的面向个性化学习的教育资源推荐方法,包括:步骤S1、采集学习者的基本特征数据,并根据所述基本特征数据建立学习者的资源兴趣度模型和学习风格模型;其中,所述基本特征数据包括学习者身份信息、学习行为记录和教育资源操作记录;步骤S2、根据所述资源兴趣度模型和学习风格模型建立学习者特征模型;步骤S3、根据所述学习者特征模型,计算不同学习者之间的相似度或不同教育资源之间的相似度;步骤S4、根据所述不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。其中,步骤S1中的学习者身份信息存储格式如下表一所示:属性名数据类型说明KeyStdIDVarchar学习者IDKeyWordS_IDStdNameVarchar名称—昵称S_NameBithdayDate出生日期S_BGradeVarchar年级S_GFavorEFGVarchar兴趣爱好S_FIPVarchar学习者使用IPS_IP表一步骤S1中的学习行为记录存储格式如下表二所示:表二步骤S1中的教育资源操作记录存储格式如下表三所示:属性名数据类型说明KeyStdIDVarchar学习者IDKeyWordS_IDObjectIDVarchar对象IDO_IClickint点击数,0(Def,未点击)O_CCollectint收藏,0(Def,未收藏)O_CollectDownloadint下载次,0(Def,未下载)O_DlCommentint评论标记,0(Def,没评论)O_CommentShareint推荐给好友数,0(Def,没推荐)O_ShareTotalTimeint使用/浏览资源的总耗时长(分钟)O_TotalTimeScoreint评分1-5分,0(Def)O_Score表三需要说明的是,上述表一、表二和表三中的字段“属性名”、“数据类型”和“说明”的值存储在关系型数据库MySQL中,字段“Key”的值存储在分布式存储系统HBase中,由大数据处理平台统计后回写至关系型数据库中。由上述技术方案可知,本发明提供的这种面向个性化学习的教育资源推荐方法,利用云计算和大数据技术,采集学习者的基本特征数据,建立学习者的资源兴趣度模型和学习风格模型,并根据资源兴趣度模型和学习风格模型建立学习者特征模型,以计算不同学习者之间的相似度或不同教育资源之间的相似度,最后根据不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。通过本发明提供的技术方案,能实现针对目标学习者的网络教育资源的个性化推荐。优选地,所述步骤S1中资源兴趣度模型中存储有学习者登录教育资源网站的学习者名和密码、浏览对象ID和教育资源兴趣度评分;资源兴趣度模型中的数据存储格式如下表四所示:属性名数据类型说明KeyStdIDVarchar学习者IDKeyWordS_IDObjectIDVarchar对象IDO_IIntrScoreFloat教育资源兴趣度评分O_IntrScore表四其中,表四中的教育资源兴趣度评分intrScore根据公式(1)进行计算:IntrScore=Score/5+(st+scc+sds)+Score(1)其中,Score为学习者使用或浏览教育资源后,对教育资源的评分,Score∈[1,5],IntrScore∈[1,10];st为对象ID浏览时长得分,根据公式(2)计算:其中,ToltalTime为使用或浏览教育资源的总耗时长,Mintime为该教育资源对应的最短学习时间,ToltalTime和Mintime的单位皆为分钟;Click为点击次数;scc为收藏评论得分,根据公式(3)计算:其中,Collect为收藏次数,Comment为评论标记次数;sds为下载推荐得分,根据公式(4)计算:其中,Download为下载次数,Share为推荐给好友次数。优选地,所述步骤S1中学习风格模型中存储有学习者的学习风格偏向值,所述学习风格偏向值根据如下步骤进行计算:根据学习者在线填写的学习风格评估表(参见如下表五),将学习者划分为四种学习风格并计算每种学习风格的偏向值tpi,i=1、2、3、4;表五上述表五中,针对每种类型,其计算结果得分为{11A,9A,7A,5A}→{5,4,3,2};{3A,A,B,3B}→{1,0.5,-0.5,-1};{5B,7B,9B,11B}→{-2,-3,-4,-5};当得分∈{5,4,3,2}表示其学习风格偏向每种类型的前者即∈{活跃型、感悟型、视觉型、序列型},当得分∈{1,0.5,-0.5,-1}表示其学习风格偏向每种类型的折中;当得分∈{-2,-3,-4,-5}∈{沉思型、直觉型、言语型、综合型};数值的取值表示其学习风格偏向的程度。根据所述四种学习风格分别对应的教育资源操作行为类别取值、偏向权重和偏向阈值,建立学习者教育资源操作行为类别偏向阀值模型(参见表六);其中,所述教育资源操作行为类别取值包括每种学习风格对应的教育资源操作行为类别的时长、点击率、时间比和次数比(参见表七);表六表七需要说明的是,上述表七中的字段“属性名”、“数据类型”和“说明”的值存储在关系型数据库MySQL中,字段“Key”的值存储在分布式存储系统HBase中,由大数据处理平台统计后回写至关系型数据库中。根据公式(5)和公式(6)计算每种学习风格偏向值tyi,i=1、2、3、4;例如:假设活跃型/沉思型对应的操作行为类别取值t_std的ctype1取值为4.5,偏向权重w1为0.3;t_disc的ctype2取值为3.8,偏向权重w2为0.2;n_disc的ctype3取值为4.8,偏向权重w3为0.25;n_mes的ctype4取值为4.2,偏向权重w4为0.25。则学习者活跃型/沉思型学习风格的偏向值为:=4.5*0.3+3.8*0.2+4.8*0.25+4.2*0.25=4.36。公式(5)中的ctypej根据公式(6)进行计算:其中,ctypej为第i种学习风格对应的教育资源操作行为类别取值,j为正整数,wj为ctypej所对应的偏向权重,lj为第一偏向阈值,hj为第二偏向阈值;例如:设ctypej为t_std,查询表7可知t_std为学习者参与学习平均时长,假设为60分钟,对应的l1为30分钟,h1为75分钟,由于60∈(30,75),则t_std的取值为:若学习者的教育资源操作记录次数小于预设值,以公式(7)计算每种学习风格偏向值sti,否则,以公式(8)计算每种学习风格偏向值sti;sti=0.8*tpi+0.2tyi(7);sti=0.8*tyi+0.2tpi(8)。优选地,所述步骤S3中的学习者特征模型为n*(m+4)的矩阵信息表(参见表八);所述学习者特征模型中存储有第n个学习者对使用或浏览过的第m个教育资源兴趣度评分及第n个学习者第i种学习风格的偏向值;1≤n≤学习者总人数,1≤m≤学习者使用或浏览过的总教育资源数,i=1、2、3、4。表八优选地,所述步骤S3中不同学习者之间的相似度根据如下步骤进行计算:统计任一学习者Ua使用或浏览过的教育资源集合Sa和任一学习者Ub使用或浏览过的教育资源集合Sb,并求Sa和Sb的交集:Sab=Sa∩Sb;根据公式(9)计算出学习者Ua和Ub对使用或浏览过的教育资源兴趣度评分的平均值:其中,k=a、b,gk,m为学习者Uk对使用或浏览过的第m个教育资源的兴趣度评分,|Sk|为学习者Uk使用或浏览过的教育资源集合Sk中的元素个数,gk,x和|Sk|皆从所述学习者特征模型查询得到;根据公式(10)计算学习者ua和ub的学习风格偏向值的平均值:其中,fk,i为学习者Uk第i种学习风格的偏向值;根据公式(11)计算学习者ua和ub的相似度:其中,0.7和0.3为相似度评分权重。优选地,所述步骤S4中根据所述不同学习者之间的相似度生成针对目标学习者的教育资源推荐结果,包括:根据Usim(ua,ub)的计算结果,将Usim(ua,ub)降序排序;取降序排列后的Usim(ua,ub)的前K1个值对应的ub作为目标学习者ua的参考学习者集合:根据公式(12)预测目标学习者ua对参考学习者ub使用或浏览过的第m个教育资源的兴趣度评分:其中,gb,m为参考学习者ub对使用或浏览过的第m个教育资源的兴趣度评分,从所述学习者特征模型查询得到;为参考学习者ub对使用或浏览过的教育资源兴趣度评分的平均值;根据Pa,m的计算结果,将Pa,m降序排列;取降序排列后的Pa,m的前N个值对应的教育资源推荐给目标学习者ua,1≤N≤m。具体来说,通过MapReduce迭代过程,取降序排列后的Pa,m的前N个值对应的教育资源推荐给目标学习者ua。优选地,所述步骤S3中不同教育资源之间的相似度根据如下步骤进行计算:统计使用或浏览过任一教育资源ra的学习者集合统计使用或浏览过任一教育资源rb的学习者集合并求和的交集根据公式(13)分别计算教育资源ra和rb的兴趣度评分的平均值:其中,k=a、b,为第n个学习者对教育资源rk的兴趣度评分,为使用或浏览过教育资源rk的学习者集合中的元素个数,和皆从所述学习者特征模型查询得到;根据公式(14)计算教育资源ra和rb的相似度:优选地,所述步骤S4中根据所述不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果,包括:根据Rsim(ra,rb)的计算结果,将Rsim(ra,rb)降序排序;取降序排列后的Rsim(ra,rb)的前K2个值对应的rb作为目标教育资源ra的参考教育资源集合:根据公式(15)预测目标学习者ua对目标教育资源ra的兴趣度评分:其中,为目标学习者ua对教育资源rb的兴趣度评分,从所述学习者特征模型查询得到;根据的计算结果,将降序排列;取降序排列后的的前N个值对应的教育资源ra推荐给目标学习者ua。具体来说,通过MapReduce迭代过程,取降序排列后的的前N个值对应的教育资源ra推荐给目标学习者ua。优选地,上述教育资源以教育资源推荐列表、个性化教育资源推荐列表、学习者社区推荐列表等形式推荐给目标学习者。优选地,所述步骤S1~S4的输出结果以网页图表的形式呈现出来(例如通过分类统计图、曲线图等形式在Web页面上呈现)。参见图2,面向个性化学习的教育资源推荐系统100,包括:第一模型建立模块101,用于采集学习者的基本特征数据,并根据所述基本特征数据建立学习者的资源兴趣度模型和学习风格模型;其中,所述基本特征数据包括学习者身份信息、学习行为记录和教育资源操作记录;第二模型建立模块102,用于根据所述学习者资源兴趣度模型和学习风格模型,建立学习者特征模型;相似度计算模块103,用于根据所述学习者特征模型,计算不同学习者之间的相似度或不同教育资源之间的相似度;教育资源推荐模块104,用于根据所述不同学习者之间的相似度或不同教育资源之间的相似度,生成针对目标学习者的教育资源推荐结果。优选地,上述面向个性化学习的教育资源推荐系统100按如下步骤进行部署:1、配置云端服务。安装智慧协同教育学习服务平台,配置部署关系数据库MySQL,按需求在每个商务页面(Web、App等)部署JavaScript数据采集脚本。2、配设基础设施设备,安装软件环境VMwareworkstation8.04,Ubuntu12.04server版,JDK1.7,Hadoop2.6,Hive0.7.0,Hbase0.90.3,Mahout0.9.0。3、按数据分析过程及相似度计算所用的统计信息及数据,部署HadoopHDFS以及实现分析统计及计算的MapReduce业务代码。4、采集数据并且将数据表切割成文件块存储在分布文件系统HDFS中进行存储和管理。5、执行数据分析任务。6、数据结果在Web页面上呈现。以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。术语“多个”指两个或两个以上,除非另有明确的限定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1