基于转化医学分析平台的临床数据集成技术数据导入方法与流程
本发明属于数据集成技术领域,特别涉及实现了一个自动化程度高、适应能力强的tranSMART临床数据集成工具。
背景技术:
近年来随着精准医疗概念的提出与相关行业的蓬勃发展,在医疗过程中产生的临床数据,基因数据等被逐渐积累,而有效地分析这些数据里蕴藏的医学信息在医疗领域开始显得越来越重要。
tranSMART(转化医学分析平台)最初是给制药公司和药物研发结构提供一个数据协同管理平台。随后,tranSMART逐步被转为开源软件。并由tranSMART Foundation组织来接手进行持续地开发和维护。这个平台是基于I2B2临床医疗数据仓库开发的,因此tranSMART可以对结构化的临床数据,如人口学信息和临床病理数据等进行数据管理。
tranSMART可以让不同的群体用同一个数据仓库来整合内部和外部的数据资源。并且提供了系统级工具来检索,查看和分析仓库里的数据。tranSMART包含下面多个特色功能:
搜索工能。通过使用Solr搜索服务可以让研究者像使用谷歌、百度这样的搜索工具来搜索感兴趣的资源信息,搜索的功能包括搜索一个独特的种类,例如疾病、基因或者临床路径等其他种类。建立复杂的搜索条件,可以自定义要搜索的种类的复杂条件,并可以保存起来。
数据集管理功能。以I2B2设计为基础。可以支持自己定义研究的子集。可以定义条件,比较两个子集的差异。数据管理器的特色功能包括保存用于构建子集的条件。可以支持用多种分析算法来对数据分析。比如可以用主成分分析来减少数据集的维数。
基因印记向导功能。tranSMART提供一个向导来辅助创建和定义基因印记和基因列表。保存的标记的基因可以用来在数据集管理器的分析功能。基因标记向导的功能包括,私有的基因印记,这样只有自己可以访问私有的基因,同时也可以将基因改为公有让所有用户都可以用。可以克隆一个存在的基因印记。
tranSMART基于Groovy语言开发,Groovy可以理解成为一种可以运行在Jvm上的脚本语言。它和Java语言之间可以相互调用并且很好地融合在一起。同时它又具有脚本语言方便灵活的特性。尤其是其中的闭包概念,可以使程序简短并且易读性不会减弱。Groovy语言的许多特性可以大大减少代码量,尤其重要的是Groovy中的闭包概念,在用它实现的项目中,闭包被广泛应用。Groovy语言允许省略掉括号,省略掉分号。由此可以看到使用Groovy语言可以在很大程度上提高编程的效率。同时Groovy语言可以无缝调用Java已经有的一些框架以及一些工具包,事实上由于某些特性它和Spring框架结合的非常好。
tranSMART的设计是典型的N-Tier架构,分为数据处理层、业务处理层和展示层。tranSMART所使用的Grails框架,遵循一种约定大于配置的原则,只需要简单的几行配置就可以区分开发、生产、测试几种不同环境,并可以在启动系统时指定是哪种环境,有一些经过验证的良好预先设定,并提供大量的API,使开发可以很顺畅不需要过度关注已经很成熟的技术细节。同时依靠Grails产生的Web应用可以兼容如今的J2EE容器。Grails最为人称道的一点是它有丰富的插件,有一个专门的插件社区,并且这个社区一直在壮大。此外Grails还有对ORM以及NoSQL的支持。
tranSMART现有的数据集成技术有几种不同的实现方式。包括基于Kettle的tranSMART Data工具、tranSMART ICE工具以及脚本方式,还有使用存储过程的方式。这些工具在设计时只考虑了一次性导入数据的情况,而不能满足增量式地添加数据的需求,即满足数据的可更新性。而且二次开发的难度较大。最终选择了可以提供数据更新支持且基于Spring Batch开发的tranSMART Batch项目为基础,用于构建自主数据集成工具。
tranSMART Batch是以Spring Batch为框架的数据导入程序。可以导入不同类型的程序。如适用于临时研究的一次性导入的临床科研数据、基因数据、维度数据、I2B2数据等等。其中导入I2B2形式的数据,是可以满足数据的更新,以及解决数据向维度表分散的问题。
tranSMART Batch的实现是采用了Groovy语言。在自动化工具构建方面,tranSMART Batch使用了基于Ant和Maven概念的自动化构建工具Gradle。Gradle基于Groovy的特定领域语言(DSL)来声明项目设置。相对于Maven和Ant,Gradle抛弃了Ant和Maven的繁琐的XML配置。其他的Gradle的特性还有很多。比如将工程依赖的地位放得高。并支持局部构建。此外Gradle支持多方式的依赖构建。包括Maven仓库、Nexus私服、Ivy仓库以及本地文件系统的jars或者dirs。使用Gradle管理项目可以达到事半功倍的效果。在配置好数据库的连接信息以后,需要执行命令./GradlewSetupSchema来创建Spring Batch需要的数据库中的Schema,用于记录批处理的信息,以便回滚、记录等操作。tranSMART Batch是通过打好的jar包来执行导入数据的。通过执行定义好的capsule任务。可以得到一个用于导入数据的jar包。接下来需要配置数据库连接的配置信息。是一些常规的jdbc配置。包括所使用的driver、服务的位置、用户名、密码等。
使用tranSMARTBatch集成技术的数据导入方法说明如下:
步骤一:准备文件。准备的文件包括:
11)数据文件:即要导入到tranSMART(转化医学分析平台,以下称为平台)的数据文件,文件中第一行是表头行,用于对数据说明。从第二行开始,每一行代表一条数据,行中每个具体数据以制表符(’/t’)分隔。
12)列映射文件:列映射文件有固定的六列内容。分别为数据文件的文件名、数据列号、这个数据是否可以是空值、数据变量、数据类型(数值型数据或者文本型数据或是自然语言类型)、数据单位(如g、ml等单位)。其中数据变量就是用来描述数据含义的。数据变量的取值为一些预先定义的符号或者是代表着一个概念的概念路径。其中预先定义的符号包括有PAT_ID、PAT_SEX、VISIT_ID等。分别用于描述患者的ID,年龄、性别以及来访的ID。概念由概念路径和概念类型构成。概念路径是一个将概念以斜线分隔的文本,如‘\开放研究\心内疾病研究\’。
13)文本替换文件:文本替换文件的作用是将一些不符合预定义规范的数据清洗掉。因此这个文件需要指定哪个数据文件中的哪列需要从什么值替换为什么值。这个文件由四列,分别为文件名、数据列的列号、原来的值、想要替换成的值。如数据列“患者基本检查文件,1,男,m”。代表的意思是将患者基本检查文件的第一列中所有“男”的数据替换成“m”。步骤二:将在列映射文件中的出现概念的路径和概念的类型手工插入到tranSMART数据库中的概念表中,除了插入概念表外还需要插入相关的内容到I2B2表中。
步骤三:读入列映射文件:验证列映射文件中的数据是否满足设定的规则,如验证映射文件中给出的概念是否已经存在于数据库中的概念表中,用来保证数据的正确性的。
步骤四:第一次读取并处理数据:读取数据文件中的数据,首先根据文本替换文件中的定义将该数据替换成规范的值;然后对数据的正确性验证;补充一些数据的缺失信息。在遍历的过程中提取出病人的ID信息即在列映射文件中该列的数据变量为‘PAT_ID’的数据,以及来访的ID数据即在列映射文件中该列的数据变量为‘VIS_ID’的数据。
步骤五:将病人ID、来访ID数据导入到平台数据库并第二次读取数据文件中的数据。按行读取这些数据。根据文本替换文件中的定义,将定义列的不符合要求的数据替换成符合要求的数据;根据列映射文件中定义的列序号以及数据变量,标识出每条数据中的每个数据的具体表示含义;将病人信息数据与病人ID对应插入到平台数据库中的病人信息表中,将来访数据与来访ID对应插入到平台数据库中的来访信息表中,将数据变量中的概念类型的变量标识的数据与概念路径本身以及在列映射文件中定义的其他类型的数据单位、数据类型等相关数据插入到平台数据库中的观测事实表中,即完成数据导入。
上述的方法存在以下问题:
1.自动化程度不高。在步骤二中需要手工编辑大量数据。繁琐而且容易出错。
2.支持导入的数据组织形式只能为每列数据为同一个概念的形式。根据现有的列映射文件的设计与变量类型。无法集成概念与数值存在于同一行中的数据组织形式情况。
3.数据源支持单一。步骤一中需要准备要导入的数据文件。这个文件是文本形式。该方法不能直接从医院数据库中抽取数据。
4.在步骤第二次遍历数据中缺少异常处理机制。对于一些可以跳过的异常不会跳过,而是直接导致程序崩溃。
技术实现要素:
本发明的目的是为克服已有技术的不足之处,提出一种基于转化医学分析平台(tranSMART)的临床数据集成技术的数据导入方法,该方法具有自动化程度高、适应能力强的特点。
本发明提出的一种基于转化医学分析平台的临床数据集成技术数据导入方法,其特征在于,该方法用于文本型的数据的导入,具体包括以下步骤:
步骤一:准备文件,准备的文件包括:
11)数据文件:即要导入到平台的数据文件,文件中第一行是表头行,用于对数据说明;从第二行开始,每一行代表一条数据,行中每个具体数据以制表符(’/t’)分隔;
数据文件还包括数据值一列对应不同的概念的数据,但对应不同的概念的数据;12)列映射文件:列映射文件有固定的六列内容。分别为数据文件的文件名、数据列号、这个数据是否可以是空值、数据变量、数据类型、数据单位;其中数据变量就是用来描述数据含义的。数据变量的取值为预先定义的符号或者是代表着一个概念的概念路径;概念由概念路径和概念类型构成;概念路径是一个将概念以斜线分隔的文本;
还包括在数据变量中增加一个自定义的标识,体现一行中存在多个概念的数据变量的层级关系;
13)文本替换文件:用于是将一些不符合预定义规范的数据清洗掉;该文件由四列,分别为文件名、数据列的列号、原来的值、想要替换成的值;
14)用于构建概念树的文件:该文件有概念路径和概念类别两列,概念路径将概念分为不同层级,不同层级之间之间以斜线“\”分隔,概念类别包括类别型和数值型两类;步骤二:根据步骤一中构建的概念树文件的概念路径和概念类别中的层级,构建概念树;将概念树中的每个节点中的概念路径与概念类型插入到平台数据库中的概念表中,将概念路径与概念类型以及节点在概念树中的相对位置插入到平台数据库的I2B2表中;
步骤三:读入列映射文件,验证列映射文件中的数据是否满足设定的规则,用来保证数据的正确性的;
步骤四:第一次读取并处理数据:首先根据文本替换文件中的定义将该数据替换成规范的值;然后对数据的正确性验证;补充数据的缺失信息;提取出病人的ID信息即在列映射文件中该列的数据变量为‘PAT_ID’的数据,以及来访的ID数据即在列映射文件中该列的数据变量为‘VIS_ID’的数据;
加入自定义变量的标识。根据自定义标识的概念路径变量构造概念路径。根据自定义标识的概念类型变量构造概念类型。再次构造概念树,并将该概念树插入到平台数据库对应的表中;
步骤五:将病人ID、来访ID数据导入到平台数据库并第二次读取数据文件中的数据:按行读取这些数据,根据文本替换文件中的定义,将指定列的不符合要求的数据替换成符合要求的数据;根据列映射文件中定义的列序号以及数据变量,标识出每条数据中的每个数据的具体表示含义,将病人信息数据与病人ID对应插入到平台数据库中的病人信息表中,将来访数据与来访ID对应插入到平台数据库中的来访信息表中,将数据变量中的概念类型的变量标识的数据与概念路径本身以及在列映射文件中定义的其他类型的数据单位、数据类型等相关数据插入到平台数据库中的观测事实表中;如果导入数据出现异常情况,只做相关记录供以后查看;如果是网络异常或平台数据库系统异常,则回滚事物,并记录当前导入的状态;即完成数据导入。
本发明还包括用于源数据库中数据的导入。
本发明的特点及有益效果:
本发明的技术特点是:在tranSMART Batch基础上1.通过给出概念树文件。利用适当数据结构在内存中构建概念树,并自动填充tranSMART数据库中概念表和I2B2表的内容;2.通过在列映射文件中增加四个自定义变量,并实现根据自定义变量处理数据的功能,完成对原方法中不能集成的数据组织形式的集成;3.通过增加可以从数据库中读入数据的功能实现直接从数据库读入数据;4.通过在步骤第二次遍历数据中增加异常处理机制,使一些可以跳过的异常直接能跳过。
本发明的有益效果是:
本方法不但能将文本数据形式的临床数据正确、全面地导入到tranSMART分析平台中,还能导入源数据库中的数据,进而可以利用tranSMART的各种算法进行数据分析。
本方法在数据导入过程中没有损失医学上关键的信息,每一条临床科研数据都可以溯源。在发生特殊情况,如网络异常、数据库系统异常时,可以记录此次导入任务的成败,并选择是提交事务、还是回滚事务。保证了数据导入的正确性。
本方法的数据导入的自动化程度高。
本方法可以选择不同的数据源的形式,如文本或者是数据库。有完善的异常处理机制。可以导入数据值一列对应不同的概念的数据,适应能力强。
附图说明
图1是本发明的方法的总体流程框图。
图2是本发明与概念树构建相关的示意图。
具体实施方式
本发明提出的基于tranSMART平台的临床数据集成方法结合附图及实施方式做以下说明:
本发明方法是在tranSMART Batch基础上以Spring Batch为框架实现的。发明的具体实施方法如图1所示,用于文本型的数据的导入,具体包括以下步骤:
步骤一:准备文件,准备的文件包括:
11)数据文件:即要导入到平台的数据文件,文件中第一行是表头行,用于对数据说明。从第二行开始,每一行代表一条数据,行中每个具体数据以制表符(’/t’)分隔。
本方法的数据文件还可以包括数据值一列对应不同的概念的数据。但对应不同的概念的数据。如表1中24.6数值对应的概念是凝血酶原时间活动度,而30.2这个数值对应的概念为凝血酶原时间。
表1发明可以集成的样例数据
12)列映射文件:列映射文件有固定的六列内容。分别为数据文件的文件名、数据列号、这个数据是否可以是空值、数据变量、数据类型(数值型数据或者文本型数据或是自然语言类型)、数据单位(如g、ml等单位)。其中数据变量就是用来描述数据含义的。数据变量的取值为一些预先定义的符号或者是代表着一个概念的概念路径。其中预先定义的符号包括有PAT_ID、PAT_SEX、VISIT_ID等。分别用于描述患者的ID,年龄、性别以及来访的ID。概念由概念路径和概念类型构成。概念路径是一个将概念以斜线分隔的文本,如‘\开放研究\心内疾病研究\’。
本方法在列映射文件的数据变量中增加一个自定义的标识,在这个标识中体现一行中存在多个概念的数据变量的层级关系。以解决已有技术不能导入数据值一列对应不同的概念的数据。本实施例的列映射文件中数据变量的标识分为表示概念类型的数据变量的标识,表示数值的数据变量的标识,以及表示数值单位的数据变量的标识。
13)文本替换文件:文本替换文件的作用是将一些不符合预定义规范的数据清洗掉。因此这个文件需要指定哪个数据文件中的哪列需要从什么值替换为什么值。这个文件由四列,分别为文件名、数据列的列号、原来的值、想要替换成的值。如数据列“患者基本检查文件,1,男,m”。代表的意思是将患者基本检查文件的第一列中所有“男”的数据替换成“m”。
14)用于构建概念树的文件:该文件有概念路径和概念类别两列,概念路径将概念分为不同层级,不同层级之间之间以斜线“\”分隔,概念类别包括类别型和数值型两类。如表2所示是一个概念的概念树文件例子。
表2构建概念树文件例子
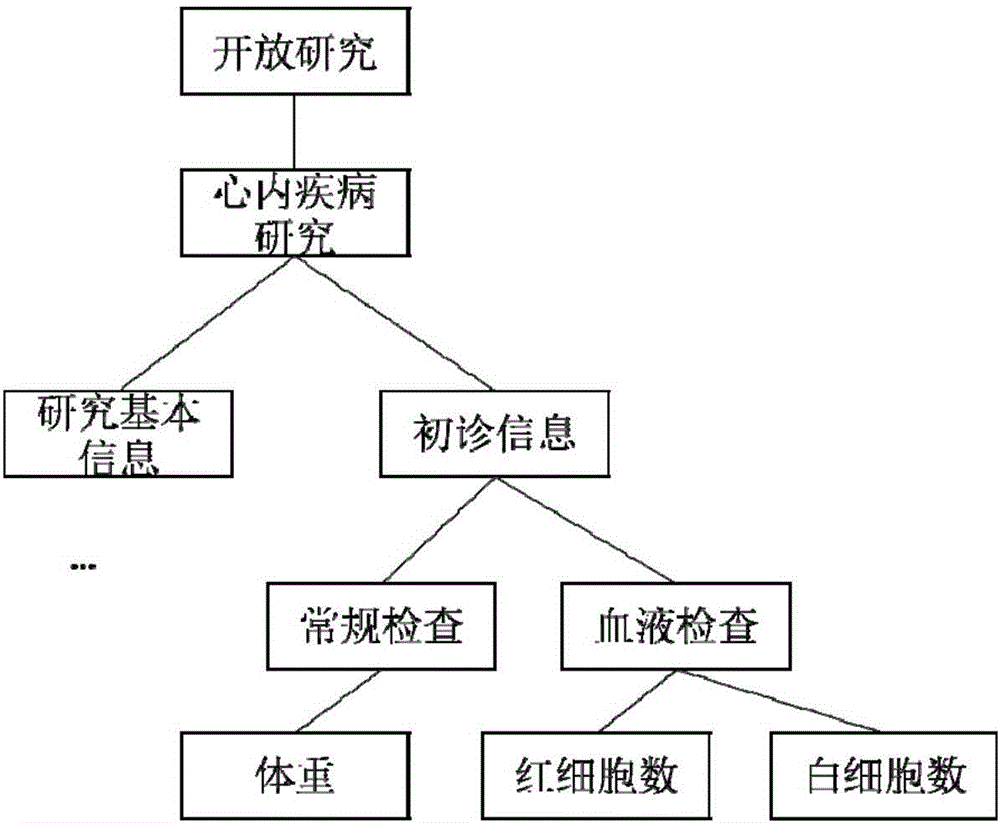
步骤二:根据步骤一中构建的概念树文件的概念路径和概念类别中的层级,构建概念树。如图2是根据表2中的数据构建出的概念树的样例。将概念树中的每个节点中的概念路径与概念类型插入到平台数据库中的概念表中,将概念路径与概念类型以及节点在概念树中的相对位置插入到平台数据库的I2B2表中。
步骤三:读入列映射文件,验证列映射文件中的数据是否满足设定的规则,如验证映射文件中给出的概念是否已经存在于数据库中的概念表中,用来保证数据的正确性的。
步骤四:第一次读取并处理数据。首先根据文本替换文件中的定义将该数据替换成规范的值;然后对数据的正确性验证;补充一些数据的缺失信息。提取出病人的ID信息即在列映射文件中该列的数据变量为‘PAT_ID’的数据,以及来访的ID数据即在列映射文件中该列的数据变量为‘VIS_ID’的数据。
在读入的时候,加入自定义变量的标识。根据自定义标识的概念路径变量构造概念路径。根据自定义标识的概念类型变量构造概念类型。再构造如图2的形式的概念树,并将该概念树插入到平台数据库对应的表中。
步骤五:将病人ID、来访ID数据导入到平台数据库并第二次读取数据文件中的数据:按行读取这些数据,根据文本替换文件中的定义,将指定列的不符合要求的数据替换成符合要求的数据;根据列映射文件中定义的列序号以及数据变量,标识出每条数据中的每个数据的具体表示含义,将病人信息数据与病人ID对应插入到平台数据库中的病人信息表中,将来访数据与来访ID对应插入到平台数据库中的来访信息表中,将数据变量中的概念类型的变量标识的数据与概念路径本身以及在列映射文件中定义的其他类型的数据单位、数据类型等相关数据插入到平台数据库中的观测事实表中;如果导入数据出现异常情况,如某些数据项目的缺失,某些数据项目的重复,只做相关记录供以后查看;如果是网络异常或平台数据库系统异常,则回滚事物,并记录当前导入的状态,包括配置信息、时间、异常情况等;即完成数据导入。
本发明还包括用于源数据库中数据的导入:
当要导入的数据是存在源数据库表中时,首先要在该源数据库中写好存储过程,存储过程返回想要导入数据的游标;同时对文本数据读入单元替换成从数据库中的存储过程读取数据的读入单元,并保证与文本读入单元读入后的结果相同;具体导入的步骤如下:
步骤一:准备文件:准备的文件包括:
11)列映射文件:列映射文件有固定的六列内容。分别为源数据库中预定义的存储过程名、数据列号、这个数据是否可以是空值、数据变量、数据类型(数值型数据或者文本型数据或是自然语言类型)、数据单位(如g、ml等单位)。其中数据变量就是用来描述数据含义的。数据变量的取值为一些预先定义的符号或者是代表着一个概念的概念路径。其中预先定义的符号包括有PAT_ID、PAT_SEX、VISIT_ID等。分别用于描述患者的ID,年龄、性别以及来访的ID。概念由概念路径和概念类型构成。概念路径是一个以斜线分隔的文本,如‘\开放研究\心内疾病研究\’。
本方法在列映射文件的数据变量中增加一个自定义的标识,在这个标识中体现一行中存在多个概念的数据变量的层级关系。以解决已有技术不能导入数据值一列对应不同的概念的数据。本实施例的列映射文件中数据变量的标识分为表示概念类型的数据变量的标识,表示数值的数据变量的标识,以及表示数值单位的数据变量的标识。
12)文本替换文件:文本替换文件的作用是将一些不符合预定义规范的数据清洗掉。因此这个文件需要指定哪个数据文件中的哪列需要从什么值替换为什么值。这个文件由四列,分别为文件名、数据列的列号、原来的值、想要替换成的值。如数据列“患者基本检查文件,1,男,m”。代表的意思是将患者基本检查文件的第一列中所有“男”的数据替换成“m”。
13)源数据库连接配置文件:包括源数据库的用户名、密码、是否自动重新连接等信息。
14)用于构建概念树的文件:该文件有概念路径和概念类别两列,概念分为不同层级,不同层级之间之间以斜线“\”分隔,概念类别包括类别型和数值型两类。如表2所示是一个概念的概念树文件例子。
表2构建概念树文件例子
步骤二:根据步骤一中构建的概念树文件的概念路径和概念类别中的层级,构建概念树。如图2是根据表2中的数据构建出的概念树的样例。将概念树中的每个节点中的概念路径与概念类型插入到平台数据库中的概念表中,将概念路径与概念类型以及节点在概念树中的相对位置插入到平台数据库的I2B2表中。
步骤三:读入列映射文件,验证列映射文件中的数据是否满足设定的规则,如验证映射文件中给出的概念是否已经存在于数据库中的概念表中,用来保证数据的正确性的。
步骤四:第一次遍历要导入的源数据库中的数据。首先根据文本替换文件中的定义将该数据替换成规范的值;然后对数据的正确性验证;补充一些数据的缺失信息。在遍历的过程中提取出病人的ID信息即在列映射文件中该列的数据变量为‘PAT_ID’的数据,以及来访的ID信息即在列映射文件中该列的数据变量为‘VIS_ID’的数据。
在读入的时候,加入自定义变量的标识。根据自定义标识的概念路径变量构造概念路径。根据自定义标识的概念类型变量构造概念类型。再构造如图2的形式的概念树,并将树插入到平台数据库对应的表中。
步骤五:将病人ID、来访ID数据导入到平台数据库并第二次遍历源数据库中的数据:按行读取源数据库中的数据,根据文本替换文件中的定义,将指定列的不符合要求的数据替换成符合要求的数据;根据列映射文件中定义的列序号以及数据变量,标识出每条数据中的每个数据的具体表示含义,将病人信息数据与病人ID对应插入到平台数据库中的病人信息表中,将来访数据与来访ID对应插入到平台数据库中的来访信息表中,将数据变量中的概念类型的变量标识的数据与概念路径本身以及在列映射文件中定义的其他类型的数据单位、数据类型等相关数据插入到平台数据库中的观测事实表中;如果导入数据出现异常,如某些数据项目的缺失,某些数据项目的重复,只做相关记录供以后查看;如果是网络异常或平台数据库系统异常,则回滚事物,并记录当前导入的状态,包括配置信息、时间、异常情况等;即完成数据导入。
- 还没有人留言评论。精彩留言会获得点赞!