基于模糊边界分片的深度动作图人体行为识别方法与流程
本发明属于机器视觉领域,特别涉及一种基于模糊边界分片的深度动作图人体行为识别方法。
背景技术:
:
人体行为识别技术是通过处理人体行为的视频序列,从中提取行为特征,并通过这些特征识别动作的一种技术。
在机器视觉和模式识别领域,人体行为识别现在已经成为一个非常活跃的分支。这种技术在人机交互领域有着许多潜在的应用,包括视频分析、监控系统,智能机器人等。前几年,人体行为识别方向的研究主要基于彩色摄像头采集的图像帧序列[1][2].这种数据有着固有的缺陷,它们对于光照、遮挡以及复杂的背景十分敏感,影响识别精度。如今深度摄像头得到了广泛的关注,这种传感器能够提供物体的3D结构信息,包括人体的形状以及动作信息。目前提取深度的特征方法主要有两个分支:基于估计的3D骨骼点的方法[3]和基于原始深度图像的方法。但是这种关节点估算有时会出现错误,特别是对于人体部分遮挡或者背景复杂的情况。C.Chen等[4]通过计算原始深度图像的深度动作图(DMM,Depth Motion Maps),并通过PCA降维后利用像素点作为特征得到了相对较好的结果。但这种方法将所有视频帧累加在一张DMM上,丢失了动作的时间信息。
本发明针对上述人体行为识别存在的问题,提出了一种基于模糊边界分片的深度动作图的人体行为识别方法,不仅吸取了原始深度图像信息相对于骨骼信息的优点,并且使用模糊边界分片的技术对DMM进行分片,提取了动作的时间信息,对光照、遮挡、复杂背景等因素具有较高鲁棒性。
技术实现要素:
:
本发明的主要目的是提出一种基于模糊边界分片的深度动作图人体行为识别方法,捕获动作的时间信息并使用鲁棒的概率协作表示分类器R-ProCRC(Robust Probabilistic Collaborative Representation based Classifier)[5]来进行分类,提高识别精度。
为了实现上述目的,本发明提供如下技术方案,包含训练阶段和测试阶段。
基于模糊边界分片的深度动作图的人体行为识别方法训练阶段技术方案如下:
步骤一:给定人体行为视频序列的深度图样本的训练集合其中X(k)表示第k个训练样本的深度图序列,为第k个样本中第i帧的原始深度图像,Nk为第k个样本的总帧数;Y(k)表示第k个训练样本所属行为类别;M表示训练集中样本个数;
步骤二:将训练集中每个视频序列训练样本X(k)按时间轴直接划分为DIV个等长时间片,每个时间片长度为划分后的时间片表示为其中
步骤三:选择合适的模糊参数α,对每个时间片进行分片模糊处理;模糊时间片表示为为避免下标溢出,对于第一个时间片不做前向模糊处理,对最后一个时间片不做后向模糊处理;
步骤四:计算每个模糊时间片在三个不同投影方向的深度动作图其中v∈{f,s,t}分别表示视频序列投影的三视图(三个方向),主视图、左视图和俯视图;至此,计算获得所有训练样本对应的深度动作图集合
步骤五:利用双三次差值法将步骤四求解获得的深度动作图调整为一个相同的尺寸,并将这些深度动作图归一化为0到1之间,归一化后的记为
步骤六:将任一训练样本X(k)对应深度动作图集合进行向量化,并将所有向量化后的序列动作图串联,完成训练样本X(k)对应的特征构建,该特征记为H(k),则所有样本的特征集合表示为{H(k)}k∈[1M];
步骤七:将步骤六得到的所有样本的输出特征{H(k)}k∈[1M]通过PCA降维,并保存所有降维后的特征
基于模糊边界分片的深度动作图的人体行为识别方法的测试阶段技术方案如下:
步骤一:给定一个人体行为视频序列的深度图样本的测试样本(TestX,TestY),其中TestX表示测试样本的深度图序列,Xi为测试样本中第i帧的原始深度图像,NT为该测试样本的总帧数;TestY表示测试样本所属行为类别;
步骤二:将测试样本TestX按时间轴直接划分为DIV个等长时间片(分片方式与训练阶段相同),每个时间片长度为划分后的时间片表示为其中
步骤三:根据训练阶段采用的模糊参数α,对每个时间片进行分片模糊处理;模糊时间片表示为为避免下标溢出,对于第一个时间片不做前向模糊处理,对最后一个时间片不做后向模糊处理;
步骤四:计算每个模糊时间片在三个不同投影方向的深度动作图DMMj,v,其中v∈{f,s,t}分别表示视频序列投影的三视图(三个方向),主视图、左视图和俯视图;至此,计算获得测试样本TestX对应的深度动作图集合{DMMj,v}j∈[1DIV],v∈[f,s,t];
步骤五:利用双三次差值法将步骤四求解获得的测试样本深度动作图{DMMj,v}j∈[1DIV],v∈[f,s,t]调整为训练阶段同一尺寸,并根据训练阶段归一化方法,将这些深度动作图归一化为0到1之间,归一化后的DMMj,v记为
步骤六:将测试样本TestX对应的深度动作图集合进行向量化,并将所有向量化后的序列动作图串联,完成测试样本TestX对应的特征构建,该特征记为HT;
步骤七:将步骤六得到的测试样本TestX的输出特征HT通过PCA降维,得到降维后的特征PCA降维方法与训练阶段一致;
步骤八:然后将降维后的输出特征送入R-ProCRC[5]分类器,获得分类输出PridY;
步骤九:比较PridY和TestY,若PridY=TestY,则识别正确,否则识别错误。
与现有的技术相比,本发明具有以下有益效果:
1、本方法采用深度数据来进行人体行为识别,相比于传统的彩色视频数据,深度数据能够实现对人体的高效分割,同时保存了人体的形状和结构特征,有助于提高分类精度;
2、传统的利用深度动作图DMM的特征提取方法将整个视频帧投影到一张DMM图上,丢失时间了信息。本方法提出的模糊边界分片的深度动作图人体行为识别方法,将深度图序列进行时间维度的分片,有效捕获了时域特征的变化规律;
3、针对人体行为时域差异性,本方法提出的模糊边界分片的深度动作图的人体行为识别方法,使用模糊参数α来控制分片之间的边界,使得相邻分片信息得到共享,进一步提高了特征对人体行为时域差异的鲁棒性,配合使用R-ProCRC分类器识别精度得到显著提高。
附图说明:
图1基于模糊边界分片的深度动作图的人体行为识别特征构建方法流程图;
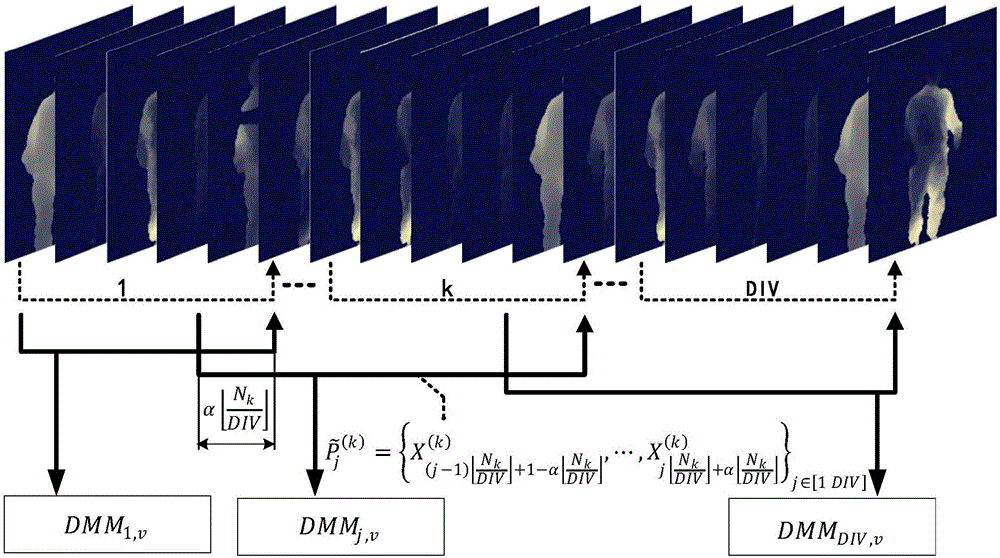
图2模糊边界分片策略示意图;
图3深度动作图在三个视角下的投影实例图;
具体实施方式
为了更好的说明本发明的目的、具体步骤以及特点,下面结合附图,以MSR Action3D数据集为例,对本发明作进一步详细的说明:
本发明提出的模糊边界分片的深度动作图的人体行为识别方法,其中特征提取的流程图如图1所示。首先对样本进行确定边界的等量分片,然后根据参数α来确定边界的模糊程度,对于每一个分片后的视频子序列都计算它的深度动作图DMM,利用双三次差值法将所有样本的DMM固定到一个相同的尺寸,并归一化,串联向量化后得到子序列的特征,完成训练样本的输出特征的构建。
本发明提出的一种基于模糊边界分片的深度动作图的人体行为识别方法,包含训练阶段和测试阶段。
基于模糊边界分片的深度动作图的人体行为识别方法训练阶段技术方案如下:
步骤一:给定人体行为视频序列的深度图样本的训练集合其中X(k)表示第k个训练样本的深度图序列,为第k个样本中第i帧的原始深度图像,Nk为第k个样本的总帧数;Y(k)表示第k个训练样本所属行为类别;M表示训练集中样本个数;
步骤二:将训练集中每个视频序列训练样本X(k)按时间轴直接划分为DIV个等长时间片,每个时间片长度为划分后的时间片表示为其中
步骤三:选择合适的模糊参数α,对每个时间片进行分片模糊处理;模糊时间片表示为为避免下标溢出,对于第一个时间片不做前向模糊处理,对最后一个时间片不做后向模糊处理;
步骤四:计算每个模糊时间片在三个不同投影方向的深度动作图其中v∈{f,s,t}分别表示视频序列投影的三视图(三个方向),主视图、左视图和俯视图;至此,计算获得所有训练样本对应的深度动作图集合
步骤五:利用双三次差值法将步骤四求解获得的深度动作图调整为一个相同的尺寸,并将这些深度动作图归一化为0到1之间,归一化后的记为
步骤六:将任一训练样本X(k)对应深度动作图集合进行向量化,并将所有向量化后的序列动作图串联,完成训练样本X(k)对应的特征构建,该特征记为H(k),则所有样本的特征集合表示为{H(k)}k∈[1M];
步骤七:将步骤六得到的所有样本的输出特征{H(k)}k∈[1M]通过PCA降维,并保存所有降维后的特征
基于模糊边界分片的深度动作图的人体行为识别方法的测试阶段技术方案如下:
步骤一:给定一个人体行为视频序列的深度图样本的测试样本(TestX,TestY),其中TestX表示测试样本的深度图序列,Xi为测试样本中第i帧的原始深度图像,NT为该测试样本的总帧数;TestY表示测试样本所属行为类别;
步骤二:将测试样本TestX按时间轴直接划分为DIV个等长时间片(分片方式与训练阶段相同),每个时间片长度为划分后的时间片表示为其中
步骤三:根据训练阶段采用的模糊参数α,对每个时间片进行分片模糊处理;模糊时间片表示为为避免下标溢出,对于第一个时间片不做前向模糊处理,对最后一个时间片不做后向模糊处理;
步骤四:计算每个模糊时间片在三个不同投影方向的深度动作图DMMj,v,其中v∈{f,s,t}分别表示视频序列投影的三视图(三个方向),主视图、左视图和俯视图;至此,计算获得测试样本TestX对应的深度动作图集合{DMMj,v}j∈[1DIV],v∈[f,s,t];
步骤五:利用双三次差值法将步骤四求解获得的测试样本深度动作图{DMMj,v}j∈[1DIV],v∈[f,s,t]调整为训练阶段同一尺寸,并根据训练阶段归一化方法,将这些深度动作图归一化为0到1之间,归一化后的DMMj,v记为
步骤六:将测试样本TestX对应的深度动作图集合进行向量化,并将所有向量化后的序列动作图串联,完成测试样本TestX对应的特征构建,该特征记为HT;
步骤七:将步骤六得到的测试样本TestX的输出特征HT通过PCA降维,得到降维后的特征PCA降维方法与训练阶段一致;
步骤八:然后将降维后的输出特征送入R-ProCRC[5]分类器,获得分类输出PridY;
步骤九:比较PridY和TestY,若PridY=TestY,则识别正确,否则识别错误。
上述技术方案中,训练阶段步骤二对视频序列进行等长时间片划分的方法中,分片数DIV的选择根据具体的人体行为样本数据集来确定最优分片数,以MSR Action3D数据集为例,DIV=3。
上述技术方案中,训练阶段步骤二对视频序列进行等长时间片划分的方法中,每个时间片长度为时间片长度采用向下取整方式;最后一个时间片若长度不足则按实际长度选取;
上述技术方案中,训练阶段步骤三对时间片的分片模糊处理中,模糊参数α的选择根据具体的人体行为样本数据集来确定最优参数,以MSR Action3D数据集为例,α=0.8。
上述技术方案中,训练阶段步骤三对时间片的分片模糊处理中,对每个样本的第一个时间片不做前向模糊处理;对每个样本的最后一个时间片不做后向模糊处理。
上述技术方案中,训练阶段步骤二和步骤三共同完成了视频序列的模糊分片处理,如图2所示,模糊参数α控制了分片之间的边界,使得相邻分片信息得到共享,进一步提高了特征对人体行为时域差异的鲁棒性。
上述技术方案中,训练阶段步骤四对各个模糊时间片在三个不同投影方向的深度动作图的计算采用视频帧绝对差叠加的方法,具体为:
对同一时间片内的视频帧做三个视觉方向的投影,获得各个视频的主视图、左视图和俯视图,接着对相邻帧的同一视角投影相减,相减后绝对值进行叠加,这样动作的轨迹就被保存了下来,具体公式如下:
其中和分别表示第k个样本中的第一个时间片和最后一个时间片,v∈{f,s,t}分别表示视频序列投影的三视图(三个方向),即主视图、左视图和俯视图;表示第k个样本中第i帧深度图的v方向投影;j∈(2,…,DIV-1),α∈(0,1);如图3所示,各投影方向的DMM图有效保存了人体行为序列的单个模糊分片在三个投影方向的轨迹信息。
上述技术方案中,训练阶段步骤五采用双三次差值法将深度动作图调整为同一尺寸,本专利采用的主视图、左视图和俯视图的尺寸分别定义为:50×25,50×40,40×20;在实际实施中,可以选择不同的插值法实现深度动作图尺寸的缩放,选择前提为尽量减少图像信息的损失。
上述技术方案中,训练阶段步骤七对步骤六计算得到的所有样本的输出特征{H(k)}k∈[1M]通过PCA降维,具体降维后的特征维数可根据训练样本的个数而定,在本专利实施实例中,若训练样本的个数为M,则最终的特征维数为(M-20)×1。
上述技术方案中,测试阶段步骤二至步骤六采用的特征构造方法及参数与训练阶段相同。
上述技术方案中,测试阶段步骤七采对PCA对步骤六计算得到的测试样本TestX的输出特征HT降维,降维后的维数为(M-20)×1,M为训练阶段样本个数。
上述技术方案中,测试阶段步骤八使用R-ProCRC分类对步骤七获得的降维后的行为特征进行分类的具体方法为:
(1)计算最优参数
其中是降维后的训练特征,HT为测试样本特征,是属于类别c(c∈C)的所有输入特征向量的集合,‖C‖为总类别数,λ和γ是0到1之间的参数;其中的构造方法为:首先将初始化为与字典相同尺寸的0矩阵,接着将分配到中,位置为在中的相对位置,即可得到例如的值为:是一个对角化的权重矩阵:
这里,表示第i行的所有元素,表示测试样本特征向量的第i个值;
(2)估计测试样本输出特征属于类别c的概率
测试样本输出特征属于类别c的概率估计方法如下:
对于所有样本来说都是相同的,因此上式可以简化为:
由此可以得到特征所属的类别。
为验证本发明的有效性,本发明在著名的人体行为深度信息数据库MSR Action3D、Action Pair上先后进行了实验。表1给出了两种人体行为深度信息数据库的特性。
表1:深度数据库特性描述
如表2所示,在实验中我们将MSR Action3D数据库分成三个固定的子集,。每个子集都使用3种实验方式,Test One将每个subject的第一次演示行为作为训练集,剩余的作为测试集。Test Two将每个subject的前两次演示行为作为训练集,剩余的作为测试集。Cross Test使用1,3,5,7,9这些subject的所有视频序列作为训练集,其余用做测试。实验结果见表3,可见本发明的行为识别精度在大多数情况下都优于传统的DMM方法。
表2:MSR Action3D数据库子集
表3:MSR Action3D数据库子集对比
表4显示了本发明在Action Pair数据库上的识别率以及与DMM的对比。由于Action Pair数据库行为都是存在大量动作时序相反的行为,比如“捡起”和“放下”,“起立”和“坐下”等,因此对时间信息十分敏感。传统的DMM只有50.6%的识别率,而本发明的识别率达到了97.2%。
表4:Action Pair不同算法识别率
由于本发明采用深度数据来进行人体行为识别,相比于传统的彩色视频数据,深度数据能够快速精准地完成人体分隔,保存人体的形状和结构特征,利于提高精度,同时使用深度动作图DMM的处理方式,相对于基于骨骼跟踪技术估计获得的骨骼点有更好的鲁棒性;传统的利用深度动作图DMM的特征提取方法将整个视频帧投影到一张DMM图上,丢失时间了信息;本方法提出的模糊边界分片的深度动作图的人体行为识别,将现有的DMM进行分片,并使用模糊参数α来控制分片之间的边界,使得相邻分片信息得到共享,也使得DMM能够更好的捕获时间信息,配合使用R-ProCRC[5]分类器可以获得卓越的识别准确率。
上面结合附图对本发明的具体实施方式做了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
参考文献
[1].Bian W,Tao D,Rui Y.Cross-domain human action recognition.[J].IEEE Transactions on Systems Man&Cybernetics Part B Cybernetics A Publication of the IEEE Systems Man&Cybernetics Society,2012,42(2):298-307.
[2].Niebles J C,Wang H,Li F F.Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words[J].International Journal of Computer Vision,2008,79(3):299-318.
[3].Wang J,Liu Z,Wu Y,et al.Mining actionlet ensemble for action recognition with depth cameras[C]//IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society,2012:1290-1297.
[4].Chen C,Liu K,Kehtarnavaz N.Real-time human action recognition based on depth motion maps[J].Journal of Real-Time Image Processing,2013:1-9.
[5].Sijia C,Lei Z,et al.A Probabilistic Collaborative Representation based Approach for Pattern Classification.IEEE Trans.on Pattern Analysis and Machine Intelligence,2016.
[6].Xu H,Chen E,Liang C,et al.Spatio-Temporal Pyramid Model based on depth maps for action recognition[C]//Mmsp2015 IEEE,International Workshop on Multimedia Signal Processing.2015。
- 还没有人留言评论。精彩留言会获得点赞!