一种基于半监督谱聚类的黑启动分区方法与流程
本发明涉及一种黑启动分区方法,尤其指一种基于半监督谱聚类的黑启动分区方法。
背景技术:
大停电后的电力系统恢复可分为黑启动、网络重构和负荷恢复三个阶段。网络重构阶段的主要任务是尽快为失电机组送电并逐步建立起一个稳定的网架结构,为下一阶段全面恢复负荷打下坚实的基础。网络重构阶段的系统恢复策略总体上可分为两类:串行恢复和并行恢复。串行恢复策略在大多数发电机并网前接力恢复各厂站;并行恢复策略将系统分成几个子系统先各自独立恢复,待各子系统恢复完成后再通过并网来实现整个系统的恢复。因此,合理的分区策略可有效降低系统恢复问题的复杂度,从而加快系统恢复进程。现有分区方法多数存在对算法初值依赖性强、难以获得全局最优解等缺点。
技术实现要素:
本发明要解决的技术问题和提出的技术任务是对现有技术方案进行完善与改进,提供一种基于半监督谱聚类的黑启动分区方法,以达到获得全局最优解的目的。为此,本发明采取以下技术方案。
一种基于半监督谱聚类的黑启动分区方法,包括以下步骤:
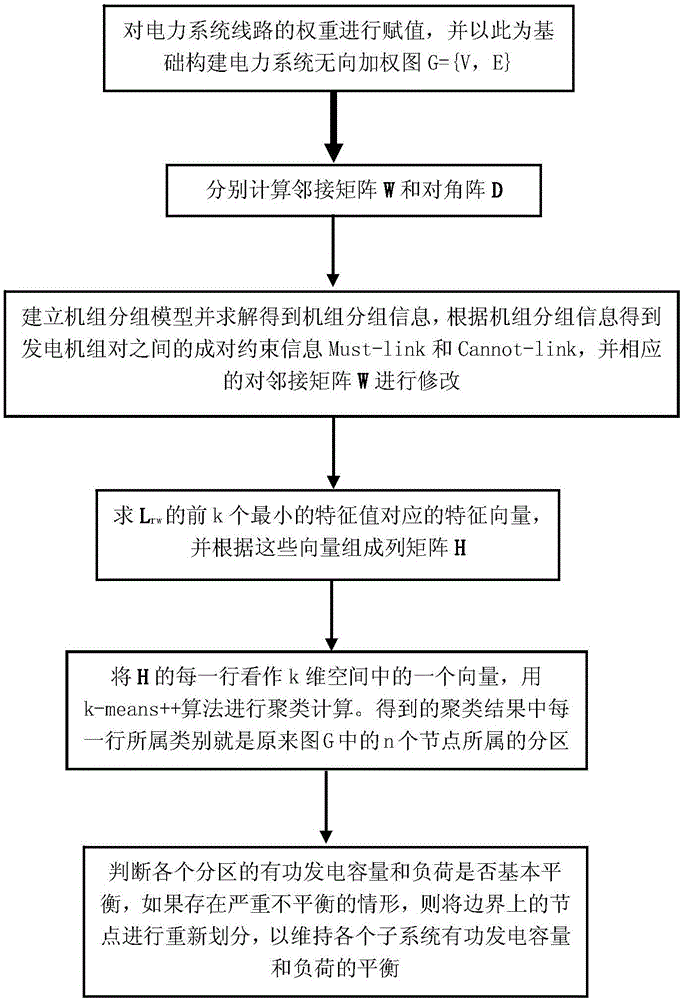
1)步骤S1:对电力系统线路的权重进行赋值,并以此为基础构建电力系统无向加权图G={V,E};
2)步骤S2:分别计算邻接矩阵W和对角阵D;
3)步骤S3:建立机组分组模型并求解得到机组分组信息,根据机组分组信息得到发电机组对之间的成对约束信息Must-link和Cannot-link,并相应的对邻接矩阵W进行修改;
4)步骤S4:计算规范化拉普拉斯矩阵Lrw=D-1(D-W);
5)步骤S5:求Lrw的前k个最小的特征值对应的特征向量,并根据这些向量组成列矩阵H;
6)步骤S6:将H的每一行作为k维空间中的一个向量,进行聚类计算;得到的聚类结果中每一行所属类别为原来图G中的n个节点所属的分区;
7)步骤S7:判断各个分区的有功发电容量和负荷是否基本平衡,当不平衡度超过设定值时,则将边界上的节点进行重新划分,以维持各个子系统有功发电容量和负荷的平衡。
本技术方案首先采用节点间的有功潮流和电气距离这两个因素为线路权重赋值,在此基础上建立电力系统无向加权图,进而依据比例割集准则建立黑启动分区策略。该策略由两步构成:第一步建立待恢复机组的分组模型,其以最大化系统发电量和最小化恢复线路总电容为目标,从而保证机组的安全快速启动;第二步以得到的机组分组信息为基础,利用半监督谱聚类算法求解黑启动分区模型。为了克服传统k-means算法对初始聚类中心敏感的缺点,在利用半监督谱聚类算法对特征向量进行聚类的最后一步采用了k-means++算法对特征向量进行聚类。本技术方案具有能够识别任意形状的样本空间并能够收敛于全局最优解且适用于分区问题。
作为对上述技术方案的进一步完善和补充,本发明还包括以下附加技术特征。
进一步的,步骤S1中的对电力系统线路的权重进行赋值的计算公式为:
wij=max((|Pij|-Dij),0)
式中:wij为节点i与j之间线路的权值;|Pij|为节点i与j之间线路的有功潮流的绝对值;Dij为节点i与j之间的电气距离,Dij用节点阻抗矩阵表示为:
Dij=Zii+Zjj-2Zij
式中:Zii/Zjj和Zij分别为节点阻抗矩阵第i/j个对角元素和第i行第j列元素。
在计算线路权值时所用的潮流和电气距离数据均预先进行min-max归一化处理。
进一步的,步骤S2中邻接矩阵W的计算方法为:
经过线路赋权后,电力系统拓扑结构简化为无向加权图G={V,E},其中V={v1,v2,…,vn}是网络中所有节点的集合,vi表示第i个节点,n为网络中节点的数目,E={e1,e2,…,em}代表节点间边的集合,且ei表示第i条边,m为网络中边的数目;邻接矩阵W,其元素wij的取值如下:若vi和vj为相邻节点,则wij等于vi和vj之间边的权值;若vi和vj为不相邻的节点,则wij=0;若i=j,则wij=0;
其中wij=wji。
步骤S3中机组分组模型为:
式中:b是分组个数;q是分组编号;Nq为分组q内的待恢复机组个数;r是所有待恢复机组的个数;α为比例系数,用于反映两个目标间的相对重要程度;[0,TC]是设定的时间区间;是分组q中机组g在t时刻所恢复的输出有功功率;Pstart,g(t)是机组g在t时刻消耗的有功功率;Pneed,g是启动机组g所需要的最小启动功率;tstart,g和tcrank,g分别是机组g的启动时刻(对于非黑启动机组,其启动时刻为获取启动功率的时刻)和开始爬坡对应的时刻;Rg是机组g的爬坡速率;Pmax,g是机组g的最大输出有功功率;Cl是线路l的充电电容,Ω是系统中已恢复线路的集合;此外,在恢复过程中,满足发电机出力约束、火电机组的热启动时间约束、机组的冷启动时间约束;
采用遗传算法求解上式机组分组模型得到机组分组信息。
进一步的,步骤S3中邻接矩阵W的修改方式如下:
假定机组vGi和机组vGj在机组分组模型求解后被分到了同一组中,则(vGi,vGj)∈Must-link;若机组vGi和机组vGj在机组分组模型求解后被分到了不同组中,则(vGi,vGj)∈Cannot-link。同时,Must-link约束和Cannot-link约束也具有对称性,且Must-link约束还具有传递性,其关系可描述如下:
Must-link约束和Cannot-link约束需要对邻接矩阵做如下修改:
进一步的,所述步骤S6中kmeans++算法的具体步骤为:
步骤601:从数据点集合X中任意的选择一个点x1作为第一个初始聚类中心;
步骤602:对于数据集中的每一个数据点xi,计算它与已选择的最近的初始聚类中心之间的距离D(xi);
步骤603:以为概率选择一个新的数据点作为初始聚类中心;
步骤604:重复步骤2和步骤3直到k个初始聚类中心都被选出;
步骤605:利用这k个初始聚类中心来执行标准的k-means算法。
有益效果:
1.本技术方案第一步时首先建立的机组分组模型可以保证机组的安全快速启动。
2.采用的半监督谱聚类具有能够识别任意形状的样本空间并能够收敛于全局最优解且适用于分区问题。
3.采用k-means++算法对特征向量进行聚类避免了传统k-means算法对初始聚类中心比较敏感的缺点。
附图说明
图1是本发明的方法流程图。
图2是本发明一实施例的新英格兰10机39节点系统拓扑结构。
图3是本发明图1所示实施例的分区结果示意图。
具体实施方式
以下结合说明书附图对本发明的技术方案做进一步的详细说明。
步骤S1:对电力系统线路的权重进行赋值,并以此为基础构建电力系统无向加权图G={V,E}。
线路权值的定义如下:
wij=max((|Pij|-Dij),0)
式中:wij为节点i与j之间线路的权值;|Pij|为节点i与j之间线路的有功潮流的绝对值。由于在系统恢复前制定黑启动分区策略时无法预知系统恢复后的联络线潮流,所以本文利用停电前线路的有功功率的绝对值作为|Pij|的近似值。Dij为节点i与j之间的电气距离。Dij可用节点阻抗矩阵表示为:
Dij=Zii+Zjj-2Zij
式中:Zii/Zjj和Zij分别为节点阻抗矩阵第i/j个对角元素和第i行第j列元素。
需要指出,在计算线路权值时所用的潮流和电气距离数据均需预先进行min-max归一化处理。
步骤S2:分别计算邻接矩阵W和对角阵D。
邻接矩阵W的计算方法如下:
经过线路赋权后,电力系统拓扑结构可简化为无向加权图G={V,E},其中V={v1,v2,…,vn}是网络中所有节点的集合,vi表示第i个节点,n为网络中节点的数目,E={e1,e2,…,em}代表节点间边的集合,且ei表示第i条边,m为网络中边的数目。设W为邻接矩阵,其元素wij的取值如下:若vi和vj为相邻节点,则wij等于vi和vj之间边的权值;若vi和vj为不相邻的节点,则wij=0;若i=j,则wij=0。
本发明研究主要针对无向图,故wij=wji。
步骤S3:建立机组分组模型并求解得到机组分组信息,根据机组分组信息得到发电机组对之间的成对约束信息Must-link和Cannot-link,并相应的对邻接矩阵W进行修改。
机组分组模型如下:
式中:b是分组个数;q是分组编号;Nq为分组q内的待恢复机组个数;r是所有待恢复机组的个数;α为比例系数,用于反映两个目标间的相对重要程度。[0,TC]是设定的时间区间。是分组q中机组g在t时刻所恢复的输出有功功率;Pstart,g(t)是机组g在t时刻消耗的有功功率;Pneed,g是启动机组g所需要的最小启动功率。tstart,g和tcrank,g分别是机组g的启动时刻(对于非黑启动机组,其启动时刻为获取启动功率的时刻)和开始爬坡对应的时刻。Rg是机组g的爬坡速率。Pmax,g是机组g的最大输出有功功率。Cl是线路l的充电电容,Ω是系统中已恢复线路的集合。此外,在恢复过程中,还需要满足发电机出力约束、火电机组的热启动时间约束、机组的冷启动时间约束等。
采用遗传算法求解上式所述的机组分组模型得到机组分组信息。
邻接矩阵W的修改方式如下:
假定机组vGi和机组vGj在机组分组模型求解后被分到了同一组中,则(vGi,vGj)∈Must-link;若机组vGi和机组vGj在机组分组模型求解后被分到了不同组中,则(vGi,vGj)∈Cannot-link。同时,Must-link约束和Cannot-link约束也具有对称性,且Must-link约束还具有传递性,其关系可描述如下:
Must-link约束和Cannot-link约束需要对邻接矩阵做如下修改:
步骤S4:计算规范化拉普拉斯矩阵Lrw=D-1(D-W)。
步骤S5:求Lrw的前k个最小的特征值对应的特征向量,并根据这些向量组成列矩阵H。
步骤S6:将H的每一行看作k维空间中的一个向量,用k-means++算法进行聚类计算。得到的聚类结果中每一行所属类别就是原来图G中的n个节点所属的分区。
kmeans++算法的具体步骤如下:
步骤S601:从数据点集合X中任意的选择一个点x1作为第一个初始聚类中心。
步骤S602:对于数据集中的每一个数据点xi,计算它与已选择的最近的初始聚类中心之间的距离D(xi)。
步骤S603:以为概率选择一个新的数据点作为初始聚类中心。
步骤S604:重复步骤2和步骤3直到k个初始聚类中心都被选出来。
步骤S605:利用这k个初始聚类中心来执行标准的k-means算法。
步骤S7:判断各个分区的有功发电容量和负荷是否基本平衡,如果存在严重不平衡的情形,则将边界上的节点进行重新划分,以维持各个子系统有功发电容量和负荷的平衡。
如图2所示,以新英格兰10机39节点系统拓扑结构。通过本发明的黑启动分区后,得到如图3所示的分区结果示意图。本技术方案本在第一步时首先建立的机组分组模型可以保证机组的安全快速启动;其次,采用的半监督谱聚类具有能够识别任意形状的样本空间并能够收敛于全局最优解且适用于分区问题;最后,采用k-means++算法对特征向量进行聚类避免了传统k-means算法对初始聚类中心比较敏感的缺点。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!