本发明属于软件测试技术领域,且特别是有关于一种回归测试用例自动分类方法,该方法用于降低回归测试能耗,提高回归测试自动化效率。
背景技术:
软件测试是一项保障软件质量与可靠性的重要活动。由于适应性维护、完善性维护与改正性维护等原因,软件处于动态演化而非静态存在。软件一旦发生变化就需要回归测试(regressiontesting)被测软件,以确保新的变化没有对软件产生副作用。回归测试已被实践证实是软件开发与维护过程中代价最昂贵的活动之一,占了软件维护阶段总费用的50%,总测试预算的80%。软件的复杂性以及回归测试高昂的测试代价对软件测试与维护人员提出了新的挑战,有效地降低回归测试能耗,提高回归测试的效率已成为软件工程研究领域和工业界亟待解决的问题。
与一般的软件测试技术相同,回归测试主要由三部分组成:构造测试用例、执行测试以及评判测试结果。其中,评判结果是通过比较运行测试用例产生的输出结果与预期的结果,作为测试通过与否的判断,据此判定被测软件的执行行为是否符合规范。评估结果的过程正是借助测试预言(testoracle)加以实现的,即对于一个给定的测试用例作为输入,运行被测软件,通过比较被测软件的输出与测试预言的一致性判定被测软件执行行为的正确性。
回归测试背景下,无论是在演化的软件版本上运行已有的测试用例,还是运行新增的测试用例,都需要基于测试预言检验被测软件的运行是否正确。然而,测试预言的构建是非常耗时耗力的工作。例如:验证医学图像分割软件就需要利用医生的专业知识构建测试预言,据此判定分割的图像是否正确。软件演化使得历史版本中的测试用例所对应的测试预言在当前版本上失效,这就需要基于演化的软件版本为原有的测试用例重新构造测试预言。同样地,为满足测试充分性要求增加新的测试用例时也需要为其构造测试预言。在当前的工业界,仍是借助手工方式产生测试预言。这不仅消耗更多的测试资源,而且很容易产生错误。伴随软件的多样性,以及规模的不断增加,测试预言的自动化技术远不能满足实际需要。
传统的回归测试用例分类方法需要借助手工方式构造测试预言,并借此判定测试用例的类别。这意味着回归测试需要消耗更多的测试资源,严重影响软件版本的发布进度。在回归测试背景下,如果不构造测试预言而又能自动判定测试用例的类别将大大地降低回归测试能耗,提高回归测试的效率。软件演化为回归测试提供了丰富的运行时信息,主要包括测试用例的执行剖面信息和执行结果。收集这些信息并训练分类模型,从而自动判定新增测试用例与原始测试用例在演化之后的软件版本上的类别将大大降低回归测试能耗,提高回归测试效率。
随着敏捷开发方法的不断普及,软件的回归测试变得更加频繁,回归测试需要消耗更多的测试资源。这使得传统的回归测试用例分类方法已经越来越不能满足实际软件回归测试的需要。
技术实现要素:
本发明目的在于提供一种回归测试用例自动分类方法,解决目前存在的回归测试通过手工构造的测试预言对回归测试用例分类低效率的问题,实现回归测试用例的自动化分类,以便更高效地开展软件回归测试,进而提高软件产品的质量。
本方面的技术方案为:回归测试用例自动分类方法,基于控制流分析技术从原始的测试用例集合中选择受待测软件变化部分影响的测试用例子集;在历史的软件版本上运行,通过动态插桩技术自动地获得每一个测试用例的执行剖面(profile),以构建分支覆盖向量,如果分支被覆盖则在向量中的值为1,反之则为0;基于中的测试用例在软件历史版本上的运行结果标记测试用例的类别,如果测试用例能发现错误,称其为错误的测试用例,置标记n,反之称为正确的测试用例,置标记y;在当前的软件版本上运行测试用例,并构建该用例对应的分支覆盖向量,通过欧式距离函数计算对应的分支覆盖向量与中的测试用例对应的分支覆盖向量之间的距离,将该距离作为与中的测试用例之间的距离;基于权重的k近邻算法确定测试用例所属的类别。
为实现上述目标,本发明提出了一种回归测试用例自动分类方法,本方法具体步骤如下。
1)选择受软件变化影响的测试用例。基于控制流分析技术为历史软件版本和当前软件版本分别构建控制流图和,以语句或者语句块作为控制流图中的节点,以循环和判定作为连接节点的边。确定控制流图受软件变化影响的边,并为控制流图中的边增加编号。采用度优先搜索的方式同步遍历控制流图和,以确定控制流图中变化的节点,与变化节点相邻的边则是受变化影响的分支,找出所有受变化影响的分支,并将其放在集合中。为控制流图和中的边增加编号,目的是为了方便计算当前软件版本中的测试用例与历史版本中的测试用例之间的距离。在控制流图和中采用深度优先搜索为两个图中的边分别增加标号,相同的边的标号一致,标记为,不同的边分别标记为和。选择受软件变化影响的测试用例子集,在历史版本上运行中的测试用例,并从中选择遍历集合的测试用例作为受待测软件变化部分影响的测试用例子集。
2)待预测类别的测试用例与步骤1)产生的测试用例子集中的测试用例之间距离的计算。采用自动化方式在历史软件版本上批量执行,并联合动态插桩技术获得运行中的测试用例产生的剖面信息文件。分析获得的剖面信息文件,并提取文件中的分支执行频率列为每一个测试用例构造分支覆盖向量,记为。在当前的软件版本上运行测试用例,并为其构造分支覆盖向量,记为。如果一个分支执行频率大于0,则在分支覆盖向量中该分支对应的值是1,否则是0。计算测试用例与中的每一个测试用例之间的欧式距离,计算公式如下:
式中表示测试用例x与y之间的欧式距离,表示同时存在于和中的分支数,表示仅存在于中的分支数,表示仅存在于中的分支数,和分别表示测试用例x和y对应的分支覆盖向量中的第分支的取值。基于中的测试用例在历史版本上的运行结果标记测试用例的类别,如果测试用例能发现错误,置标记n,反之置标记y。
3)回归测试用例的自动化分类。根据步骤2)产生的欧式距离值对中的测试用例进行升序排序,再基于排序的结果从选取个最近距离的测试用例,并为选定的每一个测试用例分配权重,权重值为距离的倒数,根据步骤2)产生的测试用例标记信息分别计算出个测试用例标记n和y的权重值之和,如果标记n的权重和大于标记y的权重和,那么待分类的测试用例属于错误的测试用例,否则属于正确的测试用例。
进一步,其中上述步骤1)的具体步骤如下:
步骤1)-1:起始状态;
步骤1)-2:按行读取历史软件版本,进行词法分析,在此基础上进行语法分析,进而构造抽象语法树,再将抽象语法树生成控制流图,图中的节点表示基本代码块,节点间的有向边代表控制路径;
步骤1)-3:采用与步骤1)-2相同的方法,为当前的软件版本构造控制流图;
步骤1)-4:采用深度优先搜索的策略同步遍历控制流图和,以确定控制流图中变化的节点,与变化的节点邻接的边作为受软件变化影响的边,并以此构建受软件变化影响的边的集合,记为;
步骤1)-5:在控制流图和中采用深度优先搜索为两个图中的边分别增加标号,相同的边的标号一致,标记为,不同的边分别标记为和;
步骤1)-6:控制流图中受软件变化影响的边集合构建完毕,控制流图和边的标号完毕;
步骤1)-7:读取测试用例集合中的一个测试用例,并在历史软件版本上上运行,如果该测试用例遍历了一个属于集合的元素,那么该测试用例即为受软件变化影响的测试用例,将该用例保存到集合中;
步骤1)-8:重复执行步骤1)-7,直到运行完测试用例集合中的所有测试用例;
步骤1)-9:测试用例子集构建完毕。
进一步,其中上述步骤2)的具体步骤如下:
步骤2)-1:起始状态;
步骤2)-2:在历史软件版本中自动注入动态插桩代码,并编译;
步骤2)-3:从测试用例集合中读取一个测试用例作为输入,并自动运行,同时记录测试用例的运行结果;
步骤2)-4:重复执行步骤2)-2、步骤2)-3,直到获取了中的所有测试用例的剖面信息与运行结果信息,并将其保存在磁盘中;
步骤2)-5:从磁盘中读取保存的每一个剖面信息文件,分析获得的剖面信息文件,并提取文件中的分支执行频率列为测试用例构造分支覆盖向量,记为,若频率值大于0,则在分支覆盖向量中该分支的取值为1,否则为0;
步骤2)-6:重复步骤2)-5,直到为中的所有测试用例构造完分支覆盖向量;
步骤2)-7:将中的所有测试用例对应的分支覆盖向量保存到文件中,该文件中的每一行包括测试用例的编号信息,以及测试用例对应的分支覆盖向量及测试用例的运行结果;
步骤2)-8:在当前软件版本中自动注入动态插桩代码,并编译;
步骤2)-9:将待分类的测试用例作为输入,自动运行,并获得该用例的剖面信息,以此为基础构建分支覆盖向量,记为;
步骤2)-10:使用步骤2)定义的公式计算测试用例与中的每一个测试用例之间的距离,并将距离信息保存在磁盘中;
步骤2)-11:根据步骤2)-7产生的测试用例集合中的每一个测试用例的运行结果标记测试用例的类别,如果测试用例的实际输出结果与预先定义的结果不一致,那么该用例是一个错误的测试用例,置标记n,否则该用例是一个正确的测试用例,标记为y;
步骤2)-12:待分类的测试用例与中的测试用例之间的距离计算完毕,测试用例集合中的测试用例类别标记完毕。
进一步;其中上述步骤3)的具体步骤如下:
步骤3)-1:起始状态;
步骤3)-2:读取步骤2)-10产生的距离文件,根据距离值对测试用例集合中的测试用例进行升序排序,从中选取具有最近距离的10个测试用例,并为这10个测试用例赋予权重,权重值为距离的倒数;
步骤3)-3:根据步骤3)-2产生的10个测试用例的标号分别计算n和y的权重和,如果标号n的权重和大于y的权重和,那么待预测的测试用例的类别是n,否则为y;
步骤3)-4:回归测试用例的分类完毕。
本发明基于运行测试用例产生的剖面信息的相似性进行回归测试用例分类,大幅提高了软件回归测试的自动化效率;本方法不仅适用于在演化之后的软件版本上对原有测试用例进行分类,同时也适用于针对演化之后的软件版本新生成的测试用例的分类;本发明从测试用例剖面信息的收集、受软件变化影响的回归测试用例选择,以及基于权重的k-近邻方法对回归测试用例进行分类,均采用自动化的方式进行,整个过程不需要人工干预,大大地提高了回归测试的自动化效率,从而更好地控制软件产品的质量。
附图说明
图1为本发明实施例的一种回归测试用例自动分类方法的流程图。
图2为图1中选择受软件变化影响的测试用例子集的流程图。
图3为图1中计算待分类的测试用例与受软件变化影响的测试用例子集距离的流程图。
图4为图1中回归测试用例分类的流程图。
具体实施方式
为了更清晰的了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
图1为本发明实施例的一种回归测试用例分类方法的流程图。
一种回归测试用例分类方法,包括下列步骤。
s101选择受软件变化影响的测试用例子集的流程图,基于控制流分析技术分别为历史软件版本和当前软件版本构建控制流图和,采用深度优先搜索策略遍历控制流图和以确定图中受软件变化的边集合,根据测试用例在历史版本上的运行信息确定测试用例集合中受软件变化影响的测试用例子集。
s103计算待分类的测试用例与受软件变化影响的测试用例子集中的测试用例之间的距离的流程图。在历史软件版本上运行测试用例子集中的测试用例,通过动态插桩技术收集中的每一个测试用例产生的剖面信息,并且构造分支覆盖向量,同时基于运行测试用例的结果标记中的测试用例的类别,再在当前软件版本上运行待分类的测试用例,并构造分支覆盖向量,最后基于步骤2)中定义的欧式距离函数计算测试用例与测试用例子集中的每一个测试用例之间的距离。
s105回归测试用例自动分类流程图。基于测试用例与测试用例子集中的每一个测试用例之间的距离对中的测试用例进行升序排序,从中选择具有最近距离的10个测试用例,并为这10个测试用例分配权重值,再基于10个测试用例的类别分别计算出类别n和y的权重和,最后根据n和y的权重和判定待预测的测试用例的类别。
图2为选择受软件变化影响的测试用例子集的流程图。读取历史软件版本和当前软件版本软件版本,进行词法与语法分析,进而构建控制流图和。采用深度优先搜索策略遍历图和,确定图中受软件变化影响的边集合,并为图和中的边增加编号。在历史软件版本上运行测试用例集合以确定受软件变化影响的测试用例子集,具体步骤如下。
步骤1:起始状态;步骤2:按行读取历史软件版本,进行词法分析,在此基础上进行语法分析,以构造抽象语法树,进而将抽象语法树转换成控制流图;步骤3:采用与步骤2相同的方法,为当前的软件版本构造控制流图;步骤4:采用深度优先搜索的策略同步遍历控制流图和,以确定控制流图中变化的节点,与变化的节点邻接的边作为受软件变化影响的边,并以此构建受软件变化影响的边的集合,记为;步骤5:采用深度优先搜索策略遍历控制流图和过程中为两个图中的边分别增加标号,相同的边的标号一致,标记为,不同的边分别标记为和;步骤6:控制流图中受软件变化影响的边集合构建完毕,控制流图和边的标号完毕;步骤7:读取测试用例集合中的一个测试用例,并在历史软件版本上上运行,如果该测试用例遍历了一个属于集合的元素,那么该测试用例即为受软件变化影响的测试用例,将该用例保存到集合中;步骤8:重复执行步骤1)-7,直到运行完测试用例集合中的所有测试用例;步骤9:测试用例子集构建完毕。
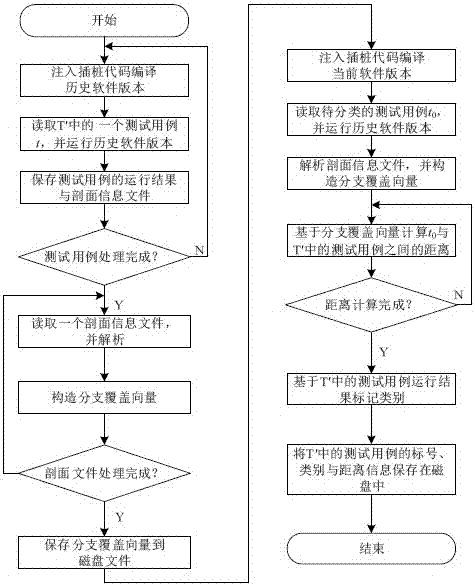
图3为计算待分类的测试用例与受软件变化影响的测试用例子集距离的流程图。在历史软件版本上运行测试用例子集,通过动态插桩技术收集中的每个测试用例的剖面分析,构造分支覆盖向量,根据测试用例的运行结果标记测试用例的类别。在当前软件版本上运行待分类的测试用例,通过动态插桩技术收集的剖面信息,并构造分支覆盖向量。通过欧式距离函数计算测试用例与中的每一个测试用例之间的距离,并将其保存在磁盘中,具体步骤如下。
步骤1:起始状态;步骤2:在历史软件版本中自动注入动态插桩代码,并编译;步骤3:从测试用例集合中读取一个测试用例作为输入,并自动运行,同时记录测试用例的运行结果;步骤4:重复执行步骤2、步骤3,直到获取了中的所有测试用例的剖面信息与运行结果信息,并将其保存在磁盘中;步骤5:从磁盘中读取保存的每一个剖面信息文件,分析获得的剖面信息文件,并提取文件中的分支执行频率列与分支编号列为测试用例构造分支覆盖向量,记为,向量中的每一个元素为一个map对象,其中分支编号作为对象的键,分支频率作为其值,若频率值大于0,则在分支覆盖向量中该分支的取值为1,否则为0;步骤6:重复步骤5,直到为中的所有测试用例构造完分支覆盖向量;步骤7:将中的所有测试用例对应的分支覆盖向量保存到文件中,该文件中的每一行包括测试用例的编号信息,以及测试用例对应的分支覆盖向量;步骤8:在当前软件版本中自动注入动态插桩代码,并编译;步骤9:将待分类的测试用例作为输入,自动运行,并获得该用例的剖面信息,以此为基础构建分支覆盖向量,记为;步骤10:使用步骤2)定义的公式计算测试用例与中的每一个测试用例之间的距离,并将距离信息保存在磁盘中;步骤11:根据步骤7产生的测试用例集合中的每一个测试用例的运行结果标记测试用例的类别,如果测试用例的实际输出结果与预先定义的结果不一致,那么该用例是一个错误的测试用例,置标记n,否则该用例是一个正确的测试用例,标记为y,将测试用例编号与测试用例的标记信息保存在文件中;步骤12:待分类的测试用例与中的测试用例之间的距离计算完毕,测试用例集合中的测试用例类别标记完毕。
图4为回归测试用例分类的流程图。读取待分类的测试用例与中测试用例的距离与中测试用例的标号信息,通过基于权重的-近邻算法对待分类的测试用例进行分类,具体步骤如下。
步骤1:起始状态;步骤2:读取待分类的测试用例与中测试用例的距离文件,将中的测试用例编号作为键,距离作为值,封装为map对象,根据距离值对测试用例集合中的测试用例进行升序排序,从中选取具有最近距离的10个测试用例,并为这10个测试用例赋予权重,权重值为距离的倒数;步骤3:读取用于保存中的测试用例的标号信息文件,将测试用例作为键,测试用例的类别作为值,封装为map对象,根据选定的10个测试用例的标号信息分别计算出标号n和y的权重和,如果标号n的权重和大于y的权重和,那么待预测的测试用例的类别是n,否则为y;步骤4:回归测试用例的分类完毕。
综上所述,本发明解决了目前软件回归测试背景下依赖手工产生的测试预言对回归测试用例进行分类的自动化效率不高的问题,该方法不需要构造测试预言,仅利用测试用例运行的历史信息与软件的演化信息对回归测试用例进行分类,不仅大幅提高了回归测试的自动化程度和运转效率,而且也降低了软件回归测试能耗,从而更好地控制软件产品的质量。