一种双核双驱洪水预报方法与流程
本发明涉及一种双核双驱洪水预报方法,是一种实时的水文预报方法,是一种通过建模针对非均匀降水的实时洪水预报方法。
背景技术:
一次降雨过程在流域上的分布,不均匀是绝对的,均匀却是相对的。在湿润地区,年降雨量大,地表土层含水量大且相对均匀。由于气候条件的原因容易形成大面积的降雨,使流域降雨分布相对均匀。而在半湿润半干旱或干旱地区,雨量不仅年内分配集中,一次降雨过程在流域面上的分布往往差异也很大,局部暴雨频发。流域出口断面的径流往往主要是由流域内某一局部面积上的暴雨形成的。流域面积越大,这种不均匀性越突出。加之每次降雨的中心位置、主雨区笼罩面积、雨量和强度等等都在发生变化,由历史资料率定出的模型参数难以应对未来下一场暴雨的特殊情况。由于所有集总式模型对面雨量的处理都是按面平均雨量作为模型的输入,无法考虑面雨量分布的不均匀性,这就给经常发生非均匀暴雨的半湿润半干旱或干旱地区的径流模拟和预报带来了极大的挑战。
为了解决这一棘手问题,世界各国学者开展了大量研究,提出了一些解决方案,主要可归纳为两类。一是不断修改模型结构,如提出了非线性模型、非线性增益模型,试图把这种降雨均匀性归结为水文过程的非线性问题。这种方法显然不能从根本上解决问题。二是在模型率定时,考虑降雨中心位置在上游还是在下游、以及降雨总量的大小,分别率定模型参数或单位线。在预报时,根据流域上降雨的综合情况(雨量大小、降雨中心位置、移动路径等)选择一套认为适合的模型参数或单位线。但由于降雨过程的不可重复性,雨量及其时程变化和空间分布会有各种各样的组合,使得选择适合的模型参数又成了一个难题。大量实践证明,实际预报效果并不理想。分布式水文模型的出现对解决这一问题提供了一条新的途径。但由于其模型结构复杂、参数较多,要求的输入资料繁多,又使用了很多概化和假定,其实际的预报效果往往不比集总式模型好。
因此,需要寻找一条简便易行的途径,提高水文模型的适应性,提高半湿润半干旱及干旱地区常见的非均匀暴雨的洪水预报精度。
技术实现要素:
为了克服现有技术的问题,本发明提出了一种双核双驱洪水预报方法。所述的方法通过“双核双驱”方法,将流域划分为暴雨核心区和非暴雨核心区,在两个分区分别建立水文模型进行产汇流计算,之后在流域出口断面处合成流域总径流,以此提高半湿润半干旱及干旱地区非均匀暴雨的洪水预报精度。
本发明的目的是这样实现的:一种双核双驱洪水预报方法,所述方法的步骤如下:
水文模型选择的步骤:用于选择适用于研究流域降雨—产流条件的集总式水文模型,包括产流模型和汇流模型;
产流参数率定的步骤:用于收集分析同一时期全流域降雨相对均匀的降雨洪水资料,采用中等以上量级的均匀暴雨洪水场次率定和校验模型参数;
汇流参数率定的步骤:用于选择在流域内分布不均匀的降雨径流资料,率定在降雨不均匀情况下降雨中心在流域不同位置的汇流参数;
降雨均匀性判定的步骤:用于降雨时统计各雨量站的累积降雨量,计算雨量不均匀系数PU,并判断是否大于雨量不均匀阈值,如果“是”则进入下一步骤,如果“否”则使用常规方式计算产汇流;
划分区域的步骤:用于根据降雨的空间分布情况将流域划分为“暴雨核心区”和“非暴雨核心区”;
在流域内降雨不均匀的前提下(PU值大于0.3~0.4时),根据降雨的空间分布情况将流域划分为“暴雨核心区”和“非暴雨核心区”。
计算产流的步骤:用于在两个分区各自代表的面积上,统计各雨量站的前期影响雨量,代表两个分区的土壤含水量,并分别建立所选定的水文模型进行产流计算,两个分区的产流参数均采用在全流域降雨均匀情况下率定的产流参数进行产流过程的分析计算;
计算汇流的步骤:用于根据两个分区所在流域位置的不同,选择率定的降雨中心在流域不同位置的汇流参数,并结合产流过程的计算结果进行汇流过程的分析计算;
叠加的步骤:用于将两个分析计算的汇流过程按同时段叠加,形成最终的流域出口断面的预报数据作为径流预报结果;
预报成果发布的步骤:用于比较计算流域出口断面的预报数据与警戒数据,若预报数据大于警戒数据,则做出洪水预警;否则认为不会发生洪水。
进一步的,所述的产流模型是:三水源蓄满产流模型SMS_3,所述的汇流模型是:三水源滞后演算模型LAG_3。
进一步的,所述的降雨不均匀系数PU根据如下公式计算:
其中:Ps为流域最干旱时产流的降雨量、
N为流域雨量站总数、
large(N,i) 为统计函数,用于返回所选范围内的第i个最大累计雨量值、
small(N,j) 为统计函数,用于返回所选范围内的第j个最小累计雨量值、
n和m为选择的最大和最小雨量站个数。
进一步的,所述的雨量不均匀阈值的数值范围是:0.3~0.4。
本发明产生的有益效果是:本发明提出的针对非均匀降雨的“双核双驱”洪水预报方法抓住了半湿润半干旱地区以及干旱地区的暴雨洪水特点,按照非均匀降雨中心的空间分布,将流域划分为“暴雨核心区”和“非暴雨核心区”,分别建立水文模型进行产汇流计算,充分利用了流域内各雨量站在暴雨期间的雨量分布信息,考虑了降雨开始时土壤含水量在流域上的差异,方法简单,易于操作。方法中提出的降雨不均匀系数能定量有效地判断流域内发生不均匀降雨的临界点,有助于准确判断“双核双驱”方法在预报实践中的使用时机。采用“双核双驱”方法进行洪水预报,可以有效减少在雨量分布不均匀的情况下选择模型参数的不确定性,一些流域的实际检验已证明该方法对提高洪水预报精度是行之有效的。
附图说明
下面结合附图和实施例对本发明作进一步说明。
图1是本发明的技术方案流程图;
图2是本发明实施案例的流域雨量站分布示意图;
图3是本发明实施案例的各雨量站降雨时程变化图;
图4是本发明实施案例的降雨不均匀系数PU值随时间变化情况;
图5是本发明实施案例的“双核双驱”方法预报结果与实测对比图;
图6是本发明实施案例的常规方法预报结果与实测对比图。
具体实施方式
实施例一:
本实施例是产流模型雨量不均匀阈值一种双核双驱洪水预报方法,流程如图1所示。一场特定的非均匀降雨,雨量总是集中在流域的某一个区域,这个区域降雨总量大、强度高,是产流的核心区域;而流域的其它区域降雨量相对较小,降雨强度弱或根本不发生降雨,因而产生的径流量也较少。根据非均匀降雨产流的这种特性,“双核双驱”方法将流域划分为“暴雨核心区”和“非暴雨核心区”,在两个区域分别使用不同的水文模型参数进行产汇流计算,之后在流域出口断面合成为流域总径流。但由于通常只有流域出口断面的水文站才有实测流量资料,因此“双核双驱”方法的关键是解决两套水文模型参数的率定问题以及在实际预报中应用的问题。
本实施例以位于华北太行山东麓的阜平流域为应用实际举例,说明结合“双核双驱”方法的具体过程:
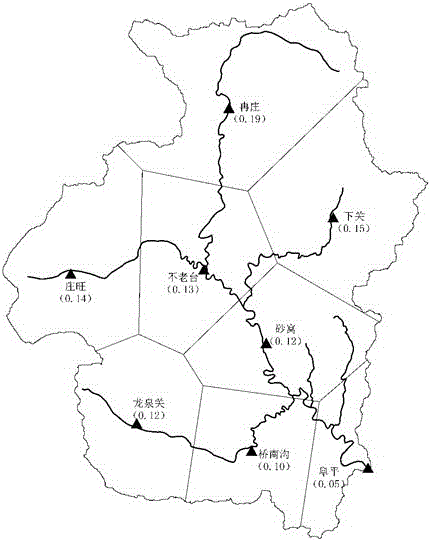
阜平流域集水面积为2210km2,位于北纬38°46′~39°21′,东经113°40′~114°18′,属于暖温带大陆性季风气候区,年平均气温12.7℃,年降雨量524.5mm,年径流量3.03×108m3(折合径流深137mm),年水面蒸发量1200mm,干旱指数2.3,无霜期约180天。流域内山地面积占80%以上,余为丘陵和山间盆地,海拔200~2000m,地势西高东低。流域河系为典型的扇形分布,主要河流有沙河、胭脂河等。流域内降雨的年际、年内变化都很大,年降水量变差系数Cv值为0.35左右,年最大四个月降水量(6~9月)占全年降水量的80%以上。由于山高坡陡、雨量集中,汛期极易形成洪水,水势陡涨陡落。但在非汛期河流的流量很小,甚至常常断流。暴雨期雨量分布往往极不均匀,差异很大,流域局部产流时有发生。流域内设有8处雨量报讯站,流域出口为阜平水文站,是其下游王快水库的入库报讯站,具有1956年以来连续实测流量资料。图2为阜平流域的雨量站分布示意图,括号内为各个雨量站的泰森多边形系数。预报目标选择阜平流域1978年8月26日~9月2日的一次暴雨洪水过程。该次降雨的主雨区集中在阜平流域的中下游南部,流域中上游基本无雨,最大洪峰流量682m3/s。
本实施例所述方法的步骤如下:
(一)水文模型选择的步骤:用于选择适用于研究流域降雨—产流条件的集总式水文模型,包括产流模型和汇流模型。集总式水文模型通常将流域产流和汇流分开考虑,使用起来方便灵活,有利于“双核双驱”方法的开展。
集总式水文模型有许多种类型,在实际应用中可以有多种选择。可根据研究区的降雨产流机理选择适宜的水文模型,如湿润地区以蓄满产流为主,可以选择以新安江模型为代表的蓄满水文模型;干旱地区以超渗产流为主,可以选择以陕北模型为代表的超深水文模型等。对于中国的研究区域,可以参考中华人民共和国水利部研发的中国洪水预报系统模型库中的集总式水文模型。
本实施例实际应用的实例,通过研究流域的产汇流特性,选择产流模型采用上述中国洪水预报系统中的三水源蓄满产流模型SMS_3,汇流模型采用三水源滞后演算模型LAG_3。
SMS_3共有11个参数,即:WUM、WLM、WDM、C、K、IMP、B、KG、KI、SM和EX。WUM、WLM和WDM分别为流域平均最大蓄水容量、流域上层土壤平均最大蓄水容量和流域下层土壤平均最大蓄水容量;C为深层蒸发折算系数;K为流域蒸散发折算系数;IMP是不透水面积占全流域面积的比例;B是流域蓄水容量曲线的方次;KG和KI分别为自由水蓄水库的地下水出流系数和壤中流出流系数;SM为流域平均的自由水蓄水容量,它决定了地表径流与另外两种径流的比例关系;EX是自由水蓄水容量曲线的指数。
LAG_3共有6个参数,即:CI、CG、CS、LAG、X和MP。CI为深层壤中流的消退系数;CG是地下径流的消退系数;CS为河网蓄水的消退系数,反映洪水过程的坦化;LAG为滞后时段数,反映洪水波的平移程度;X是马斯京根演算系数;MP为马法分段连续演算的河段数。
(二)产流参数率定的步骤:用于收集分析同一时期全流域降雨相对均匀的降雨洪水资料,采用中等以上量级的均匀暴雨洪水场次率定和校验模型参数。
“双核双驱”方法在率定水文模型参数时分为两步,首先率定全流域降雨均匀情况下的产流参数,再率定降雨不均匀条件下不同降雨中心位置的汇流参数。
大多数概念性水文模型的产流参数都具有明确的物理意义。其物理意义仅与流域的下垫面条件(包括土壤含水量)有关,而与降雨的不均匀性无关。因此,首先率定在全流域降雨均匀情况下步骤一选定的水文模型的产流参数。参数率定时收集分析同一时期全流域降雨相对均匀的降雨洪水资料,采用中等以上量级的均匀暴雨洪水场次来率定和校验模型参数。
产流参数的物理意义一般只与流域的下垫面条件有关,而与降雨的不均匀性无关。如果降雨均匀且下垫面条件稳定,产流参数应当是稳定不变的。因此,在率定SMS_3的11个产流参数时,应选择在流域内分布相对均匀且能形成全流域产流的大、中型暴雨洪水资料。率定前应对流域的暴雨洪水特征、面雨量分布情况进行详尽分析,在雨量量级、流量过程线峰型特征上对是否全流域产流有一个基本判断,选出满足全流域产流且面分布相对均匀的多场暴雨洪水资料。为尽量消除人类活动对下垫面条件的影响,在满足上述条件的前提下,应优先选择近期的资料。模型参数校验原则上也应使用具有上述特征的暴雨洪水资料,鉴于半湿润半干旱地区已经发生的均匀降雨并不多见,如果难以找到满足条件的降雨场次,也可使用在流域内局部分布相对均匀,但在其余面积上雨量很小且基本不产流的暴雨资料来替代(注意此时流域面积要进行相应调整)。
在对阜平流域的历史暴雨洪水进行详细分析后,选出了1995年和1996年两场暴雨洪水进行参数率定,选择1976年的一场洪水进行校验。流域面平均雨量采用泰森多边形方法计算。率定时以流量过程线或产流量误差最小为目标,结合参数物理意义和经验,给定参数取值范围,以人工试错与自动优选相结合的方法进行率定。本实例SMS_3产流参数的率定与校验结果见表1。其中DC为确定性系数,RE为径流总量相对误差,计算方法如公式(1)、(2)所示。
表1. SMS_3产流模型参数率定及校验成果表
(1)
(2)
式中:、为实测流量及其均值;为模拟流量;N为洪水流量过程节点总数。两个指标中,DC越大、RE越小,说明率定和校验效果越好。由表1可见,两个指标都在可接受的范围内。说明SMS_3模型在半干旱地区降雨相对均匀的情况下也能得到较好的模拟结果。
(三)汇流参数率定的步骤:用于选择在流域内分布不均匀的降雨径流资料,率定在降雨不均匀情况下降雨中心在流域不同位置的汇流参数。在选择暴雨场次时,要求降雨中心位置要有一定代表性。同时,暴雨核心区以外的流域面积上基本无降雨或降雨量较小,可以根据流量过程线判断不会产流或产流很少。汇流参数率定时应扣除暴雨核心区外基本不产流的面积。降雨中心在流域内的不同位置,应对应不同的汇流参数。
率定流域内降雨不均匀条件下不同暴雨中心位置的汇流参数。选择暴雨中心在流域不同位置、且中心区域以外降雨很小或基本无雨的暴雨洪水资料。以暴雨笼罩区为计算面积,率定暴雨中心在流域不同位置的汇流参数。实例中针对阜平流域的历史降雨资料特征,选择了暴雨区在中上游、中下游北部、中下游南部和下游四种不同位置的典型暴雨资料,来率定LAG_3模型的汇流参数。暴雨区中心在流域内不同位置时汇流参数的变化情况见表2。
表2 暴雨区中心在不同位置时LAG_3汇流模型参数变化情况
(四)降雨均匀性判定的步骤:用于降雨时统计各雨量站的累积降雨量,计算雨量不均匀系数PU,并判断是否大于雨量不均匀阈值,如果“是”则进入下一步骤,如果“否”则使用常规方式计算产汇流。用设定一个降雨不均匀系数PU,并设定阈值的方式确定是否需要使用“双核双驱”方法,即:当PU大于阈值时,表明流域内各雨量站的降雨量出现了明显的不均匀性,开始考虑使用“双核双驱”方法进行产汇流计算,否则使用常规的计算方法。
在阜新的例子中:阜平流域1978年8月26日~9月2日的一次暴雨洪水为本实例的预报目标。此次降雨从8月21日凌晨开始,雨区主要集中在流域的中下游南部。到8月27日16时流域出口断面洪水开始起涨时,流域最大点雨量累计值已经达到123.7mm,中上游雨量站观测到的最小雨量仅为48.4mm。流域雨量最大的3个站雨量累计平均值达到97.5mm,而雨量最小的3个站平均为55.5mm,二者相差42mm,雨区仍然集中在流域中下游南部。流域内各雨量站的降雨时程变化情况见图3。
根据各雨量站的前期累计雨量,计算降雨不均匀系数PU,实时跟踪流域降水量的变化情况。PU的计算方法如下:
(3)
其中:Ps为流域平均最大土壤蓄水容量;N为流域雨量站总数;large(N, i)函数和small(N, j)函数分别返回所选范围内的第i个最大累计雨量值和第j个最小累计雨量值;n和m为选择的最大和最小雨量站个数,实例中选取n=3和m=3(流域内雨量站总数的三分之一)。图4 为阜平流域1978年8月26日~9月2日暴雨洪水期间降雨不均匀系数随时间的变化情况。由图可见,从时段20开始,PU值大于0.3,且有继续增加的趋势,到时段34 ,PU值增大到0.4。结合次暴雨累计雨量情况综合判断,此时流域面降雨已经出现了很大的不均匀性,适宜使用“双核双驱”方法进行洪水预报。
(五)划分区域的步骤:用于根据降雨的空间分布情况将流域划分为“暴雨核心区”和“非暴雨核心区”。
在流域内降雨不均匀的前提下(PU值大于0.3~0.4时),根据降雨的空间分布情况将流域划分为“暴雨核心区”和“非暴雨核心区”。根据流域前期降雨量的空间分布情况,将处于降雨中心的阜平、桥南沟、砂窝、龙泉关四个雨量站的控制面积划分为“暴雨核心区”,另外四个雨量站(不老台、下关、庄旺、冉庄)的控制面积划分为“非暴雨核心区”。“暴雨核心区”雨量站的泰森多边形累加面积为892km2,“非暴雨核心区”的累加面积为1318km2。
(六)计算产流的步骤:用于在两个分区各自代表的面积上,统计各雨量站的前期影响雨量,代表两个分区的土壤含水量,并分别建立所选定的水文模型进行产流计算,两个分区的产流参数均采用在全流域降雨均匀情况下率定的产流参数进行产流过程的分析计算。一般认为,流域的下垫面在一定时期内应当是相对稳定的,水文模型的产流参数是稳定不变。
(七)计算汇流的步骤:用于根据两个分区所在流域位置的不同,选择率定的降雨中心在流域不同位置的汇流参数,并结合产流过程的计算结果进行汇流过程的分析计算。
(八)叠加的步骤:用于将两个分析计算的汇流过程按同时段叠加,形成最终的流域出口断面的预报数据作为径流预报结果。将“暴雨核心区”和“非暴雨核心区”分别计算得到的洪水流量过程线按同时段进行叠加,得到的即为流域出口断面的洪水流量过程线。
在两个分区内分别进行产汇流计算,用各自面积上的平均雨量作为水文模型的输入,产流参数采用率定好的同一套参数,汇流参数根据两个分区在流域的相对位置进行选择。“暴雨核心区”采用降雨中心位于在中下游南部的汇流参数,“非暴雨核心区”采用降雨中心位于中上游的汇流参数。两个分区在流域出口断面形成的径流过程通过叠加,形成最终的径流预报结果,见图5。
图5中采用“双核双驱”方法的预报洪水过程线与实测相比,起涨点、洪峰流量和峰现时间几乎完全一致,确定性系数DC为95.1%,径流总量相对误差RE为16.9%。图6为使用常规方法的预报结果与实测过程对比图。其中产流使用与“双核双驱”方法相同的产流参数,汇流采用全流域率定的均匀汇流参数。通过对比可见常规方法的预报结果明显不如“双核双驱”方法好。本次暴雨期间,雨期前半段流域中下游南部的雨量很大,而其余地方雨量较小;后期暴雨中心降雨基本停止而其余地点雨量开始增大(见图3)。常规方法中,全流域8个雨量站同时段计算流域面平均雨量,不同区域的降雨量被均化,与实际的降雨情况差异较大,因而预报效果不好。不均匀降雨在半湿润、半干旱地区比较常见,无论使用什么形式的水文模型,如果不考虑暴雨的不均匀特性,就会给洪水预报带来较大偏差。由于“双核双驱”方法率定的产流参数是暴雨相对均匀时的流域平均情况,所以划分的“暴雨核心区”和“非暴雨核心区”的面积不应太小,流域总面积的三分之一以上为宜,以防止局部地形地貌等下垫面条件与流域平均情况出现较大差异时影响预报精度。
(九)预报成果发布的步骤:用于比较计算流域出口断面的预报数据与警戒数据,若预报数据大于警戒数据,则做出洪水预警,否则认为不会发生洪水。
比较计算流域内各河道关键节点的水位预报数据以及警戒水位数据,若预报水位大于警戒水位,认为该节点可能发生洪水,出现险情,需要注意防汛;若预报水位小于等于警戒水位,则认为该节点不会发生洪水。
实施例二:
本实施例是实施例一的改进,是实施例一关于产流模型和汇流模型的细化。本实施例所述的产流模型是:三水源蓄满产流模型SMS_3,所述的汇流模型是:三水源滞后演算模型LAG_3。
SMS_3是一个集总式概念性水文模型,在许多国家的湿润、半湿润地区得到了广泛的应用。该模型采用蓄满产流概念,认为在降雨过程中,只有当包气带蓄水量达到田间持水量时才能产流。产流以后,超过入渗强度的部分降雨形成地面径流,下渗部分为地下径流,地下部分按退水快慢又划分成壤中流和地下径流。模型提出了流域蓄水容量曲线的概念,以考虑下垫面不均匀对产流面积的影响。LAG_3与SMS_3相匹配,用于不同水源的汇流计算。滞后演算法是把洪水波运动的平移和坦化作用分开进行连续的一次性处理,包括流域汇流与河道汇流两部分。流域汇流又分为坡面汇流和河网汇流。汇流模型只处理河网汇流,与产流模型在性质上是独立的。
实施例三:
本实施例是上述实施例的改进,是上述实施例关于降雨不均匀系数计算方法的细化。本实施例所述的降雨不均匀系数PU根据如下公式计算:
其中:Ps为流域最干旱时产流的降雨量,其值相当于流域平均最大土壤蓄水容量、N为流域雨量站总数、large(N,i) 是一统计函数,可返回所选范围内的第i个最大累计雨量值、同样small(N,j) 是一统计函数,函数可返回所选范围内的第j个最小累计雨量值、n和m为选择的最大和最小雨量站个数,其值可根据流域雨量站的总量选取,一般情况下n和m的控制面积应为流域总面积的三分之一左右为宜。用PU作为流域降雨不均匀性指标可以实时跟踪流域降水量的变化情况。根据经验,当PU值大于0.3~0.4时,就应该考虑使用“双核双驱”方法进行洪水预报。
实施例四:
本实施例是上述实施例的改进,是上述实施例关于雨量不均匀阈值的细化。本实施例所述的雨量不均匀阈值的数值范围是:0.3~0.4。在实际预报过程中,降雨不均匀系数PU是根据获取的降雨监测数据进行实时计算更新的。
根据实例一中阜平流域所处太行山区的降雨特性,当PU值大于此阈值范围时,流域各雨量站的降雨量呈现明显的不均匀趋势,适宜使用“双核双驱”方法。同时,参考阜平流域洪水预报的实践经验,当PU值超出此阈值范围时,采用传统的洪水预报方法的精度开始明显下降,而采用“双核双驱”方法的优势开始逐渐凸显。因此,将实例中PU阈值范围确定为0.3~0.4,其主要目的是通过对降雨不均匀性的实时跟踪,作为一个指示“双核双驱”方法使用时机的参考指标。对于中国半湿润半干旱地区的研究流域,可以参考使用该阈值范围,也可根据当地降雨特性和具体预报实践确定阈值。
最后应说明的是,以上仅用以说明本发明的技术方案而非限制,尽管参照较佳布置方案对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案(比如模型的选定、各个参数的率定方式、各种公式的运用、步骤的先后顺序等)进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!