词向量模型的增量式学习方法与流程
本发明属于自然语言处理技术领域,涉及词向量在线训练(学习)方法,尤其涉及一种词向量模型的增量式学习方法。
背景技术:
文本表示模型是文本挖掘、自然语言处理、信息检索的重要基础,良好的文本表示模型既需要包含对应语言单元(词或文档)的语义信息,又同时可以直接通过这种表示度量文本之间的语义相似度。词向量具有良好的语义特性,是表示词语特征的常用方式,词向量每一维的值代表一个具有一定的语义或者语法上的特征,可以为许多研究者用于进行语义或语法分析。
文献(Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013.)记载,2013年Google提出文本深度表示模型Word2vec,其利用深度学习的思想将词表征为实数值向量,利用中心词及其上下文建立局部词嵌入窗口模型,用以进行词语特征向量的优化训练。Word2vec有四种模型:NNLM、RNNLM、CBOW、Skip-gram,通过实验证明CBOW在四种模型中效果最好。
在文献(Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems.2013:3111-3119.)中,Mikolov提出CBOW模型的两种算法:多层感知器(Hierarchical Softmax,HS)、反例采样(Negative Sampling,NS)。HS算法需要基于训练样本建立复杂的Huffman树,每个词被赋予唯一的Huffman编码。与HS算法相比,NS算法不需要使用复杂的Huffman树,而是利用相对简单的随机反例采样,能大幅提高性能。
在文献(Pennington J,Socher R,Manning C D.Glove:Global Vectors for Word Representation[C]//EMNLP.2014,14:1532-43)中,Jeffrey提出了一种基于全局信息的词向量模型GloVe,其将LSI算法的词-文档共现矩阵与Word2vec的局部词嵌入窗口有效结合起来,建立词-词共现矩阵。GloVe算法优势在于无需遍历每一篇语料进行局部的词向量优化,仅对矩阵进行全局优化,因此比Word2vec训练速度更快,同时还能保存词与词之间线性关系;缺陷在于无法像Word2vec一样保留局部的词与词之间的记忆关系。
上述模型和方法中,Word2vec与GloVe都是静态、批量学习模式,不支持增量式学习,只适用于离线式的训练,但实际应用中,训练样本通常不可能一次全部得到,而是随着时间逐步得到的,并且样本反映的信息也可能随着时间产生了变化。如果新样本到达后要重新学习全部数据,需要消耗大量时间和空间。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于词向量的在线增量式学习算法(Incremental Learning Word2vec,ILW),实现在线系统中对文本进行增量式学习,而不必重新对全部数据进行学习。
本发明的原理是:基于深度神经网络的词向量增量式学习算法,针对实际应用中在线文本数据量大、实时性高的特点,本发明提出的基于词向量的在线增量式学习算法(Incremental Learning Word2vec,ILW),对Word2vec(Word2vec中CBOW模型的NS算法)进行改进,利用这个算法进行在线训练词向量模型,能够实现在线系统中对文本进行增量式学习,可以渐进的进行知识更新,且能修正和加强以前的知识,使得更新后的知识能适应新到达的数据,而不必重新对全部数据进行学习。ILW主要包括:过程(一)新增文本中的新词初始化更新;过程(二)基于历史词语进行反例采样得到反例样本集合;过程(三)进行词向量的优化更新。首先通过过程(一)渐进地进行“新词”更新,然后利用过程(二)得出新增文本中每个词的反例样本集合,最后利用过程(三)基于反例样本集合采用NS算法的随机梯度上升法进行向量优化。其中过程(一)和过程(二)是ILW算法区别于Word2vec算法的地方,是本发明的创新。本发明通过过程(一)新增文本中的新词初始化更新和过程(二)基于历史词语进行反例采样得到反例样本集合,使得更新后的向量模型能适应新文本中包含的语义及语法信息,同时对旧数据信息进行修正和加强,避免重新对所有语料进行学习,是ILW算法实现“增量式”的关键部分。
本发明提供的技术方案如下:
一种词向量模型的增量式学习方法,通过对新增文本中出现的新词进行初始化更新和基于历史词表的反例采样,基于历史词向量模型对每一篇新文本数据进行增量式学习,对词向量模型进行动态地更新,避免对历史数据进行重复性学习;该方法的超参数包括:向量维度m;反例样本个数范围[min,max];文本窗口长度c;针对一篇经过分词的新增文本text,所述增量式学习方法包括如下步骤:
经过分词的新增文本text是序列化的数据,由一系列词语组成;按顺序遍历文本text中每个词语word,对每个词语执行如下步骤1)~2):
1)如果word不属于历史词表word_list(表示历史数据中没有出现过该词语word),则作为“新词”进行词向量初始化和辅助向量初始化;
2)将词语word(无论其是否为“新词”)不去重地添加到历史词表word_list中,令new_word_list=word_list;
经过上述步骤1)~2)完成新词初始化更新,并输出更新后的历史词表new_word_list,new_word_list包含了text中的所有词语以及原有历史词语。
然后再次按顺序从头遍历文本text中每个词语word,对每个词语执行如下步骤3)~8):
3)确定当前词语word的反例样本个数为n,设定Neg(word)={};
4)从new_word_list随机有放回的抽取一个词w_,并依据w_是否为word来判断其正反性,若不是,则作为反例样本加入当前词语word的反例样本集合Neg(word)中,然后执行下一步;反之则直接执行下一步;
5)判断是继续执行第4步抽样还是输出反例样本集合进行执行第6步;
具体地,若当前词语word的反例样本集合Neg(word)词数达到n,则停止抽样输出Neg(word);反之则跳回第4步继续抽样。由于word本身之外所有词语都是反例样本,而new_word_list中包含的词语不止是词word,当当前词语word的反例样本集合Neg(word)的词数达到n时停止循环,得到反例样本集合Neg(word)。
经过上述第3~5步完成基于历史词表的反例采样,最终得到当前词语word的反例样本集合Neg(word)。由第3步中Neg(word)={}可知,Neg(word)仅对于当前遍历的word有效,下一次即使遍历到与word相同词语仍然需要重新抽样,不能在前一次抽样的Neg(word)基础上进行添加。利用Neg(word)完成接下来向量优化更新:
6)当前词语word在text中上下文各c个词的集合为上下文词集合Context(word,c),对集合中所有词向量进行线性相加求和得出xword;
7)利用xword对集合{word}∪Neg(word)中每个词w的辅助向量进行优化更新,{word}∪Neg(word)表示当前词语word组成的单元素集合{word}与其反例样本词语集合Neg(word)的总并集;
8)对上下文词集合Context(word,c)中每个词u进行词向量优化更新。
经过第6)~8)步完成向量模型优化更新。
上述词向量模型的增量式学习方法中,通常向量维度m>100才能使向量包含丰富的语义和语法上的信息;反例样本个数范围[min,max],其中max<=20,max-min<=5;文本窗口长度c,3<=c<=10;
针对上述词向量模型的增量式学习方法,步骤1)中,word的词向量初始化公式为:
v(word)={[random(-0.5,0.5)/m],....,[random(-0.5,0.5)/m]}m (式1)
式1中,[random(-0.5,0.5)/m]表示每一维的值为[-0.5,0.5]区间的随机数除以维数m。word的辅助向量θword初始化为全0的m维向量。
步骤2)中,将新增文本中的词更新至历史词表,用于接下来的反例采样。
步骤3)中,取[min,max]区间随机数作为词语word反例样本个数n。
步骤4)中,对于每个词除了自身之外所有词都可以是反例样本,因此词语被抽样选中作为反例样本概率与词频成正比。
步骤7)中,集合{word}∪Neg(word)中每个词w的辅助向量θw进行如下优化更新计算运算:
上述式2利用随机梯度上升法进行参数更新。其中Lword(w)表示词w的标签,如果w=word,则L(w)=1,反之则L(w)=0。η表示学习率,表示sigmod函数:
步骤8)中,对Context(word,c)中的每个词语u向量v(u)进行如下优化更新计算:
式3与第7步一样采用随机梯度上升法完成向量优化更新。
步骤6)~8)采用Word2vec中CBOW模型的NS算法的随机梯度法,对词word及其上下文词集合Context(word,c)和反例样本集合Neg(word)进行向量梯度优化更新,使更新后的向量模型能适应新文本数据。
将上述词向量模型的增量式学习算法ILW应用于在线系统中实时文本数据训练:用于在线系统中增量式训练文本数据,建立词向量模型,随着数据量增大,算法仍能保持高效率地训练,同时在线训练的词向量模型表现效果良好。
与现有技术相比,本发明的有益效果是:
本发明提供一种基于词向量的在线增量式学习算法(Incremental Learning Word2vec,ILW),实现在线系统中对文本进行增量式学习,而不必重新对全部数据进行学习。利用本发明提供的ILW增量式学习算法,通过对新增文本中出现的新词进行初始化更新以及基于历史词表的反例采样,避免了对历史数据进行重复性学习,大幅减少了计算复杂度。ILW算法可以基于历史词向量模型对每一篇新文本数据进行增量式学习,对词向量模型进行动态地更新。当在线系统中需要处理海量实时数据时,ILW算法可以高效地利用历史数据(历史词表)对向量模型进行动态优化更新。实验结果表明,随着数据量与向量维度的变化,ILW与Word2vec有着相似的模型准确率变化趋势,而且随着在线系统中数据量增大,ILW算法与Word2vec算法之间的模型准确率差值越小;同时随着数据量增大,ILW算法的还能保持较高的学习效率,满足在线系统的效率需求。
附图说明
图1是本发明实施例中将ILW方法用于在线系统中的流程框图。
图2是本发明提供的ILW算法准确率随训练词数量变化的曲线;
其中,(a)是在不同训练词语维度下,ILW算法的模型准确率随训练词数量的变化曲线;(b)是在不同训练词语维度下,NS算法的模型准确率随训练词数量的变化曲线。
图3是本发明实施例中准确率随向量维度变化曲线;
其中,(a)是在不同训练词语数量下,ILW算法的模型准确率随向量维度的变化曲线;(b)是在不同训练词语数量下,NS算法的模型准确率随向量维度的变化曲线。
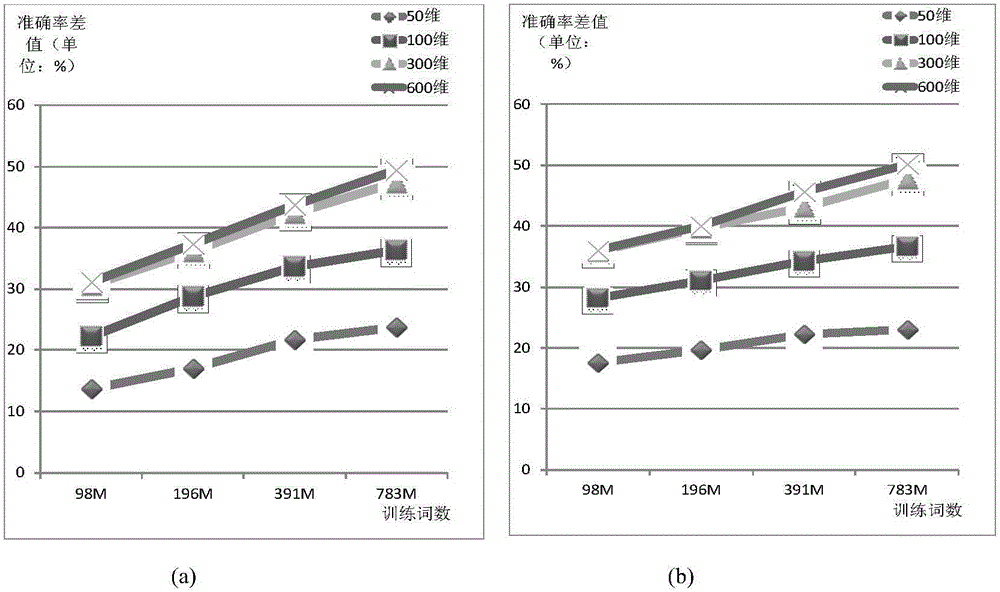
图4是本发明实施例在不同向量维度下,模型准确率差值随训练词语数量的变化曲线。
图5是本发明实施例中训练效率随参数变化曲线;
其中,(a)是在不同文本窗口长度下,训练效率随词数量变化曲线(反例样本个数范围[5,10],维度300);(b)是在不同维度下,训练效率随词数量变化曲线(文本窗口长度为5,反例样本个数范围[5,10]);(c)是在不同维度下,训练效率随文本窗口长度变化曲线(词数783M,反例样本个数范围[5,10]);(d)是在不同反例样本范围下,训练效率随文本窗口长度变化曲线(词数783M,维度300)。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于词向量的在线增量式学习算法(Incremental Learning Word2vec,ILW),实现在线系统中对文本进行增量式学习,而不必重新对全部数据进行学习。
图1是本发明提供的ILW方法用于在线系统中的流程框图。词向量模型的增量式学习方法ILW算法可分为三个部分,具体过程如下:
1.新词的初始化更新(第1~2步)
训练一篇新文本数据text,需要对向量模型进行更新。词向量模型中包含了大量的历史词语的向量信息。在CBOW模型的NS算法中,当训练样本中加入了新数据时,需要针对所有历史词语进行初始化再重新训练词向量。随着新增样本逐渐增加,重复性的初始化会增加计算量,降低算法性能。基于此,本发明提出一种针对新词的初始化更新算法(Update on Neologism),算法过程如下。
算法1包含了两个部分,首先将不属于历史词表的“新词”(在历史训练样本中没有出现过的词)进行向量的初始化。然后将新文本中所有词语有序化、不去重地更新到新词表new_word_list中,用于接下来的反例采样算法。算法1仅针对历史训练样本中未出现过的‘新词’而进行向量初始化,对于“旧词”只需要保留原有的历史向量进行后面的优化更新,不需要对所有历史数据进行初始化,如此一来既大幅节省了计算量,又能确保向量模型中加入了“新词”向量信息,也不会影响“旧词”的向量信息。
2.基于历史样本的负采样(第3~5步)
随着文本数据量增加,通过算法1更新的new_word_list中将会存放大量历史样本中的词语{w1,w2,...,wk}。Word2vec中CBOW模型的NS算法对新文本text中每个样本词word,需要对所有训练样本进行带权采样,但是实际应用中在线训练样本无法一次性全部得到,因此每接收到新样本,就需要对所有样本重新训练,这对时间和空间的需求都很高。针对这个问题,本文发明一个基于历史词语的反例采样算法(Negative Sampling on Old Words,NSOW),从{w1,w2,....,wk}抽样得到word的反例样本集合Neg(word),算法过程如下。
算法2包含三个部分,首先在更新的历史词表{w1,w2,...,wk}中随机抽取一个词w_,然后判断词w_正负性,若不是正例样本词word则将其作为反例样本加入反例样本集合Neg(word),最后判断反例样本集合大小,每个词word的反例样本个数n设为[min,max]之间随机数,若集合长度达到n则停止抽样,输出Neg(word)={w_1,w_2,...,w_n∈new_word_list},反之则回到第3行继续进行抽样。算法2中,无论更新的历史词表有多长,n次随机抽样带来的时间复杂度均为常数阶级O(n),因而算法执行效率高,同时new_word_list是一个动态更新信息的词语列表,因而当中词word被抽中概率为p(word)=(word频次)/(总词频数)。因此,算法2既保证可以高效地对更新词表进行抽样,又可以确保选择高频词作为反例样本集合概率高于低频词,使得高频词能进行更多向量优化更新来适应新增数据,而低频词则更倾向于保留旧信息。
3.新词的初始化更新(第6~8步)
通过算法2得出反例样本集合Neg(word),利用公式(2)将集合{word}∪Neg(word)中的词语w赋予标签,然后获取word在text中的上下文Context(word,c)及其线性相加向量xword,最后采用NS算法中的随机梯度上升法进行词向量v(u)与辅助向量θw优化,完成ILW算法对于新文本text的增量式学习。公式为式2和式3,如下:
ILW算法总流程如下:
综上所述,ILW通过算法1渐进的进行“新词”更新,利用算法2对“旧词”向量进行优化,使得更新后的向量模型能适应新文本中包含的语义及语法信息,避免重新对所有语料进行学习。
采用本发明提供的增量式学习方法,针对中文维基百科数据集,对语料进行繁体到简体的转换,去掉文本中的各种标签,用分词系统ICTCLAS2015对文本先后进行分词、标准词性、去除停止词与虚词一系列预处理工作之后得到的语料作为实例文本数据集。采用如上所述的ILW算法,依次执行算法1、算法2、向量优化过程,对新文本完成增量式学习,本实例中将增量式学习方法用于在线系统中增量式训练文本数据,建立词向量模型,其在线算法流程如图1。
本实例从两方面评估ILW的有效性:
(1)检验词向量模型的质量:在不同的向量维数与训练词数下,将CBOW模型的NS算法离线训练的向量模型与ILW在线训练的向量模型进行准确率比较,评估模型质量。
(2)增量学习效率分析:观察ILW算法的增量学习效率随着训练词数与各超参数的变化趋势,分析其增量学习效率是否满足在线系统效率需求。
在(1)检验词向量模型的质量中采用文献(Mikolov T,Yih W T,Zweig G.Linguistic regularities in continuous space word representations[J].In HLT-NAACL,2013.)中Mikolov提出的词向量类比方法对向量模型进行内部评价,进而检验词向量模型的质量。词对部分示例数据如表1。类比词对的部分示例数据见表1。
表1类比词对的部分示例数据
表1中,语义类比类型分为5类:常见首都城市、省会城市、货币、亲戚关系、历史人物,每个类型有400个词对,一共有2000个类比词对。实验针对表1设计一系列X1:Y1≈X2:?的问题。在词向量模型中,如果通过向量加减运算算出的词w正好是表1中对应的Y2,则问题回答正确。比如,河北:石家庄≈河南:?。从语义上看,石家庄是河北的首府,因此作为类比,答案是河南的首府郑州(对应表1中的Y2)。若算出与向量V(河南)-V(河北)+V(石家庄)的余弦相似度最大的词D是“郑州”,则模型“解答”正确,证明词向量模型满足“河北:石家庄≈河南:郑州”的类比关系,且包含了这两对词语之间语义上的关系信息。本实例中将向量模型对所有问题“解答”的准确率作为词向量模型质量的评价指标。在不同的维数与训练数据量下,CBOW模型的NS算法与ILW算法分别构建的两种模型准确率数据如表2。
表2在不同向量维数与训练数据量下,两种算法构建的模型的准确率(单位:%)
图2~4由表2所绘制。图2~3说明随着维度与训练词数增加,NS算法与ILW算法的模型准确率有相似的变化特性。图4说明随着训练词数增加,NS算法与ILW算法的模型准确率差值越来越近,显然随着在线系统中数据量增大,ILW算法的模型质量无限接近于NS算法的模型质量。
在(2)增量学习效率分析中绘制了训练效率变化曲线,如图5。图5中(a)与(b)说明训练数据量的大小不会影响ILW算法的训练效率;图5中(c)与(d)说明了训练效率受文本窗口长度、反例样本个数范围和向量维度这三个内部的超参数影响。由于内部超参数在增量学习中恒等于初始设定值不变,因此ILW算法进行在线增量学习时不会因为数据量的增加而降低效率。比如,由图3可知,当向量维度为300与600时模型准确率较高;结合图5中(a)图可知,上述两个维度可对应维持60000个/秒与30000个/秒的高效率,同时不受数据量大小的影响。
以上实例说明了,在线系统中面对海量实时文本数据时,本文发明的算法仍可以高效、准确地建立词向量模型,实现对词向量的增量式学习。
综上所述,利用本发明提供的ILW增量式学习算法,通过对新增文本中出现的新词进行初始化更新以及基于历史词表的反例采样,基于历史词向量模型对每一篇新文本数据进行增量式学习,对词向量模型进行动态地更新,能够避免对历史数据进行重复性学习,从而大幅减少了计算复杂度。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!