一种基于图像的重光照方法与流程
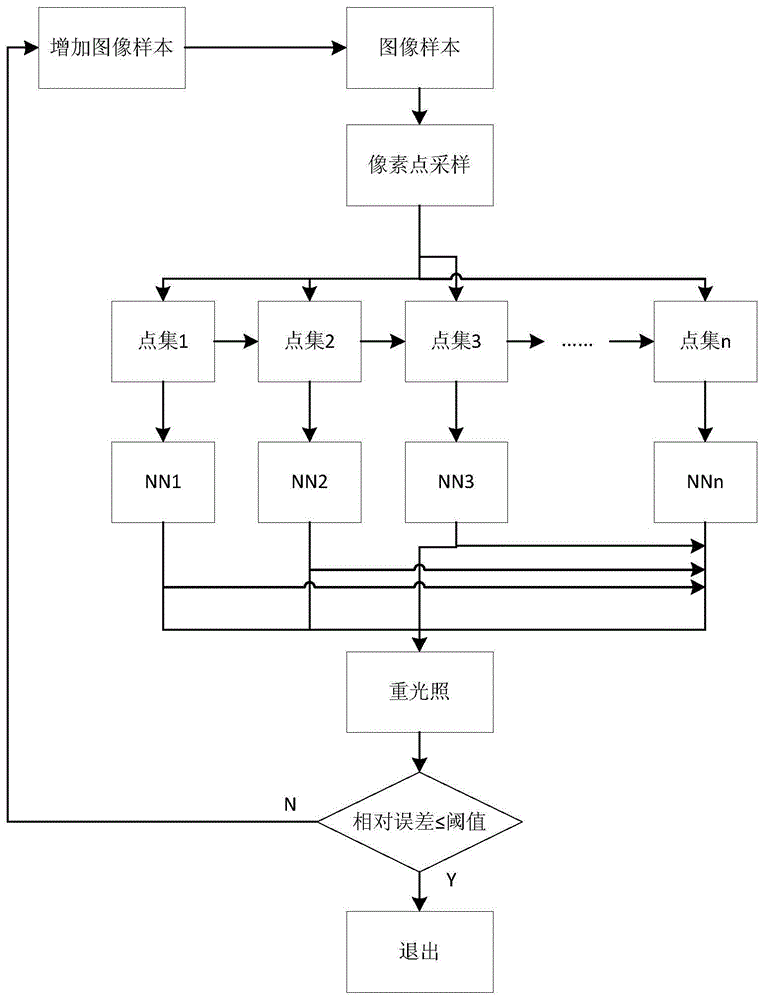
本发明涉及一种基于图像的重光照方法,属于机器学习与图形学领域。
背景技术:
:基于图像的重光照(Image-basedRelighting,IBR),也称基于图像的绘制(Image-basedRendering),其目的是从捕获的图像出发,计算获得光传输矩阵并绘制出新的光源条件下的场景图像。它的最大优势是无需场景的几何信息,渲染不受场景复杂度影响,并且也能表现反射、折射、散射等各种光照效果。因此,IBR自提出以来,立刻成为图形学领域关注的焦点。IBR往往需要通过密集采样获取图像样本,大大增加了工作强度和存储空间。能否利用机器学习方法,通过小样本的采样,尽可能准确的实现基于图像的重光照,是亟需解决的问题。技术实现要素:本发明所要解决的技术问题是提供一种基于图像的重光照方法。通过图像样本逐渐增加、像素空间随机采样、三层神经网络进行训练以及Bagging集成学习思想的综合运用,从而实现了小样本、高精度的重光照效果。本发明为解决上述技术问题采用以下技术方案:本发明提供一种基于图像的重光照方法,其特征在于,包括以下具体步骤:步骤1:采集一组三维场景数据,包括点光源的LigX、LigY坐标及其对应的在固定视点输出的图像集ImageSet,计算得到图像集ImageSet在R、G、B三个通道的平均值ImgAvg_R、ImgAvg_G、ImgAvg_B;步骤2:在图像集ImageSet中随机采样,构成图像样本数为ImageNum的图像子集ImageSubset;步骤3:在图像子集ImageSubset的像素空间中随机采样,获取人工神经网络的训练样本集,具体为:(1)在图像子集ImageSubset的像素空间中随机采样,构成像素点集,其中,采样数为PixNum,像素点的坐标为[Px,Py];(2)训练样本集包括分别对应人工神经网络的输入和输出的两个部分,其中,输入部分包括Px、Py、LigX、LigY、ImgAvg_R、ImgAvg_G、ImgAvg_B,输出部分为[LigX,LigY]与[Px,Py]相应处的图像RGB值;步骤4:利用步骤3的训练样本集对人工神经网络进行训练,训练完成后,将相对平方误差小于等于预设第一阈值δ1的像素点标记为该训练完成的人工神经网络;步骤5,在步骤4中未标记的像素点中重新随机采样,再次训练人工神经网络,直至训练样本集中的像素点全部被标记或未标记的像素点不满足人工神经网络训练的最小样本要求;当未标记的像素点不满足人工神经网络训练的最小样本要求时,利用Bagging集成学习的思想,未标记的像素点由所有神经网络共同决定其输出;步骤6:用训练好的人工神经网络测试图像集ImageSet,若相对平方误差达到预设第二阈值δ2,则保存训练好的人工神经网络,执行步骤7;否则,增加图像样本数ImageNum,返回2;步骤7:用训练好的神经网络重构光源在任意位置下的场景。作为本发明的进一步优化方案,所述步骤3中采样数PixNum≥Pixmin,其中,Tmin是人工神经网络训练需要的最小样本数,a是系数且a≥1)。作为本发明的进一步优化方案,所述步骤4中利用训练样本集对人工神经网络进行训练前,对训练样本集进行归一化处理。作为本发明的进一步优化方案,所述步骤4中的人工神经网络结构是7个输入节点、2个隐层、3个输出节点,其中,两个隐层的节点数相同,输入节点分别为Px、Py、LigX、LigY、ImgAvg_R、ImgAvg_G、ImgAvg_B;输出节点分别为[LigX,LigY]与[Px,Py]相应处图像的RGB值;隐层的节点数Nhide由实验确定。作为本发明的进一步优化方案,人工神经网络训练需要的最小样本数Tmin=b[(7+1)×Nhide+(Nhide+1)×Nhide+(Nhide+1)×3],其中,b是系数且b≥10。作为本发明的进一步优化方案,步骤4中像素点的相对平方误差其中,表示第j张图像的第i个像素点的实际RGB值,Ij(Pixi)表示人工神经网络预测输出的第j张图像的第i个像素点的RGB值。作为本发明的进一步优化方案,步骤5中当未标记的像素点不满足人工神经网络训练的最小样本要求时,利用Bagging集成学习的思想,未标记的像素点的输出由训练好的所有人工神经网络的输出简单平均得出。作为本发明的进一步优化方案,所述步骤6中相对均方误差作为本发明的进一步优化方案,步骤6中根据实际需要增加图像样本数ImageNum。作为本发明的进一步优化方案,图像样本数ImageNum增加20。本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明在模拟的两个三维场景中进行测试,结果表明,与现有的技术相比,不仅训练时间少,健壮性强;在相同的相对误差精度下,重光照所需的图像样本更少,重构场景图像的PSNR值更高。附图说明图1是本发明的方法流程图。图2是分别采用本发明与现有技术的Dragon和Mitsuba场景的训练误差和训练时间的比较图,其中,(a)是Dragon场景的训练误差,(b)是Mitsuba场景的训练误差,(c)Dragon场景的训练时间,(d)是Mitsuba场景的训练时间。具体实施方式下面结合附图对本发明的技术方案做进一步的详细说明:本发明一种基于图像的重光照方法,如图1所示,包括:步骤1:采集一组三维场景数据(Dagon,Mitsuba),包括点光源的LigX、LigY坐标及其对应的在固定视点输出的图像集ImageSet;计算图像集在R、G、B三个通道的平均值,得到ImgAvg_R、ImgAvg_G、ImgAvg_B;场景数据具体如表1所示。表1场景数据场景光源分布图像尺寸Dragon31×3164×48Mitsuba21×2164×48步骤2:在图像集ImageSet中随机采样,构成图像子集ImageSubset,图像样本数为ImageNum。步骤3:在图像子集像ImageSubset的像素点中随机采样,获取人工神经网络需要的训练样本集;(1)在图像子集像ImageSubset的像素空间随机采样,构成像素点集,采样数为PixNum,像素点的坐标为[Px,Py];(2)训练样本集由输入、输出两个部分组成,其中输入属性包括LigX、LigY、Px、Py、ImgAvg_R、ImgAvg_G、ImgAvg_B,输出属性为[LigX,LigY]与[Px,Py]相应处的图像RGB值。步骤4:利用训练样本集对人工神经网络进行训练,训练完成后,将相对平方误差RSE≤预设阈值δ1的像素点标记为该训练完成的人工神经网络。步骤5:在步骤4中未标记的像素点中重新随机采样,再次训练人工神经网络,直至训练样本集中的像素点全部被标记或未标记的像素点不满足人工神经网络训练的最小样本要求;当未标记像素点不满足人工神经网络训练的最小样本要求,利用Bagging集成学习的思想,由所有神经网络共同决定其输出。步骤6:用训练好的人工神经网络测试图像集ImageSet,如果相对平方误差达到预设阈值δ2,则保存训练好的人工神经网络;否则,增加图像样本数ImageNum,从步骤2重新开始。步骤7:用训练好的人工神经网络重构任意光源位置下的场景。随机采样与训练Imageset同等数量的图像集ImagesetTest,用训练好的神经网络重构场景。如图2所示,与Ren等人在“ImageBasedRelightingUsingNeuralNetworks.ACMTransactionsonGraphics,2015.34(4)”文中的技术相比。其中,图2中的(a)和(b)分别是Dragon和Mitsuba场景的训练误差图,(c)和(d)分别是Dragon和Mitsuba场景的训练时间示意图。由图2明显可知,随着图像样本数的增加,采用本发明的方法(图中虚线所示),RMSE明显比Ren方法下降的快,也就意味需要更少的样本达到相同的精度;同样的本发明的方法所需要的训练时间也低于Ren方法。表2是对Dragon和Mitsuba两个场景的测试数据进行场景重构结果,表明采用较少的图像可以获得比Ren方法更低RMSE值。表3场景重构结果以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1