一种压缩电气系统故障概率分布数据的方法与流程
本发明涉及电气安全系统工程,特别是涉及计算系统或元件故障数据压缩及故障概率分布计算。
背景技术:
大数据的发展日新月异,是工程科学研究中不可回避的问题,安全科学中,安全系统工程是研究可靠性或故障概率的一门重要科学,一般在实际生产过程中,积累的故障数据都是较多的,有人员经验、仪器仪表记录、也有经过一些方法分析得到的故障数据,这些数据日积月累,仅对于一个简单的元件其故障数据的记录以较多,那么对于一整套设备的故障数据便可视为大数据量级,对于大数据的处理,在安全科学范畴内是没有专门研究的,但对实际的故障分析是必要的,特别是安全系统工程领域更是迫在眉睫,需要一种能适合于安全系统工程分析,适应大数据要求,并具有一定的数据压缩和推理能力的方法。
目前对于数据压缩的研究主要有气象数据压缩、频率域矢量数据压缩、设备状态信号数据压缩等;与故障相关的数据处理方法有:超高压输电网络故障信息处理、液压机维护、大型离心压缩机故障诊断、电力系统故障分析、数字化电力系统故障分析,这些方法在不同领域中起到了积极作用,但对于安全系统工程领域难有借鉴意义,其原因在于不同领域的数据特征不同,数据表象和内在联系也是差别较大的,有一些因素之间只是简单的线型或是其他关系,但安全系统工程研究的故障数据一方面存在着内在因果联系,同时也具有人为因素和随机性等不确定特征,所以急需一种有效的故障数据处理方法。
SFT(SpaceFaultTree,SFT)理论是一种分析故障影响因素与故障之间关系的方法,目前以可进行有效的故障概率变化分析,但计算过程繁琐,同时所需数据量较大,难以处理大数据量级的故障信息,故障概率分布表示复杂,引入因素空间的相关理论,由于SFT与因素空间基本出发点一致,所以引入的方法无理论障碍,通过因素空间的背景集和内点判定定理,构建了具有满足上述要求的故障数据处理方法。
空间故障树SFT的概念框架以形成两个子分支,分别为:连续型空间故障树(Continuous SpaceFaultTree,CSFT)和离散型空间故障树(Discrete SpaceFaultTree,DSFT),前者以了解系统结构和基本事件的性质为前提,从系统内部出发研究整个系统的可靠性,是由里及表的研究;后者以充分的实际故障观测数据为前提,从系统外部的系统对于工作环境的故障响应来分析系统的可靠性,是由表及里的分析。
空间故障树的核心处理方式就是将有一定规律性、离散性、随机性的可靠性数据表示为连续的特征函数,进而使用结构化方法表示系统可靠性与影响因素之间的关系,随着理论的发展,首先提出用拟合方法进行特征函数构建,但无法表征数据的模糊性;又提出了模糊结构元化的特征函数表示方法,发现该方法仍不能较好的表示数据分布特征;进而将云模型引入构建特征函数,形成云化特征函数,但SFT对故障数据的处理方法仍不能满足大数据的处理要求,也没有适合的对故障数据的压缩方法,造成理论发展和实际应用的障碍,急需智能科学方法加以引入,汪培庄先生提出的因素空间便是其中之一。
一枚硬币在投掷后一般会有两种情况,从表象来看是随机的,但如果确定充分的影响因素,必然会找到确定的因果关系,如不能关系,则肯定有相关影响因素未考虑,这些因素的变化占用一个维度来表示,那么将构成高维空间X(F),因素空间可表示为:F是因素的集合,F的充分性便确定了从X(F)到Ω的一个映射,使偶然现象得到必然性的描述,若存在难以观测和控制的因素,则X(F)的辨别和控制范围从点x蜕化为团粒在进行一种试验时所能识控的范围C叫做条件,已知x在C中但却不知在具体位置,当C的范围跨越了正反两面的边界时,确定性就转化为随机性,不充分条件可对结果产生一定的限制,但不是强制性的,这样的内在必然性即为概率,概率论是一种广义的因果论,注定了概率统计会在人工智能中占有重要的地位,我们现在能对概率论有这样一种较为深刻的认识,是因为有了因素空间,如下给出因素空间的数学定义。
设F={f1,…,fn}是定义在U上的因素集,即fj:U→X(fj)(j=1,...,n)。
定义1设是一个布尔代数,记X(F)={X(f)}(f∈F),称ψ=(U,X(F))为U上的一个因素空间,如果满足条件:
(1)
(2)对任意及s,t∈T,若s∧t=0(s与t叫做不可约),则
X(∨{f|f∈T})=∏f∈TX(f)(∏是笛卡尔乘积) (1),
其中,F={f1,…,fn}={f1∨…∨fn}=1叫做全因素,0叫做空因素.∨和∧分别叫做因素的合成和分解运算。
从本质上来说,空间故障树和因素空间理论的着眼点是一致的——因素,空间故障树中所述空间是将系统工作环境因素作为维度所形成的空间,当各维度上因素的某一值确定后,系统的可靠性确定了,所以空间故障树研究问题的基础就是形成与环境因素数量相等的维度的空间曲面,曲面作为因变量表示系统可靠性,而环境因素在空间维度上的值就是自变量,两种理论解决问题的方式是不同的,因素空间实质上是对于事物存在形态的一种区分,通过因素的不同区分事物,空间故障树理论发展的极致也是通过区分因素了解系统本质的结构和特性,因素空间从数据分析的推理角度出发进行研究,空间故障树是从系统工程的结构化角度出发进行研究,所以两者理论的互用不存在本质障碍。
技术实现要素:
1.一种压缩电气系统故障概率分布数据的方法,其特征在于,引入因素空间中背景集和内点判定定理,构建了故障概率分布计算的新方法;其优点在于所需初始数据量较小;计算简单;具有数据压缩能力;故障概率分布的表示方法简单;步骤包括将因素分为影响因素和目标因素组成值对;划分目标因素,形成不同划分的值对集合;使用内点法化简这些集合;最后得到无重叠的故障概率分布图;可用于计算系统或元件故障数据压缩及故障概率分布计算。
2.根据权利要求1所一种计算故障概率分布的方法,其特征在于使用了故障数据压缩方法,给出故障概率分布计算方法的具体过程:
步骤1)设故障数据值对为(f1,…,fn,g),f1,…,fn表示影响故障概率,为影响因素;g表示故障概率,为目标因素;
步骤2)将实际故障数据表示为多个不同的故障数据值对(f1,…,fn,g)k,k为收集数据数量;
步骤3)将目标因素值域进行划分,Z(g)={z1(g),…,zm(g)|z1(g)∩…∩zm(g)=1且由小到大分配},其中目标因素值域为[0,1];将目标因素g的取值范围划分为m个子范围z1(g),…,zm(g);
步骤4)根据Z(g)的划分对故障数据值对(f1,…,fn,g)k划分为Γ1,…,Γm,Γ1={(f1,…,fn,g)k1|g∈z1(g)},…,Γm={(f1,…,fn,g)km|g∈zm(g)};
步骤5)将各个划分Γ1,…,Γm使用内点判定定理去掉冗余值对,形成对应的值对集合Ω1,…,Ωm;并根据Ω1,…,Ωm绘制故障概率分布A1,…,Am,初始点可选前三个值对或任选三个,其结果相同;
步骤6)分析故障概率分布,确定各划分下的故障概率分布关系;根据SFT的研究基础,并考虑到内点判定定理只适用于凸集,在生成的各划分下故障概率分布可能存在覆盖现象;即大于等于两个划分下的分布产生了重叠,重叠的区域内影响因素可造成目标因素属于两种不同的划分,这是不符合逻辑的;SFT中所研究的可靠性数据和元件特点都是故障概率(目标因素)小的故障概率分布小,大的分布大;即故障概率大的分布可能覆盖故障概率小的分布;这里给定不同划分下故障概率分布重叠时的处理方法:优先满足故障概率小的分布;即如果且i<j,则Ai∩Aj=Ai∩j∈Ai而去掉重复覆盖范围后的不同划分下故障概率分布用Z1,…,Zm,一般的,
3.根据权利要求1所一种计算故障概率分布的方法,其特征在于对电气系统故障数据的压缩和故障概率分布的计算:
步骤1)设故障数据值对(使用时间,使用温度,故障概率)=(f1,f2,g),影响因素f1=使用时间、影响因素f2=使用温度、目标因素g=故障概率;
步骤2)将实际故障数据表示为值对共81个,k=81,(3,5,81%)1,(5,7,88%)2,…,(2,16,12%)81;
步骤3)将目标因素值域进行划分Z(g)={z1(g),z2(g),z3(g),z4(g)}={[0,30%),[30,60%),[60,80%),[80,100%]},语义分别表示{一般不发生,可能发生,经常发生,发生},m=4;
步骤4)根据Z(g)的划分对故障数据值对(f1,…,fn,g)k进行划分;
步骤5)使用内点判定定理对Γ1、Γ2、Γ3、Γ4进行化简,化简后得到的Ω1、Ω2、Ω3、Ω4分别如下;
步骤6)分析故障概率分布,确定不同划分下故障概率分布关系。
SFT中对基础故障数据的表示有很多种方法,CSFT处理的数据关注于实验条件下的规整数据;而DSFT关注于实际生产过程中得到的故障数据,实际中的故障数据掺杂着一定的人为因素和随机性,处理此类数据的方法应具有能包含不确定数据兼容的能力;另外实际故障数据一般数据量较大,处理方法也应包含全部的有效信息,对数据进行压缩,同时具备一定的推理能力,原有安全学科中的故障数据表示方法显然不满足上述要求,应借鉴智能科学的数学方法并加以利用。
前节叙述的SFT所研究的是可靠性与影响可靠性因素之间的关系,例如使用时间和使用温度变化对系统或元件可靠性变化的影响,从实际生产中来源的可靠性数据主要是两类,一是具有实际生产经验的人员给出的评述;二是相关监测仪器给出的记录数据,前者必然受人因影响;后者也受到机器随机因素影响,在分析这些故障数据时必然有一些数据是不正确的,剔除这些数据后仍有冗余数据,SFT分析故障的基础数据可以表示为使用时间、使用温度、故障概率组成的值对,使用时间和使用温度影响故障概率,那么在这里要解决的问题是,如何在众多值对中保留那些最重要的值对,将冗余的值对剔除,以进行故障数据压缩,找到不同故障概率的特征区域(故障概率分布)。
这里使用因素空间理论处理上述SFT故障数据压缩及故障概率分布问题,首先给出因素空间中的背景集概念和内点判定定理。
定义2给定因素空间ψ=(U,X(F)),F={f1,...,fn,g}.设所有因素的相空间都有序而可以用整数来作为相的记号,这样的相空间叫做托架空间。
定义3若背景关系R在托架空间中是凸集,记R的所有顶点所成之集为B=B(R)={P|P是R的顶点},叫做背景基,将R换作是样本S,记B的所有顶点所成之集为B(S)={P|P是S的顶点},叫做样本背景基。
背景基可以生成背景关系,它是背景关系的无信息损失的压缩,无论数据多大,样本背景基的数量始终保持在低维度上,每输入一个新的数据,都要判断它是否是样本背景基的内点,若是,则删除此数据,否则将它纳入样本背景基。
内点判断定理:P是S的一个内点当且仅当在S中存在一点Q,使射线PQ与射线Po形成钝角,亦即,(Q-P,o-P)<0。
例1,在图1中,给定S包含a=(1,5)、b=(2,0)、c=(5,4)三点,问d=(2,2)和e=(1,0)是否在S内,
解
o=(a+b+c)/3=(2.7,3)
(o-d,a-d)=(0.7,1)(-1,3)=2.3>0;
(o-d,b-d)=(0.7,1)(0,-2)=-2<0;
(o-d,c-d)=(0.7,1)(3,2)=4.1>0,
有负值,d是S的内点,
(o-e,a-e)=(1.7,3)(0,5)=15>0;
(o-e,b-e)=(1.7,3)(1,0)=1.7>0;
(o-e,c-e)=(1.7,3)(4,5)=15>0;
均为正值,e不是S的内点。
上述给出了对故障数据压缩的基本方法,下面给出故障概率分布计算新方法的具体过程,
步骤1)设故障数据值对为(f1,…,fn,g),f1,…,fn表示影响故障概率,为影响因素;g表示故障概率,为目标因素;
步骤2)将实际故障数据表示为多个不同的故障数据值对(f1,…,fn,g)k,k为收集数据数量;
步骤3)将目标因素值域进行划分,Z(g)={z1(g),…,zm(g)|z1(g)∩…∩zm(g)=1且由小到大分配},其中目标因素值域为[0,1],将目标因素g的取值范围划分为m个子范围z1(g),…,zm(g);
步骤4)根据Z(g)的划分对故障数据值对(f1,…,fn,g)k划分为Γ1,…,Γm,Γ1={(f1,…,fn,g)k1|g∈z1(g)},…,Γm={(f1,…,fn,g)km|g∈zm(g)};
步骤5)将各个划分Γ1,…,Γm使用内点判定定理去掉冗余值对,形成对应的值对集合Ω1,…,Ωm,并根据Ω1,…,Ωm绘制故障概率分布A1,…,Am,初始点可选前三个值对或任选三个,其结果相同;
步骤6)分析故障概率分布,确定各划分下的故障概率分布关系,根据SFT的研究基础,并考虑到内点判定定理只适用于凸集,在生成的各划分下故障概率分布可能存在覆盖现象,即大于等于两个划分下的分布产生了重叠,重叠的区域内影响因素可造成目标因素属于两种不同的划分,这是不符合逻辑的,SFT中所研究的可靠性数据和元件特点都是故障概率(目标因素)小的故障概率分布小,大的分布大,即故障概率大的分布可能覆盖故障概率小的分布,这里给定不同划分下故障概率分布重叠时的处理方法:优先满足故障概率小的分布,即如果且i<j,则Ai∩Aj=Ai∩j∈Ai而去掉重复覆盖范围后的不同划分下故障概率分布用Z1,…,Zm,一般的,
附图说明
图1内点判定算例图。
图2故障概率数据图。
图3不同划分下的故障概率分布。
图4去掉覆盖后的故障概率分布。
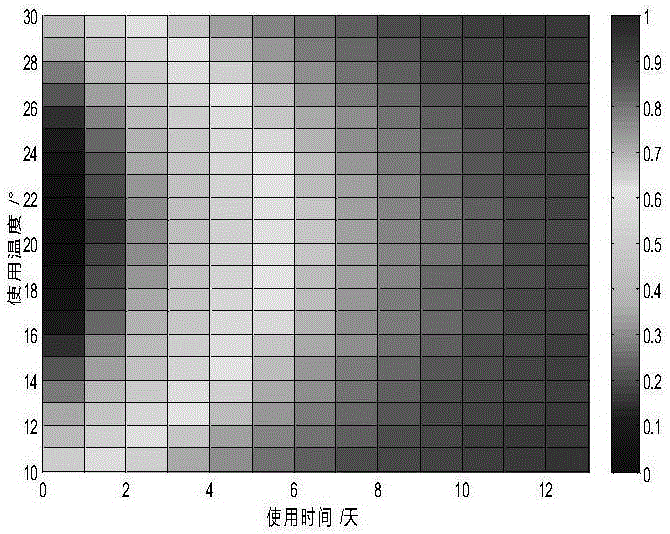
图5使用DSFT方法获得的元件故障概率分布。
具体实施方式
分析实例是针对一个电气元件故障的统计信息,包括使用时间、使用温度和故障概率,来源是操作人员和仪表记录,在实际生产中元件更新的频率设为13天,使用温度理论上为0至40℃,现场统计得到的信息为81条,数据形式为{(使用时间,使用温度,故障概率)}={(3,5,81%),(5,7,88%),(10,5,发生)……},使用上述方法对故障数据进行压缩并绘制不同划分下的故障概率分布。
步骤1)设故障数据值对(使用时间,使用温度,故障概率)=(f1,f2,g),影响因素f1=使用时间、影响因素f2=使用温度、目标因素g=故障概率;
步骤2)将实际故障数据表示为值对共81个,k=81,(3,5,81%)1,(5,7,88%)2,…,(2,16,12%)81;
步骤3)将目标因素值域进行划分Z(g)={z1(g),z2(g),z3(g),z4(g)}={[0,30%),[30,60%);[60,80%),[80,100%]},语义分别表示{一般不发生,可能发生,经常发生,发生},m=4;
步骤4)根据Z(g)的划分对故障数据值对(f1,…,fn,g)k进行划分;
Γ4={(3,5),(5,7),(10,5),(10,10),(10,20),(10,30),(10,35),(13,10),(13,15),(13,25),(13,35),(5,35),(5,40),(4,35),(6,6),(8,5),(6,33),(6,38),(8,35)},共19个值对,因为上述值对中的g∈z4(g)=[80,100%],所以将g从值对括号中提出来以简化表示,同下;
Γ3={(1,8),(3,10),(3,8),(5,9),(5,15),(7,12),(7,28),(9,16),(9,25),(10,21),(1,40),(3,28),(3,32),(1,35),(2,32),(2,38),(3,11),(3,30),(4,11),(4,29),(5,20),(5,25),(5,30),(6,14),(6,20),(7,15),(7,19),(8,15),(8,25),(9,16),(9,23)},共31个值对,g∈z3(g)=[60,80%);
Γ2={(1,9),(1,14),(1,27),(1,32),(3,11),(3,28),(2,10),(2,16),(2,26),(2,31),(5,15),(5,26),(6,21),(1,12),(1,28),(3,13),(3,30),(3,27),(3,19),(4,17),(4,20),(4,25),(4,27)},共23个值对,g∈z2(g)=[30,60%);
Γ1={(1,14),(1,16),(1,27),(2,17),(2,24),(1,20),(2,20),(2,16)},共8个值对,g∈z1(g)=[0,30%)。
将上述Γ1、Γ2、Γ3、Γ4包含的故障数据值对绘制在坐标系中,横坐标代表使用时间,纵坐标代表使用温度,不同的符号代表不同的故障概率范围,如图2所示。
从图2中可以看出,从实际中得来的故障数据是杂乱无章的,有些数据存在着重复现象,虽然是原始数据样本,但对信息的处理和压缩是及其不方便的,导致难以得到有效的故障概率分析结果,也造成了SFT难以用于实际问题处理的弊病。
步骤5)使用内点判定定理对Γ1、Γ2、Γ3、Γ4进行化简,化简过程与例1类似,这里不再给出,化简后得到的Ω1、Ω2、Ω3、Ω4分别如下:
Ω4={(5,40),(4,35),(3,5),(10,5),(13,10),(13,35)},化简后共6个值对,g∈z4(g)=[80,100%],压缩了68%;
Ω3={(1,40),(1,8),(3,8),(5,9),(7,12),(9,16),(10,21),(9,25)},化简后共8个值对,g∈z3(g)=[60,80%),压缩了74%;
Ω2={(1,32),(1,9),(3,11),(5,15),(6,21),(5,26),(3,30)},化简后共7个值对,g∈z2(g)=[30,60%),压缩了67%;
Ω1={(1,27),(1,14),(2,16),(2,24)},化简后共4个值对,g∈z1(g)=[0,30%),压缩了50%。
全部数据压缩了56条(69%),可见上述方法对故障数据的压缩是合理且可行的,另外通过上述方法压缩的数据可表示原数据集的信息,是无损形式压缩,下面来分析上述压缩后故障数据值对构成的故障概率分布。
步骤6)分析故障概率分布,确定不同划分下故障概率分布关系,图3中给出了不同使用时间和使用温度影响下元件的故障概率分布,根据步骤5)进行的化简,得到上述图中蓝色线围成的区域A4为g∈z4(g)=[80,100%];红色线围成的区域A3为g∈z3(g)=[60,80%);紫色线围成的区域A2为g∈z2(g)=[30,60%);绿色线围成的区域A1为g∈z1(g)=[0,30%),由于内点判定适用于凸集,所以图3中出现了分布覆盖的现象,根据覆盖处理方法,最终得到的不同划分下故障概率分布为:故障概率为[0,30%)的Z1=A1;故障概率为[30,60%)的故障概率为[60,80%)的故障概率为[80,100%]的绘制无覆盖不同划分下的故障概率分布如图4所示。
图4为去掉覆盖后的故障概率分布,从图中可知不同的使用时间和使用温度将使元件故障概率的变化不同,不同颜色代表了不同的故障概率变化范围,其中图中无颜色区域为无有效故障数据值对区域,在一些故障数据压缩后也可能存在数据孤岛,但上述方法可将数据孤岛表示出来。
图5为过DSFT的相关方法获得的该元件故障概率分布,是通过实际故障数据特征根据神经网络方法进行处理生成故障概率分布,方法本身虽反映全面,但存在着固有问题,比如需要数据量较大,14×41个数据对;计算过程较为复杂,需通过神经网络分析;不能适应大数据进行数据有效压缩;必须通过MATLAB图表示故障概率分布,本方法计算较为简单,为乘加法;可进行较为有效的数据压缩;对故障概率分布的表示形式简单,本例所得的故障概率分布可表示为:
Ω4={(5,40),(4,35),(3,5),(10,5),(13,10),(13,35)},g∈z4(g)=[80,100%];
Ω3={(1,40),(1,8),(3,8),(5,9),(7,12),(9,16),(10,21),(9,25)},g∈z3(g)=[60,80%);
Ω2={(1,32),(1,9),(3,11),(5,15),(6,21),(5,26),(3,30)},g∈z2(g)=[30,60%);
Ω1={(1,27),(1,14),(2,16),(2,24)},g∈z1(g)=[0,30%)。
- 还没有人留言评论。精彩留言会获得点赞!