层次性多示例多标记学习的设计方法和系统与流程
本发明涉及一种基于层次性多示例多标记学习的设计方法,属于机器学习的技术领域。
背景技术:
监督学习是机器学习领域解决实际问题时常见的学习框架,它先对学习对象进行特征提取,即:学习对象由一个示例(即属性向量)描述且对应于一个概念标记。具体来说,令Χ为示例空间、Y为标记空间,则学习任务就是从数据集{(x1,y1),(x2,y2)…(xm,ym)}中学得函数Χ→Y,其中xi∈X为一个示例,yi∈Y为示例xi所属的类别标记。
随着监督学习框架在多种研究领域的广泛应用,其问题亦应运而生。因为在真实世界中多义性对象的存在:一个对象可能包含多个示例同时对应于多个类别标记,此时如果利用上述监督学习框架并不能进行很好的建模。并且仅仅用一个示例来描述学习对象往往会导致有用信息的丢失,降低学习的性能。举些例子来说,在图像分类问题中,一幅图像往往可以分割为多个具有特定含义相对独立的区域,每个区域都可以用一个示例来描述,这样,一幅图像就可以表示成多个示例组成的一个集合,与此同时该图像往往可能同时隶属于多个概念标记;在文档分类中,可以根据其各部分表达含义的不同划分为若干部分,每个部分用一个示例来描述,这样,一个文档就可以表示成多个示例的集合,而该文档在从不同的角度进行思考时,可能同时隶属于“政治”、“经济”、“文化”等多个概念类别标记;在生物信息学中,基因或者蛋白质的每个特征可以由一个示例进行表示,而基因或者蛋白质本身往往隶属于多个生物学功能。为解决上述问题提出了多示例多标记学习学习框架,每个训练样本由多个示例组成的包描述,同时隶属于多个类别标记集。那么形式化地说,令Χ为示例空间而Y为标记空间,则学习任务就是从数据集{(Χ1,Y1),(Χ2,Y2)…(ΧN,YN)}中学得函数2Χ→2Y,其中Χi∈X为一组示例yi∈Y为Χi隶属的类别标记此外,ni表示Χi中所含示例的个数,li表示Yi所含的标记个数。
随着机器学习理论与应用研究越来越深入,多示例多标记学习显然已经成为机器学习领域热门研究方向之一。由于多示例多标记学习问题与现实应用密切相关,针对多示例多标记学习分类问题的研究具有重要的理论和应用价值。多示例多标记学习是一个具有挑战性的研究课题,过去主要应用于文本分类领域,而现在引起了越来越多的研究人员的兴趣,并应用到很多新的研究领域,如娱乐分类、蛋白质功能分类、Web信息挖掘、数据信息检索以及图像和视频的语义分类等。
但是,目前已存在的多示例多标记学习算法没有考虑标记间层次性结构,可是,现实很多应用中标记之间的关系呈现层次性结构。例如,在文档分类问题中,如果已知一篇文档描述的是关于足球的体育类新闻,则该文档可以标记为新闻类、体育新闻类、足球新闻类等,可以看出标记类别是呈现一定层次性结构的。若标记为体育新闻类,则该文档同时标记为休闲新闻类的可能性将大于标记为政治新闻类的可能性。再比如,如果已知一段视频或一幅图像标记为“野生动物”类,则该视频或图像同时标记为“草原”类的可能性将大于其标记为“城市”类的可能性。所以,随着在多示例多标记学习领域的研究深入,迫切需要挖掘出一种能应用于层次性多示例多标记学习的算法。层次性结构一般分为:树形(tree)或者有向无环图(DAG)结构,他们的不同之处在于,DAG结构中节点可以有多个父节点,最典型的例子就是:蛋白质的GO(即基因本体学)功能信息呈现DAG结构。GO是用于描述蛋白质的功能信息的,它主要从分子功能、生物学过程、细胞组分三个方面描述蛋白质信息,每一方面都呈现出有向无环图结构。而本发明能够很好地解决上面问题。
技术实现要素:
本发明目的在于解决了已有的多示例多标记学习方法没有考虑标记间层次性结构关系的问题,设计出一种将多示例单示例化方法、多标记学习与标记间层次性结构的优化方法集合到一个框架中的新的层次性多示例多标记学习设计方法及系统框架。
本发明解决其技术问题所采用的技术方案是:本发明将多示例单示例化方法、多标记学习与标记间层次性结构的优化方法统一到一个框架中,提出了一种全新的层次性多示例多标记学习设计方法。它充分利用各训练样本所包含标记之间的层次性关系,有效地预测新样本的标记集合,为多种应用提供了有效的解决思路。我们提出的层次性多示例多标记学习设计方法主要考虑了如下问题:
1)为现实中存在的多种层次性多示例多标记学习任务第一次提出详细的解决方案;
2)完善层次性标记的代价损失函数,保证了每一层被错分结点的代价权重不一样,同时缩小了在每个被错分结点上代价损失之间的差距,体现了层与层之间代价损失数值的合理性方法。
方法流程:
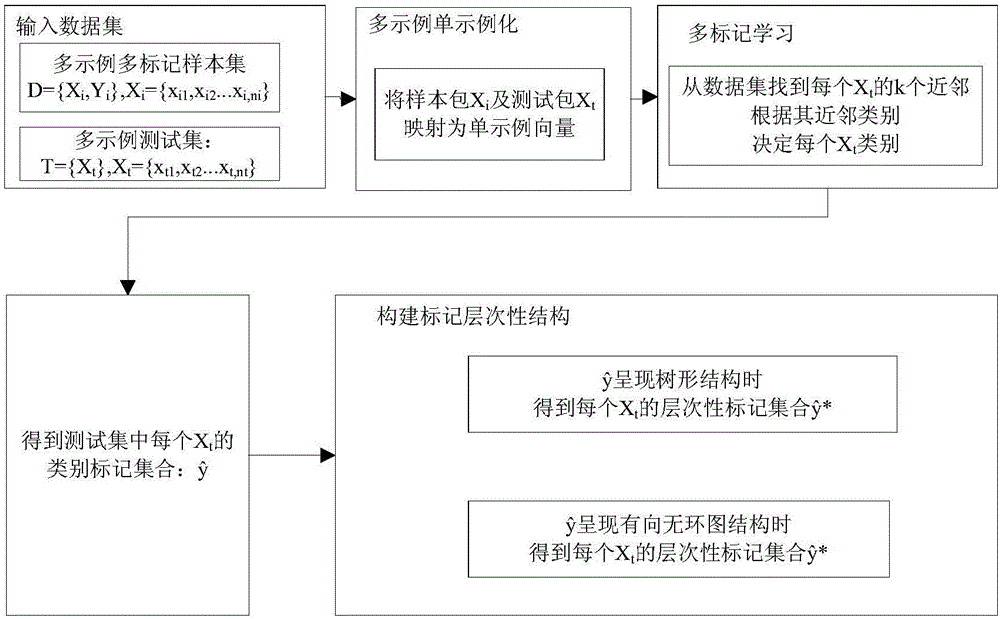
步骤1:给定输入多示例多标记训练数据集:
D={(Xi,Yi)|1≤i≤N},包含ni个样本示例(每个样本包含示例个数可能不一样,每个示例为d维),Yi={yi,1,…,yi,n}为第i样本包的标记,以及多示例测试集T={Xt},
步骤2:所有样本包Xi,以及测试包Xt进行多示例单示例化,将原始的多示例样本包压缩为(2d+1)K维单示例向量;
步骤3:基于步骤2中将多示例样本包转化为单示例向量,从而将多示例多标记学习问题转换为多标记学习问题;
步骤4:给定测试集T,通过多标记学习算法,得到每一个测试样本Xt的预测类别标记
步骤5:结合标记之间层次性结构的关系重新优化、调参,得到最终的层次性结构的标记集合这就是测试样本Xt的层次性类别标记集。即:分类结果。
进一步地,本发明的方法包括多示例单示例化、多标记学习、层次性结点被错误分类的代价优化、标记间层次性结构的优化。
进一步地,本发明所述的多示例转化为单示例问题,虽然多示例描述包的信息相对比较完整,但是示例假设空间复杂度较高,所以将多示例转化为能最大程度保留包的信息的单示例向量,从而将复杂的多示例多标记学习问题转化为多标记学习问题,将算法的计算复杂度充分降低。
进一步地,本发明所述的多标记学习问题,是利用分类准则对训练集进行统计和分析,然后基于得到的统计信息,通过“最大后验概率(maximum a posteriori,MAP)”准则预测新样本的标记集合。
进一步地,本发明所述的层次性被错分结点的代价损失,是将层次性结构中所有被错分结点信息考虑在内,确保同层结点代价损失不同,通过sigmoid函数:之后,缩小了每个被错分结点上代价损失之间的差距,合理优化了代价损失的数值,间接提高了模型的预测性能。
进一步地,本发明所述的步骤4预测出的测试样本的标记集,再结合标记的层次性结构,重新优化、调参,最终预测出测试样本的层次性标记集合。
本发明还提供了层次性多示例多标记学习的设计系统,该系统主要包括多示例单示例化模块、多标记学习模块、标记间层次性结构的优化模块。
多示例单示例化模块的功能是将多示例学习的样本包映射为一个新的能够最大程度保留包信息的向量表示,简化示例空间的复杂度,从而将多示例多标记学习问题退化为多标记学习问题。
多标记学习模块的功能是根据训练数据建立模型,来预测新样本的类别标记集合。
标记间层次性结构的优化模块的功能是将由多标记学习得到的预测结果,结合标记的层次性结构,重新优化、调参,最终得到新样本的层次性标记集合。
有益效果:
1、本发明完成了多示例多标记学习与层次性结构的统一,解决了标记之间的关系呈现层次性结构的多示例多标记学习问题。
2、本发明解决了层次性多示例多标记学习中,每个被错分节点代价损失的优化问题,并且合理利用损失函数,把每个被错分结点的信息都考虑在内。
3、本发明考虑了标记间层次性关系,提升了多示例多标记算法的学习效率,提高了分类的准确度。
附图说明
图1为本发明系统的架构图。
图2为本发明的方法流程图。
图3-a为层次性结构为树形时的方法流程图。
图3-b位层次性结构为有向无环图时的方法流程图。
具体实施方式
下面结合说明书附图对本发明创造作进一步的详细说明。
实施例一
如图1所示,本发明提供了层次性多示例多标记学习的设计系统,该系统包括多示例单示例化模块的功能、多标记学习模块的功能、层次性被错分结点的代价优化模块、标记间层次性结构的优化模块。
多示例单示例化模块的功能是将多示例学习的样本包映射为一个新的能够最大程度保留包信息的向量表示,简化示例空间的复杂度,从而将多示例多标记学习问题退化为多标记学习问题。
多标记学习模块的功能是根据训练数据建立模型,预测新样本的类别标记集合。在特征空间中,如果一个样本的k个最相似的样本中的大多数都属于某一个类别,则该样本也属于这个类别。它是利用分类准则对训练集进行统计和分析,然后基于得到的统计信息,通过“最大后验概率”准则预测新的标记集合。
层次性被错分结点的代价优化模块考虑了所有被错分节点的代价损失,从而提高了分类器的泛化性能。保证了每一层被错分结点的代价权重不一样,同时缩小了每个被错分结点上代价损失之间的差距,体现了层与层之间代价损失数值的合理性。
标记间层次性结构的优化模块的功能是将由多标记学习得到的预测结果,结合标记的层次性结构,重新优化、调参,最终得到新样本的层次性标记集合。
如图2所示,本发明提供了一种基于层次性的多示例多标记学习设计的设计方法,该方法具体实施步骤包括如下:
1、多示例样本包单示例化
多示例转化为单示例过程:对于多示例学习,一个样本是由多个示例组成的示例包。该过程是将多示例学习的样本包映射为一个新的能够最大程度保留包信息的向量表示,从而将多示例多标记学习问题转化为多标记学习问题。
以下就是本发明将多示例包映射为单一向量的映射函数的求取过程:
给定任意样本包由于包中的示例是独立同分布的,使用高斯混合模型(GMM)描述如下:
其中Ω={ωk,μk,Σk,k=1,…,k}是GMM的参数,ωk是混合权重,μk是平均向量,∑k是第k个高斯过程的协方差对角矩阵,是相应的方差向量。pk是第k高斯过程,表示如下:
对(1.1)式关于Ω求梯度并归一化:
注意到,样本包Xi中示例的维度是d,是标量,和都是d维向量,那么映射函数以高斯混合模型p将样本包Xi映射为组成的(2d+1)K-维的Fisher向量过程如下:
1)在样本数据上使用最大似然估计(MLE)确定GMM参数Ω。
2)将所有的样本包映射为单一向量。
3)对得到的单一向量进行L2范数标准化处理。
通过以上方法,本发明首先将所有样本包转化为单一向量的单示例表示。
2、多标记模型构建
上述1中已将多示例样本包转化为单示例向量,从而问题退化为多标记学习,本发明使用的多标记学习算法是一种惰性学习算法,它并没有在整个样本空间上一次性地估计目标函数,而是针对每个待分类样本做出局部的和相异的估计。
本发明的方法是一种惰性学习方法。该方法的思想是:在特征空间中,如果一个样本的k个最相似(即最邻近)的样本中的大多数都属于某一个类别,则该样本也属于这个类别。它是利用分类准则对训练集进行统计和分析,然后基于得到的统计信息,通过“最大后验概率”准则预测未见示例的标记集合。
给定包含q个标记的多标记训练集D={(x1,Y1),...,(xm,Ym)},对于未知样本x的标记矢量表示为:其中表示第j个标记,如果j∈Y,否则为0。假设Ν(x)表示x在训练集中的k个近邻样本构成的集合,对于第j个标记y(j)(1≤j≤q),该算法首先计算N(x)中属于标记y(j)的样本个数Cj:
令Ej表示样本x属于标记y(j)的事件(Event),Ρ(Ej|Cj)表示当x的k近邻集合Ν(x)中有Cj个样本属于标记y(j)的条件下,事件Ej成立的后验概率,相反的,P(-Ej|Cj)表示N(x)中有Cj个样本属于标记y(j)的条件下,事件Ej不成立的后验概率。基于最大后验概率准则即可得到多标记分类器,表达式如下:
Y={y(j)|f(x,y(j))=Ρ(Ej|Cj)/Ρ(-Ej|Cj)>1,1≤j≤q} (2.2)
由于后验概率难以直接计算,基于贝叶斯定理,可将其转换为求先验概率和条件概率:
P(Ej|Cj)=P(Ej)×P(Cj|Ej)/P(Cj) (2.3)
因此,多标记函数可重写为:
多标记分类器可重写为:
Y={yj|P(Ej)×P(Cj|Ej)/P(-Ej)×P(Cj|-Ej)>1,1≤j≤q} (2.5)
其中,Ρ(Ej)表示事件Ej成立时的先验概率,P(-Ej)表示事件Ej不成立时的先验概率,P(Cj|Ej)表示事件Ej成立时,近邻集合N(x)中有Cj个样本属于标记y(j)的条件概率。
先验概率和条件概率可基于对训练集进行频率计数的方式进行估计。先验概率利用统计训练集中属于每个标记的样本数估计得到:
其中,s是平滑参数,用以控制均匀分布在概率估计时的权重,一般设为1对应Laplace平滑。
条件概率的估计方式较为复杂,首先需要计算出两个数组:
其中δj(xi)与式(2.1)中定义的Cj类似,统计了样本xi的k近邻中属于标记y(j)的样本个数。κj[r]统计了属于标记y(j)且其k近邻集合中恰好有r个近邻属于标记y(j)的训练样本的个数,相反统计了不属于标记y(j)但其k近邻集合中恰好有r个近邻属于标记y(j)的训练样本的个数。条件概率估计如下:
通过以上多标记学习方法,可以得到给定新样本的标记集合即在每
个标记节点上的输出值:pi
3、层次性结构构建学习方法
代价函数优化过程:层次性多标记学习允许一个样本属于多个类别标记,标记之间的关系可以呈现层次性结构,其中层次中每个节点的代价损失是学习的重点,过去常用的每个节点的代价损失权重是:ci=cpa(i)/nsibl(i)(i为除根结点外的结点,pa(i)表示i的父节点,nsibl(i)统计i的兄弟姐妹的个数),常用损失函数为汉明损失:这样计算结点代价损失,可能会有如下问题:
1)已知的样本标记信息都是叶子结点,由于不同叶子结点的结点深度不一样,所以ci实际差距不是呈现倍数关系
2)每个结点直接使用公式cpa(i)/nsibl(i)计算ci,不是实际情况
3)层次性结构层数深,很多节点的子节点数量多,如果使用公式
cpa(i)/nsibl(i)计算ci,那么往往忽略了深层被错分节点的ci
所以,我们提出了一种有效的解决方法,再将ci通过一个sigmoid函数:这样保证了每一层被错分结点的代价权重不一样,同时缩小了每个被错分结点上代价损失之间的差距,体现了层与层之间代价损失数值的合理性。
层次性结构构建过程:给定测试样本xt,由上述2)可以得到xt的标记集合在该方法中,考虑标记之间的层次性结构,重新优化调参,最终得到样例的层次性标记集合。其中一个关键的步骤就是找到满足以下问题的多标记集合
●与上述2)中粗略估计的标记集合最大程度相似
●满足标记的层次性结构
●预先设定的正标记个数为:L
对于每个标记结点:
δ(i)=ci(αpi-β(1-pi)) (3.1)
其中pi是样例xt在每个标记结点上的输出值,那么优化δ(i),使其最大化,就能得到样本xt的L个正标记集合{n1,n2…nL},也即优化如下公式:
引入一个二进制指示函数θ(i)∈{0,1},θ(i)=1表示样本有第i个标记,θ(i)=0表示样本不具有标记i。则式(3.2)可重写为:其中由于标记的层次性约束有两类:tree、DAG,那么相应的优化问题分以下两种:
a)标记之间的关系呈现tree结构时,优化问题可重写为:
伪代码如下:
b)标记之间的关系呈现DAG结构时,优化问题可重写为:
伪代码如下:
说明:1)SNV是指超结点S中所有结点pi值和的均值。
2)由二进制指示函数θ(i),将θ(i)=1的所有节点在最后迭代中被选择出来,即样本xt的相关标记集合{n1,n2…nL}。由于部分θ(i)是小数形式,它的处理根据不同应用而定,因为我们着重得到:召回率-精度曲线,所以我们把小数形式的结点也当作正标记处理,那么,最终得到样本xt的正标记个数就会大于L。
本发明所解决的问题包括如下:
(1)更新层次性标记结点的代价权重,把每个被错分结点的信息都考虑在内
由于每个错分结点都代表了分类器的认知能力,所以定义好每个节点的代价函数是学习层次性多示例多标记问题的重点。过去考虑层次之间代价信息呈现倍数关系,但是由于每个节点所在层次以及所含子节点数目不尽相同,如果只是呈现倍数关系过于简化,所以我们提出再通过sigmoid函数,一方面考虑了所有错分结点的代价损失,另一方面也体现了其数值的合理性。
(2)完成了多示例多标记学习与层次性结构的统一,提高了多示例多标记学习模型的预测性能
传统的多示例多标记学习算法中没有将标记之间的层次性结构考虑在内,建立模型时虽然考虑了标记之间的相关性,但是标记之间具体呈现怎样的结构没有考虑清楚,所以构建的模型准确率较低。本发明中将标记之间的层次性结构引入计算中,充分考虑标记之间的相互影响,结合由惰性多标记算法得到的标记集合,重新优化调参,最终得到层次性结构的标记集合。
实施例二
本发明的算法伪代码如下:
。
- 还没有人留言评论。精彩留言会获得点赞!