一种用于管网建模的时序数据清洗方法与流程
本发明属于数据处理技术领域,具体而言,涉及一种用于管网建模的时序数据清洗方法。
背景技术:
管网建模过程中涉及到大量监测数据处理,例如涉及到的以时间序列的数据主要有水厂出水压力和出水流量的监测数据,居民生活用水量、用水模式数据,用于模型校验的管网监测点的压力、流量数据等。但是,这些数据中有些是正确的,而有些则由于机械仪器误差等某些不特定因素,会不可避免的存在某些时间点异常值、数据缺失、数据重复等问题。如果不加以筛选,势必会对模型计算结果产生一定的影响甚至有可能直接导致模型计算不收敛,模型崩溃等现象的发生,因此我们在将这些数据导入到模型计算之前需进行数据的预处理使之达到清洗的效果,为模型的计算提供保证。
例如,在收集到的时序监测数据中,有时候会出现个别的异常数值,从直观上看,这个数据要比其它数据小许多或者大很多。在处理试验数据时,对于这样的个别异常值,是否要剔除,剔除后如何补齐,如果单纯凭直觉判断,缺乏理论上的依据。对于建模监测数据中上述异常值、数据缺失、数据重复问题,目前还没有一套完整的标准化处理流程。通常在建模时对于异常值仅为人工判断合理区间,对于缺失值和异常值的处理是忽略缺失值使用简单的线性差值来补充异常值。
技术实现要素:
本发明的目的在于提供一种用于管网建模的时序数据清洗方法,该方法针对管网建模中的时序数据,能够采取较为合理科学的数据预处理方式为模型计算的精度提供保证。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种用于管网建模的时序数据清洗方法,包括以下步骤:
步骤1)重复值筛出;
利用结构化查询语言(SQL)选取所需时间段的数据,同一监测点位的数据作为一组,进行重复值查找,并删除相同时间点的重复值;
步骤2)离散程度分析;
批量分别计算不同组数据最大值Xmax、最小值Xmin、平均值μ、标准差σ和变异系数CV,其中CV=σ/μ,通过标准差σ和变异系数CV来分析数据的离散程度,通过变异系数CV的处理可将不同量纲的流量和压力数据同一批次处理;并对变异系数CV设定阈值,当变异系数大于所设定的阈值时,则判定该监测点位的数据为无效数据,并进行删除,不参与模型计算;
步骤3)异常值判定;
通过三倍标准差法确定上下限值,即正常值X为,确定上限值为,确定下限值为,对于不符合此范围的值均为异常值进行剔除;
步骤4)平滑曲线去噪点;
对于已去除异常值的各组监测点(离散点)数据采用最小二乘法拟合平滑曲线,首先确定一个函数逼近原函数;设近似函数为,函数值与观测值之差称为残差,可以用残差来衡量近似函数的好坏,具体方法为:
根据已知数据点,先利用MATLAB解方程组,得到待定系数和拟合函数;再利用拟合函数值代替曲线噪点值,达到曲线平滑的效果;进一步的,可将替换噪点值后拟合函数值再次进行拟合,重复上述步骤直至残差满足精度要求;
步骤5)对缺失值进行插值处理;
采用三次样条函数对缺失值进行插值,通过上述步骤描述处理监测的时序数据重复值、缺失值、异常值以及离散度较大的序列数据;
在实际建模过程中进行数据处理时,先通过最小二乘法拟合出最逼近观测值的函数,总体把握数据的趋势走向,同时甄别步骤3)中未能通过三倍标准差发去除的异常值并剔除,减小误差的存在;
在实际导入模型数据时,再利用局部分段的数据,采用三次样条曲线插值法将缺失值及异常值剔除的部分进行补齐,以防止拟合曲线数据的失真,同时保留了原合理的观测值。
进一步的,步骤1)中,所述的时间段数据包括水厂出水压力和出水流量的监测数据,居民生活用水量、用水模式数据,以及用于模型校验的不同管网监测点位的压力、流量时序数据。
进一步的,步骤2)中,所述变异系数的阈值可设定为1,即标准差σ小于平均值μ,实践中当变异系数<1时,所监测的压力和流量时序列数据离散程度较好。
进一步的,在步骤4)中,所述的函数的曲线在曲线图上不要求过所有的数据点(可以消除误差影响),但需要尽可能表现出数据的趋势,靠近这些数据点即可。
本发明的有益效果是:
本发明提供了异常值的判定,不同量纲的压力数据流量数据的标准化处理,采用差异显著性分析对异常值快速查找及替换的方法,同时对缺失数据进行比较后选择最合理的插值方式等一整套的数据处理流程。通过引入变异系数(标准差/平均数)以实现不同量纲的压力数据和流量数据标准化处理,可以同时进行判定数组的离散程度并筛选。本发明在方法上先用三倍标准差法对于异常值数据查找处理再用最小二乘法拟合,极大减小了异常值对拟合结果的影响;同时用拟合函数对噪点数据平滑处理进一步的减少异常数据的存在,最小二乘法拟合能够满足不符合正态分布的数据处理;最后采用三次样条插值较线性插值能够使插入的数值更加平滑。因此本发明的方法能够在将数据导入到模型计算之前对其进行预处理,以达到数据清洗的效果,为模型的计算提供保证。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。本发明的具体实施方式由以下实施例及其附图详细给出。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明的时序数据清洗方法的流程图。
具体实施方式
下面将参考附图并结合实施例,来详细说明本发明。
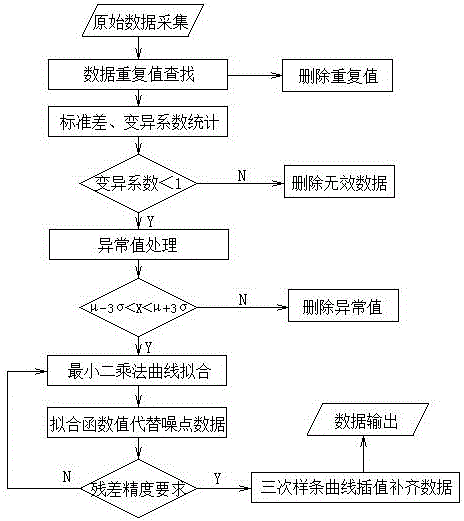
参照图1所示,一种用于管网建模的时序数据清洗方法,包括以下步骤:
步骤1)重复值筛出
利用结构化查询语言(SQL)选取所需时间段的数据,所述的时间段数据包括水厂出水压力和出水流量的监测数据,居民生活用水量、用水模式数据,以及用于模型校验的不同管网监测点位的压力、流量时序数据;同一监测点位的数据作为一组,进行重复值查找,并删除相同时间点的重复值。
步骤2)离散程度分析
批量分别计算不同组数据最大值Xmax、最小值Xmin、平均值μ、标准差σ和变异系数CV。
设这组数值X1,X2,X3,......Xn其平均值(算术平均值)为μ;则标准差σ为:
变异系数为:CV=σ/μ。
通过标准差σ和变异系数CV来分析数据的离散程度,通过变异系数CV的处理可将不同量纲的流量和压力数据同一批次处理;并对变异系数CV设定阈值,当变异系数大于所设定的阈值时,则判定该监测点位的数据为无效数据,并进行删除,不参与模型计算。
实际建模中通常会有某监测点位部分时间段采集到的数据均为0,其余时间点数据正常,与实际情况并不符合,此组数据为无效数据,这样的数据的标准差及变异系数较大,因此可以通过离散度来分析去除。
实际经验中当变异系数<1时,所监测的数据离散程度较好,对于建模中所监测的流量和压力时序数据的变异系数的阈值可选择为1,即标准差σ小于平均值μ。
步骤3)异常值判定
通过三倍标准差法确定上下限值,即正常值X为,确定上限值为,确定下限值为,对于不符合此范围的值均为异常值进行剔除。对于符合正态分布的数据数值分布在(μ-3σ,μ+3σ)中的概率为0.9974,因此在该区间之外的数据均被认为是异常值。
步骤4)平滑曲线去噪点;
对于已去除异常值的各组监测点(离散点)数据采用最小二乘法拟合平滑曲线,首先确定一个函数逼近原函数,该函数的曲线在曲线图上不要求过所有的数据点(可以消除误差影响),但该函数需要尽可能表现出数据的趋势,靠近这些数据点。
设近似函数为,函数值与观测值之差称为残差,可以用残差来衡量近似函数的好坏,具体实现方法如下:
设已知数据点,求m次多项式来拟合函数。需要求出m+1项多项式的待定系数即可,且使得以下函数值达到最小:
;
要使上述函数达到最小值,由高等数学知识有:
;
即
;
于是得到法方程:
;
转换成矩阵如下
;
利用MATLAB解方程组,得到待定系数和拟合函数。
利用拟合函数值代替曲线噪点值,达到曲线平滑的效果。进一步可将噪点值替换后再次进行拟合,重复上述步骤直至残差满足精度要求。
步骤5)对缺失值进行插值处理
采用三次样条函数对缺失值进行插值,通过上述步骤描述处理监测的时序数据重复值、缺失值、异常值以及离散度较大的序列数据;
在实际建模过程中进行数据处理时,先通过最小二乘法拟合出最逼近观测值的函数,总体把握数据的趋势走向,同时甄别步骤3)中未能通过三倍标准差发去除的异常值并剔除,减小误差的存在;
在实际导入模型数据时,再利用局部分段的数据,采用三次样条曲线插值法将缺失值及异常值剔除的部分进行补齐,具体实现方法如下:
在[a,b]上函数的三次样条插值函数S(x)满足:
(1)在[a,b]上0,1,2介导数连续,即
;
(2);
(3)在区间上是三次多项式。
通过上述插值处理对剔除的异常值及缺失值进行补齐,以防止拟合曲线数据的失真,同时保留了原合理的观测值。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!