基于ElasticSearch的HBase模糊检索系统的制作方法
本发明涉及一种数据库检索系统,尤其涉及一种基于ElasticSearch的HBase模糊检索系统。
背景技术:
HBase是一个分布式数据库,具有快速查询海量数据的特点。一方面用Rowkey基于字典序的快速检索。另一方面利用filter过滤的全表扫描查询,支持子字符和正则匹配的模糊查询。HBase全称hadoop database,是Apache的一个开源项目。HBase是一个分布式的列式数据库,基于底层HDFS分布式分拣系统。提供原生Java Api访问方式,使用ThriftServer对外支持多种语言访问。在检索上,使用rowkey做快速检索,而rowkey作为hbase的唯一键值,即hbase没有第二索引。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,Elasticsearch使用Java开发并使用Lucene为核心来实现所有的搜索和索引的功能,通过Rest Api的方式来隐藏Lucene的复杂性,并对外提供操作的服务。内置丰富的搜索方法,如:词条查询、match查询、通配符查询、more_like_this查询、范围查询、正则表达式查询等等。
在Github上有两个开源项目,一个是利用elasticsearch的river实现的定时扫描数据插入到ES中,另一个是利用HBase repilication机制,模拟一个replication节点将数据同步到elasticsearch中。
Lily HBase Indexer基于HBase的replication机制,把HBase中的数据操作,抽象成为一系列的Evernt,通过实现Listener来处理Event,然后同步到Solr中。应用于CLoudera内置的Cloudera Search项目。
现有技术存在如下缺点:
Elasticsearch-HBase-River并未实现支持rowkey的模糊检索,实现了HBase到Elasticsearch的数据同步,然而对大批量数据而言,数据的同步是非常消耗性能和时间的,特别是在资源使用较为紧张时尤为突出。该方案提供了一种数据从HBase到elasticsearch的解决方案,却不是结合HBase做存储查询的良好方案。短期分析可以,长久使用该方案必然会造成性能消耗过大,数据冗余,分析实时性较差。
Lily HBase Indexer并未实现支持rowkey的模糊检索,利用HBase replication机制将HBase的数据同步到solr中,其中将HBase上的数据操作抽象成一系列的Event,用户可以通过实现自己的Listener来处理Event。该解决方案提供了一种技术将数据同步到HBase中,同时可以监听HBase的数据操作进行实施更新,然而相比使用Elasticsearch的人数在逐年减少,热度和支持度不够Elasticsearch的好。
由上可见,使用原生的HBase查询可以分为两种,一种是基于rowkey的查询,另一种是基于filter的过滤查询。然而这两种查询都有其局限性,对于rowkey查询,能快速响应查询请求,查询条件不够灵活;而对于filter查询,目前支持DependentColumnFilter,FamilyFilter,QualifierFilter,RowFilter,ValueFilter等过滤器,基于filter过滤查询其性能不高,最糟糕的情况是全表扫描,随着数据量的增大其查询效率逐渐降低。
技术实现要素:
本发明所要解决的技术问题是提供一种基于ElasticSearch的HBase模糊检索系统,能够大大提高检索效率,满足大批量数据的实时查询分析需求,并有效保证数据的一致性。
本发明为解决上述技术问题而采用的技术方案是提供一种基于ElasticSearch的HBase模糊检索系统,包括:Web接口模块:先根据检索条件调用Elasticsearch模块,获取rowkey集合,再根据获取的rowkey集合调用HBase数据服务模块来获取HBase的数据;Elasticsearch检索模块:根据Web接口模块的输入条件作为检索条件,获取rowkeys集合;数据同步模块:用作HBase的协处理器,将Hbase中的数据与Elasticsearch建立索引,并实现数据初始化、数据操作更新同步和定时同步操作;HBase数据服务模块:将组成rowkey的字段,分别以colume的形式存放于表中;所述Elasticsearch检索模块部署在Elasticsearch集群上,所述HBase数据服务模块部署在HBase集群的服务器上,所述Web接口模块部署于可同时访问Elasticsearch集群和HBase集群的服务器上。
上述的基于ElasticSearch的HBase模糊检索系统,其中,所述Web接口模块通过解析web请求,获取检索条件,并通过HttpClient来获取Elasticsearch中rowkey数据的集合。
上述的基于ElasticSearch的HBase模糊检索系统,其中,所述Elasticsearch检索模块将Web接口模块的输入条件依次进行字符过滤、分词器分词和分词过滤后再进行检索。
上述的基于ElasticSearch的HBase模糊检索系统,其中,所述数据同步模块注册到HBase数据服务模块中作为HBase的协处理器;当HBase启动时,进行数据同步操作;当数据操作更新时,进行数据同步操作;所述数据同步模块定时检索命中率较高的表,按最近最少使用算法定期更新索引。
上述的基于ElasticSearch的HBase模糊检索系统,其中,所述HBase数据服务模块根据每个表的业务数据大小配置预分区,根据数据的使用周期配置TTl,并为rowkey建立字段的联系。
本发明对比现有技术有如下的有益效果:本发明提供的基于ElasticSearch的HBase模糊检索系统,通过将HBase与Elasticsearch结合起来,大大提高检索效率,能够满足大批量数据的实时查询分析需求,并有效保证数据的一致性。
附图说明
图1为本发明基于ElasticSearch的HBase模糊检索系统架构示意图;
图2为本发明的Web接口模块实现流程图;
图3为本发明的Elasticsearch检索模块实现流程图;
图4为本发明的HBase协处理实现流程图;
图5为本发明的HBase中的rowkey存放示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图1为本发明基于Elasticsearch的DSL查询架构示意图。
请参见图1,本发明提供的基于ElasticSearch的HBase模糊检索系统,通过HBase与Elasticsearch接口模块将ES和HBase结合起来,该接口模块由Web接口模块、Elasticsearch检索模块、数据同步模块和HBase数据服务模块组成。各模块的主要功能及实现如下。
1、Web接口模块
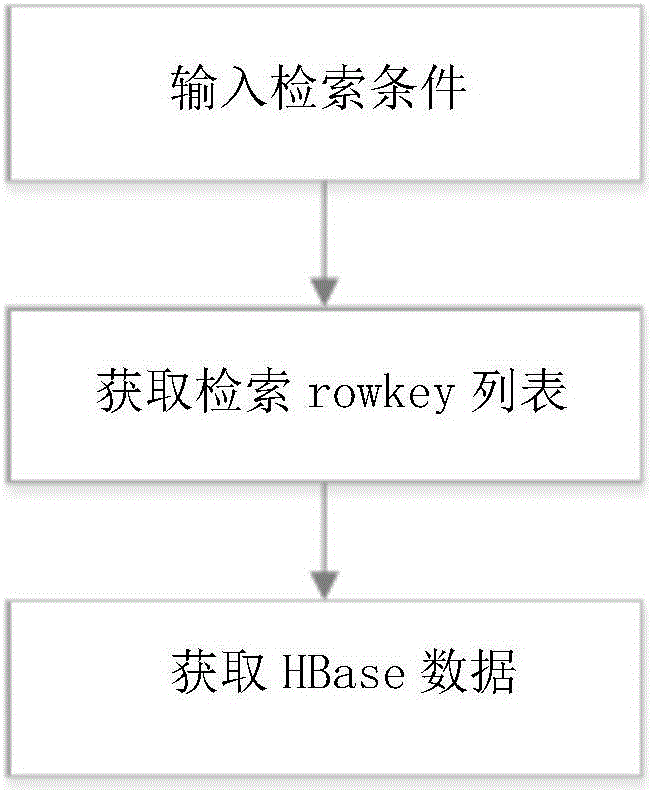
根据检索条件调用Elasticsearch模块,获取封装rowkey集合,从而调用HBase数据服务模块返回检索数据。Web接口调用流程如图2所示,包括如下过程:
解析web请求,获取检索条件;
通过HttpClient来获取Elasticsearch中rowkey数据的集合;
根据上一步获取的rowkey集合来获取HBase的数据。
2、Elasticsearch检索模块
根据web模块的输入条件作为检索,获取rowkeys集合。Elasticsearch检索流程如图3所示,根据请求检索的条件,拼装成url,通过httpclient来获取结果,解析结果集。
3、数据同步模块
通过该模块分别实现数据初始化、数据操作更新同步、定时同步三大功能。HBase协处理实现流程如图4所示:
将协处理的实现注册到HBase中;
当注册到HBase中后,当HBase启动时,进行数据同步操作;
当数据操作更新时,进行数据同步;
定时检索命中率较高的表,按最近最少使用算法定期更新索引。
4、HBase数据服务模块
HBase的存储和查询都要经过rowkey,所以rowkey的设计关系到整个数据的使用周期,本发明将组成rowkey的字段,分别以colume的形式存放于表中,以方便数据更新、数据同步及数据初始化时用于更新索引,如图5所示。
根据每个表的业务数据大小配置预分区;
根据数据的使用周期配置TTl;
为rowkey建立字段的联系。
本发明通过上述四个模块来完成基于Elasticsearch的HBase模糊检索,在集成的过程中将Web接口模块部署于可以同时访问Elasticsearch集群和HBase集群的服务器上。
HBase是一个基于Hadoop的新型非关系数据库,对于数据量比较大的查询和存储性能较高。它以rowkey为唯一键值查询,千万上亿级别的数据查询效率都是在毫秒级返回结果,然而hbase中没有二级索引,此时对rowkey的模糊检索会加载大量的数据到内存中,检索效率不高,所以本发明将HBase与Elasticsearch结合大大提高了检索效率。
ElasticSearch用于全文检索,具有较高的性能和灵活度,它对外发布Restful接口,方便用户使用,同时支持多种语言接口有很好的平台支持。这里通过使用Elasticsearch来检索出对应的rowkey,从而快速定位到HBase中的数据,快速返回结果。
Hbase和Elasticsearch之间本身是没有关联,本发明的数据存储层使用HBase分布式存储服务,接口层采用实现obverser协处理器的方式,数据检索层采用Elasticsearch综合检索。本发明分别从数据初始化、数据定时同步、数据操作这三方面实现HBase的协处理器,通过协处理器将HBase中的数据与Elasticsearch建立索引。应用Elasticsearch优秀的检索能力,快速模糊匹配到所查询的rowkey,从而实现基于Elasticsearch的HBase模糊检索。本发明结合了Elasticsearch的全文检索和HBase的分布式存储能力,Elasticsearch灵活快速检索能力弥补了HBase在检索这块不够灵活的局限,而HBase作为分布式存储数据库其性能比市面上大多数存储系统好,两者优势互补。通过数据操作和数据同步协处理器实现数据同步,保证数据的一致性。本发明通过构建rowkey解析模型,支持模糊检索,快速定位查询rowkey列表,并发起hbase查询请求,以满足实时查询响应低时延的要求;以插件的形式将本发明的技术方案实现无缝接入到现有的生产系统,第一次部署后续无需人工干预;并可兼容Elasticsearch 2.0及2.x和HBase 1.0及1.x版本。具体优点如下:1)提供web服务,通过rest api的形式屏蔽底层使用的技术,降低了使用的复杂度;2)对比传统的HBase模糊索引,无需消耗大代价的全表扫描,可以通过快速定位到需要检索的rowkey,实时返回结果,降低性能的损耗;3)通过最近最少使用算法来定期更新Elasticsearch索引与HBase数据关系的方法,无需全量对HBase进行更新,减少消耗;4)利用Restful的方式对外提供服务,支持用户使用多种语言进行查询服务,易于扩展;5)通过修改配置文件,统一部署易于操作,维护性强。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!