一种基于深度LSTM网络的图像描述生成方法与流程
本发明涉及图像理解领域,尤其是涉及一种基于深度LSTM网络的图像描述生成方法。
背景技术:
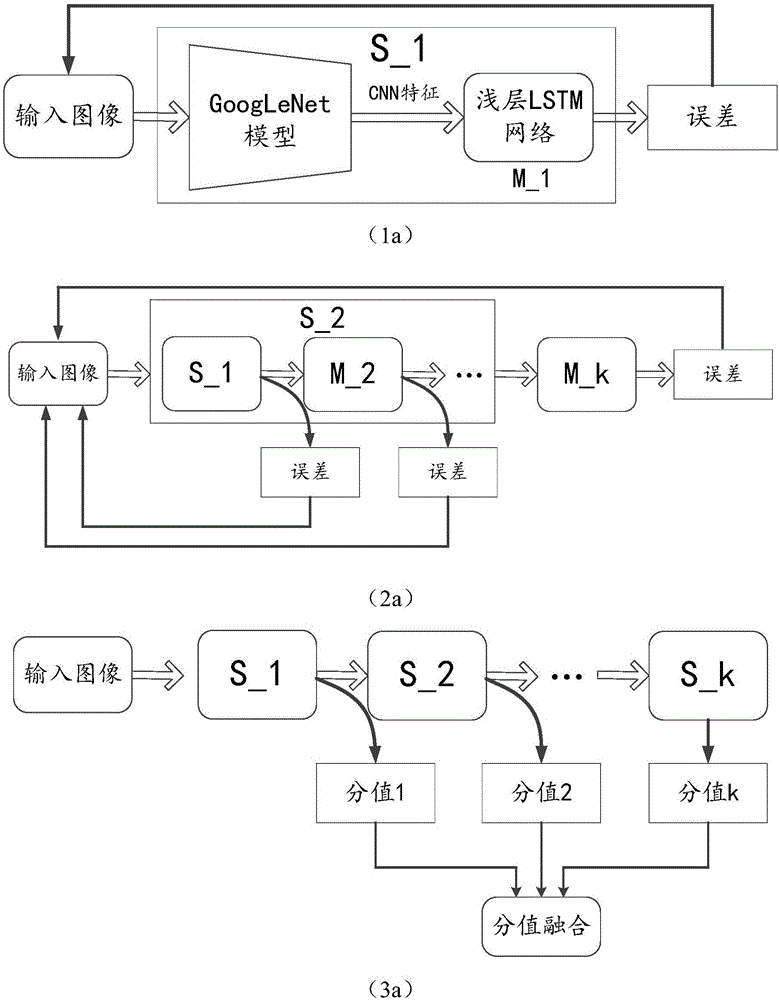
:图像标题生成是一项极具挑战性的工作,在婴幼儿早期教育、视觉障碍辅助、人机交互等领域具有广泛的应用前景。它结合了自然语言处理与计算机视觉两个领域,将一副自然图像使用自然语言的形式描述出来,或者说将图像翻译成自然语言。它首先要求系统能够准确理解图像中的内容,如识别出图像中的场景、各种对象、对象的属性、正在发生的动作及对象之间的关系等;然后根据语法规则及语言结构,生成人们能够理解的句子。人们已提出多种方法来解决这一难题,包括基于模板的方法、基于语义迁移的方法,基于神经机器翻译的方法及混合方法等。随着深度学习技术,尤其是CNN技术在语言识别和视觉领域连续取得突破,目前基于神经机器翻译及其与其他视觉技术混合的方法已成为解决该问题的主流。这类方法考虑了CNN模型能够提取抽象性及表达能力更强的图像特征,能够为后续的语言生成模型提供可靠的可视化信息。但这些方法过于依赖前期的视觉技术,处理过程复杂,对系统后端生成句子的语言模型优化不足;在使用LSTM单元生成句子时,其模型深度较浅(常使用1层或2层LSTM),多模信息变换层次不够,生成的句子语义信息不强,整体性能难以改善。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种多层次、提高表达能力、有效更新、准确性高的基于深度LSTM网络的图像描述生成方法。本发明的目的可以通过以下技术方案来实现:一种基于深度LSTM网络的图像描述生成方法,包括以下步骤:1)提取图像描述数据集中图像的CNN特征并获取与图像对应描述参考句子中单词的嵌入式向量;2)建立双层LSTM网络,其中,第一层LSTM以单词的嵌入式向量为输入,第二层LSTM以第一层LSTM的输出和CNN网络输出的图像的CNN特征为输入,并结合双层LSTM网络和CNN网络进行序列建模生成多模LSTM模型;3)采用联合训练的方式对多模LSTM模型进行训练,将CNN网络和LSTM网络中的参数进行联合优化;4)逐层增加多模LSTM模型中LSTM网络的层次,每增加一层并进行训练,直至生成图像描述句子的质量性能不再提升,最终获得逐层多目标优化及多层概率融合的图像描述模型;5)将逐层多目标优化及多层概率融合的图像描述模型中多层LSTM网络中各分支输出的概率分值进行融合,采用共同决策的方式,将概率最大对应的单词输出。所述的步骤1)具体包括以下步骤:11)将图像描述数据集中的图像缩放至256×256大小;12)在图像上随机截取5个224×224大小的图像块,并将其进行水平翻转,对数据集进行扩充;13)设置CNN网络中的卷积层和分类层的学习率调整因子和权值衰减因子为原来的1/10;14)加载在Imagenet数据集上已优化完毕的参数对模型进行初始化;15)将各图像块输入CNN网络,提取图像的CNN特征,该CNN特征维度为1000维。所述的步骤2)具体包括以下步骤:21)构建双层LSTM网络中的LSTM单元,并设置输入门、输出门、遗忘门和记忆单元;22)获取数据集中描述参考句子的平均长度,并设置每层LSTM的时间步长和隐层单元个数;23)对单词表中的每个单词采用One-Hot方式进行编码,编码维度为单词表的长度;24)将描述参考句子中每个单词的One-Hot编码映射为一个嵌入式向量,并设置向量维度;25)将每个单词的嵌入式向量作为第一层LSTM的输入,并将第一层LSTM的输出和图像CNN特征作为第二层LSTM的输入,建立多模LSTM模型;27)将双层LSTM网络的最终输出输送到分类层,并采用Softmax函数输出该特征在每个单词上的概率分值。所述的步骤3)具体包括以下步骤:31)构建目标函数O,并获取使得损失函数最小的优化参数集合(θ1,θ2):θ1为CNN网络的参数集合,θ2为LSTM网络的参数集合,X2为图像描述数据集中的输入图像,S为与X2对应的描述参考句子,f(·)表示系统函数,为损失函数,N2为训练LSTM网络时,一次迭代中所使用的样本总数,Lk为第k个样本所对应的参考句子的长度,为第k张图像对应的描述参考句子的第t个单词,为生成的第k张图像的第t个单词,为输入的第k张图像,为第k张图像的参考句子的第t-1个单词,为实数域。32)采用链式法则计算误差并采用随机梯度下降的方法对误差进行修正;33)将误差回传到CNN网络中,将每条句子中每个单词的的误差进行求和,并逐层向前传递,完成优化。所述的步骤4)具体包括以下步骤:41)将训练好的多模LSTM模型作为初始模型,记为S_1,初始模型S_1中的双层LSTM网络为初始层次,记为M_1;42)在初始层次M_1的基础上,增加一层与初始层次M_1结构相同的新层次,并采用因式分解的方式进行联结,即:新层次中的第一层LSTM以初始层次的输出以及单词的嵌入式向量为输入,第二层LSTM以第一层LSTM的输出和初始模型中CNN网络输出的图像CNN特征为输入;43)对增加新层次后的模型进行训练优化,包括以下步骤:431)保留初始层次M_1中的目标函数,并将其辅助分支中的分类层的学习率调整因子和衰减因子设置为原来的1/10;432)构建增加新层次后的模型的系统代价函数为其中,n为增加新层次的总数,为在模型增加到第i层进行训练时对应的代价函数,如模型共有3个层次,其中在训练第一层次时,对应一个代价函数,在训练第二个层次时,对应2个代价函数,这样整个模型已有3个代价函数,当有三个阶段时,则共有1+2+3=6个代价函数。43)重复步骤41)-42),在初始层次M_1上逐层增加新的层次并进行训练,直到增加层次使得模型性能不再提升。所述的步骤5)具体包括以下步骤:51)为每个辅助分支添加Softmax函数,输出当前特征属于单词表中每个单词的概率分值;52)对相应位置的所有概率分值使用乘法原理进行融合;53)取所有概率值最大者所对应的单词作为最终输出。与现有技术相比,本发明具有以下优点:一、多层次、提高表达能力:本发明提出了一种构建更深LSTM网络的方法,通过逐层优化的方法,对可视化信息和语言信息进行更多层次的非线性变换,提高生成句子的语义表达能力。二、有效更新:本发明将深度监督的方法引入到了多层LSTM网络中,防止因参数过多造成的过拟合现象,为低层LSTM单元提供正则化,同时保证低层LSTM参数不会因为梯度弥散而造成的难以有效更新的问题。三、准确性高:本发明利用了多层LSTM共同决策的方式,通过乘法原理,将连接多层LSTM的多个辅助分类器输出融合在一起,共同决定下一个单词的输出,其输出单词更加准确,进一步提升了系统性能,并且本发明在MSCOCO、Flickr30K和Flickr8K三个公开数据集上表现优良。在MSCOCO上,其CIDEr达到了94.6,在Flickr30K和Flickr8K上,其METEOR分别达到了19.4和20.8,超过同类其他模型。附图说明图1为本发明的方法流程图,其中,图(1a)为训练第一阶段的流程图,图(2a)为训练第k阶段的流程图,图(3a)为测试阶段的流程图。图2为LSTM单元的结构图。图3为LSTM逐层优化示意图,其中,图(3a)为多模LSTM模型结构图,图(3b)为逐层多目标优化及多层概率融合的图像描述模型结构图。图4为LSTM深度监督训练示意图。图5为LSTM多层概率融合示意图。具体实施方式下面结合附图和具体实施例对本发明进行详细说明。实施例下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。一种基于深度LSTM网络的图像描述生成方法,如图3、图4和图5所示,包括步骤:1)制作训练集、验证集和测试集,使用GoogLeNet模型提取图像的CNN特征;具体过程包括:11)将训练集、验证集和测试集转换为hdf5格式,每张图像对应多个标签,每个标签为该图像所对应的参考句子中的单词;12)读取图像,将其缩放到256×256大小,然后随机截取5个大小为224×224大小的图像块,并将其做水平翻转,将数据集扩充为原来的10倍;13)将GoogLeNet模型文件中的学习率因子和权值衰减因子调整为原来的1/10;14)调用GoogLeNet在Imagenet大规模数据集上已优化完毕的参数集合做为预训练模型,对GoogLeNet进行初始化;15)计算所有图像的均值,将减去均值后的图像数据送入GoogLeNet网络,取最后一层的分类层作为图像的CNN特征,特征维度为1000维;2)建立两层LSTM网络,其中第一层用于接收单词的嵌入式向量,建立语言模型;第二层LSTM用于接收第一层LSTM的输出和图像的CNN特征,并对多模特征进行序列建模;具体步骤包括:21)构建LSTM单元,如图1所示,其中:22)根据训练集中参考句子的情况,生成单词表,对于MSCOCO数据集,单词表长度为10020,对于Flickr30K数据集,单词表长度为7406,对于Flick8K,单词表长度为2549;并统计数据集中参考句子的长度,将每层LSTM的步长设置为20;在MSCOCO数据集上,其隐层输出设置为1000,在Flickr30K数据集上,LSTM隐层输出为512,在Flickr8K上,隐层输出设置为256.23)将单词表中每个单词,使用“One-Hot”方式进行映射,每个单词对应一个映射后的向量,向量维度为单词表大小;24)使用“因子分解”的方式建立LSTM网络,首先在CNN网络和LSTM之间添加嵌入层,将样本参考句子中的每个单词通过嵌入的方式映射为一个维度为1000的长度固定的向量;然后建立两层LSTM单元,第一层用于接收单词的嵌入式向量,建立语言模型,第二层用于接收第一层LSTM的输出和图像的CNN特征,建立多模模型;25)在LSTM网络上添加一个全连接层(分类层),其隐层输出为单词表大小;3.采用联合训练的方式对模型进行训练,将CNN网络和LSTM网络中的参数进行联合优化,避免模型陷入局部最优(如图3(a)所示)。具体步骤包括:31)将每张图像看作一个单独的类别,为其分别类别标签;32)使用GoogLeNet提取图像的CNN特征,并送入LSTM网络;33)使用交叉熵函数计算网络输出的每个单词与实际值之间的误差,并对每张图像中生成句子的每个单词与所有参考句子中单词的误差进行求和;具体表示为:则系统目标为迭代优化(θ1,θ2),使得损失函数最小。其中系统损失函数可表示为:N2表示在训练LSTM网络时,一次迭代中所使用的样本总量,Lk表示第k个样本所对应的参考句子的长度。34)使用链式法则逐层计算误差,并将其回传至整个模型的底层,采用梯度下降的算法,对参数进行更新;其中α表示学习率。4.使用逐层优化的思想和深度监督的方法,逐步增加LSTM网络的层次,提取更加抽象,泛化能力更强的特征,提升生成句子的质量(如图3(b)和图4所示)。具体过程包括:41)将第3)步中已训练好的模型记为S_1,其中的LSTM网络部分记为M_1;将S_1作为下一阶段的预训练模型;42)在M_1的基础上添加新的LSTM层,记为M_2,同时保留M_1中的辅助分支(分类层)和目标函数,但将辅助分支中的学习率调整因子和权值衰减因子设置为原来的1/10;M_2仍然包括两层LSTM单元,第一层用于接收M_1中顶层LSTM单元的输出,第二层接收第一层LSTM的输出和图像的CNN特征;同时添加新的辅助分支(分类层)和目标函数;43)重复42)过程,直到在验证集上性能不再提升,目前还没有发现很好的方法来判定什么时候性能不再提升,所以一般都是通过实验来决定,具体指标包括BLEU、METEOR、CIDEr等,根据经验,一般在大的数据集上可添加的层次更多,在小的数据集上则由于经常发生过拟合现象,添加的层次较少,系统整体的损失函数可描述为:其中n为阶段数(也为目标函数的个数)。5.在测试阶段,将LSTM网络中各分支输出的概率分值进行融合,采用共同决策的方式,决定下一个单词的输出(如图5所示)。具体步骤包括:51)在每个M_i上,在辅助分支(分类层)后添加Softmax函数,取出当前特征属于单词表中每个单词的概率分值;52)将当前特征的所有概率分值使用乘法原理进行融合,具体为:其中,表示CNN特征在t时刻属于第k个单词的概率,表示LSTM网络中在t时刻第j个阶段的特征输出;53)对于t时刻,取所有概率值最大者所对应的单词作为最终输出,具体为:为了验证本申请方法的性能,设计了以下实验。在三个公开数据集上(MSCOCO、Flickr30K和Flickr8K)使用本方法进行训练以及测试,使用BLEU、METEOR、ROUGE_L和CIDEr标准来对生成的句子进行评价。为便于对比,使用S_1模型作为基准模型(baseline)。在MSCOCO数据集上,其训练集有113287张图像,验证集和验证集各有5000张图像,每张图像有5条以上人工标注的参考句子;在Flickr30K数据集上,共有31783张图像,使用其中的29000张图像作为训练集,1000张图像作为测试集,其他作为验证集;在Flickr8K数据集上,共包含有8091张图像,我们取其中6000张图像用于训练,1000张图像用于测试,其余作为验证集。在各数据集上的实验结果如表1、表2和表3所示。表1本发明在MSCOCO数据集上性能表现表2本发明在Flickr30K数据集上性能表现methodB-1B-2B-3B-4METEORROUGE_LCIDErbaseline64.345.731.821.919.145.543.7Deep-264.445.831.621.619.345.443.9Deep-464.846.432.322.319.445.644.1表3本发明在Flickr8K数据集上性能表现methodB-1B-2B-3B-4METEORROUGE_LCIDErbaseline61.543.930.120.420.546.951.7Deep-261.843.729.920.320.747.352.2Deep-462.444.530.520.720.847.252.1当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1