一种基于局部及全局语法统计的股票推荐方法与流程
本发明涉及股票数据挖掘技术领域,尤其是涉及一种基于局部及全局语法统计的股票推荐方法。
背景技术:
股票市场是一个风险和利益共存的市场,股票市场的建模和预测研究对我国的经济发展和金融建设具有重要的意义。
股票技术分析的目的是预测市场价格未来的趋势,为达到此目的所采用的手段是分析股票市场过去和现在的市场行为。市场行为包括:(1)价格的高低和价格的变化;(2)发生这些变化所伴随的成交量;(3)完成这些变化所经过的时间。技术分析的理论基础主要是三大假设:市场行为包含一切信息;价格沿趋势波动并保持趋势;历史会重演。
在数据极为丰富的股票预测领域,数据挖掘的方法得到了越来越广泛的研究与应用。股票数据挖掘的研究主要集中在4个方面:相似序列匹配、股票价格预测、交易规则抽取以及时间模式发现。常用的方法有神经网络、进化算法、模糊逻辑、粗糙集、支持向量机等。
技术实现要素:
本发明公开了一种基于局部及全局语法统计的股票推荐方法。方法把股票小段时间序列的涨跌幅量化值看作是自然语言中的符号串,对股票下一交易日涨跌幅度的预测则类似于对符号串中的下一符号的预测。
本发明方法结合股票的实际,应用n元语法的思想,对股票自身的历史数据和全局的股票数据进行股票语法的规则统计,而后分别利用局部语法和全局语法计算股票下一交易日的涨跌幅得分。最后对两种结果计算综合得分,排序后进行股票的推荐。方法除了可用于股票的每日推荐外,还可用于股票每天的实时推荐。
假设股票列表为S,S=[S1, S2,…,Si,…,Sm],m为股票池中股票的数量,如中国上市股票的数量或美国上市股票的数量。本发明方法的步骤如下:
(1)对股票的涨跌幅值进行量化;
(2)基于股票自身历史数据进行局部多元语法统计;
(3)基于所有股票历史数据进行全局多元语法统计;
(4)获得待预测股票的近期涨跌幅数据并量化;
(5)计算待预测股票的局部语法预测得分;
(6)计算待预测股票的全局语法预测得分;
(7)计算每只股票的综合得分并进行排序推荐。
其中,步骤(1)的对股票的涨跌幅值进行量化,具体为:对于每只股票,获取某个时间点以来(如2005年1月1日)的涨跌幅数据,而后对涨跌幅值进行量化,即对涨跌幅值进行四舍五入的操作,变换为[-10,10]区间的整数值;最后股票池中的每只股票都变换为包含股票涨跌幅整数值的数组。
其中,步骤(2)的基于股票自身历史数据进行局部多元语法统计,具体为:对于每只股票,假设当前股票为Si,i=1,…,m ,对该股票自身的历史数据进行k元语法统计,k取1到5。首先设置一个k维数组,每个维度的长度为21,即每维有21个槽。然后遍历Si股票涨跌幅整数值数组,每次取相邻的两个值,对这两个值的共同出现的次数进行累加统计,并放入k维数组对应的槽中。k元语法统计完后,结合k-1元语法的结果,计算条件概率,对于k维数组中的每一行,计算最后一个维的数值出现的条件概率,其中一元语法不计算条件概率。条件概率的分子为k维数组每行的整数值组合的统计数,分母为k维数组每行整数值去掉最后一位的组合在k-1元语法中所对应的统计数。计算分母时如果k-1元语法没有相应的整数值组合则跳过该条件概率的计算。最后每只股票都有自己的k元语法统计结果。
其中,步骤(3)的基于所有股票历史数据进行全局多元语法统计,具体为:对于所有股票的历史数据进行k元语法统计。统计过程类似步骤(2),不同的是针对所有股票历史数据进行统计,并且最后所有股票只有一组k元语法的统计结果。
其中,步骤(4)的获得待预测股票的近期涨跌幅数据并量化,具体为获取待预测股票近4个交易日的涨跌幅数据,然后对这4日的涨跌幅数据进行量化,即对涨跌幅值进行四舍五入操作,形成整数值,记为D4,D3,D2,D1,分别代表股票近四个交易日的近似整数涨跌幅。而即将预测的下一交易日近似涨跌幅记为D0。
其中,步骤(5)的计算待预测股票的局部语法预测得分,;具体为:以D4,D3,D2,D1搜索匹配局部五元语法数组的前四个维度,获取条件概率最大的3个数值APercentk,及其对应的第五维的数值AD0k;以D3,D2,D1搜索匹配局部四元语法数组的前三个维度,获取条件概率最大的3个数值BPercentk,及其对应的第四维的数值BD0k;以D2,D1搜索匹配局部三元语法数组的前二个维度,获取条件概率最大的3个数值CPercentk,及其对应的第三维的数值CD0k;以D1搜索匹配局部二元语法数组的前一个维度,获取条件概率最大的3个数值DPercentk,及其对应的第二维的数值DD0k;最后对所有结果进行加权求和,作为局部语法的预测得分,具体公示为:
(A)
;
(B) 。
其中,步骤(6)的计算待预测股票的全局语法预测得分,具体为:以D4,D3,D2,D1搜索匹配全局五元语法数组的前四个维度,获取条件概率最大的3个数值APercentk,及其对应的第五维的数值AD0k;以D3,D2,D1搜索匹配全局四元语法数组的前三个维度,获取条件概率最大的3个数值BPercentk,及其对应的第四维的数值BD0k;以D2,D1搜索匹配全局三元语法数组的前二个维度,获取条件概率最大的3个数值CPercentk,及其对应的第三维的数值CD0k;以D1搜索匹配全局二元语法数组的前一个维度,获取条件概率最大的3个数值DPercentk,及其对应的第二维的数值DD0k;最后对所有结果进行加权求和,作为全局语法的预测得分,具体公示为:
(A)
;
(B)。
其中,步骤(7)的计算每只股票的综合得分并进行排序推荐,具体为:对于每只股票,计算股票的综合得分,具体公示为:
其中为权重系数,考虑股票自身的特点,这里取值。对所有股票的综合得分进行从大到小的排序,排序后取出前h个, 这些股票即为推荐的股票。推荐的周期为每日推荐,因此推荐的有效期仅为一天,只为下一交易日做股票推荐。推荐股票的所得综合得分可以作为该股票下一天近似涨幅的一种参考。
附图说明
图1 是本发明基于局部及全局语法统计的股票推荐方法的流程图。
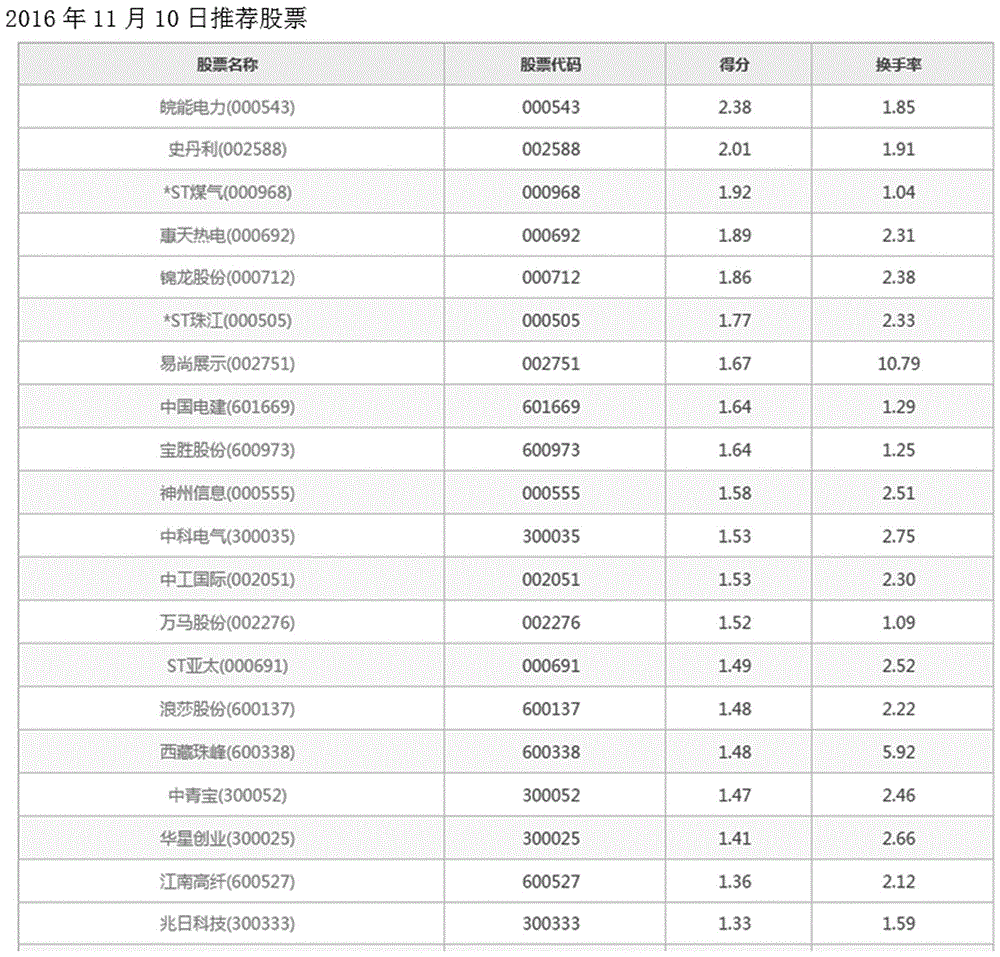
图2 是基于本发明方法输出的某一日期的推荐股票列表。具体为2016年11月10日推荐的股票,第三列的得分可以认为是对下一交易近似涨幅的预测,同时在第四列提供了当日股票的换手率作为参考。
具体实施方式
下面结合附图和实例,对本发明进行详细的描述。
n元语法((n-gram grammar)是建立在马尔可夫模型上的一种概率语法。它通过对自然语言的符号串中n个符号同时出现概率的统计数据来推断句子的结构关系。当n=2时,称为二元语法,二元文法(n=2时)被称作一阶马尔科夫链;当n = 3时,称为三元语法,三元文法模型称作二阶马尔科夫链。
本发明方法把股票小段时间序列的涨跌幅量化值看作是自然语言中的符号串,而对股票下一交易日涨跌幅度的预测类似于对符号串中的下一符号的预测。
本发明方法结合股票的实际,应用n元语法的思想,对股票自身的历史数据和全局的股票数据进行股票语法规则统计,而后分别利用局部语法和全局语法计算股票下一交易日的涨跌幅得分。最后对两种结果计算综合得分,排序后进行股票的推荐。本发明方法的推荐方式为每日推荐。
假设股票列表为S,S=[S1, S2,…,Si,…,Sm],m为股票池中股票的数量,如中国上市股票的数量或美国上市股票的数量。基于局部及全局语法统计的股票推荐过程具体如下。
一、对股票的涨跌幅值进行量化。
对于每只股票,获取某个时间点以来(如2005年1月1日)的涨跌幅数据,而后对涨跌幅值进行量化,即对涨跌幅值进行四舍五入的操作,变换为[-10,10]区间的整数值;最后股票池中的每只股票都变换为包含股票涨跌幅整数值的数组。
二、基于股票自身历史数据进行局部多元语法统计。
对于每只股票,假设当前股票为Si,i=1,…,m ,则该股票的多元语法统计过程如下。
2.1 局部一元语法统计。
由于股票有涨跌幅限制,量化后的整数值有21种情况,即[-10,10]区间的整数,因此设置一个有21槽的数组,遍历Si股票的涨跌幅整数值数组,根据涨跌幅整数值的出现次数进行累加统计,并放入对应的槽中。最后,每只股票有自己的一元语法统计数组。
2.2 局部二元语法统计。
设置一个21X21的二维数组,遍历Si股票涨跌幅整数值数组,每次取相邻的两个值,对这两个值的共同出现的次数进行累加统计,并放入二维数组对应的槽中。每只股票有自己的二元语法统计数组。
二元语法统计完后,结合一元语法的结果,计算条件概率。对于每只股票二元语法数组中的每一行,假设共同出现的两个整数值为AB,则后件B出现的条件概率P(B)=P(AB)/P(A), 即AB共同出现的次数占A单独出现次数的比例。A单独出现的次数已经在一元语法统计中得到。而AB共同出现的次数已在二元语法的统计中得到。如果前件A没出现过,则跳过条件概率的计算。
2.3 局部三元语法统计。
设置一个21X21 X21的三维数组,遍历Si股票涨跌幅整数值数组,每次取相邻的三个值,对这三个值的共同出现的次数进行累加统计,并放入三维数组对应的槽中。每只股票有自己的三元语法统计数组。
三元语法统计完后,结合二元语法的结果,计算条件概率。对于每只股票三元语法数组中的每一行,假设共同出现的三个整数值为ABC,则后件C出现的条件概率P(C)=P(ABC)/P(AB), 即ABC共同出现的次数占AB出现次数的比例。AB出现的次数已经在二元语法统计中得到。而ABC共同出现的次数已在三元语法的统计中得到。如果前件AB没出现过,则跳过条件概率的计算。
2.4 局部四元语法统计。
设置一个21X21 X21 X21的四维数组,遍历Si股票涨跌幅整数值数组,每次取相邻的四个值,对这四个值的共同出现的次数进行累加统计,并放入四维数组对应的槽中。每只股票有自己的四元语法统计数组。
四元语法统计完后,结合三元语法的结果,计算条件概率。对于每只股票四元语法数组中的每一行,假设共同出现的四个整数值为ABCD,则后件D出现的条件概率P(D)=P(ABCD)/P(ABC), 即ABCD共同出现的次数占ABC出现次数的比例。ABC出现的次数已经在三元语法统计中得到。而ABCD共同出现的次数已在四元语法的统计中得到。如果前件ABC没出现过,则跳过条件概率的计算。
2.5 局部五元语法统计。
设置一个21X21 X21 X21 X21的五维数组,遍历Si股票涨跌幅整数值数组,每次取相邻的五个值,对这五个值的共同出现的次数进行累加统计,并放入五维数组对应的槽中。每只股票有自己的五元语法统计数组。
五元语法统计完后,结合四元语法的结果,计算条件概率。对于每只股票五元语法数组中的每一行,假设共同出现的五个整数值为ABCDE,则后件E出现的条件概率P(E)=P(ABCDE)/P(ABCD), 即ABCDE共同出现的次数占ABCD出现次数的比例。ABCD出现的次数已经在四元语法统计中得到。而ABCDE共同出现的次数已在五元语法的统计中得到。如果前件ABCD没出现过,则跳过条件概率的计算。
三、基于所有股票历史数据进行全局多元语法统计。
对于所有股票,全局多元语法的统计过程如下。
3.1 全局一元语法统计。
设置一个有21槽的数组,遍历所有股票的涨跌幅整数值数组,根据涨跌幅整数值的出现次数进行累加统计,并放入对应的槽中。最后,形成一个全局的一元语法统计数组。
3.2 全局二元语法统计。
设置一个21X21的二维数组,遍历所有股票涨跌幅整数值数组,每次取相邻的两个值,对这两个值的共同出现的次数进行累加统计,并放入二维数组对应的槽中。最后,形成一个全局的二元语法统计数组。
二元语法统计完后,结合一元语法的结果,计算条件概率。对全局二元语法数组中的每一行,假设共同出现的两个整数值为AB,则后件B出现的条件概率P(B)=P(AB)/P(A), 即AB共同出现的次数占A单独出现次数的比例。A单独出现的次数已经在全局一元语法统计中得到。而AB共同出现的次数已在全局二元语法的统计中得到。如果前件A没出现过,则跳过条件概率的计算。
3.3 全局三元语法统计。
设置一个21X21 X21的三维数组,遍历所有股票涨跌幅整数值数组,每次取相邻的三个值,对这三个值的共同出现的次数进行累加统计,并放入三维数组对应的槽中。最后,形成一个全局的三元语法统计数组。
三元语法统计完后,结合二元语法的结果,计算条件概率。对全局三元语法数组中的每一行,假设共同出现的三个整数值为ABC,则后件C出现的条件概率P(C)=P(ABC)/P(AB), 即ABC共同出现的次数占AB出现次数的比例。AB出现的次数已经在全局二元语法统计中得到。而ABC共同出现的次数已在全局三元语法的统计中得到。如果前件AB没出现过,则跳过条件概率的计算。
3.4 全局四元语法统计。
设置一个21X21 X21 X21的四维数组,遍历所有股票涨跌幅整数值数组,每次取相邻的四个值,对这四个值的共同出现的次数进行累加统计,并放入四维数组对应的槽中。最后,形成一个全局的四元语法统计数组。
四元语法统计完后,结合三元语法的结果,计算条件概率。对全局四元语法数组中的每一行,假设共同出现的四个整数值为ABCD,则后件D出现的条件概率P(D)=P(ABCD)/P(ABC), 即ABCD共同出现的次数占ABC出现次数的比例。ABC出现的次数已经在全局三元语法统计中得到。而ABCD共同出现的次数已在全局四元语法的统计中得到。如果前件ABC没出现过,则跳过条件概率的计算。
3.5 全局五元语法统计。
设置一个21X21 X21 X21 X21的五维数组,遍历所有股票涨跌幅整数值数组,每次取相邻的五个值,对这五个值的共同出现的次数进行累加统计,并放入五维数组对应的槽中。最后,形成一个全局的五元语法统计数组。
五元语法统计完后,结合四元语法的结果,计算条件概率。对全局五元语法数组中的每一行,假设共同出现的五个整数值为ABCDE,则后件E出现的条件概率P(E)=P(ABCDE)/P(ABCD), 即ABCDE共同出现的次数占ABCD出现次数的比例。ABCD出现的次数已经在全局四元语法统计中得到。而ABCDE共同出现的次数已在全局五元语法的统计中得到。如果前件ABCD没出现过,则跳过条件概率的计算。
四、获得股票的近期涨跌幅数据并量化。
获取股票近4个交易日的涨跌幅数据,然后对这4日的涨跌幅数据进行量化,即对涨跌幅值进行四舍五入操作,形成整数值,记为D4,D3,D2,D1,分别代表股票近四个交易日的近似整数涨跌幅。而即将预测的下一交易日近似涨跌幅记为D0。
五、计算局部语法的预测得分。
对每只股票的近期量化涨跌幅,搜索股票自身的局部语法统计数组,并计算得分。具体过程如下。
5.1 以D4,D3,D2,D1搜索匹配局部五元语法数组的前四个维度,获取条件概率最大的3个数值APercentk,及其对应的第五维的数值AD0k,k=1,2,3。同时对该部分分配权重4。
5.2 以D3,D2,D1搜索匹配局部四元语法数组的前三个维度,获取条件概率最大的3个数值BPercentk,及其对应的第四维的数值BD0k,k=1,2,3。同时对该部分分配权重3。
5.3 以D2,D1搜索匹配局部三元语法数组的前二个维度,获取条件概率最大的3个数值CPercentk,及其对应的第三维的数值CD0k,k=1,2,3。同时对该部分分配权重2。
5.4 以D1搜索匹配局部二元语法数组的前一个维度,获取条件概率最大的3个数值DPercentk,及其对应的第二维的数值DD0k,k=1,2,3。同时对该部分分配权重1。
5.5 计算局部语法预测得分
(1)
;
(2) 。
计算过程中,如果分母部分的条件概率和为0,则跳过该部分分数的贡献分值。
六、计算全局语法的预测得分。
对每只股票的近期量化涨跌幅,搜索股票全局的语法统计数组,并计算得分。具体过程如下。
6.1 以D4,D3,D2,D1搜索匹配全局五元语法数组的前四个维度,获取条件概率最大的3个数值APercentk,及其对应的第五维的数值AD0k,k=1,2,3。同时对该部分分配权重4。
6.2以D3,D2,D1搜索匹配全局四元语法数组的前三个维度,获取条件概率最大的3个数值BPercentk,及其对应的第四维的数值BD0k,k=1,2,3。同时对该部分分配权重3。
6.3 以D2,D1搜索匹配全局三元语法数组的前二个维度,获取条件概率最大的3个数值CPercentk,及其对应的第三维的数值CD0k,k=1,2,3。同时对该部分分配权重2。
6.4 以D1搜索匹配全局二元语法数组的前一个维度,获取条件概率最大的3个数值DPercentk,及其对应的第二维的数值DD0k,k=1,2,3。同时对该部分分配权重1。
6.5 计算全局语法预测得分
(1)
;
(2)。
计算过程中,如果分母部分的条件概率和为0,则跳过该部分分数的贡献分值。
七、计算综合得分并进行排序推荐。
7.1 对于每只股票,计算股票的综合得分。具体为:
其中为权重系数,考虑股票自身的特点,这里取值。
7.2 对所有股票的综合得分进行从大到小的排序,排序后取出前h个, 这些股票即为推荐的股票。推荐的有效期仅为一天,只为下一交易日做股票推荐。推荐股票的所得综合得分可以作为该股票下一天近似涨幅的一种参考。
综上所述,本发明公开了一种基于局部及全局语法统计的股票推荐方法。方法对股票自身的历史数据和全局的股票数据进行股票语法规则统计,而后分别利用局部语法和全局语法计算股票下一交易日的可能涨跌幅得分。最后对两种结果计算综合得分。方法除了可用于股票的每日推荐外,还可用于股票每天的实时推荐。进行实时推荐时,仅需将所用的日线数据换成分钟线数据即可。
本发明方法同样可应用于证券类具有时间序列特征的数据,如基金、期货等。因此,尽管为说明目的公开了本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是不可能的。因此,本发明不应局限于最佳实施例和附图所公开的内容。当前公开的实施例在所有方面应被理解为说明性的而非对其请求保护的范围的限制。
- 还没有人留言评论。精彩留言会获得点赞!