一种基于图书内容的图书书后索引自动构建方法与流程
本发明涉及利用计算机人工智能、数据挖掘等方法进行书后索引词的生成,尤其涉及一种基于图书内容的图书书后索引自动构建方法。
背景技术:
书后索引泛指书后附件。是以书中某些词语为线索,指出与这些词语的描述对象有关的内容位于本书的什么位置。一般宏篇巨著,特别是学术著作,内容博大精深,往往在正文后附有索引,供读者检索。
书后索引在西方长期以来受到广泛的重视,西方读者习惯于使用书索引来检索自己所需的内容。有的国家对书后索引做出明确的规定,如果一部学术著作不附索引,就不允许出版。书后索引编制的好坏,通常作为评判图书质量的重要指标之一,书后索引也是国际学术著作通行的惯例,是图书结构规范化和标准化的要求,在学术著作、大型书稿中通常都要求在书后附有索引。由此可看出,西方出版机构比较重视书后索引,绝大多数的著作都附有书后索引,普及率很高,并且种类不一而全,质量较高。但在我国,现代编辑出版不重视书后索引,甚至常常将译书中已有的书后索引删节,这些看似节省效率的短视行为,产生原因是多方面的,但其中不可忽略的一个方面的原因在于对书后索引的信息检索功能认识不够。
在当今的信息时代,由于受时间和信息量的限制,读者常常不可能把他要了解的书完全通读。书后索引除了可以帮助读者快速查找专有名词、提名,掌握该书专业名词分布的章节、页码外,同时也是解答学科术语、专有名词等问题的重要参考资料。书后索引的检索功能就是对文献深层开发,是实现信息增值的重要途径。书后索引将书中所论述各方面具有信息价值的内容作为一个单位;然后读者可以查找该内容线索的短语,再以该短语为线索,指出与该短语描述对象有关的信息及其所在位置。在阅读前,读者可以根据书后索引所提供的指示,自由选择书中自己所需信息。阅读后人们可借助书后索引的指引,重新回味曾一度阅读过的知识,或寻找某些信息在文中的特定位置,或重新定位文中读者所需的特定信息。
技术实现要素:
本发明的目的是为克服现有技术的不足,提供一种基于图书章节文本内容的书后索引词的构建方法。
本发明的目的是通过以下技术方案来实现的:一种基于图书内容的图书书后索引自动构建方法,包括以下步骤:
1)选择一本书,将图书的正文作为待查找的字符串,去匹配从科学技术术语中得到的高频词性规则,所有匹配成功的子串就作为候选短语;
2)对于每一个候选短语,计算其互信息、信息熵、候选短语间包含关系、标点位置、长度、词库状态、语法依赖关系、短语组合模式、语义相似度、短语内链、语法树连通分量数等特征值;
3)采用支持向量机算法,根据候选短语的特征值来进行分类训练,得到短语分类模型及模型准确率;
4)进行特征选择,再用选择后的特征来训练模型并进行短语分类,得到候选索引词列表;
5)采用随机森林算法,根据候选索引词的表征向量以及由图书标题和图书中图分类名得到的专业领域表征向量,得到一个候选索引词的术语度;
6)根据候选索引词的信息量、词频、点互信息和百科关键值来得到一个候选词的索引度;
7)根据候选索引词的标题偏移距离、候选索引词比例和兴趣度来得到一个候选词的上下文权值;
8)结合候选索引词的术语度、索引度以及上下文权值来计算一个候选索引词的索引分数;
9)根据候选索引词的索引分数以及在书中的分布来进行排序,从而使得索引词分布更加均匀,实现索引词的生成。
进一步地,所述的步骤1)具体为:
对科学技术术语利用自然语言处理工具LTP-Cloud去切词并标注词性,切分后每一个字词记为W[i],对应的词性描述符为N[i],N就是该科学技术术语所对应的词性规则。通过对科学技术术语的词性规则进行统计,得到频率最高的10个词性规则,作为高频词性规则组。
对图书正文利用自然语言处理工具LTP-Cloud去切词并标注词性,切分后每一个字词记为TextW[i],对应的词性描述符为TextN[i];TextN词性数组作为目标,用高频词性规则组里的词性规则作为模式,TextN中所有匹配成功的词性子串,其对应的字词子串作为候选短语。
进一步地,所述的步骤2)中,对于每一个候选短语W,考虑以下特征:
2.1)互信息MI(W)公式如下:
一个候选短语W经过分词后,得到子字符串数组,数组长度为N。若N为1,则互信息值为1;若N大于1,则取其中一个切分点为基准,左侧组成左子字符串WL,右侧组成右子字符串WR,W为N-Gram。若W一共出现了j次,而N阶短语一共有k个,则上式的P(W)=j/k。同理可以求出P(WL)和P(WR)。若切分点有多个,则取MI(W)最大的值作为互信息值,并进行归一化。互信息值越高,表明WL和WR相关性越高,则WL和WR组成短语的可能性越大;反之,互信息值越低,WL和WR之间相关性越低,则WL和WR之间存在短语边界的可能性越大。
2.2)左右信息熵
左信息熵EL(W)公式如下:
其中A是W的左相邻词语的集合,a是A中的一个词语。P(aW|W)是在候选短语W出现的条件下,aW短语出现的概率。该值越高,表示a与W之间接续关系越不确定,a不应该和W组成短语,W本身更具有独立性。
右信息熵ER(W)公式如下:
其中B是W的右相邻词语的集合,b是B中的一个词语。P(Wb|W)是在候选短语W出现的条件下,Wb短语出现的概率。该值越高,表示W与b之间接续关系越不确定,b不应该和W组成短语,W本身更具有独立性。
2.3)内信息熵
对当前候选短语W从分词点进行分割,得到左右两个子串WL和WR,其中WL是WR的左邻接词,WR是WL的右邻接词,WL+WR=W。
依据2.2)的公式,计算WL的右信息熵E1和WR的左信息熵E2。E1、E2中的较小值作为内熵Ein(W)。如果当前候选短语W有多个切分左子串和右子串的方式,则取所有分词情况下计算得到的内熵最小值作为当前短语的内信息熵。
候选短语W的内熵越高,表明W的左右子串越离散,组合成短语的可能性越小,越不可能成为短语。
2.4)候选短语间包含关系
在图书正文中,统计所有抽取的候选短语之间的包含关系。若候选短语W1是候选短语W2的子字符串,则W2包含W1。
2.5)标点位置
候选短语是否直接出现在标点符号之前或之后。
2.6)语义相似度
利用中文分词工具对候选短语进行分析,使用Word2Vec工具将短语中的左子串WL和右子串WR转换为向量,再计算向量之间的余弦距离,作为短语内部的相似度。如果有多个切分左子串和右子串的方式,则取所有分词情况下计算得到的相似度最大值作为语义相似度。
2.7)长度
候选短语的汉字字数。
2.8)词库状态
词库里的词条来自于百度百科收录的标题。相关特征如下:
2.8.1)候选短语是否在词库中出现;
2.8.2)该候选短语通过中文分词工具得到的字词,有几个在词库中出现过;
2.8.3)在词库中,有多少个词包含当前的候选短语。
2.9)短语内链
候选短语在其百度百科的页面里,所包含的超链接的个数。
2.10)语法树连通分量数
图书内容文本中的一个句子经过自然语言工具LTP-Cloud处理后,得到一棵语法树。候选短语在语法树里都是由一个或多个字词节点组成的图。图的连通分量数即为该候选短语的语法树连通分量数。
2.11)语法依赖关系
在特征2.10)中得到了候选短语在语法树中对应的图,图中的一个点用来表达一个字词,图的一条边用来表达两个字词之间的依赖关系。
如果图的连通分量数为1且根节点只有1个子节点,则选取根节点与子节点的依赖关系作为特征;
如果图的连通分量数为1且根节点的子节点的个数大于1,则选取最后1个子节点的依赖关系作为特征;
如果图的连通分量数为1且根节点没有子节点,则依赖关系为单一;
如果图的连通分量数大于1,则依赖关系为其他。
2.12)短语组合模式
候选短语经过中分文词工具分词后,得到的词组长度为N,则该候选短语为N-Gram。在特征2.10)中得到了候选短语的在语法树中对应的图,对于图中的字词节点,用英文大写字母按照文本顺序进行标记。N=2时的短语组合模式用集合{A,B}来表达;N=3时的短语组合模式用集合{A,B,C}来表达,依次类推。相邻的字母,左边字母是右边字母的父节点。不相邻的字母没有依赖关系。
进一步地,所述的步骤3)具体为:
用步骤2)中得到的候选短语的特征值来表达该候选短语,并将一部分数据进行人工标注,标注这些候选短语为短语类和非短语类,再取一部分标注数据作为训练集,剩下的标注数据作为测试集。
用支持向量机训练算法将人工标注的训练集进行训练得到一个模型,使其成为非概率二元线性分类模型,并用测试集来进行验证。
将测试集里的短语的特征作为支持向量机训练的模型的输入,将模型输出的分类结果和测试集里人工标注的结果进行对比,如果标注相同则为正确,标注不同则为错误,统计正确标注所占的比例得到该模型的准确率。
进一步地,所述的步骤4)中,特征选择采用序列后向选择算法,步骤2)得到的所有特征组成特征全集O。具体步骤如下:
(4.1)计算每个候选短语在特征集合O里的所有特征值,并用这些特征值作为输入,进行模型训练,得到模型准确率A,将A作为模型基准。
(4.2)特征集合O的集合大小记为n。从特征集合O中去掉一个特征xi得到子集Oi,i∈[1,n],共得到n个子集。
(4.3)进行n次训练。得到每个子集Oi对应的模型准确率Ai。
(4.4)从A1到An中找出最大值Am,m∈[1,n]。若Am≥A,则将A赋值为Am并作为新的模型基准,对应的特征集合Om作为新的特征集合O,返回步骤(4.2);若Am<A,则结束特征选择过程,保留下来的特征集合O记为特征集合S。
计算每个候选短语在特征集合S里的所有特征值,用这些特征值作为支持向量机训练的模型的输入,根据模型输出的分类结果,将短语类里的短语作为候选索引词。
进一步地,所述的步骤5)具体为:
全国科学技术名词库中,包含术语词条和术语分类名。术语词条作为短语,术语分类信息作为专业领域。利用随机森林算法得到术语度计算模型。步骤如下:
(1)先用中文分词工具对术语词条以及术语分类名进行分词,分别得到词组R和词组S,以及短语的词性规则信息N;
(2)用Word2Vec工具,分别将词组R、S中的词转换为向量数组RS和SS;
(3)步骤(2)中的向量数组RS的向量均值作为短语的表征向量RSV,向量数组SS的向量均值作为专业领域的表征向量SSV。
(4)如果短语的词性规则N属于高频词性规则组,则该短语为正例;反之则为负例,另外人工标注部分非术语短语作为负例。步骤(3)中得到的短语表征向量和专业领域表征向量作为特征,以上得到的正例和负例构成术语度训练集。
(5)用随机森林算法将步骤(4)得到的训练集进行训练得到术语度计算模型。
通过以上步骤,得到了术语度计算模型。模型的两个输出分别为该短语属于正例的概率P1、属于负例的概率P2。P1即为该短语的术语度。
用图书的标题及图书的中图分类名称共同来表达这本书的专业领域。利用候选索引词和专业领域来计算该候选索引词的术语度,计算步骤如下:
(1)先用中文分词工具对候选索引词以及图书的标题、图书的中图分类名进行分词,分别得到词组E和词组T、词组C;
(2)用Word2Vec工具,分别将词组E、T、C中的词转换为向量数组EVS、TVS、CVS;
(3)向量数组EVS的向量均值作为候选索引词的表征向量EV;向量数组TVS和CVS的向量均值作为专业领域的表征向量RV。
(4)将步骤(3)中得到的向量EV和RV作为输入,用训练得到的术语度计算模型来计算候选索引词的术语度。
进一步地,所述的步骤6)具体为:
索引度是用来衡量一个候选索引词是否适合作为一个索引词。评分考虑四个因素:信息量、词频、点互信息和百科关键值。
6.1)信息量衡量一个候选索引词所含信息的多少,信息量I(t,C)计算公式如下:
其中,t为候选索引词,C为t对应的上下文,用C从百度百科查询得到k个上下文,记为Ci,i∈[1,k],sim(C,Ci)是计算C和Ci的余弦距离作为相似度。p是Ci对t的优先级,p(Ci)=log(k-i+1)。
6.2)词频是一个候选索引词在一本图书正文中出现的次数s与该图书正文中总词数n的比值,词频TF(t)公式如下:
TF(t)=s/n
6.3)点互信息PMI(t)计算公式如下:
其中,t=x1x2x3..xn为一个候选索引词经过自然语言工具分词处理之后得到的词组;p(x1..xn)表示x1..xn同时出现的概率,p(x1)表示出现x1的概率,p(x2..xn)表示x2..xn同时出现的概率。
6.4)百科关键值考虑一个候选索引词在百科中是否作为标题或作为内链。对于任意一个候选索引词t,其百科关键值PK(t)计算公式如下:
PK(t)=count(B acklinks(t))/totalhits(t)
其中,Backlinks(t)是候选索引词t的反向链接,count(Backlinks(t))是候选索引词t的反向链接数,totalhits(t)是候选索引词t在百科数据中的查询结果数。
该候选索引词的索引度Indexability(t)的公式如下:
Indexability(t)=I(t,C)+TF(t)+PMI(t)+PK(t)
其中I(t,C)是候选索引词t的信息量,TF(t)是候选索引词t的词频,PMI(t)是候选索引词t的点互信息,PK(t)是候选索引词t的百科关键值。
进一步地,所述的步骤7)具体为:
上下文权值考虑一个候选索引词在书中上下文情境下的权值。权值考虑标题偏移距离、候选索引词比例以及该候选索引词的兴趣度。
7.1)标题偏移距离offset(t)是候选索引词在章节中所处的段落的位置信息。对于候选索引词t,所在章节共有n个段落,候选索引词t所在的段落为第k段,则标题偏移距离计算公式如下:
offset(t)=k/n
7.2)候选索引词比例R(t)是在一个章节中,候选索引词t的个数s与所有候选索引词个数m的比值,计算公式如下:
R(t)=s/m
7.3)兴趣度rD(t,d)是用来描述候选索引词吸引用户的能力。对于图书章节d里的一个候选索引词t,其兴趣度计算公式如下:
其中n(t,d)是候选索引词t在章节d中的词频,Pd是章节d中的所有候选索引词,n(p,d)是候选索引词p在章节d中的词频,D是当前这本书所有章节构成的集合,n(t,D)是候选索引词t在章节集合D里的词频。
7.4)候选索引词的上下文权重ContextWeight(t)公式如下:
ContextWeight(t)=λ1×offset(t)+λ2×R(t)+λ3×rD(t,d)
其中λ1=0.3,λ2=0.2,λ3=0.5是权重参数。
进一步地,所述的步骤8)中,候选索引词的索引分数Score(t)计算公式为:Score(t)=termi(t)×Indexability(t)×ContextWeight(t)
其中termi(t)是候选索引词t的术语度,Indexability(t)是候选索引词t的索引度,ContextWeight(t)是候选索引词t的上下文权值。
进一步地,所述的步骤9)中,从候选索引词中获得索引词的步骤如下:
输入:一本图书B的所有候选索引词cands及索引分数;
输出:这本书的索引词列表E,列表大小s;
步骤(1):初始化临时索引词列表F;
步骤(2):将候选索引词全部放入临时索引词列表F中;
步骤(3):将列表F中选取索引分数最高的s个候选索引词从F中移除,并放入索引词列表E中;
步骤(4):按照候选索引词在书中的先后顺序来遍历E中的候选索引词。如果存在两个相邻的候选索引词itj-1和itj,他们所在的章节的序数差大于40,则进行步骤(5);否则进行遍历,直到遍历结束,再进行步骤(9);
步骤(5):如果F中存在候选索引词it,it所在章节在itj-1和itj所在的章节之间(含itj-1和itj所在的章节),则将所有的it组成候选索引词集合S1,并进行步骤(6);否则进行步骤(4);
步骤(6):将S1中的候选索引词中分数最高的一个候选索引词从F移除,并添加到E中;
步骤(7):E中的候选索引词按出现的先后顺序排序。若E中存在三个连续的候选索引词itk-1、itk和itk+1,满足itk-1和itk+1所在的章节的序数差不大于40,则将所有满足条件的itk组成候选索引词集合S2;
步骤(8):将S2中的候选索引词中分数最低的一个候选索引词从E移除;进行步骤(4);
步骤(9):得到索引词列表E。
本发明与现有技术相比具有的有益效果:
1.该方法的流程保证可以依靠机器自动完成,无需人工干预;
2.该方法在短语抽取过程中加强了特征表达,在传统的互信息和信息熵这两个特征上,一方面深化了信息熵的应用方式,另一方面又加入了语法语义特征,提高了短语抽取效果;
3.该方法在索引抽取过程中,和传统的评分方法相比增加了术语度,在上下文权值计算中又利用了兴趣度,使得索引词的评分更加合理、准确;
4.该方法结合了短语识别方法和图书索引选择方法,得到了图书书后索引词,提高了读者的阅读质量。
附图说明
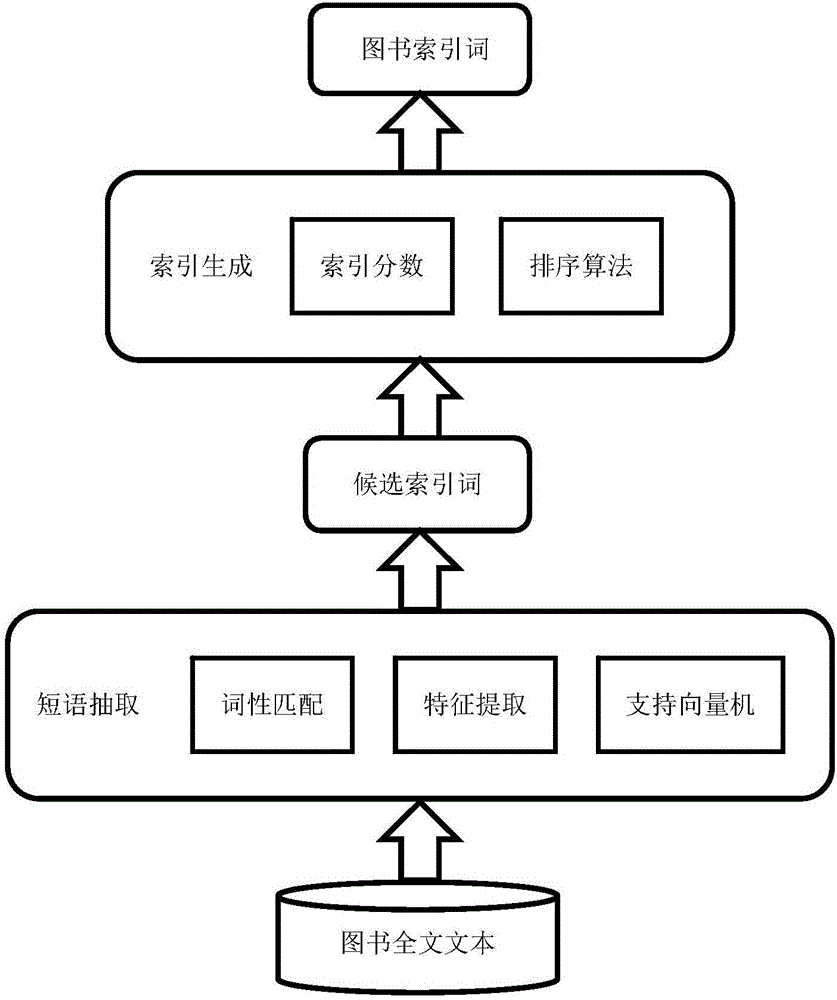
图1为本发明的总流程图;
图2为获取候选索引词的流程图;
图3为生成索引词的流程图;
图4为《实用电源技术手册:UPS电源分册》的索引词生成结果。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1所示,本发明提供的一种基于图书内容的图书书后索引自动构建方法,该方法包括以下步骤:
1)选择一本书,将图书的正文作为待查找的字符串,去匹配从科学技术术语中得到的高频词性规则,所有匹配成功的子串就作为候选短语;
2)对于每一个候选短语,计算其互信息、信息熵、候选短语间包含关系、标点位置、长度、词库状态、语法依赖关系、短语组合模式、语义相似度、短语内链、语法树连通分量数等特征值;
3)采用支持向量机算法,根据候选短语的特征值来进行分类训练,得到短语分类模型及模型准确率;
4)进行特征选择,再用选择后的特征来训练模型并进行短语分类,得到候选索引词列表;
5)采用随机森林算法,根据候选索引词的表征向量以及由图书标题和图书中图分类名得到的专业领域表征向量,得到一个候选索引词的术语度;
6)根据候选索引词的信息量、词频、点互信息和百科关键值来得到一个候选词的索引度;
7)根据候选索引词的标题偏移距离、候选索引词比例和兴趣度来得到一个候选词的上下文权值;
8)结合候选索引词的术语度、索引度以及上下文权值来计算一个候选索引词的索引分数;
9)根据候选索引词的索引分数以及在书中的分布来进行排序,从而使得索引词分布更加均匀,实现索引词的生成。
进一步地,所述的步骤1)具体为:
对科学技术术语利用自然语言处理工具LTP-Cloud去切词并标注词性,切分后每一个字词记为W[i],对应的词性描述符为N[i],N就是该科学技术术语所对应的词性规则。通过对科学技术术语的词性规则进行统计,得到频率最高的10个词性规则,作为高频词性规则组。
对图书正文利用自然语言处理工具LTP-Cloud去切词并标注词性,切分后每一个字词记为TextW[i],对应的词性描述符为TextN[i];TextN词性数组作为目标,用高频词性规则组里的词性规则作为模式,TextN中所有匹配成功的词性子串,其对应的字词子串作为候选短语。
进一步地,所述的步骤2)中,对于每一个候选短语W,考虑以下特征:
2.1)互信息MI(W)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。公式如下:
一个候选短语W经过分词后,得到子字符串数组,数组长度为N。若N为1,则互信息值为1;若N大于1,则取其中一个切分点为基准,左侧组成左子字符串WL,右侧组成右子字符串WR,W为N-Gram。若W一共出现了j次,而N阶短语一共有k个,则上式的P(W)=j/k。同理可以求出P(WL)和P(WR)。若切分点有多个,则取MI(W)最大的值作为互信息值,并进行归一化。互信息值越高,表明WL和WR相关性越高,则WL和WR组成短语的可能性越大;反之,互信息值越低,WL和WR之间相关性越低,则WL和WR之间存在短语边界的可能性越大。
2.2)左右信息熵
左信息熵EL(W)公式如下:
其中A是W的左相邻词语的集合,a是A中的一个词语。P(aW|W)是在候选短语W出现的条件下,aW短语出现的概率。该值越高,表示a与W之间接续关系越不确定,a不应该和W组成短语,W本身更具有独立性。
右信息熵ER(W)公式如下:
其中B是W的右相邻词语的集合,b是B中的一个词语。P(Wb|W)是在候选短语W出现的条件下,Wb短语出现的概率。该值越高,表示W与b之间接续关系越不确定,b不应该和W组成短语,W本身更具有独立性。
2.3)内信息熵
对当前候选短语W从分词点进行分割,得到左右两个子串WL和WR,其中WL是WR的左邻接词,WR是WL的右邻接词,WL+WR=W。
依据2.2)的公式,计算WL的右信息熵E1和WR的左信息熵E2。E1、E2中的较小值作为内熵Ein(W)。如果当前候选短语W有多个切分左子串和右子串的方式,则取所有分词情况下计算得到的内熵最小值作为当前短语的内信息熵。
候选短语W的内熵越高,表明W的左右子串越离散,组合成短语的可能性越小,越不可能成为短语。
2.4)候选短语间包含关系
在图书正文中,统计所有抽取的候选短语之间的包含关系。若候选短语W1是候选短语W2的子字符串,则W2包含W1。
2.5)标点位置
候选短语是否直接出现在标点符号之前或之后。
2.6)语义相似度
利用中文分词工具对候选短语进行分析,使用Word2Vec工具将短语中的左子串WL和右子串WR转换为向量,再计算向量之间的余弦距离,作为短语内部的相似度。如果有多个切分左子串和右子串的方式,则取所有分词情况下计算得到的相似度最大值作为语义相似度。
2.7)长度
候选短语的汉字字数。
2.8)词库状态
词库里的词条来自于百度百科收录的标题。相关特征如下:
2.8.1)候选短语是否在词库中出现;
2.8.2)该候选短语通过中文分词工具得到的字词,有几个在词库中出现过;
2.8.3)在词库中,有多少个词包含当前的候选短语。
2.9)短语内链
候选短语在其百度百科的页面里,所包含的超链接的个数。
2.10)语法树连通分量数
图书内容文本中的一个句子经过自然语言工具LTP-Cloud处理后,得到一棵语法树。候选短语在语法树里都是由一个或多个字词节点组成的图。图的连通分量数即为该候选短语的语法树连通分量数。
2.11)语法依赖关系
在特征2.10)中得到了候选短语在语法树中对应的图,图中的一个点用来表达一个字词,图的一条边用来表达两个字词之间的依赖关系。
如果图的连通分量数为1且根节点只有1个子节点,则选取根节点与子节点的依赖关系作为特征;
如果图的连通分量数为1且根节点的子节点的个数大于1,则选取最后1个子节点的依赖关系作为特征;
如果图的连通分量数为1且根节点没有子节点,则依赖关系为单一;
如果图的连通分量数大于1,则依赖关系为其他。
2.12)短语组合模式
候选短语经过中分文词工具分词后,得到的词组长度为N(N≤26),则该候选短语为N-Gram。在特征2.10)中得到了候选短语的在语法树中对应的图,对于图中的字词节点,用英文大写字母按照文本顺序进行标记。N=2时的短语组合模式用集合{A,B}来表达;N=3时的短语组合模式用集合{A,B,C}来表达,依次类推。相邻的字母,左边字母是右边字母的父节点。不相邻的字母没有依赖关系。
短语组合模式仅考虑2-Gram和3-Gram,共有19种模式:A_B,AB,BA,A_B_C,A_BC,A_CB,B_AC,B_CA,C_AB,C_BA,ABC,ACB,BAC,BCA,CAB,CBA,AB_AC,BA_BC,CA_CB。
进一步地,所述的步骤3)具体为:
用步骤2)中得到的候选短语的特征值来表达该候选短语,并将一部分数据进行人工标注,标注这些候选短语为短语类和非短语类,再取一部分标注数据作为训练集,剩下的标注数据作为测试集。
用支持向量机训练算法将人工标注的训练集进行训练得到一个模型,使其成为非概率二元线性分类模型,并用测试集来进行验证。
将测试集里的短语的特征作为支持向量机训练的模型的输入,将模型输出的分类结果和测试集里人工标注的结果进行对比,如果标注相同则为正确,标注不同则为错误,统计正确标注所占的比例得到该模型的准确率。
进一步地,所述的步骤4)具体为:
在步骤2)中得到了候选短语的特征值,步骤3)中得到了训练的模型和模型准确率。由于特征数量较多,需要经过特征选择剔除不相关或冗余的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。
特征选择采用序列后向选择算法,步骤2)得到的所有特征组成特征全集O。具体步骤如下:
(4.1)计算每个候选短语在特征集合O里的所有特征值,并用这些特征值作为输入,进行模型训练,得到模型准确率A,将A作为模型基准。
(4.2)特征集合O的集合大小记为n。从特征集合O中去掉一个特征xi得到子集Oi,i∈[1,n],共得到n个子集。
(4.3)进行n次训练。得到每个子集Oi对应的模型准确率Ai。
(4.4)从A1到An中找出最大值Am,m∈[1,n]。若Am≥A,则将A赋值为Am并作为新的模型基准,对应的特征集合Om作为新的特征集合O,返回步骤(4.2);若Am<A,则结束特征选择过程,保留下来的特征集合O记为特征集合S。
计算每个候选短语在特征集合S里的所有特征值,用这些特征值作为支持向量机训练的模型的输入,根据模型输出的分类结果,将短语类里的短语作为候选索引词。
进一步地,所述的步骤5)具体为:
全国科学技术名词库中,包含术语词条和术语分类名。术语词条作为短语,术语分类信息作为专业领域。利用随机森林算法得到术语度计算模型。步骤如下:
(1)先用中文分词工具对术语词条以及术语分类名进行分词,分别得到词组R和词组S,以及短语的词性规则信息N;
(2)用Word2Vec工具,分别将词组R、S中的词转换为向量数组RS和SS;
(3)步骤(2)中的向量数组RS的向量均值作为短语的表征向量RSV,向量数组SS的向量均值作为专业领域的表征向量SSV。
(4)如果短语的词性规则N属于高频词性规则组,则该短语为正例;反之则为负例,另外人工标注部分非术语短语作为负例。步骤(3)中得到的短语表征向量和专业领域表征向量作为特征,以上得到的正例和负例构成术语度训练集。
(5)用随机森林算法将步骤(4)得到的训练集进行训练得到术语度计算模型。
通过以上步骤,得到了术语度计算模型。模型的两个输出分别为该短语属于正例的概率P1、属于负例的概率P2。P1即为该短语的术语度。
用图书的标题及图书的中图分类名称共同来表达这本书的专业领域。利用候选索引词和专业领域来计算该候选索引词的术语度,计算步骤如下:
(1)先用中文分词工具对候选索引词以及图书的标题、图书的中图分类名进行分词,分别得到词组E和词组T、词组C;
(2)用Word2Vec工具,分别将词组E、T、C中的词转换为向量数组EVS、TVS、CVS;
(3)向量数组EVS的向量均值作为候选索引词的表征向量EV;向量数组TVS和CVS的向量均值作为专业领域的表征向量RV。
(4)将步骤(3)中得到的向量EV和RV作为输入,用训练得到的术语度计算模型来计算候选索引词的术语度。
进一步地,所述的步骤6)具体为:
索引度是用来衡量一个候选索引词是否适合作为一个索引词。评分考虑四个因素:信息量、词频、点互信息和百科关键值。
6.1)信息量衡量一个候选索引词所含信息的多少,信息量I(t,C)计算公式如下:
其中,t为候选索引词,C为t对应的上下文,用C从百度百科查询得到k个上下文,记为Ci,i∈[1,k],sim(C,Ci)是计算C和Ci的余弦距离作为相似度。p是Ci对t的优先级,p(Ci)=log(k-i+1)。
6.2)词频是一个候选索引词在一本图书正文中出现的次数s与该图书正文中总词数n的比值,词频TF(t)公式如下:
TF(t)=s/n
6.3)点互信息是用于计算候选索引词间的语义相似度,基本思想是统计两个候选索引词在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。
点互信息PMI(t)计算公式如下:
其中,t=x1x2x3..xn为一个候选索引词经过自然语言工具分词处理之后得到的词组;p(x1..xn)表示x1..xn同时出现的概率,p(x1)表示出现x1的概率,p(x2..xn)表示x2..xn同时出现的概率。
6.4)百科关键值考虑一个候选索引词在百科中是否作为标题或作为内链。对于任意一个候选索引词t,其百科关键值PK(t)计算公式如下:
PK(t)=count(Backlinks(t))/totalhits(t)
其中,Backlinks(t)是候选索引词t的反向链接,count(Backlinks(t))是候选索引词t的反向链接数,totalhits(t)是候选索引词t在百科数据中的查询结果数。
该候选索引词的索引度Indexability(t)的公式如下:
Indexability(t)=I(t,C)+TF(t)+PMI(t)+PK(t)
其中I(t,C)是候选索引词t的信息量,TF(t)是候选索引词t的词频,PMI(t)是候选索引词t的点互信息,PK(t)是候选索引词t的百科关键值。
进一步地,所述的步骤7)具体为:
上下文权值考虑一个候选索引词在书中上下文情境下的权值。权值考虑标题偏移距离、候选索引词比例以及该候选索引词的兴趣度。
7.1)标题偏移距离offset(t)是候选索引词在章节中所处的段落的位置信息。对于候选索引词t,所在章节共有n个段落,候选索引词t所在的段落为第k段,则标题偏移距离计算公式如下:
offset(t)=k/n
7.2)候选索引词比例R(t)是在一个章节中,候选索引词t的个数s与所有候选索引词个数m的比值,计算公式如下:
R(t)=s/m
7.3)兴趣度rD(t,d)是用来描述候选索引词吸引用户的能力。对于图书章节d里的一个候选索引词t,其兴趣度计算公式如下:
其中n(t,d)是候选索引词t在章节d中的词频,Pd是章节d中的所有候选索引词,n(p,d)是候选索引词p在章节d中的词频,D是当前这本书所有章节构成的集合,n(t,D)是候选索引词t在章节集合D里的词频。一个候选索引词在某个文档中出现频率很高,而在其他文档中出现次数较少,那么这个候选索引词的兴趣度就越高。
7.4)通过以上步骤,得到一个候选索引词的相对标题偏移量、索引词选词比例以及兴趣度。该候选索引词的上下文权重ContextWeight(t)公式如下:
ContextWeight(t)=λ1×offset(t)+λ2×R(t)+λ3×rD(t,d)
其中λ1=0.3,λ2=0.2,λ3=0.5是权重参数。
进一步地,所述的步骤8)具体为:
在步骤4)中从一本图书中得到了候选索引词。在步骤5)中可以得到一个候选索引词的术语度,在步骤6)中可以得到一个候选索引词的索引度,在步骤7)中可以得到一个候选索引词的上下文权值。该候选索引词的索引分数Score(t)计算公式为:
Score(t)=termi(t)×Indexability(t)×ContextWeight(t)
其中termi(t)是候选索引词t的术语度,Indexability(t)是候选索引词t的索引度,ContextWeight(t)是候选索引词t的上下文权值。
进一步地,所述的步骤9)具体为:
在步骤8)中从一本图书中得到了的所有候选索引词的索引分数。从候选索引词中获得索引词的步骤如下:
输入:一本图书B的所有候选索引词cands及索引分数;
输出:这本书的索引词列表E,列表大小s;
步骤(1):初始化临时索引词列表F;
步骤(2):将候选索引词全部放入临时索引词列表F中;
步骤(3):将列表F中选取索引分数最高的s个候选索引词从F中移除,并放入索引词列表E中;
步骤(4):按照候选索引词在书中的先后顺序来遍历E中的候选索引词。如果存在两个相邻的候选索引词itj-1和itj,他们所在的章节的序数差大于40,则进行步骤(5);否则进行遍历,直到遍历结束,再进行步骤(9);
步骤(5):如果F中存在候选索引词it,it所在章节在itj-1和itj所在的章节之间(含itj-1和itj所在的章节),则将所有的it组成候选索引词集合S1,并进行步骤(6);否则进行步骤(4);
步骤(6):将S1中的候选索引词中分数最高的一个候选索引词从F移除,并添加到E中;
步骤(7):E中的候选索引词按出现的先后顺序排序。若E中存在三个连续的候选索引词itk-1、itk和itk+1,满足itk-1和itk+1所在的章节的序数差不大于40,则将所有满足条件的itk组成候选索引词集合S2;
步骤(8):将S2中的候选索引词中分数最低的一个候选索引词从E移除;进行步骤(4);
步骤(9):得到索引词列表E。
实施例
如附图1所示,给出了图书索引词生成方法的实施总流程。以生成图书《实用电源技术手册:UPS电源分册》的索引词列表为例,下面结合本发明方法和附图详细说明该实例实施的具体步骤,如下:
(1)如附图2所示,图书《实用电源技术手册:UPS电源分册》的全文文本通过词性匹配得到候选短语;
(2)如附图2所示,根据候选短语的特征值,通过支持向量机算法得到候选索引词;
(3)如附图3所示,根据候选索引词以及图书标题《实用电源技术手册:UPS电源分册》和中图分类名“工业技术”,得到候选索引词的术语度;
(4)如附图3所示,根据候选索引词的信息量、词频、点互信息和百科关键值来得到一个候选词的索引度;
(5)如附图3所示,根据候选索引词的标题偏移距离、候选索引词比例和兴趣度来得到一个候选词的上下文权值;
(6)如附图3所示,结合候选索引词的术语度、索引度以及上下文权值来计算一个候选索引词的索引分数;
(7)如附图3所示,根据候选索引词的分数以及在图书《实用电源技术手册:UPS电源分册》中的分布来进行排序,生成索引词列表。
本实例的运行结果在附图4中显示,为图书《实用电源技术手册:UPS电源分册》生成了一份索引词列表。这种图书书后索引生成方法有良好的使用价值和应用前景。
- 还没有人留言评论。精彩留言会获得点赞!