一种基于排列融合的图像检索重排序方法及系统与流程
本发明涉及技术图像检索重排序领域,尤其涉及一种基于排列融合的图像检索重排序方法及系统。
背景技术:
:图像检索重排序是图像检索领域研究的前沿问题。该技术试图在基于文本的图像检索结果的基础上,利用返回检索图像的视觉信息进行重排序,提高图像检索性能。图像检索重排序能够同时对检索系统产生积极的影响。该技术可以高效地结合基于文本的图像检索和基于内容的图像检索的优点:先利用基于文本的检索快速从海量数据库中返回初始查询结果,然后对初始查询结果中排序靠前的一部分图像精细分析其内容,对这些图像进行重排序,以改善图像检索的结果。从用户的角度讲,图像检索重排序技术可以提升用户体验;对检索系统来说,图像检索重排序可以有效改善图像检索性能。图像重排序方法一般基于两个假设:(1)返回的初始文本查询结果中排序靠前的图像大部分都是跟查询相关的;(2)与查询相关的图像之间的相似性比较高。大部分图像重排序的方法都是从这两个假设出发,设计重排序模型。此外,由于重排序是通过挖掘图像的视觉模式来对图像初始查询结果进行改善,因此图像重排序中的两个重要环境是图像的视觉特征表达和重排序模型建立。在图像视觉特征表达方面,一般常用的特征有基于纹理的、基于形状的、基于颜色的特征。利用最广泛的是尺度旋转不变特征(ScaleInvariantFeatureTransform,SIFT),这种特征对局部遮挡和旋转等有较高的鲁棒性,因此在图像检索、图像识别等领域取得了不错的效果。然而,近年来提出的深度卷积神经网络,不依赖于人工特征提取,可以自动从大量训练数据中提取层级特征,为图像视觉特征表达提供了一种新方法。如果可以将深度特征用于重排序中的特征表达,将有效提升重排序效果。在重排序模型设计方面,不管是基于伪相关反馈的方法,还是基于图的方法,基本假设都是返回的初始查询结果中排序靠前的图像大部分与查询相关。然而,由于噪声的影响,返回的结果中有包含大量不相关图像,在这种情况下这些重排序模型的效果不理想。因此,需要解决初始返回结果中噪声过大的问题。技术实现要素:基于
背景技术:
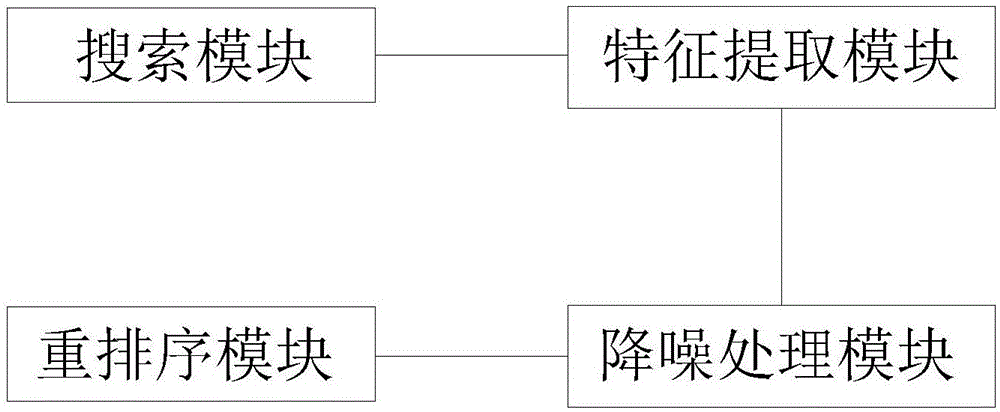
存在的技术问题,本发明提出了一种基于排列融合的图像检索重排序方法及系统。本发明提出的基于排列融合的图像检索重排序方法,包括以下步骤:S1、在搜索引擎上输入请求查询文本Q,得到基于请求查询文本Q的初始检索结果L,提取所述初始检索结果L中每幅图像的视觉特征,再计算出所述初始检索结果L中每幅图像与其它图像的相似度;S2、根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理后得到检索图像列表L′;S3、从所述检索图像列表L′中选取一个或多个种子点图像,并采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;其中,当从所述检索图像列表L′中选取一个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;当从所述检索图像列表L′中选取多个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果。优选地,步骤S1中提取所述初始检索结果L中每幅图像的视觉特征,再计算出所述初始检索结果L中每幅图像与其它图像的相似度具体包括:对初始检索结果L={I1,I2,...,IN}中的图像Ii提取基于深度卷积神经网络的特征,将其表示成一个特征向量;优选地,采用在ImageNetILSVRC-2012数据集上训练好的卷积神经网络;将图片Ii输入该网络,提取第七层全连接层的4096维特征k=1,...,4096,再将上述特征通过下述公式进行归一化,得到Ii的特征向量xi:其中,K是特征的维数且K=4096;由于特征的维数K较高,因此需对特征进行降维处理,优选地,采用PCA对特征进行降维处理;优选地,计算所述初始检索结果L中两幅图像Ii和Ij的相似度具体包括:计算两幅图像Ii和Ij对应特征向量间的卡方距离dij:两幅图像Ii和Ij的相似度sij按如下公式计算:其中,λ=0.5。优选地,步骤S2具体包括根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,去除所述初始检索结果L中与请求查询文本Q不相关的噪声图像,得到检索图像列表L′;优选地,采用基于相似度加权和的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:通过公式计算所述初始检索结果L中的每幅图像Ii与所述初始检索结果L中其它图像的相似度加权以及图像Ii的置信分数ci,所述公式为:其中,N为所述初始检索结果L中图像的幅数,sij为图像Ii和图像Ij之间的相似度,μj为加权系数,且图像Ij在所述初始检索结果L中的排序越靠前μj越大;优选地,采用基于视觉降序的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:基于视觉排序的降噪方法是利用视觉排序模型来计算每幅图像的置信分数;置信分数向量c=[c1,c2,L,cN]T中的ci对应所述初始检索结果L中第i图像Ij的置信分数,且置信分数通过下式迭代求解;c=d(S*×c)+(1-d)p;其中,c的初值设置为1/N,d为平衡参数且d=0.85,S*为对相似性矩阵S做列归一化得到的矩阵;将上式迭代达到稳定的结果c作为每幅图像的置信分数,且置信分数越高表明图像与请求查询文本Q的相关性越高,则将所述初始检索结果L中的图像按照置信分数从高至低进行排序,得到检索图像列表L′。优选地,步骤S3具体包括从所述检索图像列表L′中多次选取种子点图像,且每个种子点图像对应一个重排序结果,再对得到的多个重排序结果进行融合以得到最终重排序结果;优选地,采用Borda融合方法对得到的多个重排序结果进行融合,具体包括:Borda融合是将重排序结果转化成分数后再进行融合;重排序结果中排序越靠前的图像,分数越高;具体地,重排序结果中排序为R的图像的分数s为:其中,N为重排序结果中图像的总数量;对每幅图像计算出其在多个重排序结果中的分数总和,分数总和越高表明该图像与请求查询文本Q的相关度越高;将每幅图像按照分数总和从高至低排列即得到最终重排序结果;优选地,采用Condorect融合方法对得到的多个重排序结果进行融合,具体包括:Condorect融合是采用少数服从多数的投票机制;在每次迭代过程中,选择一张图像,上述图像满足如下条件:该图像与其它图像成对比较排名,如果该图像在重排序结果中的排名比其它图像都靠前,则选取该幅图像加入融合后图像序列,同时将此图像从候选图像集中去除;在下一次迭代过程中,按照上述过程和方法再选取一张图像加入融合后图像集;如此得到最终重排序结果;优选地,采用RRF融合方法对得到的多个重排序结果进行融合,具体包括:RRF融合方法将每幅图像按照如下公式从多个重排序结果R中计算出该幅图像的排序分数,所述公式为:其中,r(Ii)为图像Ii在某个重排序结果r中的排序位置;将每幅图像按照RRFscore的大小降序排序即得到最终重排序结果。本发明提出的基于排列融合的图像检索重排序系统,包括:搜索模块,用于在搜索引擎上根据请求查询文本Q得到基于请求查询文本Q的初始检索结果L;特征提取模块,用于提取所述初始检索结果L中每幅图像的视觉特征,并计算出所述初始检索结果L中每幅图像与其它图像的相似度;降噪处理模块,用于根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,并得到检索图像列表L′;重排序模块,用于从所述检索图像列表L′中选取一个或多个种子点图像,并采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果。优选地,所述重排序模块从所述检索图像列表L′中选取一个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;所述重排序模块从所述检索图像列表L′中选取多个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果。优选地,所述特征提取模块提取所述初始检索结果L中每幅图像的视觉特征,再计算出所述初始检索结果L中每幅图像与其它图像的相似度具体包括:对初始检索结果L={I1,I2,...,IN}中的图像Ii提取基于深度卷积神经网络的特征,将其表示成一个特征向量;优选地,采用在ImageNetILSVRC-2012数据集上训练好的卷积神经网络;将图片Ii输入该网络,提取第七层全连接层的4096维特征k=1,...,4096,再将上述特征通过下述公式进行归一化,得到Ii的特征向量xi:其中,K是特征的维数且K=4096;由于特征的维数K较高,因此需对特征进行降维处理,优选地,采用PCA对特征进行降维处理;优选地,计算所述初始检索结果L中两幅图像Ii和Ij的相似度具体包括:计算两幅图像Ii和Ij对应特征向量间的卡方距离dij:两幅图像Ii和Ij的相似度sij按如下公式计算:其中,λ=0.5。优选地,降噪处理模块具体包括根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,并得到检索图像列表L′;优选地,采用基于相似度加权和的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:通过公式计算所述初始检索结果L中的每幅图像Ii与所述初始检索结果L中其它图像的相似度加权以及图像Ii的置信分数ci,所述公式为:其中,N为所述初始检索结果L中图像的幅数,sij为图像Ii和图像Ij之间的相似度,μj为加权系数,且图像Ij在所述初始检索结果L中的排序越靠前μj越大;优选地,采用基于视觉降序的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:基于视觉排序的降噪方法是利用视觉排序模型来计算每幅图像的置信分数;置信分数向量c=[c1,c2,L,cN]T中的ci对应所述初始检索结果L中第i图像Ij的置信分数,且置信分数通过下式迭代求解;c=d(S*×c)+(1-d)p;其中,c的初值设置为1/N,d为平衡参数且d=0.85,S*为对相似性矩阵S做列归一化得到的矩阵;将上式迭代达到稳定的结果c作为每幅图像的置信分数,且置信分数越高表明图像与请求查询文本Q的相关性越高,则将所述初始检索结果L中的图像按照置信分数从高至低进行排序,得到检索图像列表L′。优选地,所述重排序模块具体包括从所述检索图像列表L′中选取多个种子点图像,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果;优选地,采用Borda融合方法对得到的多个重排序结果进行融合,具体包括:Borda融合是将重排序结果转化成分数后再进行融合;重排序结果中排序越靠前的图像,分数越高;具体地,重排序结果中排序为R的图像的分数s为:其中,N为重排序结果中图像的总数量;对每幅图像计算出其在多个重排序结果中的分数总和,分数总和越高表明该图像与请求查询文本Q的相关度越高;将每幅图像按照分数总和从高至低排列即得到最终重排序结果;优选地,采用Condorect融合方法对得到的多个重排序结果进行融合,具体包括:Condorect融合是采用少数服从多数的投票机制;在每次迭代过程中,选择一张图像,上述图像满足如下条件:该图像与其它图像成对比较排名,如果该图像在重排序结果中的排名比其它图像都靠前,则选取该幅图像加入融合后图像序列,同时将此图像从候选图像集中去除;在下一次迭代过程中,按照上述过程和方法再选取一张图像加入融合后图像集;如此得到最终重排序结果;优选地,采用RRF融合方法对得到的多个重排序结果进行融合,具体包括:RRF融合方法将每幅图像按照如下公式从多个重排序结果R中计算出该幅图像的排序分数,所述公式为:其中,r(Ii)为图像Ii在某个重排序结果r中的排序位置;将每幅图像按照RRFscore的大小降序排序即得到最终重排序结果。本发明提出了一种基于排序融合的图像检索重排序方法,该方法首先对初始检索结果进行降噪处理得到降噪后的排序结果,再对上述降噪后的排序结果进行基于图的重排序;如此,先对初始检索结果作了降噪处理后再对其进行基于图的重排序,有效地降低了重排序结果的不稳定性;进一步地,本发明提出了两种对初始结果进行降噪的方法,可以有效地从初始检索结果中将与请求查询文本相关的图像排在前面,提升后续基于图的重排序中种子点图像的查询相关度,保证重排序结果的稳定性和准确性;同时,本发明提出了三种对多个重排序结果进行融合的方法,上述方法通过对多个重排序结果进行融合再得到最终重排序结果,提升了最终重排序结果的稳定性,进一步保障本发明提出的重排序方法的稳定性和准确度。附图说明图1为一种基于排列融合的图像检索重排序方法的步骤示意图;图2为一种基于排列融合的图像检索重排序系统的结构示意图。具体实施方式如图1所示,图1为本发明提出的一种基于排列融合的图像检索重排序方法。参照图1,本发明提出的基于排列融合的图像检索重排序方法,包括以下步骤:S1、在搜索引擎上输入请求查询文本Q,得到基于请求查询文本Q的初始检索结果L,提取所述初始检索结果L中每幅图像的视觉特征,再计算出所述初始检索结果L中每幅图像与其它图像的相似度;其中,提取所述初始检索结果L中每幅图像的视觉特征,再计算出所述初始检索结果L中每幅图像与其它图像的相似度具体包括:对初始检索结果L={I1,I2,...,IN}中的图像Ii提取基于深度卷积神经网络的特征,将其表示成一个特征向量;优选地,采用在ImageNetILSVRC-2012数据集上训练好的卷积神经网络;将图片Ii输入该网络,提取第七层全连接层的4096维特征k=1,...,4096,再将上述特征通过下述公式进行归一化,得到Ii的特征向量xi:其中,K是特征的维数且K=4096;由于特征的维数K较高,因此需对特征进行降维处理,优选地,采用PCA对特征进行降维处理;优选地,计算所述初始检索结果L中两幅图像Ii和Ij的相似度具体包括:计算两幅图像Ii和Ij对应特征向量间的卡方距离dij:两幅图像Ii和Ij的相似度sij按如下公式计算:其中,λ=0.5。S2、根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理后得到检索图像列表L′;具体包括根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,去除所述初始检索结果L中与请求查询文本Q不相关的噪声图像,得到检索图像列表L′;优选地,采用基于相似度加权和的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:通过公式计算所述初始检索结果L中的每幅图像Ii与所述初始检索结果L中其它图像的相似度加权以及图像Ii的置信分数ci,所述公式为:其中,N为所述初始检索结果L中图像的幅数,sij为图像Ii和图像Ij之间的相似度,μj为加权系数,且图像Ij在所述初始检索结果L中的排序越靠前μj越大;优选地,采用基于视觉降序的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:基于视觉排序的降噪方法是利用视觉排序模型来计算每幅图像的置信分数;置信分数向量c=[c1,c2,L,cN]T中的ci对应所述初始检索结果L中第i图像Ij的置信分数,且置信分数通过下式迭代求解;c=d(S*×c)+(1-d)p;其中,c的初值设置为1/N,d为平衡参数且d=0.85,S*为对相似性矩阵S做列归一化得到的矩阵;将上式迭代达到稳定的结果c作为每幅图像的置信分数,且置信分数越高表明图像与请求查询文本Q的相关性越高,则将所述初始检索结果L中的图像按照置信分数从高至低进行排序,得到检索图像列表L′。S3、从所述检索图像列表L′中选取一个或多个种子点图像,并采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;其中,当从所述检索图像列表L′中选取一个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;当从所述检索图像列表L′中选取多个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果。当从所述检索图像列表L′中多次选取种子点图像,且每个种子点图像对应一个重排序结果,再对得到的多个重排序结果进行融合以得到最终重排序结果;优选地,采用Borda融合方法对得到的多个重排序结果进行融合,具体包括:Borda融合是将重排序结果转化成分数后再进行融合;重排序结果中排序越靠前的图像,分数越高;具体地,重排序结果中排序为R的图像的分数s为:其中,N为重排序结果中图像的总数量;对每幅图像计算出其在多个重排序结果中的分数总和,分数总和越高表明该图像与请求查询文本Q的相关度越高;将每幅图像按照分数总和从高至低排列即得到最终重排序结果;优选地,采用Condorect融合方法对得到的多个重排序结果进行融合,具体包括:Condorect融合是采用少数服从多数的投票机制;在每次迭代过程中,选择一张图像,上述图像满足如下条件:该图像与其它图像成对比较排名,如果该图像在重排序结果中的排名比其它图像都靠前,则选取该幅图像加入融合后图像序列,同时将此图像从候选图像集中去除;在下一次迭代过程中,按照上述过程和方法再选取一张图像加入融合后图像集;如此得到最终重排序结果;优选地,采用RRF融合方法对得到的多个重排序结果进行融合,具体包括:RRF融合方法将每幅图像按照如下公式从多个重排序结果R中计算出该幅图像的排序分数,所述公式为:其中,r(Ii)为图像Ii在某个重排序结果r中的排序位置;将每幅图像按照RRFscore的大小降序排序即得到最终重排序结果。如图2所示,图2为本发明提出的一种基于排列融合的图像检索重排序系统。参照图2,本发明提出的基于排列融合的图像检索重排序系统,包括:搜索模块,用于在搜索引擎上根据请求查询文本Q得到基于请求查询文本Q的初始检索结果L;特征提取模块,用于提取所述初始检索结果L中每幅图像的视觉特征,并计算出所述初始检索结果L中每幅图像与其它图像的相似度;具体包括:对初始检索结果L={I1,I2,...,IN}中的图像Ii提取基于深度卷积神经网络的特征,将其表示成一个特征向量;优选地,采用在ImageNetILSVRC-2012数据集上训练好的卷积神经网络;将图片Ii输入该网络,提取第七层全连接层的4096维特征k=1,...,4096,再将上述特征通过下述公式进行归一化,得到Ii的特征向量xi:其中,K是特征的维数且K=4096;由于特征的维数K较高,因此需对特征进行降维处理,优选地,采用PCA对特征进行降维处理;优选地,计算所述初始检索结果L中两幅图像Ii和Ij的相似度具体包括:计算两幅图像Ii和Ij对应特征向量间的卡方距离dij:两幅图像Ii和Ij的相似度sij按如下公式计算:其中,λ=0.5。降噪处理模块,用于根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,并得到检索图像列表L′;降噪处理模块具体包括根据所述初始检索结果L中每幅图像与其它图像的相似度对所述初始检索结果L进行降噪处理,并得到检索图像列表L′;优选地,采用基于相似度加权和的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:通过公式计算所述初始检索结果L中的每幅图像Ii与所述初始检索结果L中其它图像的相似度加权以及图像Ii的置信分数ci,所述公式为:其中,N为所述初始检索结果L中图像的幅数,sij为图像Ii和图像Ij之间的相似度,μj为加权系数,且图像Ij在所述初始检索结果L中的排序越靠前μj越大;优选地,采用基于视觉降序的降噪方法对所述初始检索结果L进行降噪处理,上述降噪方法具体包括:基于视觉排序的降噪方法是利用视觉排序模型来计算每幅图像的置信分数;置信分数向量c=[c1,c2,L,cN]T中的ci对应所述初始检索结果L中第i图像Ij的置信分数,且置信分数通过下式迭代求解;c=d(S*×c)+(1-d)p;其中,c的初值设置为1/N,d为平衡参数且d=0.85,S*为对相似性矩阵S做列归一化得到的矩阵;将上式迭代达到稳定的结果c作为每幅图像的置信分数,且置信分数越高表明图像与请求查询文本Q的相关性越高,则将所述初始检索结果L中的图像按照置信分数从高至低进行排序,得到检索图像列表L′。重排序模块,用于从所述检索图像列表L′中选取一个或多个种子点图像,并采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;其中,重排序模块从所述检索图像列表L′中选取一个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到重排序结果;重排序模块从所述检索图像列表L′中选取多个种子点图像时,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果。当所述重排序模块从所述检索图像列表L′中选取多个种子点图像,采用基于图的重排序方法对所述检索图像列表L′中的图像进行重排序得到多个重排序结果,并对上述得到的多个重排序结果进行融合,得到最终重排序结果;优选地,采用Borda融合方法对得到的多个重排序结果进行融合,具体包括:Borda融合是将重排序结果转化成分数后再进行融合;重排序结果中排序越靠前的图像,分数越高;具体地,重排序结果中排序为R的图像的分数s为:其中,N为重排序结果中图像的总数量;对每幅图像计算出其在多个重排序结果中的分数总和,分数总和越高表明该图像与请求查询文本Q的相关度越高;将每幅图像按照分数总和从高至低排列即得到最终重排序结果;优选地,采用Condorect融合方法对得到的多个重排序结果进行融合,具体包括:Condorect融合是采用少数服从多数的投票机制;在每次迭代过程中,选择一张图像,上述图像满足如下条件:该图像与其它图像成对比较排名,如果该图像在重排序结果中的排名比其它图像都靠前,则选取该幅图像加入融合后图像序列,同时将此图像从候选图像集中去除;在下一次迭代过程中,按照上述过程和方法再选取一张图像加入融合后图像集;如此得到最终重排序结果;优选地,采用RRF融合方法对得到的多个重排序结果进行融合,具体包括:RRF融合方法将每幅图像按照如下公式从多个重排序结果R中计算出该幅图像的排序分数,所述公式为:其中,r(Ii)为图像Ii在某个重排序结果r中的排序位置;将每幅图像按照RRFscore的大小降序排序即得到最终重排序结果。本实施方式中基于排序融合的图像检索重排序方法,该方法首先对初始检索结果进行降噪处理得到降噪后的排序结果,再对上述降噪后的排序结果进行基于图的重排序;如此,先对初始检索结果作了降噪处理后再对其进行基于图的重排序,有效地降低了重排序结果的不稳定性;进一步地,提出了两种对初始结果进行降噪的方法,可以有效地从初始检索结果中将与请求查询文本相关的图像排在前面,提升后续基于图的重排序中种子点图像的查询相关度,保证重排序结果的稳定性和准确性;同时,提出了三种对多个重排序结果进行融合的方法,上述方法通过对多个重排序结果进行融合再得到最终重排序结果,提升了最终重排序结果的稳定性,进一步保障本发明提出的重排序方法的稳定性和准确度。为验证本实施方式提出的方案的可行性和稳定性,针对性的进行了多次实验;实验结果如表1-表4所示,表中标记的含义如下:MAP@T是指排序前T的图像的平均正确率,是衡量图像排序结果的公认标准,它们的取值范围都在[0,1]之间,值越大表示排序效果越好。具体来说:1)对降噪方法进行了对比实验:对比初始检索结果、基于相似度加权和的降噪结果和基于视觉排序的降噪结果,实验结果请参见表1。从表1可以发现,通过对初始检索结果进行降噪,可以有效提升排序效果。表1基于相似度加强和的降噪方法和基于视觉排序的降噪方法比较结果2)对基于图的重排序方法进行了对比实验:比较初始检索结果、基于图的重排序结果(策略1)、先用基于相似度加权和的降噪后再用基于图的重排序结果(策略2),和先用基于视觉排序的降噪后再用基于图的重排序结果(策略3),实验结果请参见表2。从表2可以发现,基于图的重排序结果比初始检索结果好,先去噪再重排序比单独重排序的效果好。MAP@T初始检索结果策略1策略2策略350.6110.6700.7730.794100.5530.6640.7540.767200.5030.6550.7280.739400.4520.6390.6890.694600.4310.6290.6670.671800.4260.6270.6560.6601000.4310.6340.6570.662ALL0.5690.7150.7360.740表2基于图的重排序结果、先用基于相似度加权和的降噪后再用基于图的重排序结果和先用基于视觉排序的降噪后再用基于图的重排序结果比较3)对融合排序方法进行了对比实验:比较了三种不同融合策略的重排序结果,实验结果请参见表3。从表3可以发现,融合排序比单独排序效果好,三种融合策略效果相差不大,Borda和RRF略好于Condorect方法。表3三种不同融合策略的重排序结果比较4)利用本发明的方案与现有技术的方案进行了对比。对比结果如表4。表4的数据表明,本发明的重排序结果高于其它任何对比方法,可以得出本发明方法具有更好的重排序效果。表4本发明技术方案与现有技术方案的对比结果以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1