一种基于条件概率的程序错误定位方法与流程
本发明属于软件程序错误定位检测技术领域,具体涉及一种基于条件概率的程序错误定位方法。
背景技术:
软件规模和复杂程度的与日俱增给软件开发和调试技术带来了极大的挑战,面对软件开发过程中如影相随的软件缺陷问题,软件测试是提升其质量和可靠性的重要技术手段。因此,人们在软件测试方面的投入逐年不断增加,软件测试过程中,当发生被测软件的行为与预期不一致(即失效)时,开发人员就需要随即开展软件调试.软件调试的首要任务是缺陷定位,它为后续错误代码修复工作提供了基础。
缺陷定位旨在探测和查找引起软件失效的错误代码,是一项非常枯燥和耗时的活动。传统的手工设置断点的调试方法,不仅断点位置选择困难,且时间开销巨大;因此,实现缺陷定位的自动化成为了软件学术界和工业界共同追求的目标。目前自动化的缺陷定位方法尚未成熟,仍是软件工程领域的研究热点,近些年来,研究人员从不同的角度尝试提出了一系列缺陷定位方法,包括基于切片的错误定位方法、基于不变量的错误定位方法、模型检验方法和基于程序频谱的错误定位方法等。基于切片的错误定位方法主要通过对程序的静态或动态分析,找出与给定变量相关联的语句,从而缩小错误查找范围。基于不变量的错误定位,则通过利用成功和失效测试例不变量之间的差异信息,从而辅助定位错误语句。模型检验方法则利用失效程序行为与期望模型行为的冲突来推导程序错误。相比而言,基于频谱的缺陷定位方法(Spectrum-based Fault Localization,SFL)由于不需要考虑程序本身结构,执行开销小,成为了一种当前比较行之有效的重要方法。
程序频谱通常指程序运行时代码覆盖信息的集合,是程序动态行为特征的一种描述形式。由于程序运行失效时,必定至少执行到了某条错误语句,据此,可以得出经验性的推断:当某条语句被更多的失效执行所覆盖,那么它为错误语句的可能性就越高。因此,通过收集程序的频谱和执行结果两方面的信息来推导出程序缺陷位置成为了可能。具体的,SFL方法主要通过对比分析被测程序在成功执行和失效执行的程序频谱信息,构造相应的可疑度计算公式来估测程序元素(如语句,谓词等)出错的可能性,最终调试人员将程序元素按照可疑度大小降序逐一排查错误。因此,可疑度值辅助缺陷定位的精确程度成为了衡量SFL方法优劣的主要性能指标。
程序频谱和执行结果之间存在的潜在关联是可疑度计算公式构造的基础,显然,充分地挖掘和利用这种潜在关联蕴含的缺陷揭示信息,有助于提升可疑度计算公式缺陷定位的效用。
技术实现要素:
鉴于上述,本发明提供了一种基于条件概率的程序错误定位方法,通过经验性研究程序频谱和执行结果两者之间的内在关联,引入统计学的条件概率思想,构建了用以量化分析两者关系强弱评估的P模型,从而提出相应的可疑度计算公式,具有更好的缺陷定位效果。
一种基于条件概率的程序错误定位方法,包括如下步骤:
(1)统计软件程序中各条语句在每组测试用例下的语句覆盖情况,得到对应的语句覆盖矩阵;
(2)统计每组测试用例在软件程序运行下的执行结果:正确或错误;
(3)对于软件程序中的任一条语句s,构建由概率Pfe、Pef、Pte、Pet和Ptn所组成的条件概率模型;其中,Pfe表示在执行语句s的情况下软件程序运行结果为失败的概率,Pef表示在软件程序运行结果为失败的情况下执行语句s的概率,Pte表示在执行语句s的情况下软件程序运行结果为成功的概率,Pet表示在软件程序运行结果为成功的情况下执行语句s的概率,Ptn表示在不执行语句s的情况下软件程序运行结果为成功的概率;
(4)根据所述的条件概率模型计算语句s的错误可疑度并依此遍历软件程序中的所有语句;进而根据所述的错误可疑度从高到低对软件程序中的语句进行排序并逐条进行错误排查。
所述语句覆盖情况的定义为:以某一测试用例作为软件程序的输入,若软件程序对于该测试用例的整个运行过程中执行了某一条语句,则该语句在该测试用例下的语句覆盖情况表示为1,否则表示为0。
所述语句覆盖矩阵的维度为m×n,m为软件程序中的语句总数,n为测试用例总数;该矩阵中第i行第j列的元素值为第i条语句在第j组测试用例下的语句覆盖情况,i和j均为自然数且1≤i≤m,1≤j≤n。
所述概率Pfe、Pef、Pte、Pet和Ptn的计算表达式如下:
其中,a11表示软件程序对于测试用例的整个运行过程中执行了语句s且测试用例在软件程序运行下执行结果为正确的测试用例个数,a10表示软件程序对于测试用例的整个运行过程中执行了语句s且测试用例在软件程序运行下执行结果为错误的测试用例个数,a00表示软件程序对于测试用例的整个运行过程中未执行语句s且测试用例在软件程序运行下执行结果为错误的测试用例个数,a01表示软件程序对于测试用例的整个运行过程中未执行语句s且测试用例在软件程序运行下执行结果为正确的测试用例个数,a11+a10+a00+a01=n。
所述步骤(4)通过以下公式计算语句s的错误可疑度:
susp(s)=a11(Pfe+Pef)
其中:susp(s)为语句s的错误可疑度。
或所述步骤(4)通过以下公式计算语句s的错误可疑度:
优选地,所述步骤(4)通过以下公式计算语句s的错误可疑度并依此遍历所有语句;
susp(s)=a11(Pfe+Pef)
根据错误可疑度从高到低对软件程序中的语句进行排序并逐条进行错误排查,当排查比达到40%时仍未查找到错误语句,则通过以下公式重新计算剩余60%语句的可疑度,进而根据该可疑度从高到低对剩余60%的语句进行排序并逐条进行错误排查:
本发明通过经验性研究程序频谱和执行结果两者之间的内在关联,引入统计学的条件概率思想,构建了用以量化分析两者关系强弱评估的P模型。针对一些经典的SFL方法,依赖提出的P模型来量化分析具体的可疑度计算公式,从而探究其缺陷定位精度和效率差异的本质原因。基于此,本发明提出了一种基于条件概率的缺陷定位新方法,为了验证新方法的有效性,实证研究以Siemens套件中的7个程序和Space程序为基准评测对象,测试结果表明与已有的13个经典缺陷定位方法相比,本发明方法具有更好的缺陷定位效果。
附图说明
图1为西门子套件的错误语句的P值大小排名示意图。
图2为Space程序错误语句的P值大小排名示意图。
图3为本发明方法与经典方法关于代码检查百分比-错误版本数量的实验结果对比示意图。
图4为本发明方法与近年来先进方法关于代码检查百分比-错误版本数量的实验结果对比示意图。
图5为本发明方法与经典方法关于找到错误所需排查代码百分比的实验结果对比示意图。
图6为本发明方法与近年来先进方法关于找到错误所需排查代码百分比的实验结果对比示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
本发明为了方便浏览和计算,可以用符号表示出某条语句在不同测试测试用例下的四种运行情况,如表1所示:
表1
例如,a11代表了运行测试用例时执行了该语句且测试用例结果为失败的统计情况,若某条语句在某个用例下刚好执行且测试用例的结果为失败,那么该语句的a11计数就加1。在接下来的内容中,都将用这种形式来表示不同的频谱公式。
现有程序错误定位方法中,有的是引用其他领域的公式并进行大量实验来寻找出缺陷定位效果较好的公式,也有的则从程序实体本身入手,通过对程序实体的一些规律挖掘,如事件包含信息量、成功用例的影响来构造出新的频谱方法。这些方法本质上都可以看成是对a11、a10、a00和a01这四个因子权重的考虑,对这四个因子的权重考虑的越准确,缺陷定位效果也就越好。
为了更加全面准确的衡量出a11、a10、a00和a01四个因子的权重,需要对程序实体有更进一步的分析。因此,本发明从语句是否执行以及程序运行结果这两面的关系入手,对不同的情况进行具体分析,从而进一步提高缺陷定位的效率。
程序频谱包括了语句执行信息以及程序运行结果两方面的信息,语句包括执行与不执行两方面,运行结果则包括了成功与失败两方面。而这两者的信息并非相互独立,而是存在的一定的关系。因此,我们通过条件概率,来量化它们之间的关系。设某条语句s执行为E,不执行为N,程序运行失败为F,运行成功为T。我们将某条语句的运行情况与执行结果以条件概率的方式来表示:
P(F|E):表示在某条语句执行的条件下,程序运行结果为失败的概率,简称为Pfe;P(E|F):表示程序在运行失败的条件下,某条语句执行的概率,简称为Pef;P(T|E):表示在某条语句执行的条件下,程序运行结果为成功的概率,简称为Pte;P(E|T):表示程序在运行成功的条件下,某条语句执行的概率,简称Pet;P(T|N):表示在某条语句不执行的条件下,程序运行结果为成功的概率,简称为Ptn。
上述的几个条件概率,我们将其统称为P值。接着,进一步用a11、a10、a00和a01四个因子来表示出具体的公式,以Pfe为例。Pfe的含义为某条语句在执行的情况下失败的概率,用条件概率的定义表示则为:
同理,可得其他几个条件概率的公式为:
由通过上述对语句执行情况与执行结果关系的量化,我们就可以统计出错误语句与正确语句的P值的大小,从而进一步挖掘出其中的规律。首先,我们对其中的规律进行初步猜想,根据频谱方法的经验性分析可知,由于失败用例所执行的语句越多,该语句越有可能是错误语句。因此,可以粗略的猜想错误语句的Pfe以及Pef的值应该比正确语句的Pfe和Pef的值要大,而错误语句的Pet以及Ptn的值应该比正确语句Pet和Ptn的值小。由于Pfe与Pte的和为1,因此在考虑这两者的时候,只需要考虑其中一个即可,本发明考虑的是Pfe。
下面举一个简单的例子来对我们的猜想加以说明,该例子对两个数进行操作,然后返回操作结果。程序主要包含了一个简单的条件判断以及赋值。其中,代码行5为错误语句,正确语句应为result=a+b;T1~T6代表六个具体的测试用例,我们统计了测试用例T1~T6的执行情况以及执行结果,其中,T1=(2,1,sum),T2=(3,4,sum),T3=(5,0,sum),T4=(3,2,average),T5=(1,1,average),T6=(8,3,average)。统计结果如表2所示,若该语句被执行到,则用点表示,否则显示为空白。
表2
根据上述表格的统计信息,就可以将其代入到不同的P值公式进行计算,表3显示的是计算结果。
表3
注:*表示不可计算。
通过上述的计算结果可以得知,错误语句的Pfe、Pef以及Ptn这三个P值大于等于正确语句的对应P值,而错误语句的Pte、Pet的值则比正确语句的对应P值要低,与我们的猜想相一致。
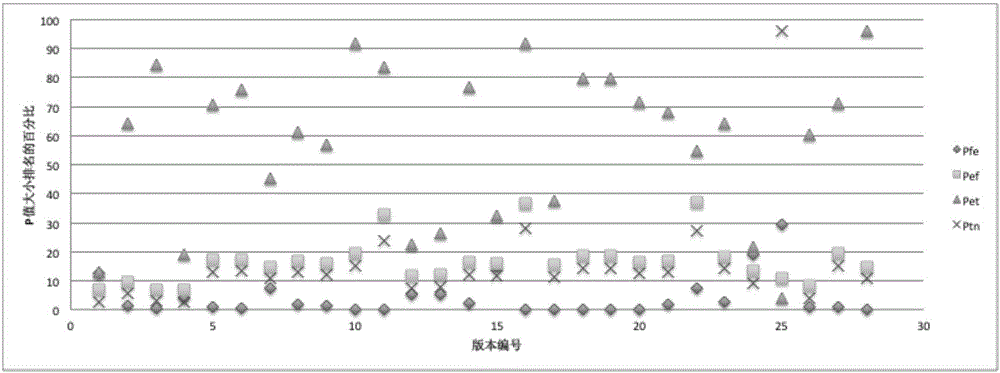
为了进一步验证我们的猜想,我们统计了西门子套件以及space程序的130个单行错误版本下所有可执行语句的P值大小,然后将错误语句的P值大小正确语句进行比较,图1为西门子的102个单行错误版本,而图2则为space程序的28个版本,横坐标为对不同错误版本的编号,纵坐标则为错误语句的P值相对大小位置。图1和图2中的某一点代表错误语句在某个版本下的P值大小在所有可执行语句中的排名情况。
从图1可以看出,大多数版本的错误语句的Pfe、Pef以及Ptn的值的大小在所有可执行语句中排名都比较靠前,其中错误语句的Pfe排名虽然出现了少数干扰,但是排名在前20%的版本也要多余Pef和Ptn,而错误语句的Pef与Pef的排名则都比较靠前。而对于错误语句的Pet大小而言,虽然多数版本的Pet大小在所有可执行语句中位于后40,但是却出现了较多的不符合该规律的版本,与我们的假设相符。而space由于程序代码量与测试用例远远大于西门子程序,所以实验结果也更加的稳定,与我们的猜想更加符合,绝大多数实验版本的错误语句的Pfe、Pef以及Ptn大小排名靠前,其中Pfe的排名要更加靠前。而多数版本的错误语句的Pet排名则比较靠后,但是在space这样的大程序下,同样出现了较多不符合规律的版本。
我们将之前的猜想经过实验验证之后,进一步总结发现以下两点:
发现1:错误语句的Pfe、Pef以及Ptn的大小在在所有可执行语句中的处于靠前的位置,排名的平均值分别为19.8、25.5、24.4。
发现2:错误语句的Pet的大小在所有可执行语句中的排名通常在后30%到40%,但是出现了较多排名靠前的情况,因此排名相对不稳定,平均值为55。
对于发现1,研究的是语句执行与运行失败这两者之间的概率关系,不难得知,由于缺陷语句的执行与失败之间存在很强的关联,因此Pfe与Pef的大小排名也应该靠前;反过来讲,错误语句不执行的情况下,语句运行为成功的概率也应该比较高,因此Ptn的排名也比较靠前;而对于发现2,理想情况下,错误语句执行的条件下,程序运行成功的概率应当不如正确语句,然而,统计出来的Pet排名却出现了较大的波动,规律相对不明显。对此,我们的解释是巧合性成功的普遍存在,使得在统计时出现了较多的噪声干扰。即一些测试用例虽然执行了错误语句,但是由于没有满足错误发生的条件或者虽然满足了错误的发生条件,但是没有影响到该模块的输出,这些测试用例都将影响到Pet的排名情况。
利用上述得出的两点发现,可以评价现有的一些频谱公式。因此,我们挑选了以下几个较为典型的频谱公式,这些公式的特点在于它们经过适当的变换之后都可以等价于P值的组合。
Ochiai:
Kulczynskil2:
Tarantula:
Ample:
不难发现,将Ochiai公式进行平方运算,结果就等于Pfe与Pef的乘积,而将Kulczynskil2乘以2,则等价于Pfe与Pef的和,而在计算可疑度的时候,上述运算不会改变可疑度的相对位置,因此这两个公式分别等价于Pfe*Pef以及Pfe+Pef。根据上述发现1可知,错误语句的Pfe与Pef的排名靠前,因此不管是将其相加还是相乘,结果的排名也会更靠前,所以Ochiai与Kulczynskil2的缺陷定位效果都较为理想。
同理,Tarantula方法实际上等价于而Ample方法则等价于|Pef-Pet|。这两个公式虽然都考虑到了错误语句的Pet排名,但是所采取的方式是直接将Pet与其他P值进行加减运算。而根据发现2,Pet排名表现出不稳定性,与其他P值进行加减之后,结果也会表现出不稳定性。因此这两个公式的缺陷定位效果普遍不如前面两个公式。
接下来,我们将利用上述的两点发现,进一步研究如何提高缺陷定位的效率。通过大量的观察以及实验,我们提出了以下两个公式:
Cp1:
Cp2:
首先是公式Cp1,根据之前的发现可知错误语句的Pfe与Pef的排名都比较靠前,可以将其作为公式的主要因子,比如Ochiai与Kulczynskil2。但是,在特定的情况下,也会出现正确语句的Pfe值大于错误语句的Pfe值,从而降低了错误语句的可疑度排名。例如,当正确语句存在于条件判断某块中,a10次数大大的减少。而a11的减少幅度则相对较少,根据可知,这种情况会使得正确语句的Pfe值变大。
表4
表4为西门子套件的tot_info的版本19的错误行数所在代码片段,S1为错误语句,错误原因为MAXILINE的值定义错误。我们统计了不同语句在1052个测试用例下的运行信息,并分别计算出不同语句的P值。这里只列出具有代表性的错误语句S1以及正确语句S7、S8,计算结果如表5所示:
表5
通过计算可知,如果采用Pfe与Pef相加的方式(即Kulczynskil2)计算可疑度,正确语句S7、S8的可疑度反而会排在错误语S1前面,从而降低了错误定位的效果。因此,为了弥补该不足,我们在构造可疑度公式时,应赋予a11更高的权重,因此CP1公式在Pef之前乘以一个a11,避免类似上述情况对可疑度结果的影响;同时,为了保持Pfe与Pef权重的一致性,在Pef之前也同样乘以一个a11。
公式Cp2的构造是基于发现2。根据发现2,Pet的排名在后面的百分之30到40,但是不稳定,不建议将其与其他P值直接进行加减运算,会影响到缺陷定位的效果,比如之前提到的Tarantula与Ample。因此,我们将Pet单独放在分母的位置,不仅在公式中体现出了Pet的规律,也尽可能的降低了其不稳定性所带来的负面影响。
实际过程中,程序员根据可疑度高低进行错误排查时,以CP1为主,当排查语句超过40%时还不能发现错误,此时可以以CP2对剩余语句重新计算排序后进行错误排查。这是因为,实验结果显示:当代码排查比低于40%时,CP1与其他公式相比,能发现更多的错误,故以CP1作为主要依据;而当代码排查比高于40%时,CP2则比其他公式更有优势。
以下我们通过实验对本发明所提出的可疑度公式CP1和Cp2进行验证,实验环境为Linux系统,版本为Ubuntu14.04,同时使用Gcc编译源程序,并使用Gcov工具收集代码执行信息,两者的版本都为4.8.4。实验采取的程序为以往论文广泛使用的西门子套件以及space程序,这些程序的版本都可以从SIR[19]库获取。其中,西门子套件共包括7个子程序,每个子程序都提供了一个正确版本以及若干个错误版本,每个错误版本皆为单错误类型,且错误版本的错误皆为手工植入的错误。而space则是一个完整的应用程序,包括38个错误版本,每个错误都是真实的错误。另外space包括13525个测试用例,大量的测试用例保证了每一行可执行语句都至少被30个测试用例所覆盖。西门子和space的程序信息见表6。
表6
在测试用例的选择上,选取的是全部测试用例。在版本的选择上,一些版本因为不存在失败测试用例而被排除,这些版本是schedule2的v9space的v1,v2,v32,v34。另外,也有一些版本导致异常终止,包括print_tokens2的版本10、tcas的版本38、schedule的1,5,6,9、replace的27,32以及space的v26,v30,v35,v36,v38。这些因为错误而导致程序异常终止的版本中,有一些版本虽然只有部分用例导致程序运行异常终止,但是由于实验采取的是全部测试用例,为了保持实验的严谨和一致性,故也将这几个版本排除。因此,实验共采用space的28个版本以及西门子的123个版本,合计共151个版本。
实验的目的主要是证实本发明所提出的Cp1与Cp2这两个方法的有效性。为了便于比较,实验还使用了一些经典公式以及近些年来提出的一些方法,共计13个,如表7所示,这些方法都是在以往论文中被经常拿来作为比较的方法。
表7
注:Dstar公式中,star为自定义参数,取值范围为任意正整数。
因为实验中所定位到的错误代码的粒度为语句,而西门子套件和space程序中,有一些版本的错误则是因为预定义数值错误、代码缺失以及变量类型定义错误引起的,这三者无法直接标识出错误所在位置。因此,我们采取的措施如下:对于预定义数值错误以及变量类型定义错误这两种错误类型,将错误代码标识到具体变量的使用行;而对于代码缺失所引起的错误,我们将错误代码行数随机标记到该行缺失代码所在的同一代码块的某一行。
实验结果主要是本发明所提出的方法与其他方法的比较,从两个角度来进行比较:所能发现的错误版本数以及不同程序使用的方法的平均性能。所能发现的错误版本数是指在某个检查代码的百分比下,所能发现的缺陷版本的百分比,如图3和图4所示,横坐标表示检测的代码的百分比,纵坐标表示所能发现的缺陷版本数的占总版本数的百分比。
从图3和图4中可以看出,在检查1%的代码下,Wong3与Op2能够发现最多的错误版本;随着代码排查百分比的增加,Cp1的效果开始逐渐超过其他方法,直到代码排查比达到19%,Cp1都处于领先的地位;当代码排查比超过19%时,Kulczynski2的效果开始开始赶上Cp1,两者都稍稍领先于其他方法;而当代码排查比超过31%时候,Cp1、Op2、M2、Kulczynsik2、Wong3这几个方法的定位效果领先于其他方法;当代码排查比超过42%时,Cp2与Wong1的优势明显。最后,随着代码排查比的不断增加,各种缺陷定位方法的效果开始持平。
综合来看,Cp1方法在绝大多数情况下,缺陷定位效果都要优于其他大多数方法,因为它在充分考虑Pfe与Pef的基础上,进行了改进;而Cp2则更侧重于考察Pet的影响,它的优势在于当代码排查比较大时,与Wong1方法都具有明显优势,同时,在代码排查比不大时,Cp2的缺陷定位效果又明显优于Wong1。因此,Cp1和Cp2的方法在发现错误版本方面,都具有各自的优势,与我们的预期相符。
从图5来看,在与一些经典方法比较时,除了schedule程序外,CP1在不同程序下的平均性能均要好于这些经典方法,而Cp2的平均性能则稍差于Kulczynski2,但是好于其他经典方法。而从图6来看,在与近些年来提出的一些缺陷效果定位较好的方法进行对比时,不同方法在不同版本下各有优势所在,Cp2在space程序下的平均性能最好,而在其他程序下,Cp1、Wong3以及Op2这三个方法要稍微优于其他方法,且这三个方法之间的平均性能差别很小,具体参见表8。
表8
注:数字表示找到错误语句的代码排查百分比,数字越低代表排查效果越好。
由此可见,本发明基于概率论中条件概率思想,量化程序语句执行与运行结果之间的关系,将其称之为P值;通过对西门子套件以及space程序中错误语句的P值统计,总结出了P值的两点规律,并利用这两点规律,解释了几个经典的方法的优劣;同时,提出了两个新的频谱公式Cp1以及Cp2。其中,Cp1在不同的程序中的整体缺陷定位效果要优于其他方法,而Cp2则在代码排查比超过一定范围时具有明显的优势。
- 还没有人留言评论。精彩留言会获得点赞!