一种用基于文本挖掘的电力用户分群方法与流程
背景技术:
:
随着新一轮的电力体制改革和电力企业向以客户服务能力提升为核心的转变,电力企业比以往更加关注为用电客户提供差异化、个性化的服务,进一步提高用电客户满意度。但对用电客户提供差异化、个性化服务的前提,就是需要根据用电客户的多种属性特征划分出不同的用电客户集合,即客户分群。传统的电力客户分群主要基于历史存量数据,根据业务人员已知的经验规则,采用数据分析和专家评定结合的方法,对客户进行分群。但传统的客户分群方法,其标签体系主要通过业务人员手工映射,受人工成本和人员经验局限性的影响,难以大规模开展;同时,传统客户分群的数据源主要为电力企业自有系统的结构化数据,没有对用电客户的行为数据、偏好数据和情感信息等动态数据做处理和分析,很难做到对用电客户的精准分群。因此,传统的电力客户分群方法,已经远远不能满足电力企业对用电客户提供个性化服务的需求了。
技术实现要素:
:
本发明正是为了克服现有电力客户分群方法存在的不足之处,提出了一种基于文本挖掘的电力用户分群的新方法。通过应用大数据技术和机器学习技术,基于电力企业的历史经营数据和用电客户的浏览行为、态度偏好、操作日志等非结构化数据,对用电客户进行精准用户画像,进而利用用户画像进行客户分群,分析用户偏好、发掘出客户的真正需求,进行有针对性的产品推荐和对用电客户提供个性化的服务。
本发明提出的一种基于文本挖掘的电力用户分群方法,本发明特征是,包括如下步骤:
步骤100:原始数据的采集与预处理;
通过数据挖掘和ETL工具收集电力企业的客户档案数据和历史运营数据;
通过网络爬虫收网上营业厅等系统的客户用电行为、偏好、操作日志等数据;
通过语音转换工具将95598等语音系统的语音信息转化为结构化文本数据;
步骤200:基于机器学习的文本自动分类模型建立标签体系库;
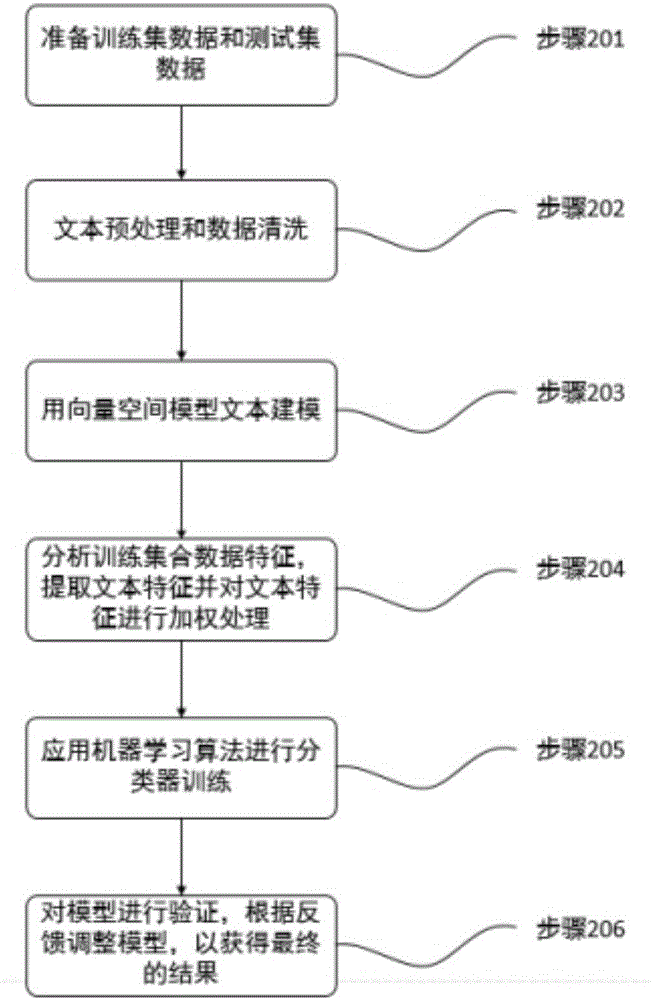
步骤201:准备训练集数据和测试集数据;
步骤202:文本预处理和数据清洗;
进行文本分词,通过去除停用词、低频词和标记信息等手段除去文档噪音,保留每一个文档的特征和有效字段;
步骤203:用向量空间模型文本建模;
步骤204:分析训练集合数据特征,提取文本特征并对文本特征进行加权处理;
步骤205:应用机器学习算法进行分类器训练;
步骤206:对模型进行验证,根据反馈调整模型,以获得最终的结果;
步骤300:利用K-means聚类算法对用电客户进行用户画像;
本发明根据步骤200得到的用户画像标签体系中的标签和权值,选取前K个业务关注的标签及其权值,使用K-means算法进行用户画像;
步骤400基于用户画像进行精细化客户群划分。
本发明根据步骤300所得的用户画像,将用户按照一定的规则进行聚类;依据用户画像下的若干个标签属性,采用Jaccard计算相似度的方法,计算出用户间的相似度,然后采用k-means方法对相似度在特定阀值范围内的用户进行聚类,完成客户群划分;其中相似度公式为:
Cik与Cjk分别表示第i个用户的第K个属性和第j个用户的第K个属性
用户相似度定义为:
其中Sim(u1,u2)表示用户u1和u2的相似度,M表示用户u的维度属性,Sij表示用户u1的第i个属性跟u2的第j个属性的相似度,且i=j。
本发明的有益效果是:
通过对网上营业厅等系统的客户用电行为、偏好、操作日志,以及95598系统的语音信息等非结构化数据进行处理分析,增加了用户分群的数据来源,提高了分群的准确度。
通过采用基于机器学的文本挖掘方法实现了用户画像的标签体系,通过统一的数据模型,只需要少量的人工辅助,非常适合于海量数据。
基于用户画像下的若干个标签属性,采用Jaccard计算相似度的方法,降低了个体用户画像的误差对群体用户画像的干扰,提高了用户分群的准确性。
附图说明:图1为总体结构图;
图2为构建标签体系库过程图;
具体实施方式:
下面结合附图对本发明具体实施方式做详细说明。一种基于文本挖掘的电力用户分群方法具体实施步骤如下:
步骤100原始数据的采集与预处理
通过数据挖掘和ETL工具收集电力企业的客户档案数据和历史运营数据;
通过网络爬虫收网上营业厅等系统的客户用电行为、偏好、操作日志等数据;
通过语音转换工具将95598等语音系统的语音信息转化为结构化文本数据;
步骤200基于机器学习的文本自动分类模型建立标签体系库
步骤201准备训练集数据和测试集数据
利用人工对一批预处理后的文档进行了准确分类,以作为进行机器学习的训练集数据;同时,准备测试已经训练好的模型的分类能力的测试样本集。训练集和测试集数据按照8:2的比例划分,其中80%的数据用于模型的建立,20%数据用于测试所建立模型的性能。
步骤202文本预处理和数据清洗
进行文本分词,通过去除停用词、低频词和标记信息等手段除去文档噪音,保留每一个文档的特征和有效字段。
采用THULAC(一个由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包)进行中文分词。
步去掉一些低频词,比如某些单词只在一两个文本中出现过,这样词留在集合中会导致大部分文本样本的该属性值为0。
去掉停止词,一般这种词几乎不携带任何信息。例如:“的”、“地”、“得”之类的助词,以及像“然而”、“因此”等只能反映句子语法结构的词语,它们不但不能反映文献的主题,而且还会对关键词的抽取造成干扰,有必要将其滤除。应该去掉的停止词为所有虚词以及标点符号。
去掉一些标记信息,这主要针对网页文本或其他的标记语言文本步骤203用向量空间模型文本建模
空间向量模型利用文本特征向量表示文本,在该模型中,用文本集合中的词条作为表示文本的特征项,所有特征项构成文本的特征向量。假设一个文档集合D包含n个文档,文档集合表示为D={d1,d2,d3,……,dn},文本集合中的所有词条表示为W={w1,w2,w3,……,wn},其中每个文档特征项对应一个权值,每个文档中特征项分布的差异性,使得特征项的权值不同,则每个文档都可以由特征向量Vdn={vt1,vt2,vt3,……,vtn}唯一表示,Vtn表示文本tn的特征向量,vtn表示特征词tn在文本dn中对应的权值。
步骤204分析训练集合数据特征,提取文本特征并对文本特征进行加权处理
本发明采用基于Filter模型的特征提取法,该方法依赖于训练集合数据本身,采用一种和分类器无关的评价标准,通过特征选择方法对所有特征进行过滤,过滤掉冗余、无关的特征,保留与类别相关的特征。选择和目标函数相关度大的特征子集,有利于提高算法的准确度。其具体步骤包括:
1)通过对训练集合文本进行分词等预处理,得到训练文本集合包含的所有文本特征,构成文本的原始特征集合S。
2)用某种特征评价函数对集合S中的每一个文本特征项评分,将集合S中各个文本特征项得分按分值高低进行排序。
3)按业务需求进行向量降维设定,若需将原始的向量空间维度降维N,则选择几个S中文本特征项排名最高的N个特征项,构成最终特征集合。
步骤205应用机器学习算法进行分类器训练
本发明采用KNN(K近邻算法)对分分类器进行训练。KNN算法的原理是通过找到与待分类文本相似度最接近的k个训练集文本,然后统计k个训练集文本的类别归属情况。若K个训练集文本中,属于类别C的文本占多数,则待分类文本属于类别C。其中文本相似度的计算通常采用欧式距离,K值为基于经验的人工制定参数。KNN算法的具体步骤如下:
1)计算特征选择环节获得的文本特征词集合中各个特征词对应每个经过预处理的训练集文本的权重,然后将经过预处理的训练集文本用特征向量表示。
2)计算特征现选择环节获得的文本特征词集合中各个特征词对应的经过预处理的待分类文本的权重,然后将讲过预处理的待分类文本用特征向量表示。
3)通过计算相似度得出与待分类文本最相似的前K个训练集文本。
4)统计K个训练集文本的类别归属情况
5)将待分类文本分到K个训练集文本归属类别占多数的类别中。
步骤206对模型进行验证,根据反馈调整模型,以获得最终的结果
步骤300利用K-means聚类算法对用电客户进行用户画像
根据步骤200得到的用户画像标签体系中的标签和权值,选取前K个业务关注的标签及其权值,使用K-means算法进行用户画像。K-means算法的步骤如下:
1)输入K的值,即我们希望将数据集D={P1,P2,…,Pn}经过聚类得到K个分类。
2)从数据集D中随机选择K个数据点作为质心,质心集合定义为:Centroid={Cp1,Cp2,……,Cpk},排除质心以后数据集O={O1,O2,…,Om}。
3)对集合O中每一个数据点Oi,计算Oi与Cpj(j=1,2,…,k)的距离,得到一组距离Si={si1,si2,……,sik},计算Si中距离最小值,则该该数据点Oi就属于该最小距离值对应的质心。
4)每个数据点Oi都已经属于其中一个质心,然后根据每个质心所包含的数据点的集合,重新计算得到一个新的质心。
5)如果新计算的质心和原来的质心之间的距离达到某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止。
6)如果新质心和原来之心距离变化很大,需要迭代2~5步骤。
步骤400基于用户画像进行精细化客户群划分
根据步骤300所得的用户画像,将用户按照一定的规则进行聚类。依据用户画像下的若干个标签属性,采用Jaccard计算相似度的方法,计算出用户间的相似度,然后采用k-means方法对相似度在特定阀值范围内的用户进行聚类,完成客户群划分。其中相似度公式为:
Cik与Cjk分别表示第i个用户的第K个属性和第j个用户的第K个属性
用户相似度定义为:
其中Sim(u1,u2)表示用户u1和u2的相似度,M表示用户u的维度属性,Sij表示用户u1的第i个属性跟u2的第j个属性的相似度,且i=j。
- 还没有人留言评论。精彩留言会获得点赞!